AIエージェントの評価と監視
MLflow は、エージェント評価と LLM 評価を提供し、AI アプリケーションの品質を測定、改善、維持するのに役立ちます。MLflow は、LLM、エージェント、RAG システム、その他の生成AIアプリケーションについて、テストから本番運用モニタリングまで、開発ライフサイクル全体をサポートします。
AI エージェントと LLM の評価は、従来の ML モデルの評価よりも複雑です。これらのアプリケーションには、複数のコンポーネント、複数ターンの会話、微妙な品質基準が含まれます。定性的および定量的メトリックスの両方において、パフォーマンスを正確に評価するには専門的な評価アプローチが必要です。
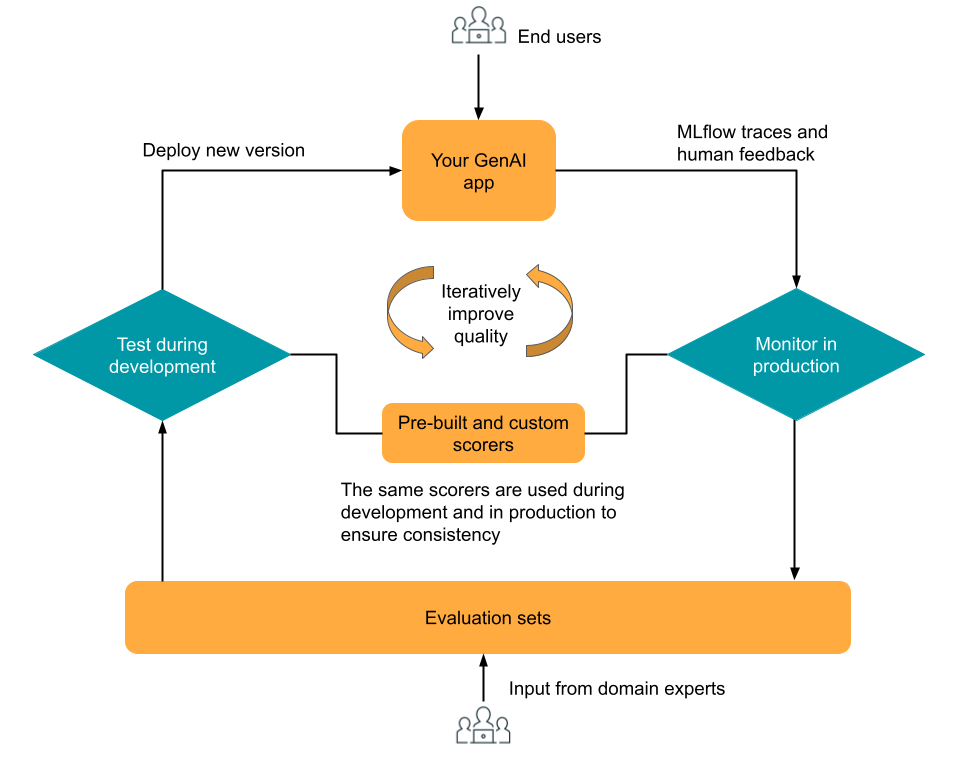
MLflow 3 の評価およびモニタリング コンポーネントは、GenAI アプリの品質を繰り返し最適化できるように設計されています。 評価とモニタリングはMLflow Tracingに基づいて構築されており、開発、テスト、本番運用フェーズでの継続的なトレース ログを提供します。 トレースは、組み込みまたはカスタム ジャッジおよびスコアラーをLLM使用して 開発中に評価 でき、 本番運用モニタリングでは 同じジャッジおよびスコアラーを再利用できるため、アプリケーションのライフサイクル全体を通じて一貫した評価が保証されます。ドメイン専門家は、統合されたレビュー アプリを使用してフィードバックを提供し、人間からのフィードバックを収集して、さらなる反復のための評価データを生成できます。
この図は、この高レベルの反復ワークフローを示しています。
機能 | 説明 |
|---|---|
シンプルな GenAI アプリケーションを使用して MLflow 評価を紹介する簡単なデモ ノートブックを実行します。 | |
シミュレートされた RAG アプリケーションを使用して、完全な評価ワークフローのチュートリアルをステップ実行します。 評価データセットと LLM ジャッジを使用して品質を評価し、問題を特定し、アプリを反復的に改善します。 | |
組み込みLLMジャッジ、カスタムLLMジャッジ、およびカスタム スコアラーを使用して、アプリの品質のメトリクスを定義します。 開発と本番運用の両方に同じメトリクスを使用します。 | |
スコアラーと LLM ジャッジを使用して、評価データセットで GenAI アプリケーションをテストします。アプリのバージョンを比較し、改善を追跡し、結果を共有します。 | |
会話の完全性、ユーザーの不満、対話の一貫性を専門のスコアラーで評価し、複数ターンの会話の品質を評価します。 | |
さまざまなシナリオとユーザーの動作を使用して会話型 AI エージェントをテストするために、合成マルチターン会話を生成できます。 | |
本番運用 GenAI アプリケーション トレース上でスコアラーとLLMジャッジが自動的に実行され、品質を継続的に監視します。 | |
レビュー アプリを使用して専門家のフィードバックを収集し、評価データセットを構築します。 | |
自然言語を使用して評価スコアを確認し、評価データセットを検査し、スケジュールされたスコアラーを確認し、適切なスコアラーで |
エージェント評価は、マネージド MLflow 3 と統合されています。エージェント評価 SDK メソッドは、 mlflow[databricks]>=3.1 SDK を使用して使用できるようになりました。MLflow 3 を使用するように MLflow 2 エージェント評価コードを更新するには、「エージェント評価から MLflow 3 に移行する」を参照してください。