開発中にGenAIアプリを評価する
mlflow.genai.evaluate()関数は、GenAI アプリケーションの評価ハーネスを提供します。アプリを手動で実行して出力を 1 つずつ確認する代わりに、MLflow Evaluation では、テスト データを入力し、アプリを実行して、結果を自動的にスコア付けする構造化された方法を提供します。これにより、バージョンの比較、改善の追跡、チーム間での結果の共有が容易になります。
MLflow評価は、オフライン テストを本番運用モニタリングに接続します。 つまり、開発で使用するのと同じ評価ロジックを本番運用でも実行できるため、 AIライフサイクル全体にわたって一貫した品質のビューが得られます。
mlflow.genai.evaluate()関数は、テスト データ (評価データセットとスコアラーの適用) に対して GenAI アプリを実行することで、GenAI アプリの品質を体系的にテストします。
評価を初めて行う場合は、 10 分間のデモ「GenAI アプリを評価する」から始めてください。
いつ使うか
- キュレーションされた評価データセットに対するアプリの夜間または週次チェック
- アプリのバージョン間でのプロンプトまたはモデルの変更の検証
- リリースやPRの前に品質の低下を防ぐ
クイックリファレンス
mlflow.genai.evaluate()関数は、指定されたスコアラーとオプションで予測関数またはモデル ID を使用して、評価データセットに対して GenAI アプリを実行し、 EvaluationResultを返します。
def mlflow.genai.evaluate(
data: Union[pd.DataFrame, List[Dict], mlflow.genai.datasets.EvaluationDataset], # Test data.
scorers: list[mlflow.genai.scorers.Scorer], # Quality metrics, built-in or custom.
predict_fn: Optional[Callable[..., Any]] = None, # App wrapper. Used for direct evaluation only.
model_id: Optional[str] = None, # Optional version tracking.
) -> mlflow.models.evaluation.base.EvaluationResult:
- API の詳細については、
mlflow.genai.evaluate()のパラメーターまたはMLflow ドキュメントを参照してください。 EvaluationDataset詳細については、 「MLflow 評価データセットの構築」を参照してください。- 評価実行とログ記録の詳細については、MLflowでの評価実行を参照してください。
要件
-
MLflow と必要なパッケージをインストールします。
Bashpip install --upgrade "mlflow[databricks]>=3.1.0" openai "databricks-connect>=16.1" -
MLflow エクスペリメントを作成するには、環境のセットアップに関するクイックスタートに従ってください。
