ワークスペースモデルレジストリ (レガシ) を使用したモデルのライフサイクルの管理
このドキュメントでは、ワークスペースモデルレジストリについて説明します。 ワークスペースで Unity Catalog が有効になっている場合は、このページの手順を使用しないでください。 代わりに、 Unity Catalog のモデルを参照してください。
ワークスペースモデルレジストリから Unity Catalogにアップグレードする方法のガイダンスについては、「ワークフローとモデルを Unity Catalogに移行する」を参照してください。
ワークスペースのデフォルトカタログが (hive_metastoreではなく) Unity Catalogにあり、Databricks Runtime 13.3 LTS 以降を使用するか、MLflow 3 を使用してクラスタリングを実行している場合、モデルはワークスペースのデフォルトカタログに自動的に作成され、ワークスペースのデフォルトカタログから読み込まれるため、設定は必要ありません。この場合に Workspace Model Registry を使用するには、ワークロードの開始時に import mlflow; mlflow.set_registry_uri("databricks") を実行して、明示的にターゲットにする必要があります。 デフォルト カタログが 2024 年 1 月より前の Unity Catalog カタログに構成され、ワークスペース モデルレジストリが 2024 年 1 月より前に使用されていた少数のワークスペースは、この動作から除外され、 Workspace Model Registry by デフォルトを引き続き使用します。
2024 年 4 月以降、Databricks Workspace Model Registryワークスペースのデフォルト カタログ が にある新しいアカウントのワークスペースのUnity Catalog が無効になります。
この記事では、機械学習ワークフローの一部として ワークスペースモデルレジストリ を使用して、ML モデルのライフサイクル全体を管理する方法について説明します。 ワークスペースモデルレジストリは、Databricksが提供するMLflowモデルレジストリののホスト型バージョンです。
このWorkspace Model Registry MLflowは、MLflow 2.x と同様に 3 でも引き続きサポートされます。MLflow3 では、デフォルト レジストリ URI はdatabricks-uc で、 のMLflow Model Registry Unity Catalogが使用されます。Workspace Model Registry を使用するには、 mlflow.set_registry_uri("databricks")を呼び出す必要があります。詳細については、「 モデル レジストリ」を参照してください。
ワークスペースモデルレジストリ には、次の機能があります。
- 時系列のモデルリネージ(どのMLflowのエクスペリメントとランによって、ある時点のモデルが生成されたか)。
- モデルサービング。
- モデルのバージョン管理。
- ステージの移行 (ステージングから本番運用、アーカイブなど)。
- Webhookを使用すると、レジストリイベントに基づいてアクションを自動的にトリガーできます。
- モデルイベントのEメール 通知。
モデルの説明を作成して表示したり、コメントを残したりすることもできます。
この記事には、ワークスペースモデルレジストリUI と ワークスペースモデルレジストリAPI の両方の手順が含まれています。
Workspace Model Registryの概念の概要については、 DatabricksのMLflow参照してください。
モデルを作成または登録する
UI を使用してモデルを作成または登録するか、APIを使用してモデルを登録することができます。
UI を使用してモデルを作成または登録する
ワークスペースモデルレジストリにモデルを登録するには、2つの方法があります。 MLflowに記録された既存のモデルを登録するか、新しい空のモデルを作成して登録し、以前に記録済みモデルを割り当てることができます。
既存の記録済みモデルをノートブックから登録する
-
ワークスペースで、登録するモデルを含む MLflow 実行を特定します。
-
ノートブックの右側のサイドバーにある エクスペリメント アイコン
 をクリックします。
をクリックします。
-
エクスペリメント 実行サイドバーで、実行日の横にある
 アイコンをクリックします。 [MLflow の実行] ページが表示されます。 このページには、パラメーター、メトリクス、タグ、アーティファクトのリストなど、実行の詳細が表示されます。
アイコンをクリックします。 [MLflow の実行] ページが表示されます。 このページには、パラメーター、メトリクス、タグ、アーティファクトのリストなど、実行の詳細が表示されます。
-
-
「アーティファクト」セクションで、 xxx-model という名前のディレクトリをクリックします。
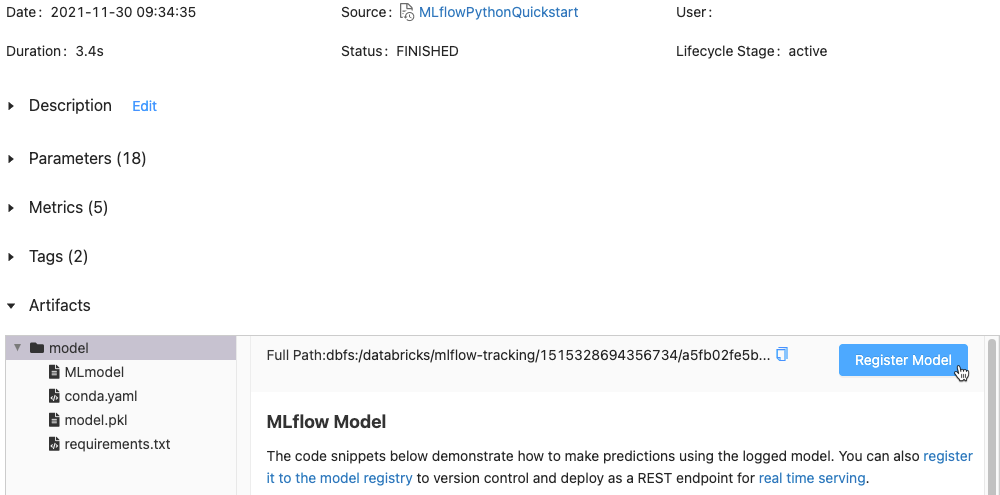
-
右端の モデルを登録する ボタンをクリックします。
-
ダイアログで、[ モデル ]ボックスをクリックし、次のいずれかの操作を行います。
- ドロップダウンメニューから[ 新しいモデルを作成 ]を選択します。 「モデル名 」フィールドが表示されます。モデル名を入力します (例:
scikit-learn-power-forecasting)。 - ドロップダウンメニューから既存のモデルを選択します。
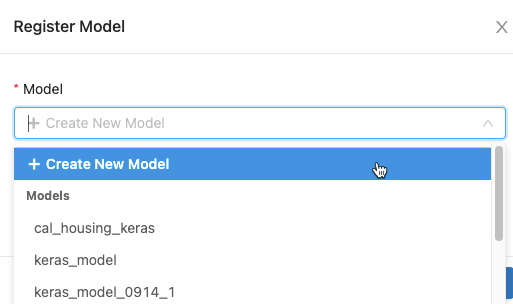
