ワークスペースモデルレジストリ 例
このドキュメントでは、ワークスペースモデルレジストリについて説明します。 Databricksでは、Unity Catalog のモデルを使用することをお勧めします。 Unity Catalog のモデルは、一元化されたモデル ガバナンス、ワークスペース間のアクセス、リネージ、デプロイを提供します。ワークスペースモデルレジストリ は、今後廃止される予定です。
この例では、ワークスペースモデルレジストリ を使用して、風力発電所の日次電力出力を予測する機械学習アプリケーションを構築する方法を示します。 この例では、次の方法を示しています。
- MLflowによるモデルの追跡と記録
- モデルレジストリ付きモデルとして登録する
- モデルの説明とモデルバージョンのステージの移行
- 登録したモデルを本番運用アプリケーションと統合
- モデルレジストリ内のモデルの検索と発見
- モデルのアーカイブと削除
この記事では、 MLflow Tracking と MLflow モデルレジストリ UI と APIを使用してこれらの手順を実行する方法について説明します。
MLflow Tracking と Registry APIを使用してこれらすべての手順を実行するノートブックについては、モデルレジストリのサンプルノートブックを参照してください。
MLflow Tracking を使用したデータセットの読み込み、モデルのトレーニング、追跡
モデルレジストリにモデルを登録するにはまず、エクスペリメントの実行 中にモデルを学習させ、記録する必要があります。このセクションでは、風力発電所のデータセットを読み込み、モデルをトレーニングし、トレーニングの実行を MLflow に記録する方法を示します。
データセットの読み込み
次のコードは、米国の風力発電所の気象データと電力出力情報を含むデータセットを読み込みます。 データセットには、数年にわたって 6 00:00時間ごとにサンプリングされた wind direction、wind speed、air temperature フィーチャと、08:00``16:00に 1 つずつサンプリングされたフィーチャと、1 日の総電力出力 (power) が含まれています。
import pandas as pd
wind_farm_data = pd.read_csv("https://github.com/dbczumar/model-registry-demo-notebook/raw/master/dataset/windfarm_data.csv", index_col=0)
def get_training_data():
training_data = pd.DataFrame(wind_farm_data["2014-01-01":"2018-01-01"])
X = training_data.drop(columns="power")
y = training_data["power"]
return X, y
def get_validation_data():
validation_data = pd.DataFrame(wind_farm_data["2018-01-01":"2019-01-01"])
X = validation_data.drop(columns="power")
y = validation_data["power"]
return X, y
def get_weather_and_forecast():
format_date = lambda pd_date : pd_date.date().strftime("%Y-%m-%d")
today = pd.Timestamp('today').normalize()
week_ago = today - pd.Timedelta(days=5)
week_later = today + pd.Timedelta(days=5)
past_power_output = pd.DataFrame(wind_farm_data)[format_date(week_ago):format_date(today)]