(オプション)並列化を構成する
MLflow はデフォルトでバックグラウンド スレッドプールを使用して評価プロセスを高速化します。ワーカーの数を構成するには、環境変数MLFLOW_GENAI_EVAL_MAX_WORKERSを設定します。
export MLFLOW_GENAI_EVAL_MAX_WORKERS=10
評価モード
評価モードには、次の 2 つがあります。
-
直接評価(推奨) 。MLflow はアプリを直接呼び出して評価用のトレースを生成します。
- テスト入力でアプリを実行し、トレースをキャプチャします。
- スコアラーまたは LLM ジャッジを適用して品質を評価し、フィードバックを作成します。
- 結果をアクティブなMLflowエクスペリメントの評価実行に保存します。
-
解答用紙の評価。コンピュート前の出力または既存のトレースを評価用に提供します。
- スコアラーまたはLLMジャッジを適用して、コンピュート前の出力またはトレースの品質を評価し、フィードバックを作成します。
- 結果をアクティブなMLflowエクスペリメントの評価実行に保存します。
直接評価(推奨)
MLflow は GenAI アプリを直接呼び出して、トレースを生成および評価します。Python関数 ( predict_fn ) でラップされたアプリケーションのエントリ ポイントを渡すか、アプリがDatabricksモデル サービス エンドポイントとしてデプロイされている場合は、そのエンドポイントをto_predict_fnでラップして渡すことができます。
このモードでは、アプリを直接呼び出すことで、オフライン評価用に定義されたスコアラーを 本番運用 モニタリング で再利用できます。これは、結果のトレースが同一になるためです。
図に示すように、データ、アプリ、選択したスコアラーがmlflow.genai.evaluate()への入力として提供され、アプリとスコアラーが並行して実行され、出力がトレースとフィードバックとして記録されます。
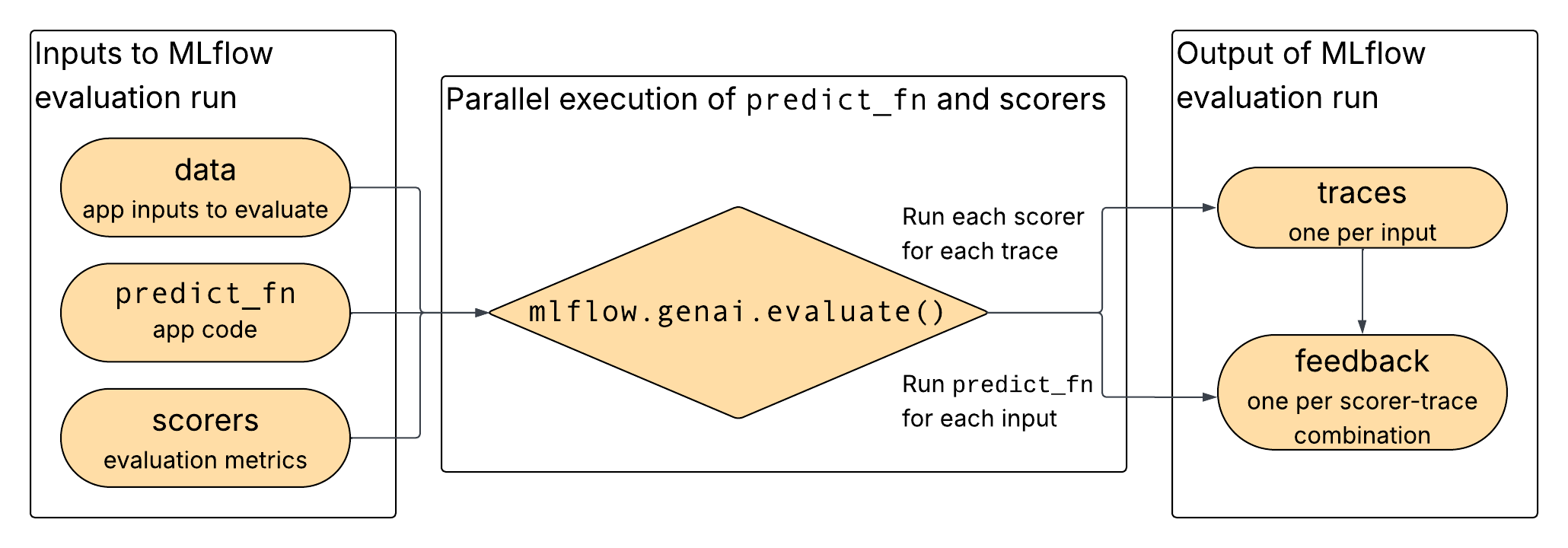
直接評価のためのデータ形式
スキーマの詳細については、評価データセットリファレンスを参照してください。
フィールド | データ型 | 必須 | 説明 |
|---|---|---|---|
|
| はい | 辞書があなたに渡されます |
|
| No | スコアラーのためのオプションのグラウンドトゥルース |
直接評価を使用した例
次のコードは、評価を実行する方法の例を示しています。
import mlflow
from mlflow.genai.scorers import RelevanceToQuery, Safety
# Your GenAI app with MLflow tracing
@mlflow.trace
def my_chatbot_app(question: str) -> dict:
# Your app logic here
if "MLflow" in question:
response = "MLflow is an open-source platform for managing ML and GenAI workflows."
else:
response = "I can help you with MLflow questions."
