評価データセット参照
MLflow の評価データセットは、GenAI アプリの評価に使用される構造化テストデータを定義します。inputs、オプションのグラウンド トゥルース expectations、およびソースやタグなどのリネージ フィールドです。このページではデータセットスキーマを文書化し、最も頻繁に使用されるSDKメソッドとクラスへのリンクを提供します。
評価データセットの使用方法に関する一般情報および例については、開発中の生成AIアプリの評価を参照してください。
評価データセットスキーマ
評価データセットでは、このセクションで説明されているスキーマを使用する必要があります。
コアフィールド
次のフィールドは、評価データセットの抽象化でも、データを直接渡す場合でも使用されます。
列 | データ型 | 説明 | 必須 |
|---|---|---|---|
|
| アプリの入力 (ユーザーの質問、コンテキストなど) は、JSON 形式で選択可能な | Yes |
|
| グラウンド トゥルース ラベルは、JSON シリアル化可能な | オプション |
expectations 予約済みキー
expectations 組み込み LLM ジャッジによって使用される予約済みキーがいくつかあります: guidelines 、 expected_facts 、およびexpected_response 。
フィールド | 使用者 | 説明 |
|---|---|---|
|
| 表示すべき事実のリスト |
|
| 正確または類似の期待出力 |
|
| 従うべき自然言語のルール |
|
| 取得する必要があるドキュメント |
追加フィールド
次のフィールドは、評価 データセットの抽象化レイヤーによってリネージとバージョン履歴を追跡するために使用されます。
列 | データ型 | 説明 | 必須 |
|---|---|---|---|
| string | レコードの一意の識別子。 | 指定しない場合は自動的に設定されます。 |
| timestamp | レコードが作成された時刻。 | 挿入時や更新時に自動的に設定されます。 |
| string | レコードを作成したユーザー。 | 挿入時や更新時に自動的に設定されます。 |
| timestamp | レコードが最後に更新された時刻。 | 挿入時や更新時に自動的に設定されます。 |
| string | レコードを最後に更新したユーザー。 | 挿入時や更新時に自動的に設定されます。 |
| struct | データセット レコードのソース。ソースフィールドを参照してください。 | オプション |
| dict[str, Any] | データセット レコードのキーと値のタグ。 | オプション |
ソースフィールド
sourceフィールドは、データセット レコードの取得元を追跡します。各レコードには 1 つのソース タイプのみ を含めることができます。