weather_and_forecast = pd.DataFrame(wind_farm_data)[format_date(week_ago):format_date(week_later)]
if len(weather_and_forecast) < 10:
past_power_output = pd.DataFrame(wind_farm_data).iloc[-10:-5]
weather_and_forecast = pd.DataFrame(wind_farm_data).iloc[-10:]
return weather_and_forecast.drop(columns="power"), past_power_output["power"]
モデルのトレーニング
次のコードは、TensorFlow Keras を使用してニューラルネットワークをトレーニングし、データセット内の気象特徴に基づいて電力出力を予測します。MLflow は、モデルのハイパーパラメーター、パフォーマンスメトリクス、ソース コード、およびアーティファクトを追跡するために使用されます。
def train_keras_model(X, y):
import tensorflow.keras
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense
model = Sequential()
model.add(Dense(100, input_shape=(X_train.shape[-1],), activation="relu", name="hidden_layer"))
model.add(Dense(1))
model.compile(loss="mse", optimizer="adam")
model.fit(X_train, y_train, epochs=100, batch_size=64, validation_split=.2)
return model
import mlflow
X_train, y_train = get_training_data()
with mlflow.start_run():
# Automatically capture the model's parameters, metrics, artifacts,
# and source code with the `autolog()` function
mlflow.tensorflow.autolog()
train_keras_model(X_train, y_train)
run_id = mlflow.active_run().info.run_id
MLflow UIを使用してモデルを登録および管理
このセクションの内容:
新しい登録済みモデルを作成する
-
ノートブックの右側のサイドバーにある MLflowエクスペリメント アイコン をクリックして、 エクスペリメント 実行サイドバーに移動します。
 Databricks
Databricks
-
TensorFlow Kerasモデル トレーニング セッションに対応する MLflowランを見つけ、MLflow ラン UI で ランの詳細を参照 アイコンをクリックして開きます。
-
MLflow UI で、 アーティファクト セクションまで下にスクロールし、 model という名前のディレクトリをクリックします。表示される モデルを登録する ボタンをクリックします。

-
ドロップダウンメニューから 新規モデルの作成 を選択し、モデル名「
power-forecasting-model」を入力します。 -
登録する をクリックします。これにより、
power-forecasting-modelという新しいモデルが登録され、Version 1という新しいモデル バージョンが作成されます。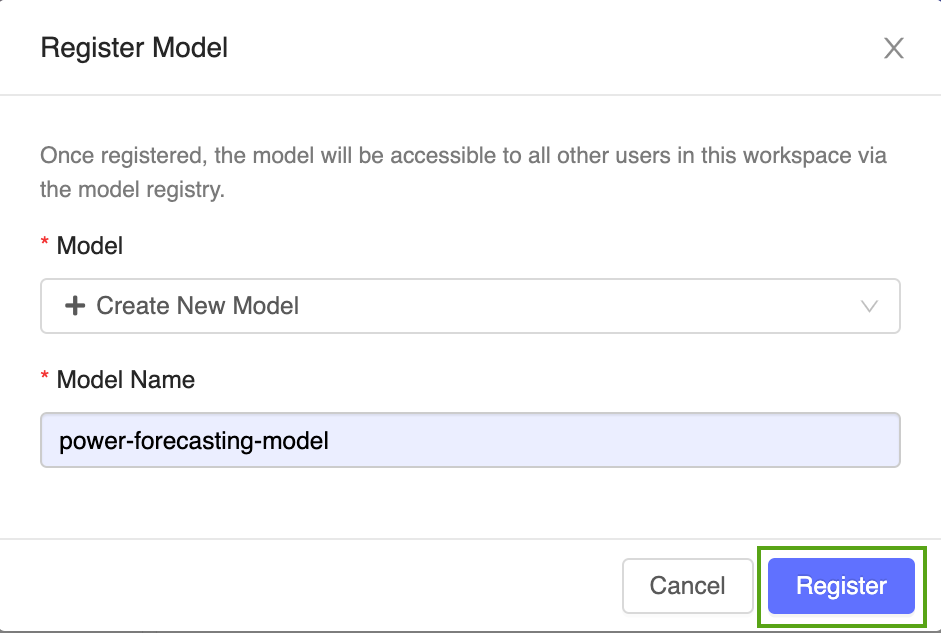