- ドロップダウンメニューから[ 新しいモデルを作成 ]を選択します。 「モデル名 」フィールドが表示されます。モデル名を入力します (例:
-
登録 をクリックします。
- [ 新しいモデルの作成 ] を選択した場合は、
scikit-learn-power-forecastingという名前のモデルが登録され、 ワークスペースモデルレジストリによって管理される安全な場所にモデルがコピーされ、モデルの新しいバージョンが作成されます。 - 既存のモデルを選択した場合は、選択したモデルの新しいバージョンが登録されます。
しばらくすると、[ モデルを登録する ] ボタンが新しい登録済みモデル バージョンへのリンクに変わります。
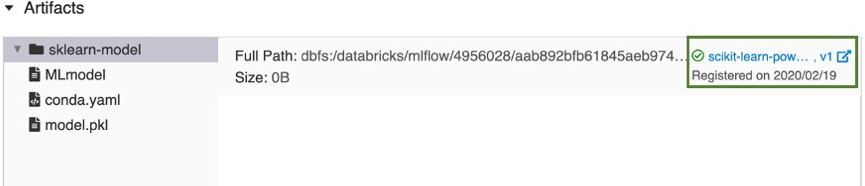
- [ 新しいモデルの作成 ] を選択した場合は、
-
リンクをクリックして、ワークスペースモデルレジストリ UIで新しいモデルバージョンを開きます。 ワークスペースモデルレジストリでモデルを見つけるには、サイドバーの
 モデル をクリックします。
モデル をクリックします。
新しい登録済みモデルを作成し、それに記録済みモデルを割り当てる
[登録済みモデル] ページの [モデルの作成] ボタンを使用して、新しい空のモデルを作成し、それに記録済みモデルを割り当てることができます。 以下の手順に従います。
-
登録済みモデルのページで、[ モデルの作成 ] をクリックします。 モデルの名前を入力し、[ 作成 ]をクリックします。
-
ノートブックから既存の記録済みモデルを登録する の手順 1 から 3 に従います。
-
[登録する Model] ダイアログで、ステップ 1 で作成したモデルの名前を選択し、[ 登録する ] をクリックします。 これにより、作成した名前のモデルが登録され、 ワークスペースモデルレジストリによって管理される安全な場所にモデルがコピーされ、モデル バージョン (
Version 1) が作成されます。しばらくすると、 MLflow 実行 UI の [登録する Model] ボタンが、新しく登録されたモデル バージョンへのリンクに置き換わります。 これで、 エクスペリメント ラン ページの「モデルを登録する」ダイアログの モデル ドロップダウンリストからモデルを選択できるようになりました。また、Create ModelVersion などの API コマンドでモデルの名前を指定して、モデルの新しいバージョンを登録することもできます。
API を使用してモデルを登録する
ワークスペースモデルレジストリにモデルを登録するには、プログラムによる方法が3つあります。 すべての方法で、ワークスペースモデルレジストリによって管理される安全な場所にモデルがコピーされます。
-
MLflowエクスペリメント中にモデルをログに記録し、指定した名前で登録するには、
mlflow.<model-flavor>.log_model(...)メソッドを使用します。名前が登録されたモデルが存在しない場合、メソッドは新しいモデルを登録し、バージョン 1 を作成し、ModelVersionMLflow オブジェクトを返します。 その名前の登録済みモデルがすでに存在する場合、メソッドは新しいモデルバージョンを作成し、バージョンオブジェクトを返します。Pythonwith mlflow.start_run(run_name=<run-name>) as run:
...
mlflow.<model-flavor>.log_model(<model-flavor>=<model>,
artifact_path="<model-path>",
registered_model_name="<model-name>"
) -
指定した名前のモデルを登録するには、すべてのエクスペリメントの実行が完了し、レジストリに追加するのに最も適したモデルを決定した後、
mlflow.register_model()方法を使用します。 この方法では、mlruns:URI引数の実行 ID が必要です。名前が登録されたモデルが存在しない場合、メソッドは新しいモデルを登録し、バージョン 1 を作成し、ModelVersionMLflow オブジェクトを返します。 その名前の登録済みモデルがすでに存在する場合、メソッドは新しいモデルバージョンを作成し、バージョンオブジェクトを返します。Pythonresult=mlflow.register_model("runs:<model-path>", "<model-name>") -
指定した名前で新しい登録済みモデルを作成するには、MLflow クライアント API
create_registered_model()メソッドを使用します。 モデル名が存在する場合、このメソッドはMLflowExceptionをスローします。Pythonclient = MlflowClient()
result = client.create_registered_model("<model-name>")
Databricks Terraform プロバイダーと databricks_mlflow_model にモデルを登録することもできます。
クォータ制限
2024 年 5 月以降、すべての Databricks ワークスペースに対して、 ワークスペースモデルレジストリ ワークスペースごとの登録済みモデルとモデル バージョンの合計数にクォータ制限が課されます。 リソースの制限を参照してください。レジストリ クォータを超えた場合、Databricks では、登録されたモデルと不要になったモデル バージョンを削除することをお勧めします。 Databricks では、モデルの登録と保持の戦略を調整して、制限内に収まるようにすることもお勧めします。 ワークスペースの制限を増やす必要がある場合は、Databricks アカウント チームにお問い合わせください。
