メトリクス ビューのマテリアライゼーション
実験段階
この機能は実験的なものです。
この記事では、メトリクス ビューのマテリアライゼーションを使用してクエリのパフォーマンスを高速化する方法について説明します。
メトリクス ビューのマテリアライゼーションは、マテリアライズドビューを使用してクエリを高速化します。 LakeFlow Spark宣言型パイプラインは、特定のメトリクス ビューのユーザー定義のマテリアライズドビューを調整します。 クエリ時に、クエリ オプティマイザーは、自動集計認識クエリ マッチング (クエリ リライトとも呼ばれます) を使用して、メトリクス ビュー上のユーザー クエリを最適なマテリアライズドビューにインテリジェントにルーティングします。
このアプローチには、事前計算と自動増分更新の利点があるため、さまざまなパフォーマンス目標に対してどの集計テーブルまたはマテリアライズドビューをクエリするかを決定する必要がなく、個別の本番運用パイプラインを管理する必要がなくなります。
概要
次の図は、メトリクス ビューが定義とクエリの実行をどのように処理するかを示しています。
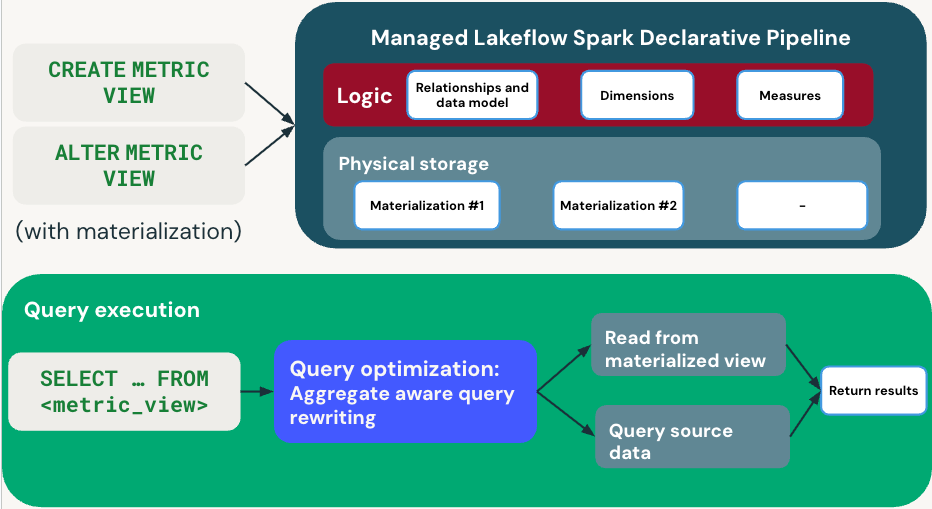
定義フェーズ
マテリアライゼーションを使用してメトリクス ビューを定義する場合、 CREATE METRIC VIEWまたはALTER METRIC VIEWディメンション、メジャー、更新スケジュールを指定します。 Databricks 、マテリアライズ ド ビューを維持する管理されたパイプラインを作成します。
クエリ実行
SELECT ... FROM <metric_view>を実行すると、クエリ オプティマイザーは集計を考慮したクエリ書き換えを使用してパフォーマンスを最適化します。
- 高速パス : 該当する場合、コンピュート前のマテリアライズドビューから読み取ります。
- フォールバック パス : マテリアライゼーションが利用できない場合にソース データから直接読み取ります。
クエリ オプティマイザーは、マテリアライズド データとソース データを選択して、パフォーマンスと鮮度のバランスを自動的に調整します。どのパスが使用されるかに関係なく、結果は透過的に受け取られます。
要件
メトリクス ビューにマテリアライゼーションを使用するには、次の手順を実行します。
- ワークスペースではサーバレス コンピュートが有効になっている必要があります。 これはLakeFlow Spark宣言型パイプラインを実行するために必要です。
- Databricks Runtime 17.2 以上。
構成リファレンス
マテリアライゼーションに関連するすべての情報は、メトリクス ビューの YAML 定義のmaterializationという名前の最上位フィールドで定義されます。
materializationフィールドには次の必須フィールドが含まれています:
- スケジュール :マテリアライズドビューのスケジュール句と同じ構文をサポートします。
- モード :
relaxedに設定する必要があります。 - materialized_views : マテリアライズするマテリアライズドビューのリスト。
- name : マテリアライゼーションの名前。
- ディメンション : 実現するディメンションのリスト。ディメンション名への直接参照のみが許可され、式はサポートされていません。
- メジャー : マテリアライズするメジャーのリスト。メジャー名への直接参照のみが許可され、式はサポートされていません。
- type : マテリアライズドビューが集約されるかどうかを指定します。 2 つの値
aggregatedとunaggregatedが受け入れられます。typeがaggregatedの場合、少なくとも 1 つのディメンションまたはメジャーが必要です。typeがunaggregatedの場合、ディメンションまたはメジャーを定義する必要はありません。
TRIGGER ON UPDATE句は、メトリクス ビューのマテリアライゼーションではサポートされていません。
定義例
version: 1.1
source: prod.operations.orders_enriched_view
filter: revenue > 0
dimensions:
- name: category
expr: substring(category, 5)
- name: color
expr: color
measures:
- name: total_revenue
