Databricks での LLMOps ワークフロー
この記事では、LLMOps ワークフローに固有の情報を追加することで、 Databricks の MLOps ワークフロー を補完します。 詳細については、「 The Big Book of MLOps」を参照してください。
LLM の MLOps ワークフローはどのように変更されますか?
LLMは、自然言語処理(NLP)モデルのクラスであり、自由回答形式の質問応答、要約、命令の実行など、さまざまなタスクにわたってサイズとパフォーマンスで前任者を大幅に上回っています。
LLMの開発と評価は、従来のMLモデルとはいくつかの重要な点で異なります。 このセクションでは、LLM の主要なプロパティの一部と MLOps への影響について簡単にまとめます。
LLM の主なプロパティ | MLOps への影響 |
|---|---|
LLMにはさまざまな形式があります。
| 開発プロセス: プロジェクトは、多くの場合、既存のモデル、サードパーティモデル、またはオープンソースモデルから始まり、カスタムの微調整されたモデルで終了し、段階的に開発されます。 |
多くのLLMは、一般的な自然言語のクエリと命令を入力として受け取ります。 これらのクエリには、必要な応答を引き出すために慎重に設計されたプロンプトを含めることができます。 | 開発プロセス: LLM をクエリするためのテキスト テンプレートの設計は、多くの場合、新しい LLM パイプラインを開発する上で重要な部分です。 ML アーティファクトのパッケージ化: 多くの LLM パイプラインは、既存の LLM または LLM サービス エンドポイントを使用します。 これらのパイプライン用に開発された ML ロジックは、モデル自体ではなく、プロンプト テンプレート、エージェント、またはチェーンに焦点を当てている場合があります。 パッケージ化されて本番運用に昇格される ML アーティファクトは、モデルではなく、これらのパイプラインである可能性があります。 |
多くの LLM には、クエリの回答に役立つ例、コンテキスト、またはその他の情報を含むプロンプトを与えることができます。 | サービングインフラストラクチャ: LLM クエリをコンテキストで拡張する場合は、ベクトル インデックスなどの追加ツールを使用して、関連するコンテキストを検索できます。 |