次のノートブックは、モデルレジストリ エンティティをインベントリおよび削除する方法を示しています。
ワークスペース モデルレジストリ エンティティを一覧するノートブック
UIでモデルを表示する
登録済みモデルページ
サイドバーの![]() モデル をクリックすると、「登録済みモデル」ページが表示されます。このページには、レジストリ内のすべてのモデルが表示されます。
モデル をクリックすると、「登録済みモデル」ページが表示されます。このページには、レジストリ内のすべてのモデルが表示されます。
このページから 新しいモデルを作成できます 。
また、このページから、ワークスペース管理者はワークスペースモデルレジストリ内のすべてのモデルに権限を設定できます。

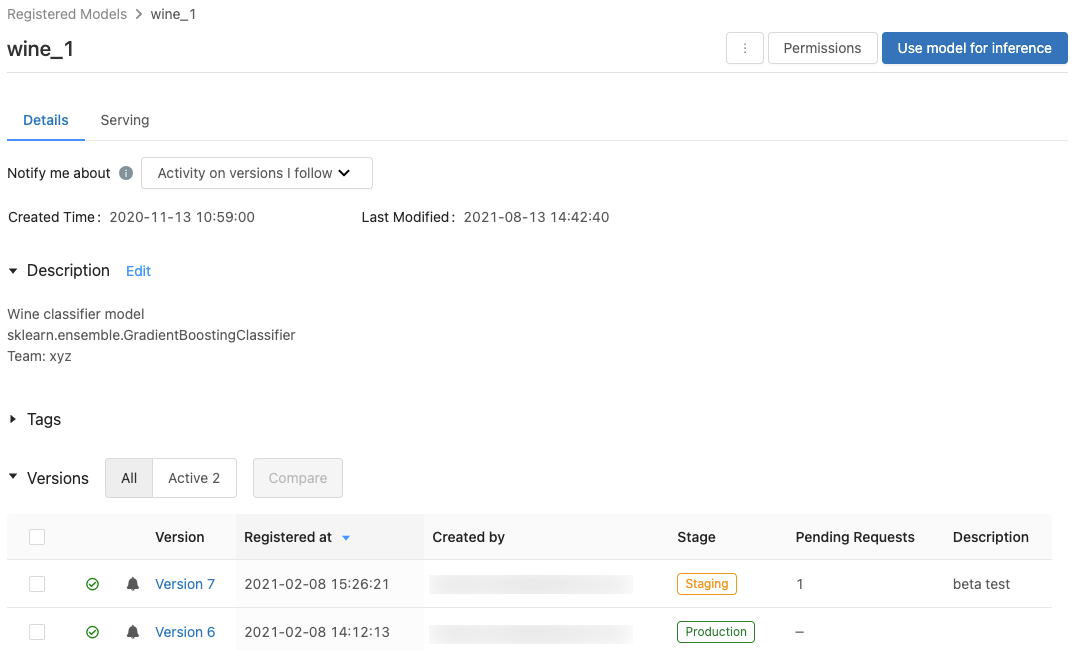
登録モデルページ
モデルの登録済みモデルページを表示するには、登録済みモデルページでモデル名をクリックします。 登録済みモデルページには、選択したモデルに関する情報と、モデルの各バージョンに関する情報を含むテーブルが表示されます。 このページでは、次のこともできます。
- モデルサービングを設定します。
- 推論にモデルを使用するノートブックを自動的に生成します。
- Eメール 通知を設定します。
- モデルのバージョンを比較します。
- モデルの権限を設定します。
- モデルを削除します。
モデルバージョンページ
モデルバージョンページを表示するには、次のいずれかの操作を行います。
- 登録済みモデルページの 最新バージョン 列でバージョン名をクリックします。
- 登録済みモデル ページの バージョン 列でバージョン名をクリックします。
このページには、登録済みモデルの特定のバージョンに関する情報が表示され、ソース実行 (モデルを作成するために実行されたノートブックのバージョン) へのリンクも表示されます。 このページでは、次のこともできます。
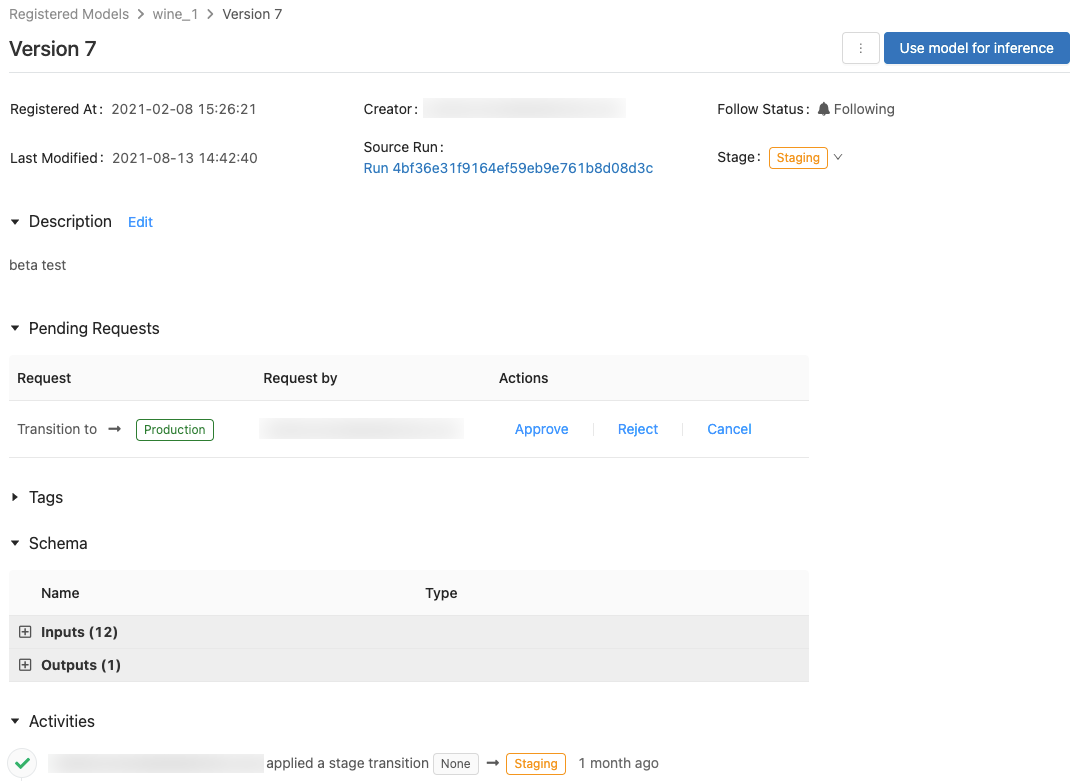
モデルへのアクセスの制御
モデルに対する権限を設定するには、少なくともCAN MANAGE権限が必要です。 モデルのアクセス許可レベルに関する情報については、「MLflowモデル ACL」を参照してください。モデル バージョンは、親モデルから権限を継承します。 モデルバージョンの権限は設定できません。
-
サイドバーで、「
モデル 」をクリックします。 -
モデル名を選択します。
-
[権限] をクリックします。[権限設定] ダイアログが開きます

-
ダイアログで、[ ユーザー、グループ、またはサービスプリンシパルの選択 ] ドロップダウンを選択し、ユーザー、グループ、またはサービスプリンシパルを選択します。
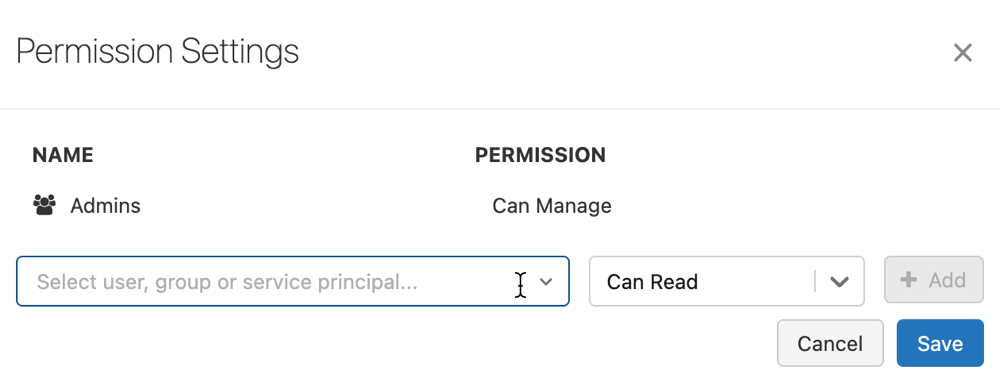
-
権限ドロップダウンから権限を選択します。
-
追加 をクリックし、 保存 をクリックします。
ワークスペース管理者とレジストリ全体のレベルで CAN MANAGE 権限を持つユーザーは、[モデル] ページの アクセス許可 をクリックして、ワークスペース内のすべてのモデルにアクセス許可レベルを設定できます。
モデルステージの移行
モデルバージョンには、 なし 、 ステージング 、 本番運用 、 アーカイブ のいずれかのステージがあります。 ステージング ステージはモデルのテストと検証を目的としており、 本番運用 ステージは、テストまたはレビュー プロセスを完了し、ライブ スコアリングのためにアプリケーションにデプロイされたモデル バージョン用です。アーカイブ済みモデル バージョンは非アクティブと見なされ、その時点で 削除を検討できます。 モデルの異なるバージョンは、異なる段階にある場合があります。
適切な 権限を持つ ユーザーは、ステージ間でモデルバージョンを移行できます。 モデルバージョンを特定のステージに移行する権限がある場合は、直接移行を行うことができます。 権限がない場合は、ステージの移行をリクエストでき、モデルバージョンの移行権限を持つユーザーは リクエストを承認、拒否、またはキャンセルできます。
モデルステージは、UIまたは APIを使用して移行できます。
UIを使用したモデルステージのトランジション
次の手順に従って、モデルのステージを移行します。
-
使用可能なモデル・ステージと使用可能なオプションのリストを表示するには、モデル・バージョン・ページで、「 ステージ:」 の横にあるドロップダウンをクリックし、別のステージへの遷移をリクエストまたは選択します。
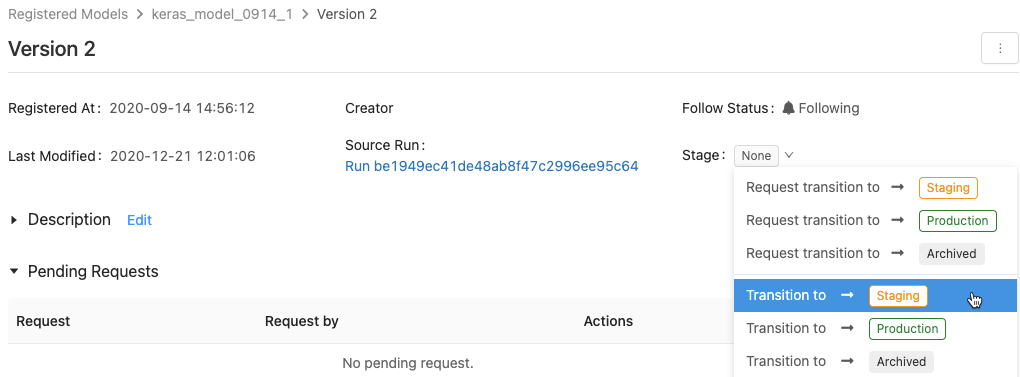
-
オプションのコメントを入力し、 OK をクリックします。
モデル版を本番運用ステージに移行する
テストと検証を行った後、本番運用ステージへの移行または移行のリクエストを行うことができます。
ワークスペースモデルレジストリ では、各ステージで登録済みモデルの複数のバージョンを使用できます。 本番運用に1つのバージョンのみを含める場合は、「 既存の本番運用モデルのバージョンをアーカイブ済みに移行する 」にチェックを入れることで、現在本番運用中のモデルのすべてのバージョンをアーカイブ済みに移行できます。
モデル バージョン ステージの移行要求を承認、拒否、またはキャンセルする
ステージの移行権限を持たないユーザーは、ステージの移行をリクエストできます。 要求は、モデルバージョンページの 保留中の要求 セクションに表示されます。

ステージの移行リクエストを承認、却下、またはキャンセルするには、[ 承認 ]、[ 却下 ]、または [ キャンセル ] リンクをクリックします。