しばらくすると、MLflow UI に新しく登録されたモデルへのリンクが表示されます。 このリンクをたどると、新しいモデル バージョンが MLflow モデルレジストリ UI で開きます。
モデルレジストリ UI の探索
MLflow モデルレジストリ UI のモデル バージョン ページには、登録された予測モデルのVersion 1に関する情報 (作成者、作成時間、現在のステージなど) が表示されます。
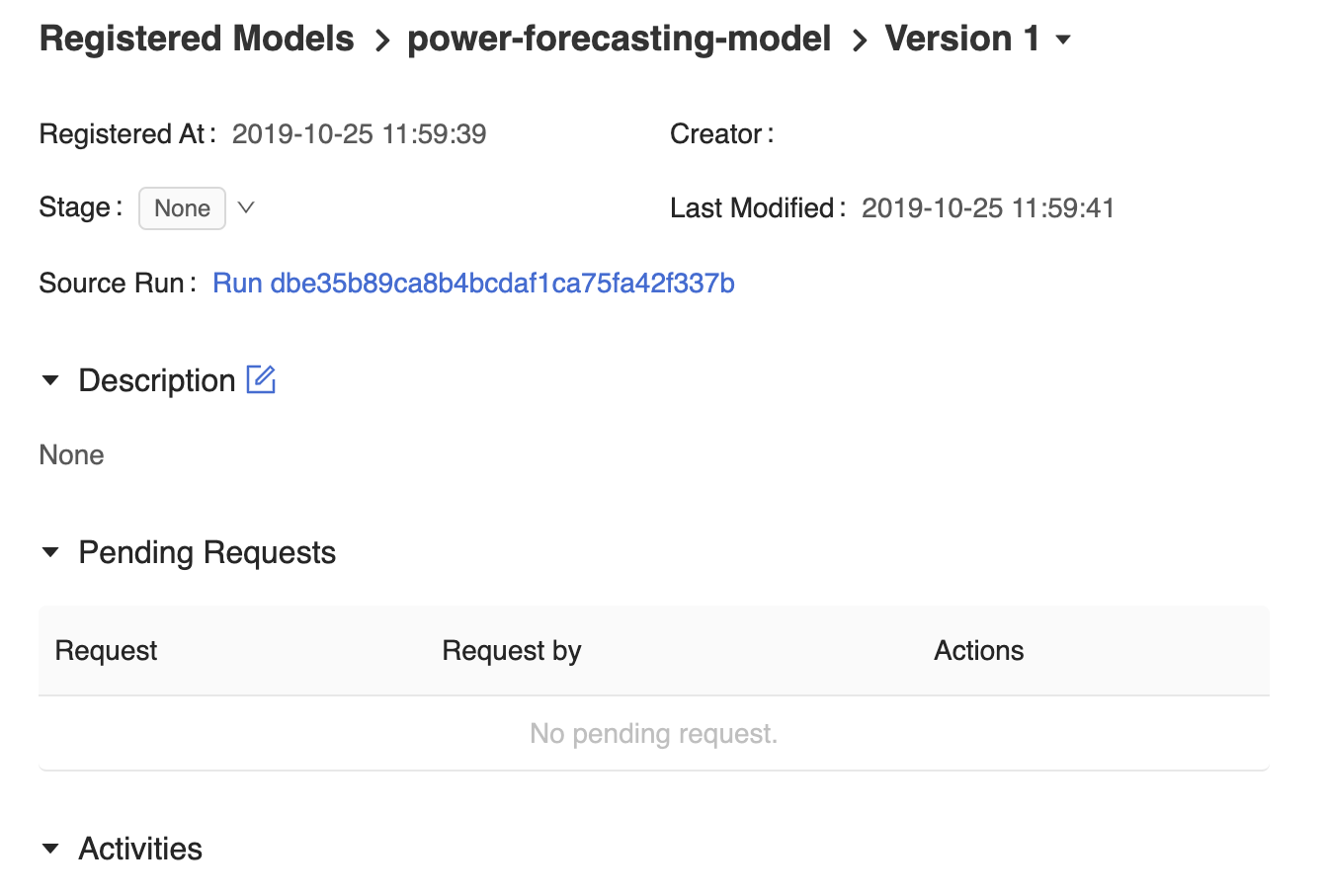
モデル バージョン ページには、MLflowランUIでモデルの作成に使用されたMLflowランを開く ソースラン リンクもあります。MLflow のラン UI から ソース ノートブックリンクにアクセスして、モデルのトレーニングに使用された Databricks ノートブックのスナップショットを表示できます。


MLflow モデルレジストリに戻るには、サイドバーの![]() モデル をクリックします。
モデル をクリックします。
表示される MLflow モデルレジストリ ホーム ページには、 Databricks ワークスペースに登録されているすべてのモデルの一覧 (バージョンとステージを含む) が表示されます。
power-forecasting-model リンクをクリックして登録済みモデル ページを開くと、予測モデルのすべてのバージョンが表示されます。
モデルの説明を追加する
登録済みのモデルとモデルバージョンに説明を追加できます。 登録されたモデルの説明は、複数のモデルバージョンに適用される情報(モデリング問題とデータセットの一般的な概要など)を記録するのに役立ちます。 モデルバージョンの説明は、特定のモデルバージョンの固有の属性(モデルの開発に使用された方法論やアルゴリズムなど)を詳しく説明するのに役立ちます。
-
登録した電力予測モデルに高レベルの説明を追加します。
 アイコンをクリックし、次の説明を入力します。
アイコンをクリックし、次の説明を入力します。This model forecasts the power output of a wind farm based on weather data. The weather data consists of three features: wind speed, wind direction, and air temperature.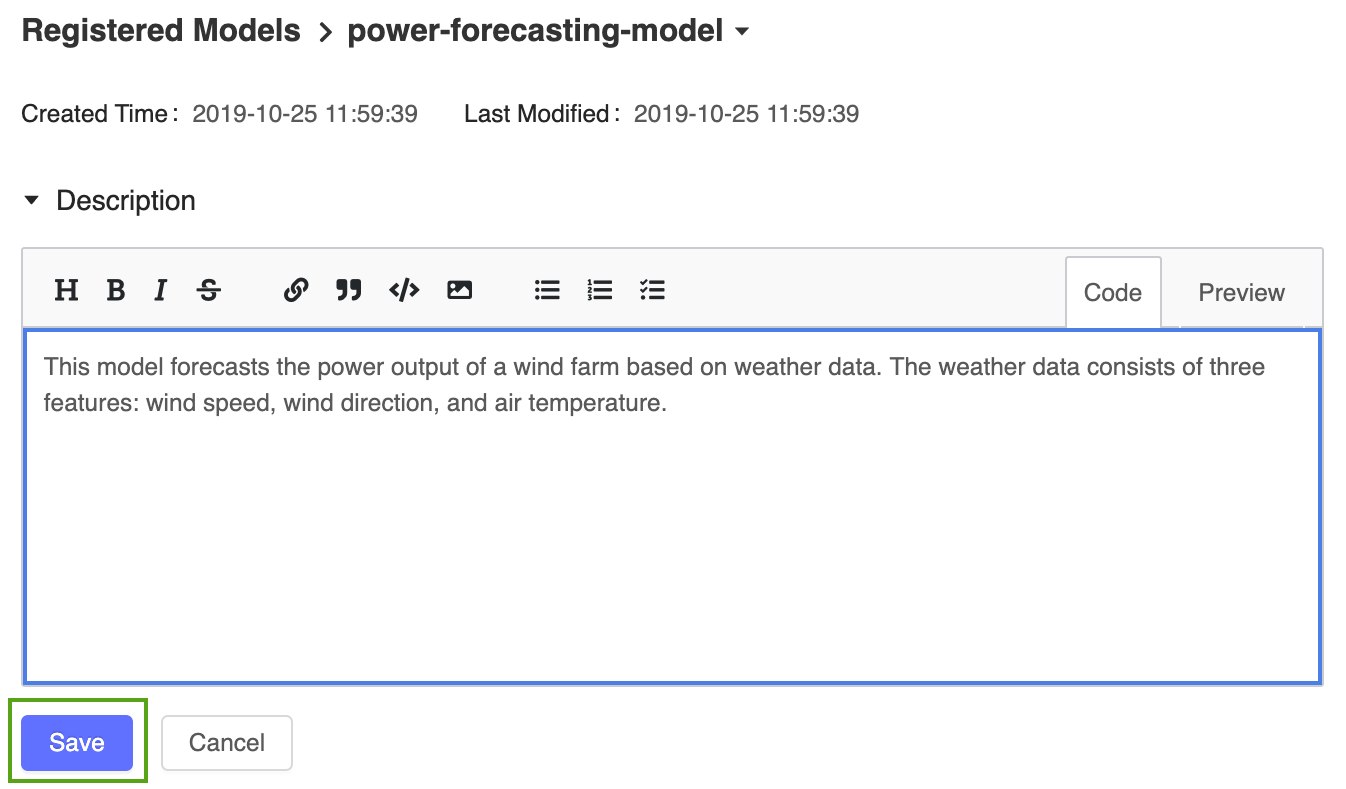
-
[ 保存 ]をクリックします。
-
登録済みのモデルページから バージョン1 リンクをクリックして、モデルバージョンページに戻ります。
-
アイコンをクリックし、次の説明を入力します。
This model version was built using TensorFlow Keras. It is a feed-forward neural network with one hidden layer.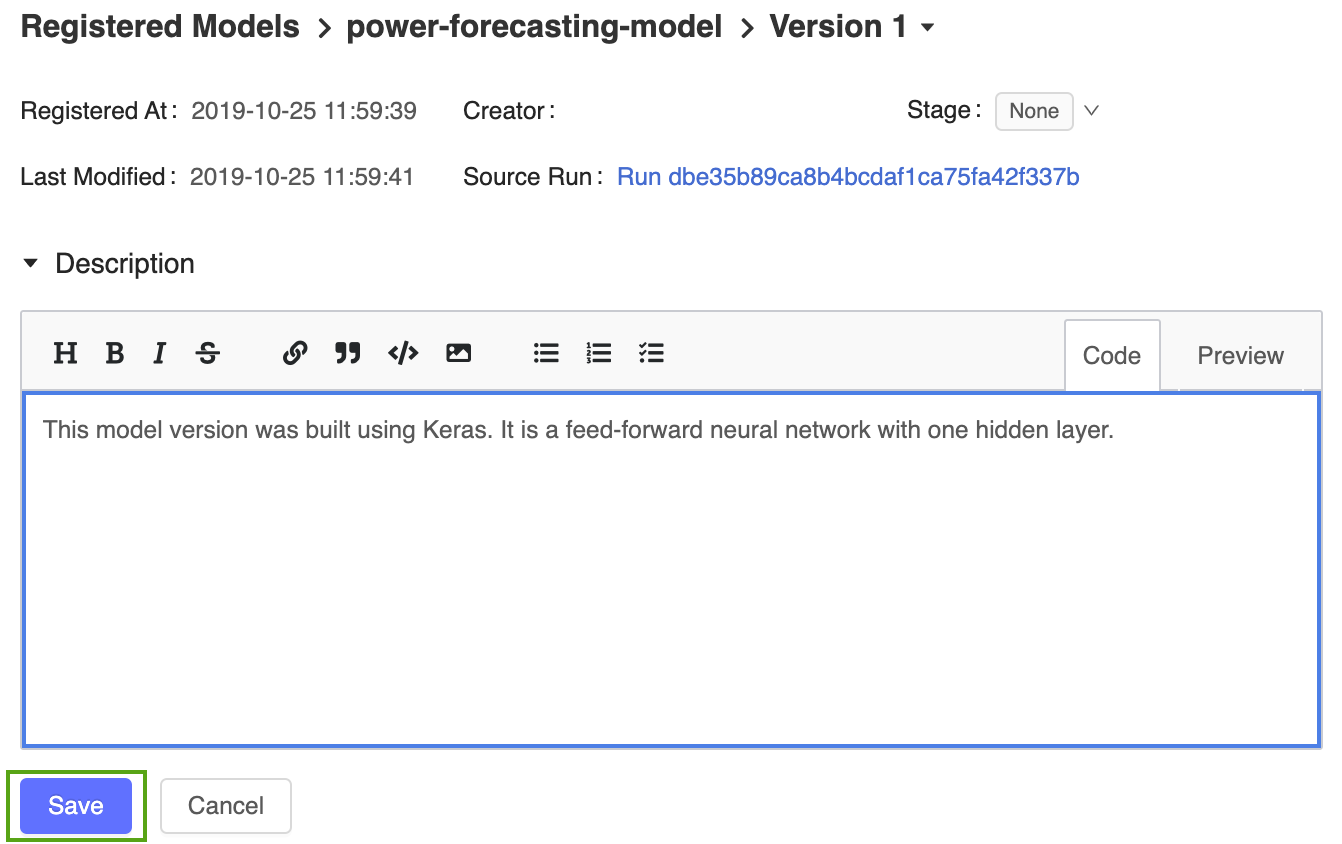
-
[ 保存 ]をクリックします。
モデルバージョンの移行
この MLflow モデルレジストリ では、 None 、 Staging 、 Production 、Archivedといういくつかのモデルステージが定義されています。 各ステージには独自の意味があります。 たとえば、 Staging は モデル テスト用であり、 Production はテストまたはレビュー プロセスを完了し、アプリケーションにデプロイされたモデル用です。
-
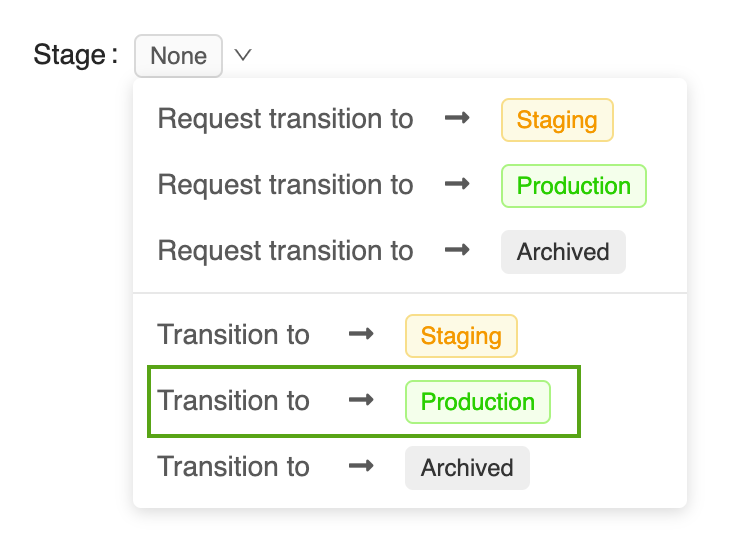
ステージ ボタンをクリックすると、使用可能なモデル・ステージのリストと、使用可能なステージの移行オプションが表示されます。
-
本番運用への移行 を選択し、ステージの移行確認画面で OK を押すと、 モデルを本番運用 に移行できます。
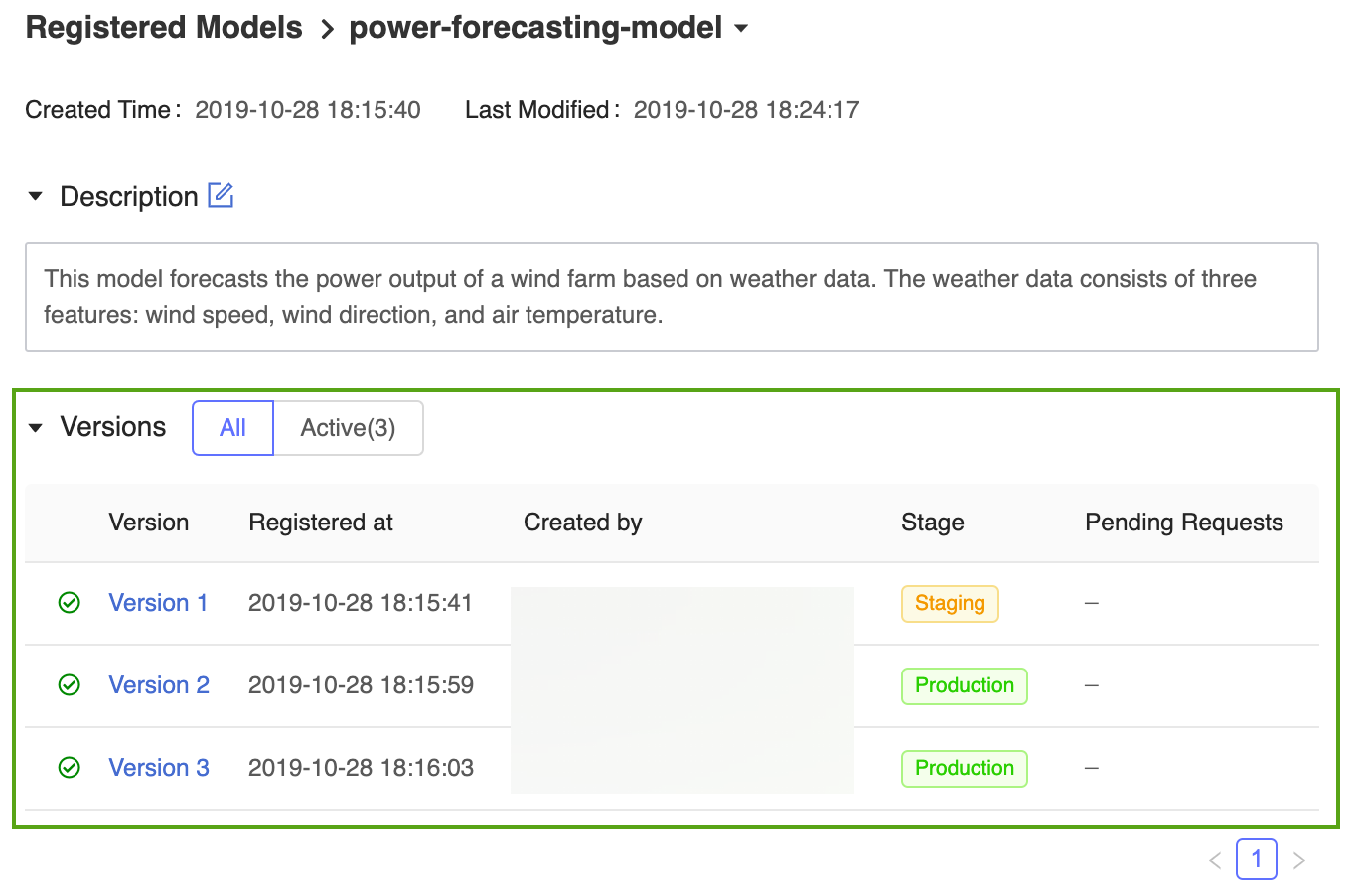