サードパーティの API は、独自のオープンソースモデルを提供します。 | API ガバナンス: 一元化されたAPIガバナンスを使用すると、APIプロバイダーを簡単に切り替えることができます。 |
LLM は非常に大規模なディープラーニング モデルであり、多くの場合、ギガバイトから数百ギガバイトの範囲です。 | サービングインフラストラクチャ: LLM では、リアルタイム モデルサービングには GPU が必要で、動的に読み込む必要があるモデルには高速ストレージが必要になる場合があります。 コストとパフォーマンスのトレードオフ: モデルが大きいほど、より多くの計算が必要になり、提供にコストがかかるため、モデルのサイズと計算を縮小する手法が必要になる場合があります。 |
LLMは、単一の「正しい」答えがないことが多いため、従来の ML メトリクスを使用して評価することは困難です。 | 人間からのフィードバック: LLMの評価とテストには、人間のフィードバックが不可欠です。 ユーザーからのフィードバックは、テスト、モニタリング、将来のファインチューニングなど、 MLOps プロセスに直接組み込む必要があります。 |
MLOpsとLLMOpsの共通点
MLOps プロセスの多くの側面は、LLM でも変更されません。 たとえば、次のガイドラインは LLM にも適用されます。
- 開発、ステージング、本番運用に別々の環境を使用します。
- バージョン管理には Git を使用します。
- MLflow を使用してモデル開発を管理し、 Unity Catalog のモデル を使用してモデルのライフサイクルを管理します。
- Delta テーブルを使用してレイクハウス アーキテクチャにデータを格納する。
- 既存の CI/CD インフラストラクチャを変更する必要はありません。
- MLOps のモジュール構造は同じままで、特徴量化、モデル トレーニング、モデル推論などのパイプラインがあります。
リファレンスアーキテクチャ図