トランジションリクエストの作成者は、リクエストをキャンセルすることもできます。
モデルバージョンのアクティビティの表示
リクエストされたトランジション、承認されたトランジション、保留中のトランジション、モデルバージョンに適用されたすべてのトランジションを表示するには、[アクティビティ]セクションに移動します。このアクティビティの記録は、監査または検査のためのモデルのライフサイクルのリネージを提供します。
API を使用したモデルステージの移行
適切な権限を持つユーザーは、モデルバージョンを新しいステージに移行できます。
モデル バージョン ステージを新しいステージに更新するには、MLflow クライアント API transition_model_version_stage() メソッドを使用します。
client = MlflowClient()
client.transition_model_version_stage(
name="<model-name>",
version=<model-version>,
stage="<stage>",
description="<description>"
)
<stage>に指定できる値は、"Staging"|"staging"、"Archived"|"archived"、"Production"|"production"、"None"|"none"です。
推論にモデルを使用する
プレビュー
この機能は パブリック プレビュー段階です。
モデルを ワークスペースモデルレジストリ に登録した後、バッチ推論またはストリーミング推論にモデルを使用するノートブックを自動的に生成できます。 または、エンドポイントを作成して、 モデルサービングでリアルタイムサービングにモデルを使用することもできます。
登録済みのモデルページまたはモデルバージョンページの右上隅にある[![]() ]をクリックします。[モデル推論の構成] ダイアログが表示され、バッチ推論、ストリーミング推論、またはリアルタイム推論を構成できます。
]をクリックします。[モデル推論の構成] ダイアログが表示され、バッチ推論、ストリーミング推論、またはリアルタイム推論を構成できます。
株式会社Anacondaは、anaconda.org チャンネル の利用規約 を更新しました。 新しいサービス条件に基づき、Anacondaのパッケージングと配布に依存する場合は、商用ライセンスが必要になる場合があります。 詳細については、 Anaconda Commercial Edition の FAQ を参照してください。 Anacondaチャンネルの使用は、その利用規約に準拠します。
MLflowv1.18 より前 (Databricks Runtime 8.3ML 以前) で記録された モデルは、デフォルトによって condadefaults チャンネル (https://repo.anaconda.com/pkgs/) で記録されていました依存関係として。 このライセンス変更に伴い、 Databricks は MLflow v1.18 以降を使用してログインしたモデルでの defaults チャンネルの使用を停止しました。 ログに記録されたデフォルト チャンネルは、コミュニティが管理する https://conda-forge.org/ を指す conda-forgeになりました。
MLflow v1.18より前のモデルをログに記録し、そのモデルのconda環境からdefaultsチャンネルを除外しなかった場合、そのモデルは意図していないdefaultsチャンネルに依存している可能性があります。モデルにこの依存関係があるかどうかを手動で確認するには、記録済みモデルにパッケージ化されているconda.yaml ファイル内のchannel値を調べます。たとえば、defaults チャンネルの依存関係を持つモデルのconda.yamlは、次のようになります。
channels:
- defaults
dependencies:
- python=3.8.8
- pip
- pip:
- mlflow
- scikit-learn==0.23.2
- cloudpickle==1.6.0
name: mlflow-env
Databricksは、Anacondaとの関係の下で、モデルと対話するためのAnacondaリポジトリの使用が許可されているかどうかを判断できないため、Databricksは顧客に変更を加えることを強制していません。Databricks の使用による Anaconda.com リポジトリの使用が Anaconda の条件で許可されている場合は、何もする必要はありません。
モデルの環境で使用するチャンネルを変更したい場合は、新しい conda.yamlでモデルをワークスペース モデルレジストリに再登録する これを行うには、log_model()の conda_env パラメーターでチャンネルを指定します。
log_model() APIの詳細については、使用しているモデル フレーバーのMLflowドキュメンテーション(log_model for a scikit-learnなど)を参照してください。
conda.yamlファイルの詳細については、 MLflow のドキュメントを参照してください。
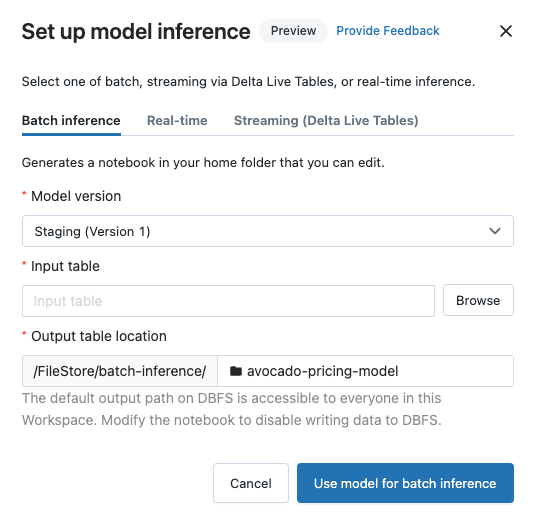
バッチ推論を構成する
これらの手順に従ってバッチ推論ノートブックを作成すると、ノートブックは、モデルの名前が付いたフォルダー内の Batch-Inference フォルダーの下のユーザー フォルダーに保存されます。必要に応じてノートブックを編集できます。
-
バッチ推論 タブをクリックします。
-