モデル版を 本番運用 に移行すると、UIに現在のステージが表示され、アクティビティログにその移行を反映したエントリが追加されます。


この MLflow モデルレジストリ では、複数のモデルバージョンで同じステージを共有できます。 ステージごとにモデルを参照する場合、 モデルレジストリ は最新のモデル バージョン (バージョン ID が最大のモデル バージョン) を使用します。 登録済みモデルページには、特定のモデルのすべてのバージョンが表示されます。
MLflow APIを使用してモデルを登録および管理
このセクションの内容:
モデルの名前をプログラムで定義する
モデルが登録され、 本番運用 に移行したので、プログラマティック を使用して参照 MLflowAPIことができます。登録したモデルの名前を次のように定義します。
model_name = "power-forecasting-model"
モデルを登録する
model_name = get_model_name()
import mlflow
# The default path where the MLflow autologging function stores the TensorFlow Keras model
artifact_path = "model"
model_uri = "runs:/{run_id}/{artifact_path}".format(run_id=run_id, artifact_path=artifact_path)
model_details = mlflow.register_model(model_uri=model_uri, name=model_name)
import time
from mlflow.tracking.client import MlflowClient
from mlflow.entities.model_registry.model_version_status import ModelVersionStatus
# Wait until the model is ready
def wait_until_ready(model_name, model_version):
client = MlflowClient()
for _ in range(10):
model_version_details = client.get_model_version(
name=model_name,
version=model_version,
)
status = ModelVersionStatus.from_string(model_version_details.status)
print("Model status: %s" % ModelVersionStatus.to_string(status))
if status == ModelVersionStatus.READY:
break
time.sleep(1)
wait_until_ready(model_details.name, model_details.version)
API を使用してモデルとモデル バージョンの説明を追加する
from mlflow.tracking.client import MlflowClient
client = MlflowClient()
client.update_registered_model(
name=model_details.name,
description="This model forecasts the power output of a wind farm based on weather data. The weather data consists of three features: wind speed, wind direction, and air temperature."
)
client.update_model_version(
name=model_details.name,