ヒューマンソース : 人が手動で作成したレコード
{
"source": {
"human": {
"user_name": "jane.doe@company.com" # user who created the record
}
}
}
文書ソース : 文書から合成されたレコード
{
"source": {
"document": {
"doc_uri": "s3://bucket/docs/product-manual.pdf", # URI or path to the source document
"content": "The first 500 chars of the document..." # Optional, excerpt or full content from the document
}
}
}
トレースソース : 本番運用トレースから作成されたレコード
{
"source": {
"trace": {
"trace_id": "tr-abc123def456". # unique identifier of the source trace
}
}
}
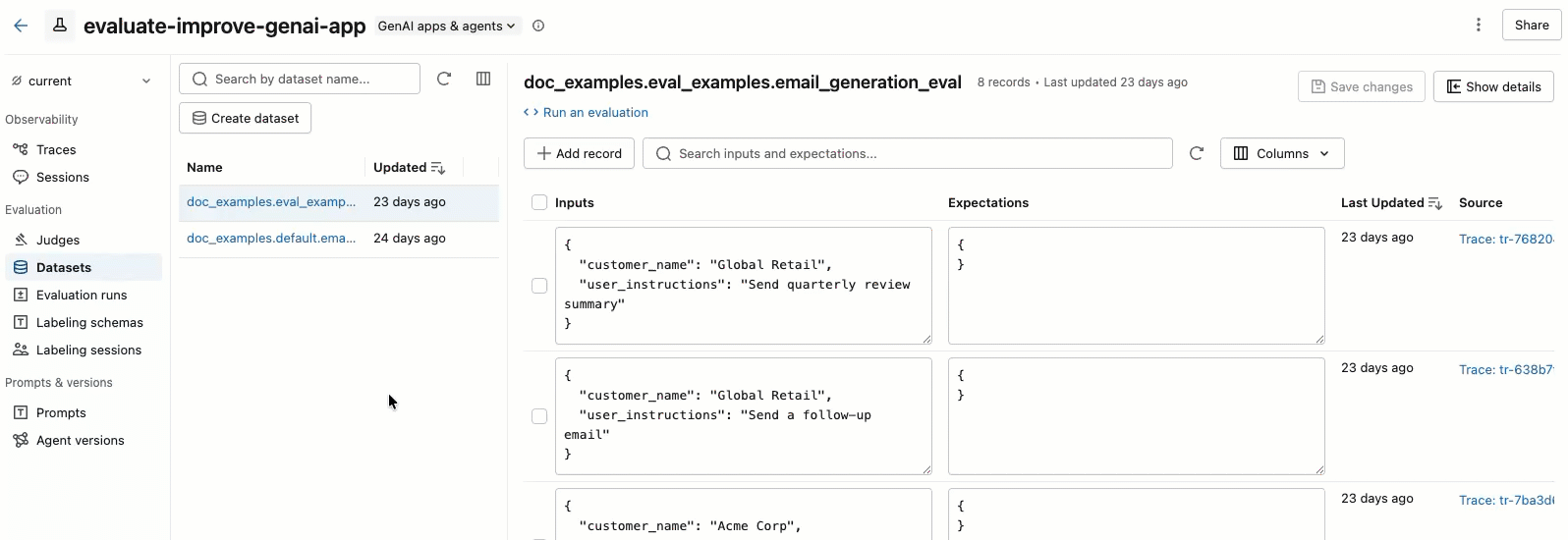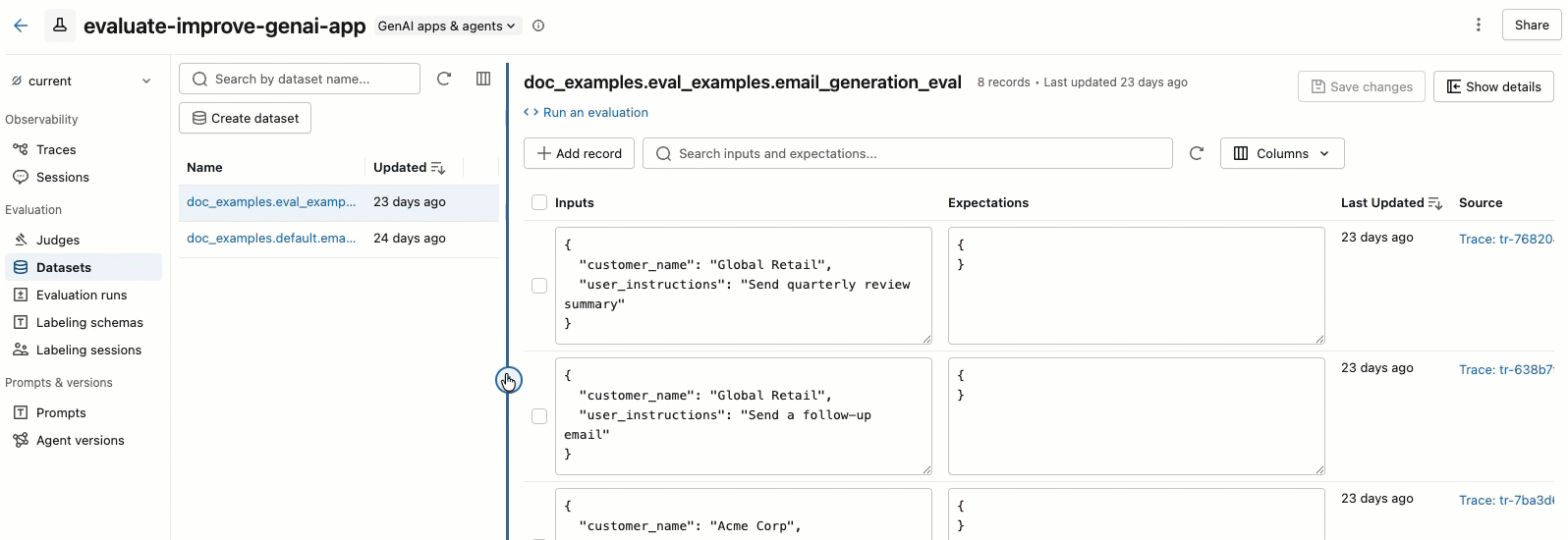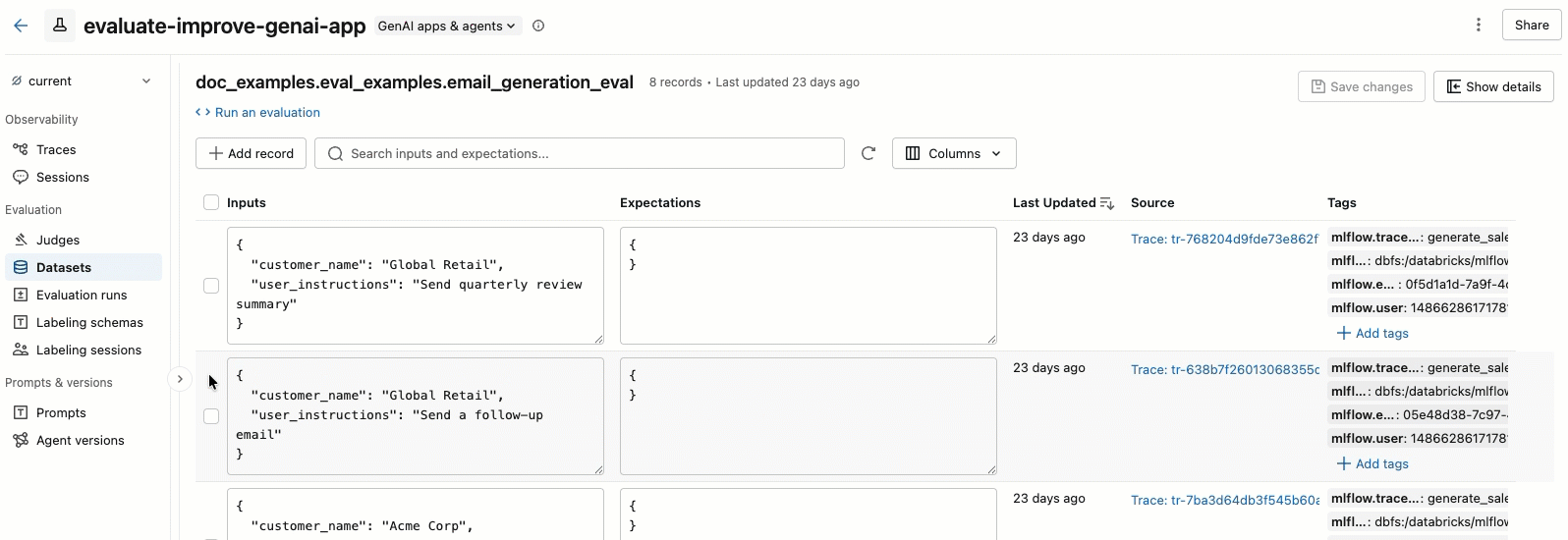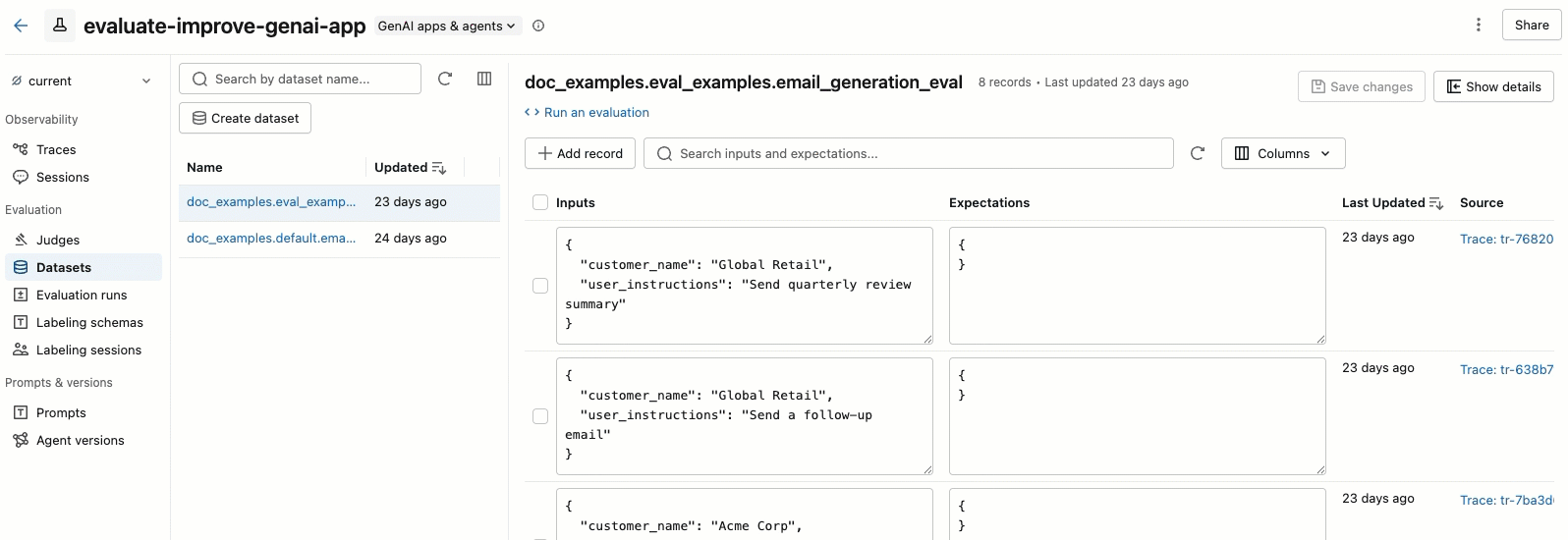