モデル バージョン ドロップダウンから、使用するモデル バージョンを選択します。ドロップダウンの最初の 2 つの項目は、モデルの現在の本番運用バージョンとステージング バージョン (存在する場合) です。 これらのオプションのいずれかを選択すると、ノートブックは実行時点の本番運用バージョンまたはステージングバージョンを自動的に使用します。 モデルの開発を続行するときに、ノートブックを更新する必要はありません。
-
[入力テーブル ] の横にある [参照 ] ボタンをクリックします。 [入力データの選択 ] ダイアログが表示されます。必要に応じて、 コンピュート ドロップダウンでクラスターを変更できます。
Unity Catalog 対応ワークスペースの場合、 入力データの選択 ダイアログでは、 <catalog-name>.<database-name>.<table-name>の 3 つのレベルから選択できます。
-
モデルの入力データを含むテーブルを選択し、 選択 をクリックします。 生成されたノートブックは、このデータを自動的にインポートしてモデルに送信します。 生成されたノートブックは、モデルに入力する前にデータの変換が必要な場合に編集できます。
-
予測は、ディレクトリ の
dbfs:/FileStore/batch-inferenceのフォルダに保存されます。 デフォルトでは、予測はモデルと同じ名前のフォルダに保存されます。 生成されたノートブックを実行するたびに、名前にタイムスタンプが付加された新しいファイルがこのディレクトリに書き込まれます。 また、タイムスタンプを含めず、ノートブックの後続の実行でファイルを上書きすることもできます。手順は、生成されたノートブックに記載されています。予測を保存するフォルダを変更するには、 出力テーブルの場所フィールドに新しいフォルダ名を入力するか 、フォルダアイコンをクリックしてディレクトリをブラウズし、別のフォルダを選択します。
予測を Unity Catalog内の場所に保存するには、ノートブックを編集する必要があります。 Unity Catalog のデータを使用する機械学習モデルをトレーニングし、結果を Unity Catalog に書き戻す方法を示すノートブックの例については、「 機械学習のチュートリアル」を参照してください。
Lakeflow Pipelinesを使用したストリーミング推論の構成
これらの手順に従ってストリーミング推論ノートブックを作成すると、ノートブックは、モデルの名前を持つフォルダー内の DLT-Inference フォルダーの下のユーザー フォルダーに保存されます。必要に応じてノートブックを編集できます。
-
Streaming (Lakeflow pipelines) tabをクリックします。
-
モデル バージョン ドロップダウンから、使用するモデル バージョンを選択します。ドロップダウンの最初の 2 つの項目は、モデルの現在の本番運用バージョンとステージング バージョン (存在する場合) です。 これらのオプションのいずれかを選択すると、ノートブックは実行時点の本番運用バージョンまたはステージングバージョンを自動的に使用します。 モデルの開発を続行するときに、ノートブックを更新する必要はありません。
-
[入力テーブル ] の横にある [参照 ] ボタンをクリックします。 [入力データの選択 ] ダイアログが表示されます。必要に応じて、 コンピュート ドロップダウンでクラスターを変更できます。
Unity Catalog 対応ワークスペースの場合、 入力データの選択 ダイアログでは、 <catalog-name>.<database-name>.<table-name>の 3 つのレベルから選択できます。
-
モデルの入力データを含むテーブルを選択し、 選択 をクリックします。 生成されたノートブックは、入力テーブルをソースとして使用するデータ変換を作成し、MLflow PySpark 推論 UDF を統合してモデル予測を実行します。 モデルの適用前または適用後にデータに追加の変換が必要な場合は、生成されたノートブックを編集できます。
-
出力 Lakeflow パイプライン名を指定してください。ノートブックは、指定された名前でライブテーブルを作成し、それを使用してモデルの予測を格納します。生成されたノートブックを変更して、必要に応じてターゲット データセットをカスタマイズできます。たとえば、ストリーミング ライブテーブルを出力として定義したり、スキーマ情報を追加したり、データ品質制約を追加したりできます。
-
その後、このノートブックを使用して新しいパイプラインを作成するか、追加のノートブック ライブラリとして既存のパイプラインに追加できます。
リアルタイム推論を構成する
モデルサービング は、 MLflow 機械学習モデルをスケーラブルな REST API エンドポイントとして公開します。 モデルサービングエンドポイントを作成するには、「 カスタムモデルサービングエンドポイントを作成する」を参照してください。
フィードバックの提供
この機能はプレビュー段階であり、フィードバックをお待ちしております。 フィードバックを提供するには、[モデル推論の構成] ダイアログで [ Provide Feedback ] をクリックします。
モデルバージョンの比較
ワークスペースモデルレジストリでモデルのバージョンを比較できます。
- 登録モデルページで、モデルバージョンの左側にあるチェックボックスをクリックして、2つ以上のモデルバージョンを選択します。
- 比較 をクリックします。
- [
<N>バージョンの比較] 画面が表示され、選択したモデル バージョンのパラメーター、スキーマ、およびメトリクスを比較するテーブルが表示されます。 画面の下部で、プロットのタイプ(散布図、等高線座標、または平行座標)と、プロットするパラメーターまたはメトリクスを選択できます。
通知設定を制御する