expr: SUM(revenue)
- name: number_of_suppliers
expr: COUNT(DISTINCT supplier_id)
materialization:
schedule: every 6 hours
mode: relaxed
materialized_views:
- name: baseline
type: unaggregated
- name: revenue_breakdown
type: aggregated
dimensions:
- category
- color
measures:
- total_revenue
- name: suppliers_by_category
type: aggregated
dimensions:
- category
measures:
- number_of_suppliers
モード
relaxedモードでは、自動クエリ リライトは、候補マテリアライズドビューにクエリを処理するために必要なディメンションとメジャーがあるかどうかのみを検証します。
これは、いくつかのチェックがスキップされることを意味します。
- マテリアライズドビューが最新であるかどうかのチェックはありません。
- 一致する SQL 設定 (たとえば、
ANSI_MODEまたはTIMEZONE) があるかどうかのチェックはありません。 - マテリアライズドビューが決定的な結果を返すかどうかのチェックはありません。
クエリに次のいずれかの条件が含まれている場合、クエリの書き換えは行われず、クエリはソース テーブルにフォールバックします。
- マテリアライズドビューの行レベルのセキュリティ (RLS)または列レベルのマスキング (CLM) 。
- マテリアライズドビューの
current_timestamp()のような非決定的関数。 これらは、メトリクス ビュー定義またはメトリクス ビューで使用されるソース テーブルに表示される場合があります。
試験的なリリース期間中は、 relaxedのみがサポートされるモードです。これらのチェックが失敗した場合、クエリはソース データにフォールバックします。
メトリクス ビューのマテリアライゼーションのタイプ
次のセクションでは、メトリクス ビューで使用できるマテリアライズドビューのタイプについて説明します。
集約型
このタイプは、ターゲット カバレッジの指定されたメジャーとディメンションの組み合わせに対する事前コンピュート集計を行います。
これは、特定の一般的な集計クエリ パターンまたはウィジェットをターゲットにする場合に役立ちます。Databricksでは、潜在的なフィルター列をマテリアライズドビュー構成のディメンションとして含めることをお勧めします。 潜在的なフィルター列は、 WHERE句のクエリ時に使用される列です。
非集約型
このタイプは、集約型と比較してパフォーマンスの向上が少なく、より広い範囲をカバーするために、集約されていないデータ モデル全体 (たとえば、 source 、 join 、 filterフィールド) を具体化します。
次の条件に当てはまる場合は、このタイプを使用します。
- ソースはコストのかかるビューまたは SQL クエリです。
- メトリクス ビューで定義された結合は高価です。
ソースが選択フィルターが適用されていない直接テーブル参照である場合、未集計のマテリアライズドビューでは利点が得られない可能性があります。
具体化ライフサイクル
このセクションでは、マテリアライゼーションがライフサイクル全体を通じてどのように作成、管理、更新されるかについて説明します。
作成と変更
メトリクス ビューの作成または変更 ( CREATE 、 ALTER 、または Catalog Explorer を使用) は同期的に行われます。 指定されたマテリアライズドビューは、 LakeFlow Spark宣言型パイプラインを使用して非同期に実体化されます。
メトリクス ビューを作成すると、 Databricks LakeFlow Spark宣言型パイプライン パイプラインを作成し、マテリアライズドビューが指定されている場合はすぐに初期更新をスケジュールします。 メトリクス ビューは、ソース データからのクエリにフォールバックすることで、実体化なしでもクエリ可能のままです。
メトリクス ビューを変更する場合、初めてマテリアライゼーションを有効にする場合を除き、新しい更新はスケジュールされません。 マテリアライズドビューは、次にスケジュールされた更新が完了するまで、自動クエリ リライトには使用されません。