このセクションでは、2 つの LLM ベースのアプリケーションを使用して、 従来の MLOps のリファレンス アーキテクチャに対する調整の一部を示します。 この図は、1)サードパーティーの APIを使用したRAG(Retrieval-augmented generation)アプリケーション、2)セルフホステッド・ファインチューニング・モデルを使用したRAGアプリケーションの本番運用アーキテクチャを示しています。 どちらの図もオプションのベクターデータベースを示しています — このアイテムは、モデルサービングエンドポイントを介してLLMに直接クエリを実行することで置き換えることができます。
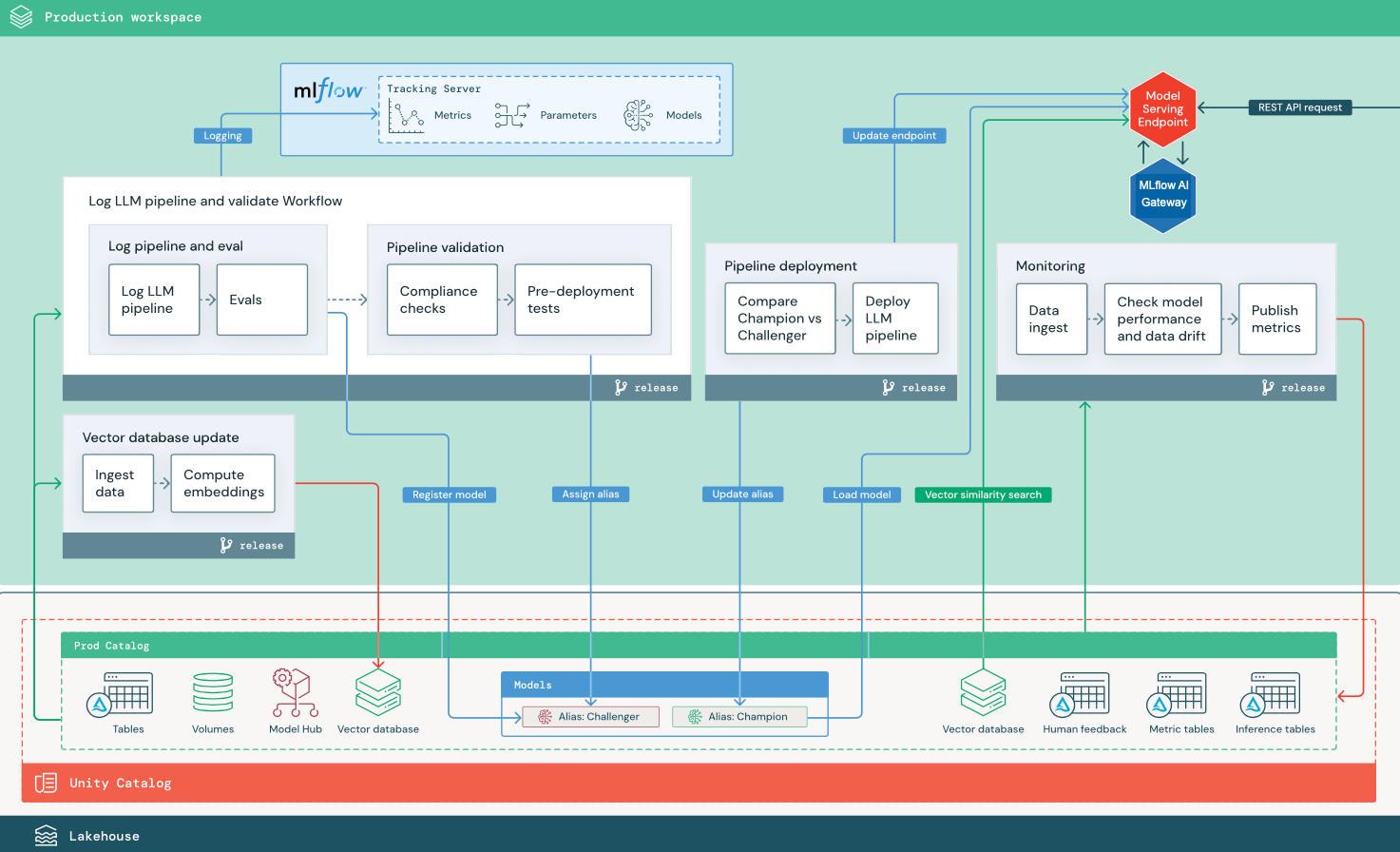
サードパーティのLLM APIを使用したRAG
この図は、 Databricksの外部モデルを使用してサードパーティのLLM APIに接続するRAGアプリケーションの本番運用アーキテクチャを示しています。
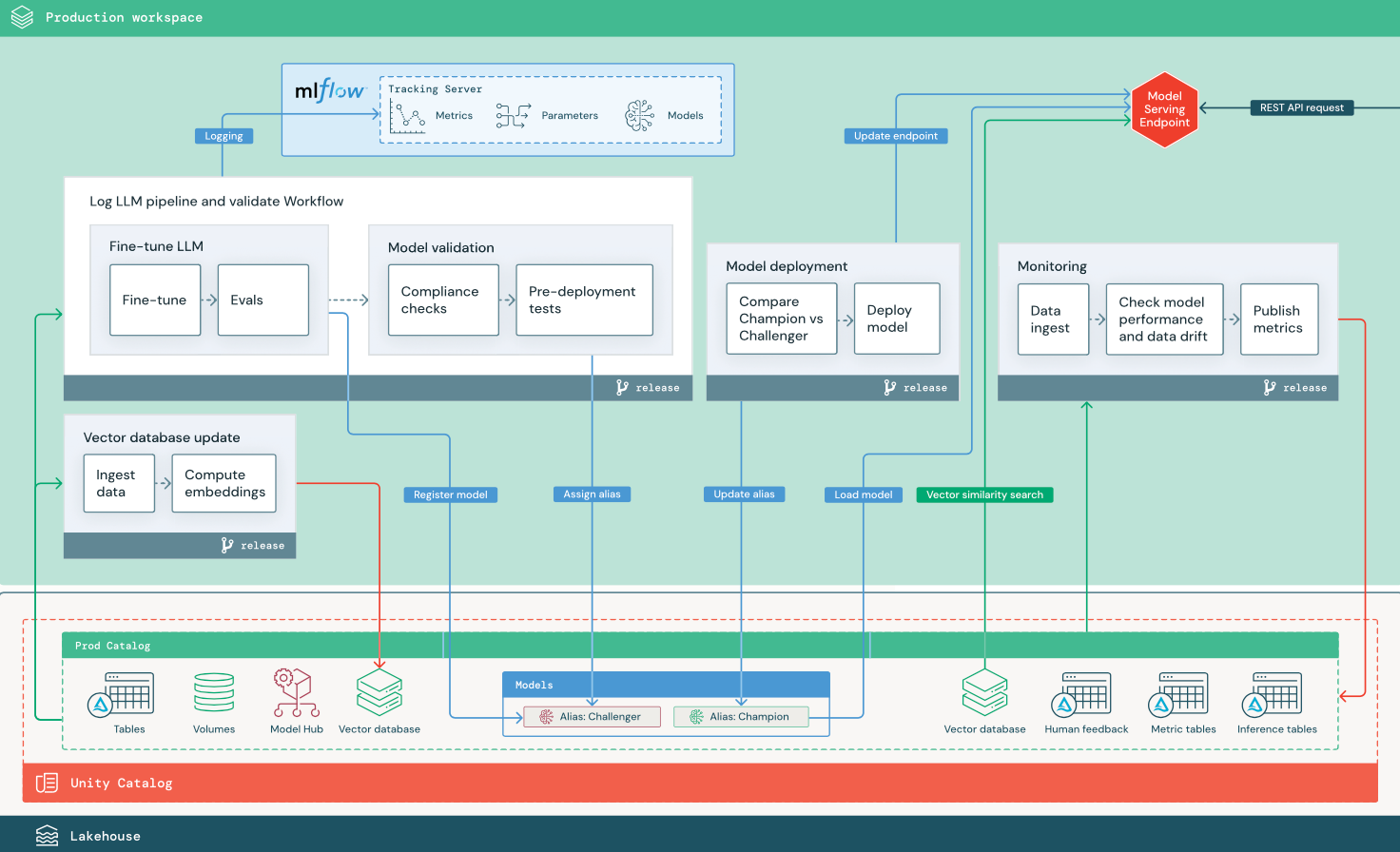
微調整されたオープンソースモデルによるRAG
この図は、オープンソースモデルを微調整するRAGアプリケーションの本番運用アーキテクチャを示しています。
LLMOpsの MLOps 本番運用アーキテクチャの変更
このセクションでは、LLMOps アプリケーションの MLOps リファレンス アーキテクチャの主な変更点について説明します。
モデルハブ
LLM アプリケーションでは、多くの場合、内部または外部のモデル ハブから選択された既存の事前トレーニング済みモデルが使用されます。 モデルはそのまま使用することも、微調整することもできます。
DatabricksはUnity CatalogとDatabricks Marketplaceに含まれる高品質の事前トレーニングされた基盤モデルが含まれています。 これらの事前トレーニング済みモデルを使用すると最先端の AI 機能にアクセスでき、独自のカスタム モデルを構築する時間と費用を節約できます。詳細については、 Unity CatalogからAIおよびLLMモデルを生成する」を参照してください。
ベクトル インデックス
一部のLLMアプリケーションは、高速な類似性検索のためにベクトルインデックスを使用します。たとえば、LLMクエリでコンテキストやドメイン知識を提供するためです。Databricks は、統合された AI 検索機能を提供しており、Unity Catalog 内の任意の Delta テーブルをインデックスとして利用できます。AI検索インデックスは Delta テーブルと自動的に同期します。詳細については、「 AI検索」を参照してください。