登録されたモデルおよび指定したモデル・バージョンでのアクティビティーについて、Eメール で通知するように ワークスペースモデルレジストリ を構成できます。
登録モデルページの「 Notify me about 」メニューには、次の3つのオプションが表示されます。
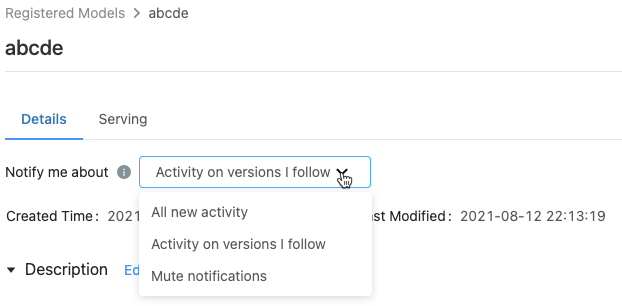
- すべての新しいアクティビティ : このモデルのすべてのモデルバージョンのすべてのアクティビティに関するEメール 通知を送信します。 登録済みのモデルを作成した場合は、この設定がデフォルトです。
- フォローしているバージョンでのアクティビティ : フォローしているモデルバージョンについてのみEメール通知を送信します。 この選択により、フォローしているすべてのモデルバージョンの通知を受け取ります。特定のモデルバージョンの通知をオフにすることはできません。
- 通知のミュート :この登録済みモデルのアクティビティに関するEメール通知を送信しません。
次のイベントがEメール通知をトリガーします。
- 新モデルバージョンの作成
- ステージ移行のリクエスト
- ステージ移行
- 新しいコメント
次のいずれかの操作を行うと、モデル通知が自動的にサブスクライブされます。
- そのモデルバージョンについてコメントする
- モデルバージョンのステージの移行
- モデルのステージの遷移要求を行う
モデル・バージョンをフォローしているかどうかを確認するには、 モデル・バージョン・ページの「ステータスのフォロー」フィールド、または登録済みモデル・ページのモデル・バージョンの表を確認します。
すべてのEメール通知をオフにする
Eメール 通知は、[ユーザー設定] メニューの [ ワークスペースモデルレジストリ 設定] タブでオフにできます。
- Databricks ワークスペースの右上隅にあるユーザー名をクリックし、ドロップダウン メニューから [ 設定 ] を選択します。
- 設定 サイドバーで、 通知 を選択します。
- モデルレジストリのEメール 通知 をオフにします。
アカウント管理者は、 管理者設定ページで組織全体のEメール通知をオフにすることができます。
Eメール送信の最大数
ワークスペースモデルレジストリ 、各アクティビティごとに各ユーザーに送信されるEメールの数を制限します。 例えば、登録したモデルに対して作成された新しいモデルバージョンについて、1日に20通のEメールを受け取った場合、 ワークスペースモデルレジストリ は1日の制限に達したことを知らせるEメールを送信し、そのイベントに関する追加のEメールは翌日まで送信されません。
Eメールの上限を引き上げるには、 Databricks アカウントチームにお問い合わせください。
Webhook
プレビュー
この機能は パブリック プレビュー段階です。
Webhook を使用すると、ワークスペースモデルレジストリ イベントをリッスンして、インテグレーションでアクションを自動的にトリガーできます。 Webhook を使用して、機械学習パイプラインを自動化し、既存の CI/CD ツールやワークフローと統合できます。 たとえば、新しいモデルバージョンが作成されたときにCIビルドをトリガーしたり、本番運用へのモデル移行がリクエストされるたびにSlackを通じてチームメンバーに通知したりできます。
モデルまたはモデルバージョンに注釈を付けてください
アノテーションによって、モデルまたはモデルのバージョンに関する情報を提供できます。たとえば、問題の概要や、使用された方法論およびアルゴリズムに関する情報を含めることができます。
UIを使用したモデルまたはモデルバージョンの注釈付け
Databricks UI には、モデルとモデル バージョンに注釈を付ける方法がいくつか用意されています。 説明やコメントを使用してテキスト情報を追加したり、 検索可能なキー値タグを追加したりできます。 説明とタグは、モデルとモデルバージョンで使用できます。コメントはモデルバージョンでのみ使用できます。
- 説明は、モデルに関する情報を提供することを目的としています。
- コメントは、モデルバージョンのアクティビティに関する継続的な議論を維持する方法を提供します。
- タグを使用すると、モデルのメタデータをカスタマイズして、特定のモデルを見つけやすくすることができます。
モデルまたはモデルバージョンの説明を追加または更新してください
-
登録済みモデルまたはモデル バージョン ページで、 説明 の横にある 編集 をクリックします。編集ウィンドウが表示されます。
-
編集ウィンドウで説明を入力または編集します。
-
保存 をクリックして変更を保存するか、 キャンセル をクリックしてウィンドウを閉じます。
モデルバージョンの説明を入力した場合、その説明は登録済みモデルページのテーブルの「 説明 」列に表示されます。列には、最大 32 文字または 1 行のテキストのいずれか短い方が表示されます。
モデル バージョンのコメントを追加する
- モデル バージョン ページを下にスクロールし、 アクティビティ の横にある下矢印をクリックします。
- 編集ウィンドウにコメントを入力し、 コメントの追加 をクリックします。
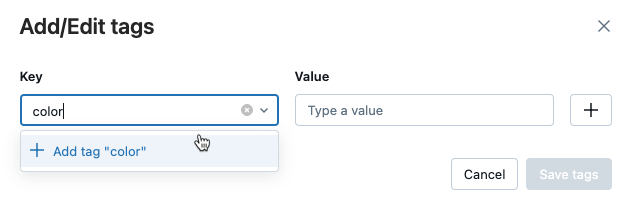
モデルまたはモデル バージョンのタグを追加する
-
登録済みモデルまたはモデルバージョンページで、まだ開いていない場合は
 をクリックします。タグ テーブルが表示されます。
をクリックします。タグ テーブルが表示されます。
-
「名前 」フィールドと 「値 」フィールドをクリックし、タグのキーと値を入力します。
-
[ 追加 ] をクリックします。
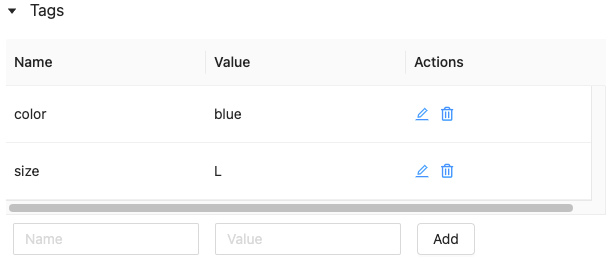