version=model_details.version,
description="This model version was built using TensorFlow Keras. It is a feed-forward neural network with one hidden layer."
)
API を使用してモデル バージョンを移行し、詳細を取得する
client.transition_model_version_stage(
name=model_details.name,
version=model_details.version,
stage='production',
)
model_version_details = client.get_model_version(
name=model_details.name,
version=model_details.version,
)
print("The current model stage is: '{stage}'".format(stage=model_version_details.current_stage))
latest_version_info = client.get_latest_versions(model_name, stages=["production"])
latest_production_version = latest_version_info[0].version
print("The latest production version of the model '%s' is '%s'." % (model_name, latest_production_version))
API を使用して登録済みモデルのバージョンを読み込みます
MLflow モデル コンポーネントでは、複数の機械学習フレームワークからモデルを読み込むための関数が定義されています。 たとえば、 mlflow.tensorflow.load_model() は MLflow 形式で保存された TensorFlow モデルを読み込むために使用され、 mlflow.sklearn.load_model() は MLflow 形式で保存された scikit-learn モデルを読み込むために使用されます。
これらの関数は、 MLflow モデルレジストリからモデルを読み込むことができます。
import mlflow.pyfunc
model_version_uri = "models:/{model_name}/1".format(model_name=model_name)
print("Loading registered model version from URI: '{model_uri}'".format(model_uri=model_version_uri))
model_version_1 = mlflow.pyfunc.load_model(model_version_uri)
model_production_uri = "models:/{model_name}/production".format(model_name=model_name)
print("Loading registered model version from URI: '{model_uri}'".format(model_uri=model_production_uri))
model_production = mlflow.pyfunc.load_model(model_production_uri)
本番運用モデルによる発電出力の予測
このセクションでは、実稼働モデルを使用して、風力発電所の天気予報データを評価します。 forecast_power() アプリケーションは、指定されたステージから最新バージョンの予測モデルを読み込み、それを使用して今後 5 日間の電力本番運用を予測します。
def plot(model_name, model_stage, model_version, power_predictions, past_power_output):