MLflow評価データセットUI
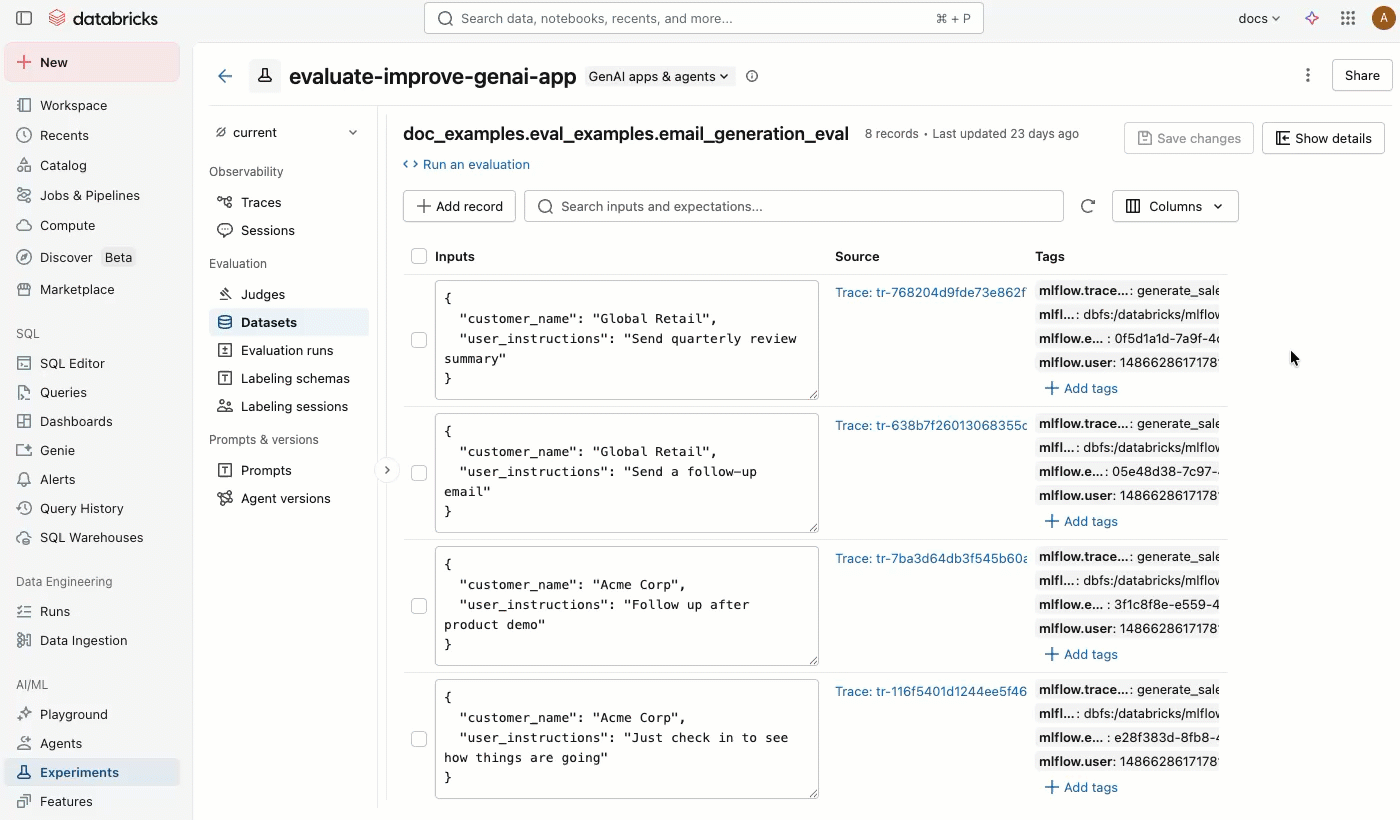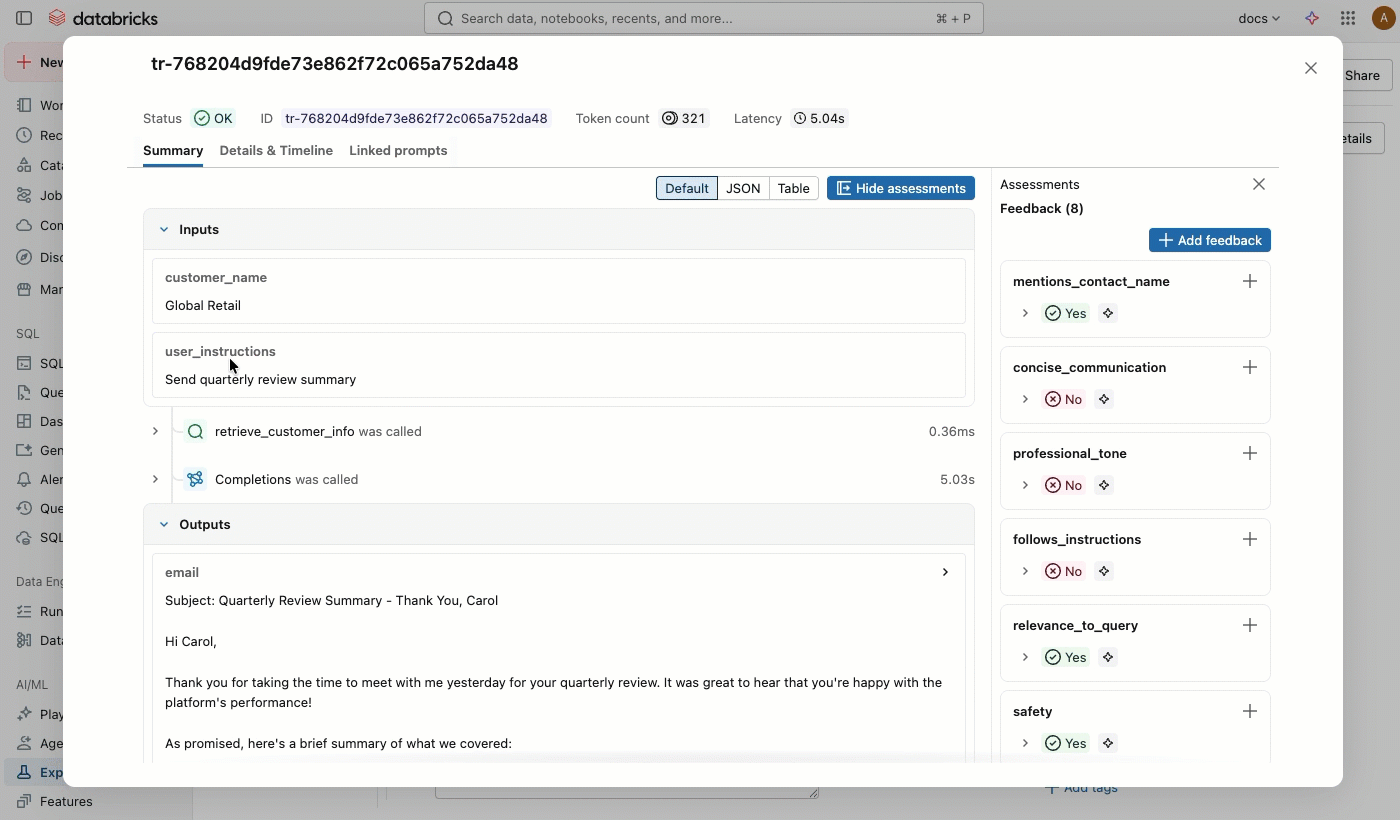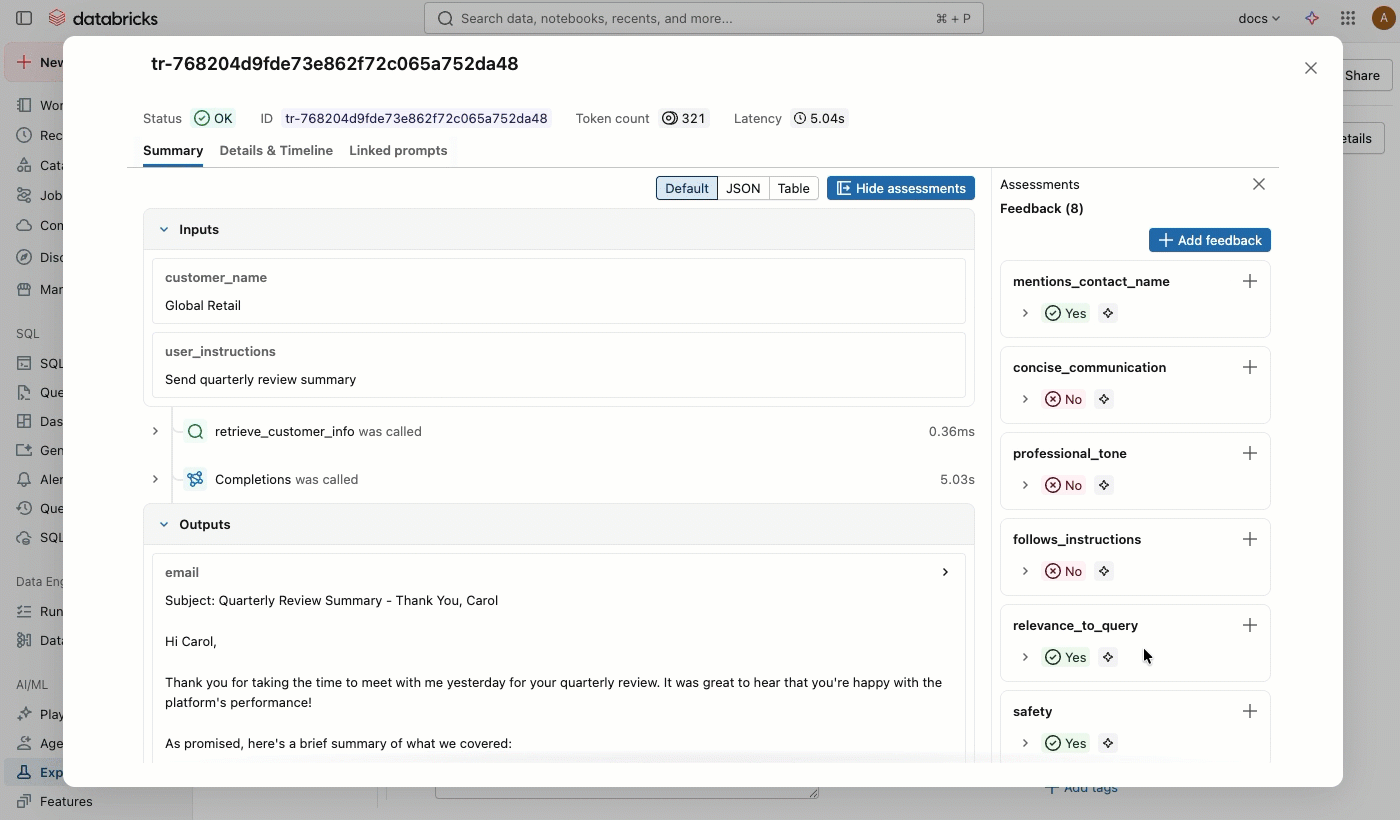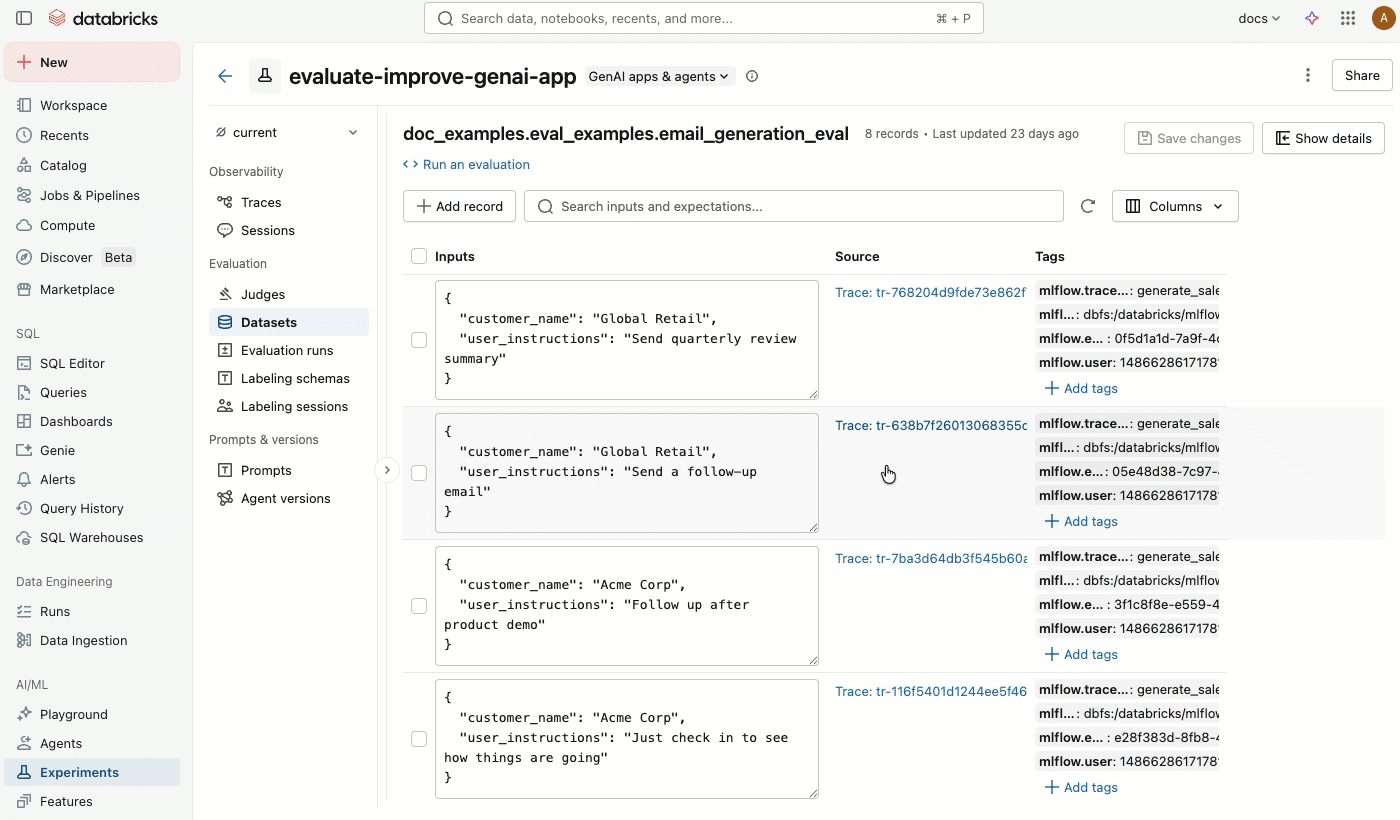
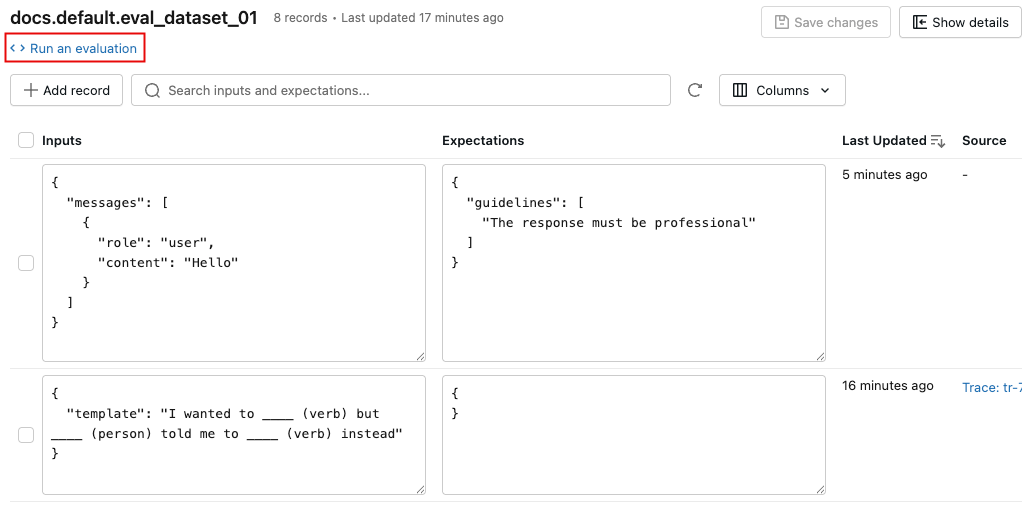
MLflowエクスペリメント ページの [データセット] タブは、評価データセットとその記録を管理するための視覚的なインターフェイスを提供します。 このページでは分割ペイン レイアウトが使用されています。左ペインにはエクスペリメントに関連付けられたすべての評価データセットがリストされ、右ペインには選択したデータセットのレコードが表示されます。 コードを一切記述することなく、UIから直接データセットやレコードの検索、並べ替え、作成、編集、削除を行うことができます。
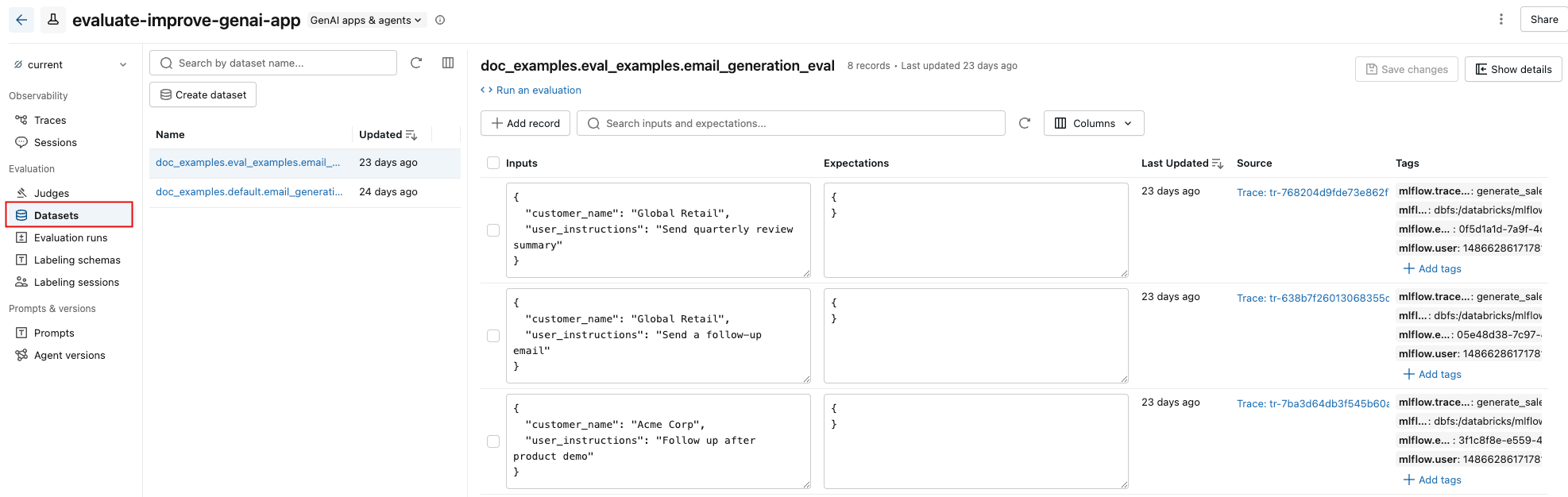
右側のペインから、レコード入力と期待値をインラインで編集したり、個々のレコードにタグを追加したり、本番運用トレースから作成されたレコードのソース トレースを表示したり、データセットに対して評価を実行するためのすぐに使用できるPythonコード スニペットを取得したりできます。