モデルまたはモデル バージョンのタグの編集または削除
既存のタグを編集または削除するには、[ アクション ] 列のアイコンを使用します。
API を使用してモデル バージョンに注釈を付ける
モデルバージョンの説明を更新するには、MLflowクライアントAPIのupdate_model_version()メソッドを使用します。
client = MlflowClient()
client.update_model_version(
name="<model-name>",
version=<model-version>,
description="<description>"
)
登録済みモデルまたはモデル バージョンのタグを設定または更新するには、MLflow クライアント API set_registered_model_tag()) または set_model_version_tag() メソッドを使用します。
client = MlflowClient()
client.set_registered_model_tag()(
name="<model-name>",
key="<key-value>",
tag="<tag-value>"
)
client = MlflowClient()
client.set_model_version_tag()(
name="<model-name>",
version=<model-version>,
key="<key-value>",
tag="<tag-value>"
)
モデルの名前を変更する (API のみ)
登録されたモデルの名前を変更するには、MLflowクライアントAPIのrename_registered_model()メソッドを使用します。
client=MlflowClient()
client.rename_registered_model("<model-name>", "<new-model-name>")
登録済みモデルの名前を変更できるのは、バージョンがない場合、またはすべてのバージョンが [なし] ステージまたは [アーカイブ済み] ステージにある場合のみです。
モデルを検索する
ワークスペースモデルレジストリ でモデルは、UI または API を使用して検索できます。
モデルを検索すると、少なくとも CAN READ パーミッションを持つモデルのみが返されます。
UI を使用したモデルの検索
![]() 登録済みのモデルを表示するには、サイドバーの「 モデル 」をクリックします。
登録済みのモデルを表示するには、サイドバーの「 モデル 」をクリックします。
特定のモデルを検索するには、検索ボックスにテキストを入力します。 モデルの名前または名前の任意の部分を入力できます。
タグで検索することもできます。 タグは tags.<key>=<value>の形式で入力します。 複数のタグを検索するには、 AND 演算子を使用します。
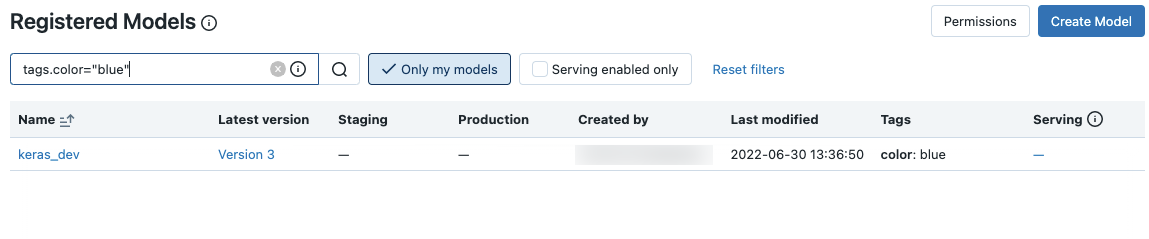
MLflow 検索構文を使用して、モデル名とタグの両方を検索できます。例えば:
![]()
API を使用したモデルの検索
MLflow search_registered_models()メソッドを使用して、 Workspace Model Registry内の登録済みモデルを検索できます。
モデルにタグを設定している場合は、search_registered_models() を使用してそれらのタグで検索することもできます。
import mlflow
from pprint import pprint
print(f"Find registered models with a specific tag value")
for m in mlflow.search_registered_models(f"tags.`<key-value>`='<tag-value>'"):
pprint(dict(m), indent=4)
MLflow search_model_versions()メソッドを使用して、特定のモデル名を検索し、そのバージョンの詳細を一覧表示することもできます。
import mlflow
from pprint import pprint
[pprint(mv) for mv in mlflow.search_model_versions("name='<model-name>'")]
出力は以下のようになります。
{ 'creation_timestamp': 1582671933246,
'current_stage': 'Production',
'description': 'A random forest model containing 100 decision trees '
'trained in scikit-learn',
'last_updated_timestamp': 1582671960712,
'name': 'sk-learn-random-forest-reg-model',
'run_id': 'ae2cc01346de45f79a44a320aab1797b',
'source': './mlruns/0/ae2cc01346de45f79a44a320aab1797b/artifacts/sklearn-model',
'status': 'READY',
'status_message': None,
'user_id': None,
'version': 1 }
{ 'creation_timestamp': 1582671960628,
'current_stage': 'None',
'description': None,
'last_updated_timestamp': 1582671960628,