import pandas as pd
import matplotlib.dates as mdates
from matplotlib import pyplot as plt
index = power_predictions.index
fig = plt.figure(figsize=(11, 7))
ax = fig.add_subplot(111)
ax.set_xlabel("Date", size=20, labelpad=20)
ax.set_ylabel("Power\noutput\n(MW)", size=20, labelpad=60, rotation=0)
ax.tick_params(axis='both', which='major', labelsize=17)
ax.xaxis.set_major_formatter(mdates.DateFormatter('%m/%d'))
ax.plot(index[:len(past_power_output)], past_power_output, label="True", color="red", alpha=0.5, linewidth=4)
ax.plot(index, power_predictions.squeeze(), "--", label="Predicted by '%s'\nin stage '%s' (Version %d)" % (model_name, model_stage, model_version), color="blue", linewidth=3)
ax.set_ylim(ymin=0, ymax=max(3500, int(max(power_predictions.values) * 1.3)))
ax.legend(fontsize=14)
plt.title("Wind farm power output and projections", size=24, pad=20)
plt.tight_layout()
display(plt.show())
def forecast_power(model_name, model_stage):
from mlflow.tracking.client import MlflowClient
client = MlflowClient()
model_version = client.get_latest_versions(model_name, stages=[model_stage])[0].version
model_uri = "models:/{model_name}/{model_stage}".format(model_name=model_name, model_stage=model_stage)
model = mlflow.pyfunc.load_model(model_uri)
weather_data, past_power_output = get_weather_and_forecast()
power_predictions = pd.DataFrame(model.predict(weather_data))
power_predictions.index = pd.to_datetime(weather_data.index)
print(power_predictions)
plot(model_name, model_stage, int(model_version), power_predictions, past_power_output)
新しいモデル バージョンを作成する
従来の機械学習技術は、電力予測にも効果的です。 次のコードでは、 scikit-learn を使用してランダム フォレスト モデルをトレーニングし、mlflow.sklearn.log_model() 関数を介して MLflow モデルレジストリ に登録する。
import mlflow.sklearn