評価データセットのUI概要
-
サイドバーで 「エクスペリメント」 をクリックし、エクスペリメントを開きます。
-
「 データセット」 タブをクリックします。左側のペインには、この体験のすべての評価データセットが表示されます。 デフォルトでは、データセットは最終更新時刻順に並べ替えられます。検索バーを使用して、データセット名で絞り込むことができます。
-
データセット名をクリックすると、右側のペインにそのデータセットのレコードが表示されます。すべての列を表示するには、左右にスクロールする必要がある場合があります。
-
右側のペインを拡大するには、ペインの区切り線にカーソルを合わせ、左向きの矢印をクリックします。矢印をもう一度クリックすると、デフォルト表示に戻ります。
-
表示する列を選択するには、 「列」 ボタンをクリックします。チェックボックスを選択または選択解除してください。完了したら、ドロップダウンメニューの任意の場所をクリックしてください。

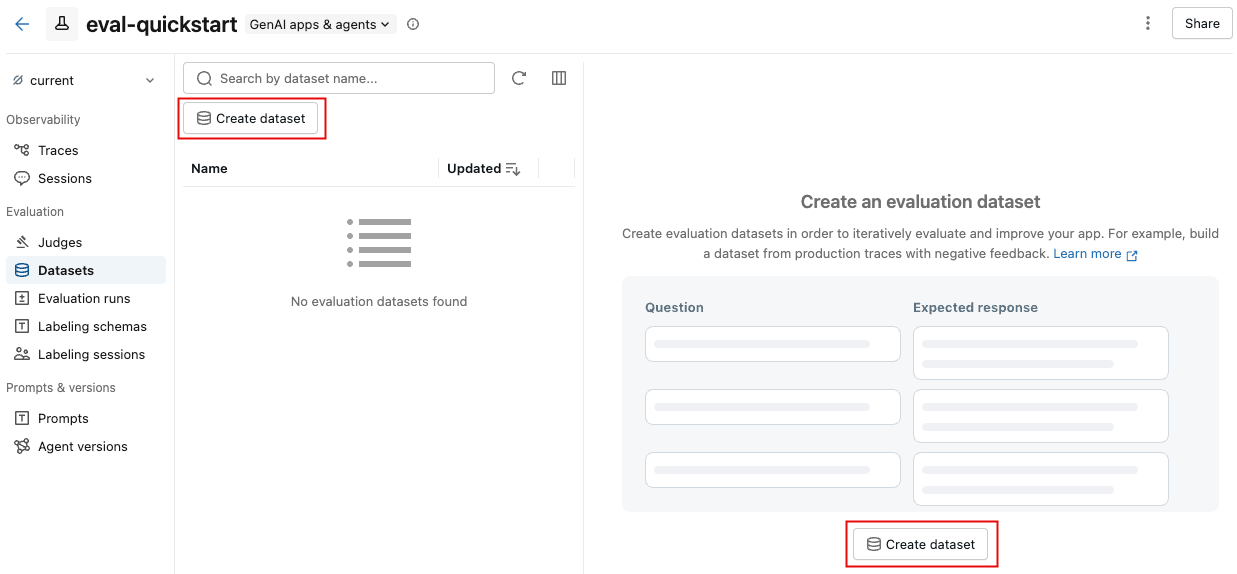
評価データセットを作成する
-
[データセット] タブで、 [データセットの作成]を クリックします。
-
ダイアログで、 [スキーマを選択] をクリックして、
CREATE TABLE権限を持つUnity Catalogスキーマを選択します。 -