'name': 'sk-learn-random-forest-reg-model',
'run_id': 'd994f18d09c64c148e62a785052e6723',
'source': './mlruns/0/d994f18d09c64c148e62a785052e6723/artifacts/sklearn-model',
'status': 'READY',
'status_message': None,
'user_id': None,
'version': 2 }
モデルまたはモデルバージョンを削除する
モデルは、UI または API を使用して削除できます。
UI を使用したモデルのバージョンまたはモデルの削除
この操作は元に戻せません。 モデル・バージョンは、レジストリから削除するのではなく、アーカイブ・ステージに移行できます。 モデルを削除すると、 ワークスペースモデルレジストリ によって保存されたすべてのモデル アーティファクトと、登録されたモデルに関連付けられているすべてのメタデータが削除されます。
モデルとモデル・バージョンは、「なし」ステージまたは「アーカイブ済」ステージでのみ削除できます。 登録済みモデルのバージョンがステージングステージまたは本番運用ステージにある場合は、モデルを削除する前に、それらを なし ステージまたは アーカイブ済み ステージに移行する必要があります。
モデルバージョンを削除するには:
- サイドバーの「 モデル 」をクリックします。
- モデル名をクリックします。
- モデル バージョンをクリックします。
- 画面の右上隅にあるケバブメニュー
 をクリックし、ドロップダウンメニューから[ 削除 ]を選択します。
をクリックし、ドロップダウンメニューから[ 削除 ]を選択します。
モデルを削除するには:
- サイドバーの「 モデル 」をクリックします。
- モデル名をクリックします。
- 画面の右上隅にあるケバブメニュー をクリックし、ドロップダウンメニューから[ 削除 ]を選択します。
API を使用してモデルのバージョンまたはモデルを削除する
この操作は元に戻せません。 モデル・バージョンは、レジストリから削除するのではなく、アーカイブ・ステージに移行できます。 モデルを削除すると、 ワークスペースモデルレジストリ によって保存されたすべてのモデル アーティファクトと、登録されたモデルに関連付けられているすべてのメタデータが削除されます。
モデルとモデル・バージョンは、「なし」ステージまたは「アーカイブ済」ステージでのみ削除できます。 登録済みモデルのバージョンがステージングステージまたは本番運用ステージにある場合は、モデルを削除する前に、それらを なし ステージまたは アーカイブ済み ステージに移行する必要があります。
モデルバージョンを削除します
モデルバージョンを削除するには、MLflowクライアントAPIのdelete_model_version()メソッドを使用します。
# Delete versions 1,2, and 3 of the model
client = MlflowClient()
versions=[1, 2, 3]
for version in versions:
client.delete_model_version(name="<model-name>", version=version)
モデルの削除
モデルを削除するには、MLflowクライアントAPIのdelete_registered_model()メソッドを使用します。
client = MlflowClient()
client.delete_registered_model(name="<model-name>")
ワークスペース間でモデルを共有する
Databricks では、 Unity Catalog のモデル を使用して、ワークスペース間でモデルを共有することをお勧めします。 Unity Catalog は、ワークスペース間のモデル アクセス、ガバナンス、監査ログをすぐにサポートします。
ただし、ワークスペース モデルレジストリを使用している場合は、一部のセットアップで 複数のワークスペース間でモデルを共有する こともできます。 たとえば、自分のワークスペースでモデルを開発してログに記録し、リモート ワークスペース モデルレジストリを使用して別のワークスペースからモデルにアクセスできます。 これは、複数のチームがモデルへのアクセスを共有する場合に便利です。 複数のワークスペースを作成し、これらの環境全体でモデルを使用および管理できます。
ワークスペース間で MLflow オブジェクトをコピーする
MLflowDatabricksワークスペースとの間で オブジェクトをインポートまたはエクスポートするには、コミュニティ主導のオープンソースプロジェクトMLflow Export-Import MLflowを使用して、ワークスペース間でエクスペリメント、モデル、および実行 移行できます。
これらのツールを使用すると、次のことができます。
- 同じまたは別のトラッキングサーバー内の他の データサイエンティスト と共有し、共同作業します。 たとえば、他のユーザーのエクスペリメントをワークスペースに複製できます。
- 1 つのワークスペースから別のワークスペース (開発ワークスペースから本番運用ワークスペースなど) にモデルをコピーします。
- エクスペリメント MLflow をコピーして、ローカルの追跡サーバーから Databricks ワークスペースに実行します。
- ミッションクリティカルなエクスペリメントとモデルを別の Databricks ワークスペースにバックアップします。
例
この例では、ワークスペースモデルレジストリ を使用して機械学習アプリケーションを構築する方法を示します。