from sklearn.ensemble import RandomForestRegressor
from sklearn.metrics import mean_squared_error
with mlflow.start_run():
n_estimators = 300
mlflow.log_param("n_estimators", n_estimators)
rand_forest = RandomForestRegressor(n_estimators=n_estimators)
rand_forest.fit(X_train, y_train)
val_x, val_y = get_validation_data()
mse = mean_squared_error(rand_forest.predict(val_x), val_y)
print("Validation MSE: %d" % mse)
mlflow.log_metric("mse", mse)
# Specify the `registered_model_name` parameter of the `mlflow.sklearn.log_model()`
# function to register the model with the MLflow Model Registry. This automatically
# creates a new model version
mlflow.sklearn.log_model(
sk_model=rand_forest,
artifact_path="sklearn-model",
registered_model_name=model_name,
)
MLflow モデルレジストリ検索を使用して新しいモデルバージョンIDをフェッチします
from mlflow.tracking.client import MlflowClient
client = MlflowClient()
model_version_infos = client.search_model_versions("name = '%s'" % model_name)
new_model_version = max([model_version_info.version for model_version_info in model_version_infos])
wait_until_ready(model_name, new_model_version)
新しいモデル バージョンに説明を追加する
client.update_model_version(
name=model_name,
version=new_model_version,
description="This model version is a random forest containing 100 decision trees that was trained in scikit-learn."
)
新しいモデル バージョンをステージングに移行し、モデルをテストします
モデルを本番運用アプリケーションにデプロイする前に、多くの場合、ステージング環境でテストすることをお勧めします。 次のコードは、新しいモデル バージョンを ステージング に移行し、そのパフォーマンスを評価します。
client.transition_model_version_stage(
name=model_name,
version=new_model_version,
stage="Staging",
)
forecast_power(model_name, "Staging")
新しいモデルバージョンを本番運用にデプロイする
新しいモデル バージョンがステージングで適切に動作することを確認した後、次のコードでモデルを 本番運用 に移行し、「 本番運用モデルによる電力出力の予測 」セクションとまったく同じアプリケーション コードを使用して電力予測を生成します。
client.transition_model_version_stage(