AI検索インデックスから情報を取得するロジックをカプセル化し、返されたデータをコンテキストとしてLLMに提供するモデル アーティファクトを作成できます。その後、MLflowのLangChain または PyFunc モデル フレーバーを使用してモデルをログに記録できます。
LLM の微調整
LLM モデルはゼロから作成するにはコストと時間がかかるため、LLM アプリケーションでは、特定のシナリオでのパフォーマンスを向上させるために、既存のモデルを微調整することがよくあります。リファレンス アーキテクチャでは、ファインチューニングとモデル デプロイは個別の Lakeflow ジョブとして表されます。 デプロイする前に微調整されたモデルを検証することは、多くの場合、手動のプロセスです。
Databricks には、独自のデータを使用して既存の LLM をカスタマイズし、特定のアプリケーションに合わせてパフォーマンスを最適化できる基盤モデル ファインチューニングが用意されています。 詳細については、 基盤モデル ファインチューニングを参照してください。
モデルサービング
サードパーティ の シナリオを使用する RAGAPI では、アーキテクチャの重要な変更点として、LLM パイプラインがモデルサービングAPI エンドポイントから内部またはサードパーティの への外部LLMAPI 呼び出しを行うことが重要です。これにより、複雑さ、潜在的な遅延、および追加の資格情報管理が追加されます。
Databricksは、AIモデルのデプロイ、管理、クエリを実行するための統一されたインターフェースを提供するモデルサービングを提供しています。詳細についてはモデルサービングを参照してください。
モニタリングと評価における人間のフィードバック
人間のフィードバックループは、ほとんどのLLMアプリケーションで不可欠です。 人間のフィードバックは、他のデータと同様に管理する必要があり、理想的には、ニアリアルタイム ストリーミングに基づくモニタリングに組み込む必要があります。
MLflow レビューアプリは、人間のレビュアーからフィードバックを収集するのに役立ちます。詳細については、MLflow での人間によるフィードバックを参照してください。