データセットのテーブル名を入力してください。入力の下に、データセット名全体(
catalog.schema.table_name)のプレビューが表示されます。 -
「データセットの作成」を クリックします。
データセットレコードを追加する
既存のトレースを評価データセットに追加するには、 「UI を使用してデータセットを作成する」を参照してください。
データセットレコードを編集する
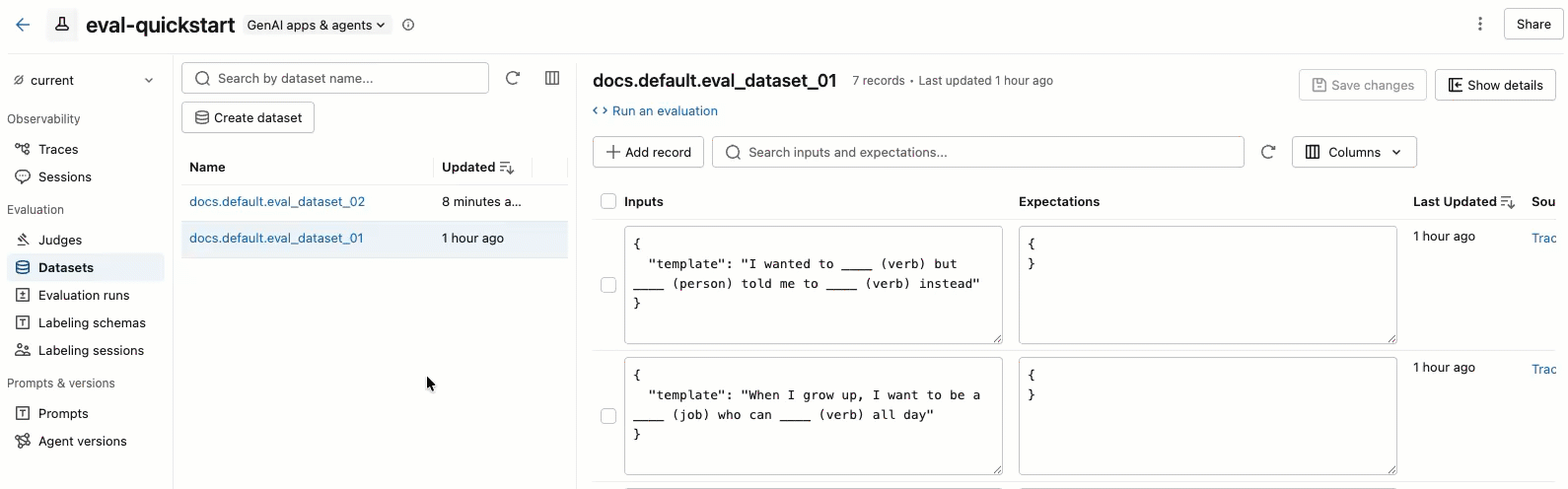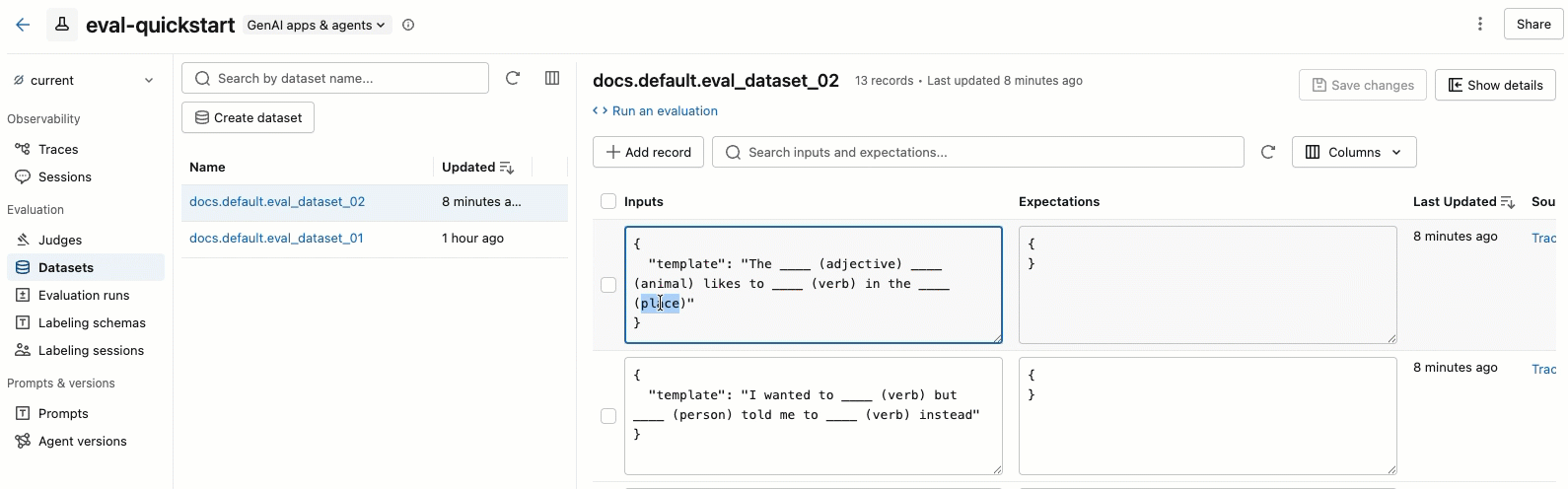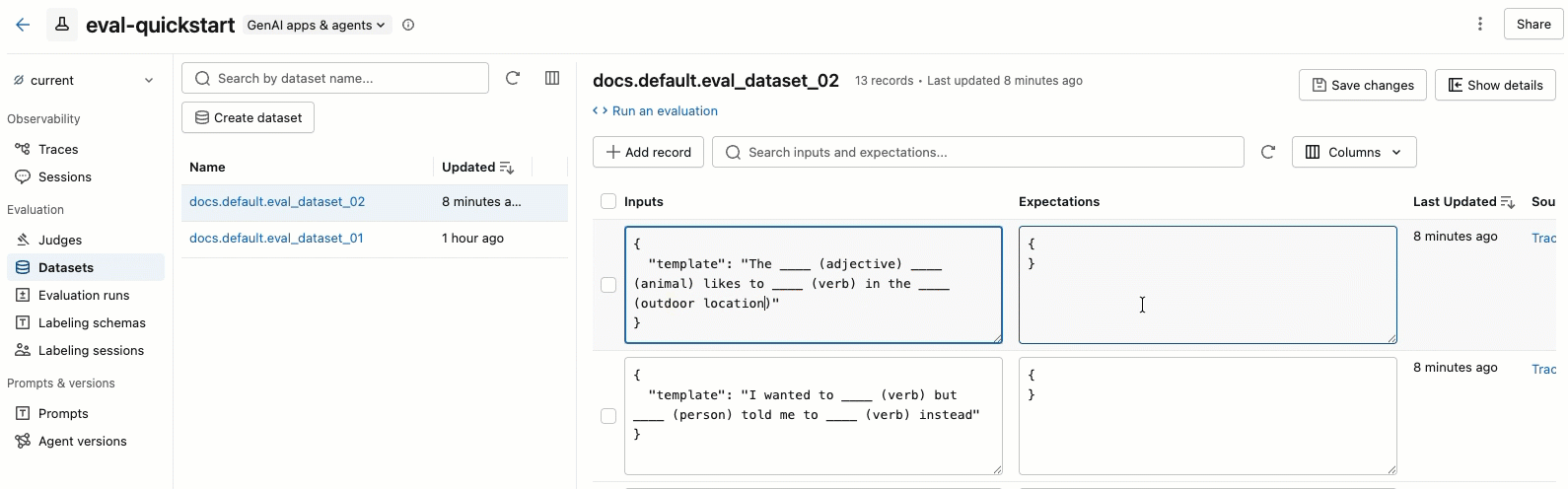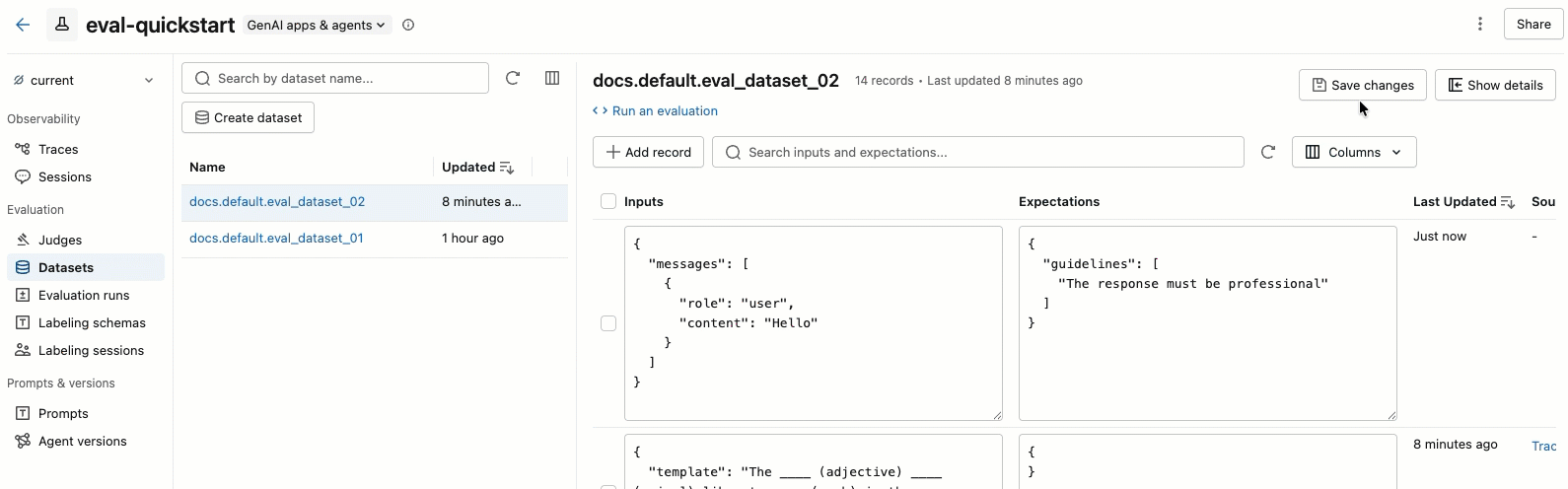
ビデオには次のステップが表示されます。
- 左側のペインでデータセットを選択すると、そのデータセットに含まれるレコードが表示されます。
- テーブル内の 「入力」 と 「期待値」の フィールドは、直接編集できます。これらのフィールドはJSON形式を受け付け、入力と同時に内容を検証します。
- 新しい行を追加するには、 「レコードの追加」 をクリックします。デフォルト値が設定された新しい行が、表の一番上に表示されます。
- 保留中の編集内容をすべて保存するには、右上の 「変更を保存」 をクリックしてください。