name=model_name,
version=new_model_version,
stage="production",
)
forecast_power(model_name, "production")
現在、 本番運用 ステージには、Kerasモデルで学習したモデルバージョンとscikit-learnで学習させたモデルの 2 つのモデルバージョンがあります。
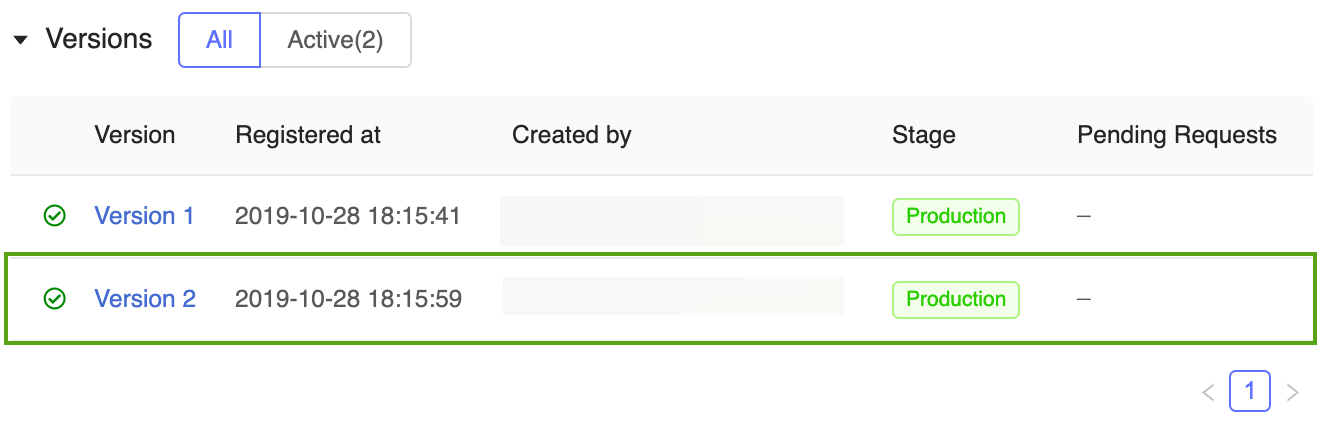
ステージごとにモデルを参照する場合、 MLflow Model モデルレジストリ は自動的に最新の本番運用バージョンを使用します。 これにより、アプリケーションコードを変更せずに本番運用モデルを更新することができます。
モデルをアーカイブして削除する
モデルバージョンが使用されなくなった場合は、アーカイブまたは削除できます。 登録済みモデル全体を削除することもできます。これにより、関連付けられているすべてのモデルバージョンが削除されます。
電力予測モデルのアーカイブVersion 1
電力予測モデルの Version 1 は使用されなくなったためアーカイブします。 モデルは、 MLflow モデルレジストリ UI または MLflow APIを使用してアーカイブできます。
MLflow UI でのアーカイブVersion 1
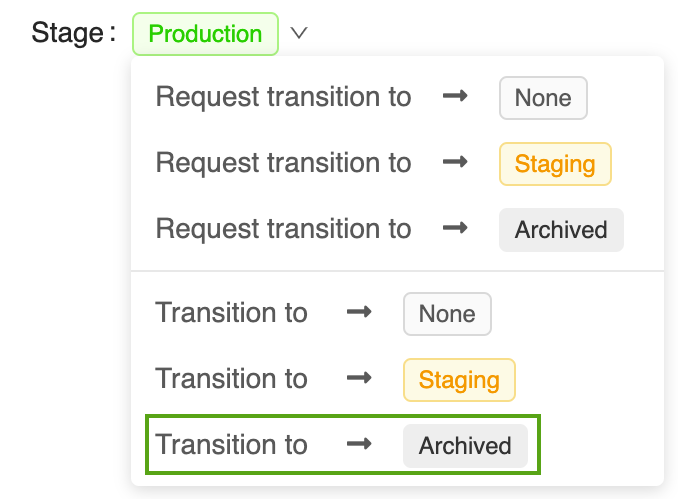
電力予測モデルの Version 1 をアーカイブするには:
-
対応するモデルバージョンページを MLflow モデルレジストリ UIで開きます。
-
ステージ ボタンをクリックし、 アーカイブに移行 を選択します。
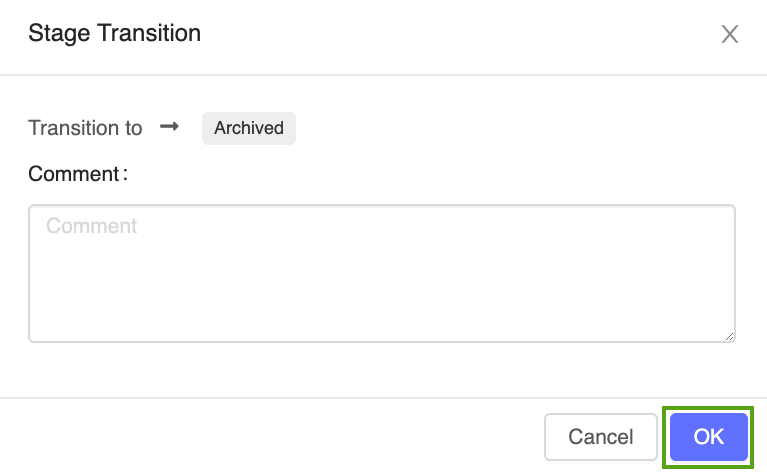
-
ステージの移行確認ウィンドウで OK を押します。

MLflow API を使用したアーカイブVersion 1
次のコードでは、 MlflowClient.update_model_version() 関数を使用して、電力予測モデルの Version 1 アーカイブします。
from mlflow.tracking.client import MlflowClient
client = MlflowClient()
client.transition_model_version_stage(
name=model_name,
version=1,
stage="Archived",
)
電力予測モデルの Version 1 を削除する
MLflow UI または MLflow API を使用して、モデル バージョンを削除することもできます。
モデル バージョンの削除は永続的であり、元に戻すことはできません。
MLflow UI で Version 1 を削除する
電力予測モデルの Version 1 を削除するには:
-
対応するモデルバージョンページを MLflow モデルレジストリ UIで開きます。
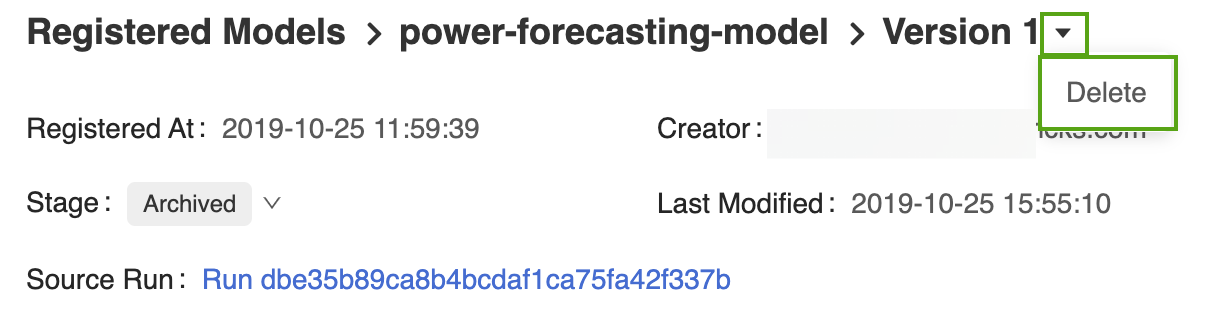
-
バージョン識別子の横にあるドロップダウン矢印を選択し、[ 削除 ] をクリックします。
MLflow API を使用して Version 1 を削除する
client.delete_model_version(
name=model_name,
version=1,
)
MLflow API を使用してモデルを削除する
最初に、残りのすべてのモデル バージョン ステージを なし または アーカイブ済み に移行する必要があります。
from mlflow.tracking.client import MlflowClient
client = MlflowClient()
client.transition_model_version_stage(
name=model_name,
version=2,
stage="Archived",
)
client.delete_registered_model(name=model_name)