実現化スケジュールを変更しても更新はトリガーされません。
更新動作をより細かく制御するには、 「手動更新」を参照してください。
基礎となるパイプラインを検査する
メトリクス ビューの具体化は、 LakeFlow Spark宣言型パイプラインを使用して実装されます。 パイプラインへのリンクは、カタログ エクスプローラーの 概要 タブに表示されます。カタログ エクスプローラーにアクセスする方法については、 「カタログ エクスプローラーとは」を参照してください。
メトリクス ビューでDESCRIBE EXTENDEDを実行して、このパイプラインにアクセスすることもできます。 更新情報 セクションには、パイプラインへのリンクが含まれています。
DESCRIBE EXTENDED my_metric_view;
出力例:
-- Returns additional metadata such as parent schema, owner, access time etc.
> DESCRIBE TABLE EXTENDED customer;
col_name data_type comment
------------------------------- ------------------------------ ----------
... ... ...
# Detailed Table Information
... ...
Language YAML
Table properties ...
# Refresh information
Latest Refresh status Succeeded
Latest Refresh https://...
Refresh Schedule EVERY 3 HOURS
手動更新
LakeFlow Spark宣言型パイプライン ページへのリンクから、パイプラインの更新を手動で開始して具体化を更新できます。 次の SQL コマンドを使用して手動で更新をトリガーすることもできます。
REFRESH MATERIALIZED VIEW <metric-view-name>
増分更新
マテリアライズドビューは可能な限り増分更新を使用し、データ ソースと計画構造に関して同じ制限があります。
前提条件と制限の詳細については、 「マテリアライズドビューの増分更新」を参照してください。
自動クエリ書き換え
マテリアライゼーションを含むメトリクス ビューへのクエリでは、そのマテリアライゼーションを可能な限り使用しようとします。 クエリ書き換え戦略には、完全一致と非集約一致の 2 つがあります。

Metricus ビューをクエリすると、オプティマイザーはクエリと使用可能なユーザー定義のマテリアライゼーションを分析します。 クエリは、次のアルゴリズムを使用して、ベース テーブルではなく最適なマテリアライゼーションで自動的に実行されます。
- まず完全一致を試みます。
- 集約されていないマテリアライゼーションが存在する場合は、集約されていない一致を試行します。
- クエリの書き換えに失敗した場合、クエリはソース テーブルから直接読み取ります。
クエリの書き換えを有効にするには、マテリアライゼーションが完了する必要があります。
クエリがマテリアライズドビューを使用していることを確認する
クエリがマテリアライズドビューを使用しているかどうかを確認するには、クエリに対してEXPLAIN EXTENDEDを実行してクエリ プランを確認します。 クエリがマテリアライズドビューを使用している場合、リーフ ノードには__materialization_mat___metric_viewと YAML ファイルからのマテリアライゼーションの名前が含まれます。
あるいは、クエリ プロファイルにも同じ情報が表示されます。
完全一致
完全一致戦略の対象となるには、クエリのグループ化式がマテリアライズド ディメンションと正確に一致している必要があります。クエリの集計式は、マテリアライゼーションメジャーのサブセットである必要があります。
未集計のマッチ
集約されていないマテリアライゼーションが利用可能な場合、この戦略は常に適格です。
課金
マテリアライズドビューを更新すると、 LakeFlow Spark宣言型パイプラインの利用料金が発生します。
既知の制限
メトリクス ビューのマテリアライゼーションには次の制限が適用されます。
- 別のメトリクス ビューをソースとして参照する実体化を含むメトリクス ビューは、未集約のマテリアライゼーションを持つことができません。