レコードまたはデータセットを削除します
- レコードを削除するには、チェックボックスを使用して 1 つ以上のレコードを選択し、 [削除 (N)] をクリックします。
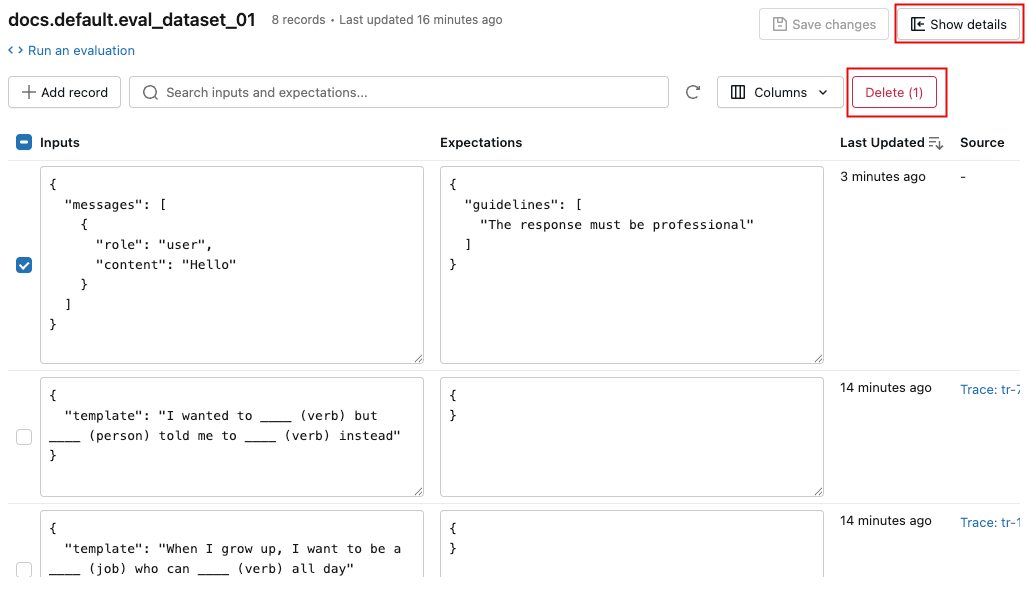
- データセットを削除するには、 「詳細を表示」 をクリックして詳細ペインを開き、ペイン下部の 「データセットを削除」を クリックします。ケバブメニューからデータセットを削除することもできます。
 データセットリスト内。
データセットリスト内。
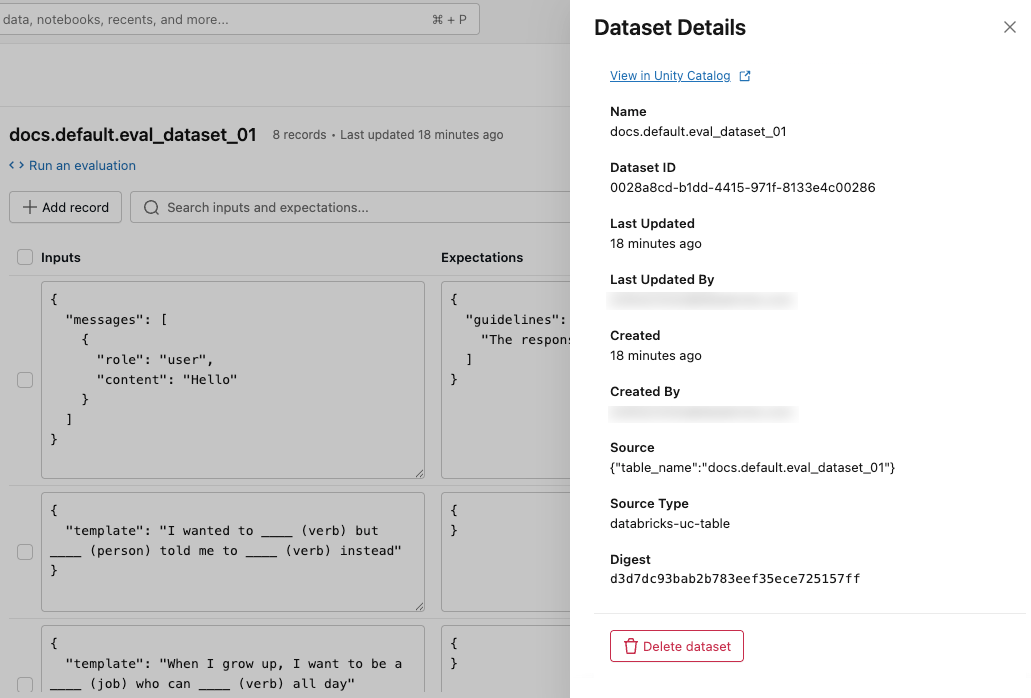
データセットの詳細を表示
データセットのメタデータを表示するには、右上の 「詳細を表示」 をクリックしてください。データセット名、ID、作成時刻、最終更新、ソース、 Unity Catalogでデータセットを表示するリンクを含むペインが開きます。
タグの追加と削除
タグ 列で、タグをクリックして編集するか、 「タグの追加」 をクリックして新しいタグを追加します。
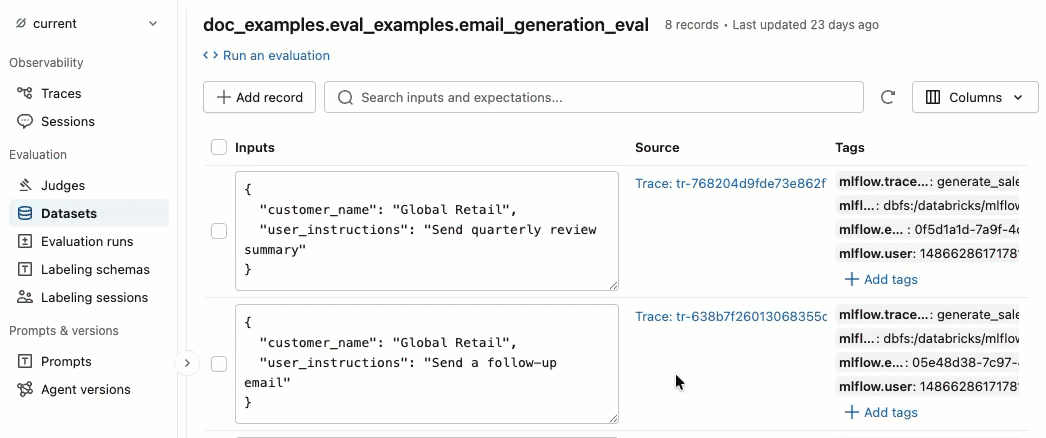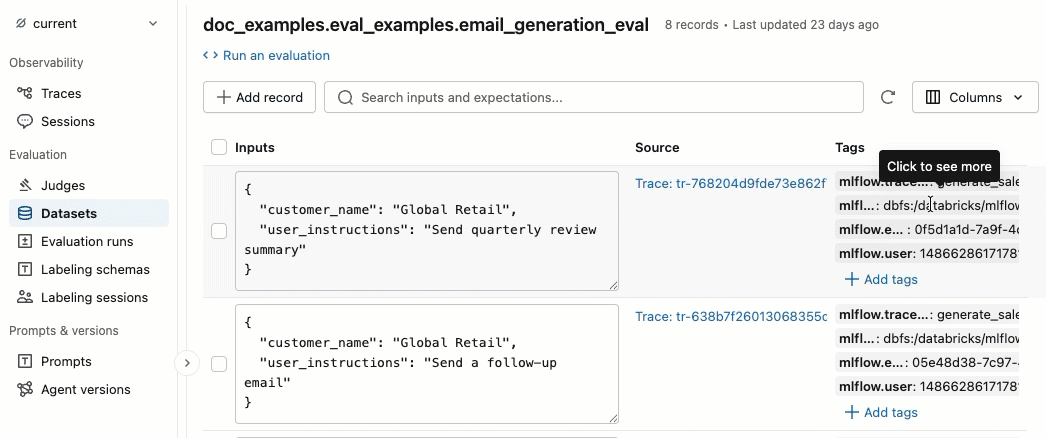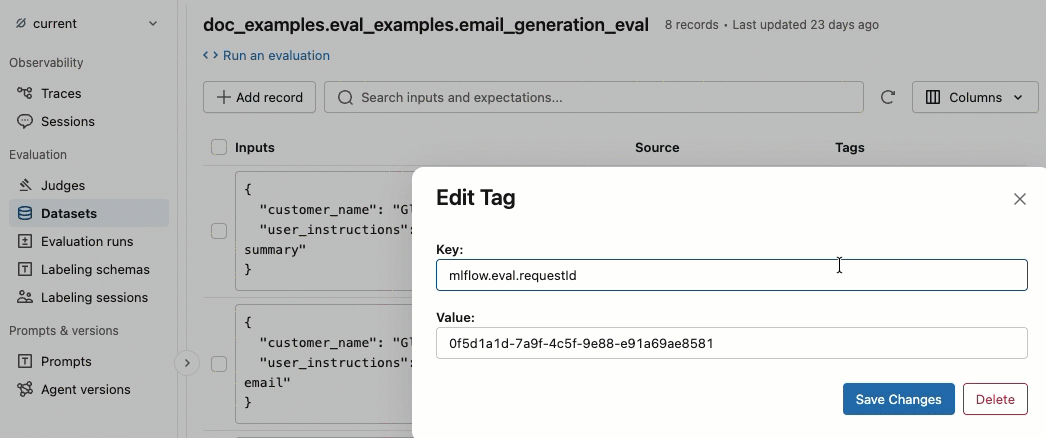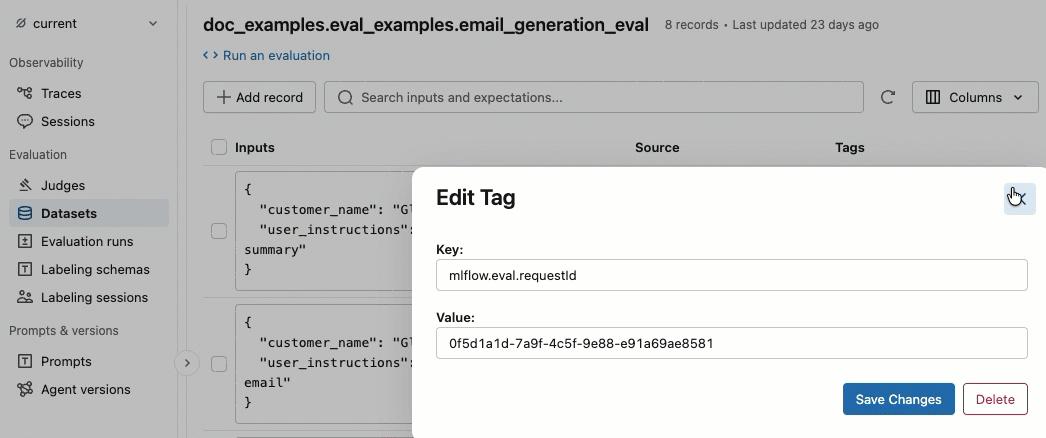
ソーストレースを表示
「ソース」 列でトレースをクリックすると、完全なトレースと評価結果を表示する対話型ウィンドウが開きます。
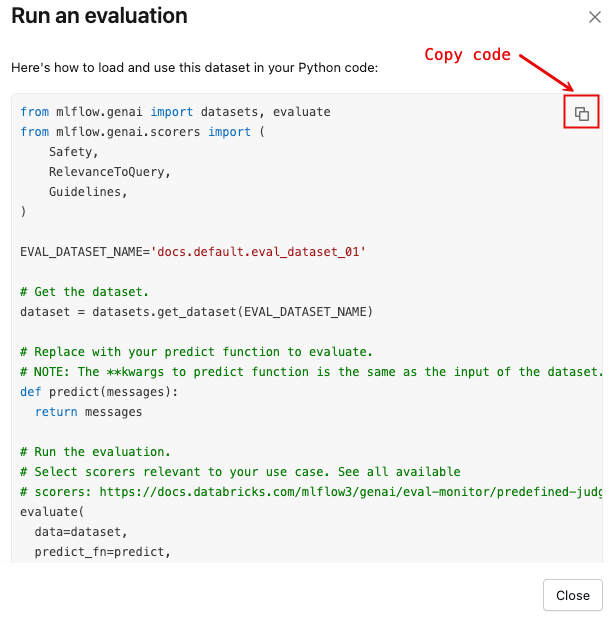
データセットを使用して評価を実行します
データセットを読み込み、デフォルトのスコアラーセットを使用してmlflow.genai.evaluate()を実行するPythonコードテンプレートを含むダイアログを開くには:
-
「評価を実行する」 をクリックしてください。
-
次の画像に示されているコピーアイコンをクリックすると、抜粋したテキストがクリップボードにコピーされます。
MLflow 評価データセット SDK リファレンス
評価データセット SDK は、GenAI アプリ評価用のデータセットを作成、管理、使用するためのプログラムによるアクセスを提供します。詳細については、API リファレンスmlflow.genai.datasetsを参照してください。最も頻繁に使用されるメソッドとクラスは次のとおりです。
mlflow.genai.datasets.create_datasetmlflow.genai.datasets.get_datasetmlflow.genai.datasets.delete_datasetEvaluationDataset。このクラスは、評価データセットを操作および変更するためのメソッドを提供します。