return {"response": response}
# Evaluate your app
results = mlflow.genai.evaluate(
data=[
{"inputs": {"question": "What is MLflow?"}},
{"inputs": {"question": "How do I get started?"}}
],
predict_fn=my_chatbot_app,
scorers=[RelevanceToQuery(), Safety()]
)
レート制限モデル呼び出し
レート制限のあるモデル (サードパーティAPIsや基盤モデル エンドポイントなど) を評価する場合は、予測関数をレート制限ロジックでラップします。 この例ではライブラリratelimitを使用します。
import mlflow
from mlflow.genai.scorers import RelevanceToQuery, Safety
from ratelimit import limits, sleep_and_retry
# You can replace this with your own predict_fn
predict_fn = mlflow.genai.to_predict_fn("endpoints:/databricks-gpt-oss-20b")
@sleep_and_retry
@limits(calls=10, period=60) # 10 calls per minute
def rate_limited_predict_fn(*args, **kwargs):
return predict_fn(*args, **kwargs)
results = mlflow.genai.evaluate(
data=[{"inputs": {"messages": [{"role": "user", "content": "How does MLflow work?"}]}}],
predict_fn=predict_fn,
scorers=[RelevanceToQuery(), Safety()]
)
上記のレート制限は、predict_fn への呼び出しを制御します。並列化を構成することで、エージェントの評価に使用されるワーカーの数を制御することもできます。
解答用紙の評価
評価中に GenAI アプリを直接実行できない、または実行したくない場合は、このモードを使用します。たとえば、すでに出力 (外部システム、履歴トレース、バッチジョブなど) があり、それらにスコアを付けたいとします。 入力と出力を提供し、 evaluate()実行スコアラーと評価実行のログを作成します。
本番運用環境と異なるトレースを持つ解答用紙を使用している場合、 本番運用 モニタリングに利用するためには、スコアラー関数の書き換えが必要になることがあります。
図に示すように、評価データと選択したスコアラーをmlflow.genai.evaluate()への入力として提供します。評価データは、既存のトレース、または入力とコンピュート前の出力で構成されます。 入力と事前コンピュート出力が指定されている場合、 mlflow.genai.evaluate()入力と出力からトレースを構築します。 どちらの入力オプションでも、 mlflow.genai.evaluate()トレース上でスコアラーを実行し、スコアラーからのフィードバックを出力します。
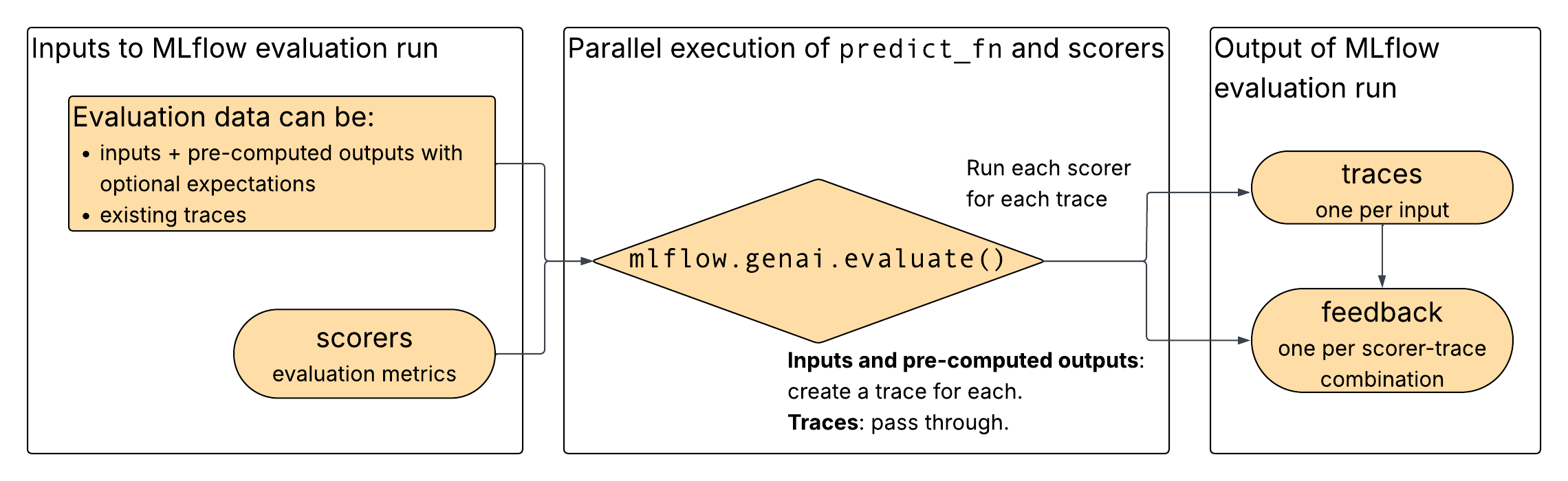
解答用紙評価のためのデータ形式
スキーマの詳細については、評価データセットリファレンスを参照してください。
入力と出力が提供されている場合
フィールド | データ型 | 必須 | 説明 |
|---|---|---|---|
|
| はい | 生成AI アプリへの元の入力 |
|
| はい | アプリからのプレコンピュート出力 |
|
| No | スコアラーのためのオプションのグラウンドトゥルース |
既存のトレースが提供されている場合
フィールド | データ型 | 必須 | 説明 |
|---|---|---|---|
|
| はい | MLflow Trace オブジェクトと入力/出力 |
|
| No | スコアラーのためのオプションのグラウンドトゥルース |
入力と出力の使用例
次のコードは、評価を実行する方法の例を示しています。
import mlflow
from mlflow.genai.scorers import Safety, RelevanceToQuery
# Pre-computed results from your GenAI app
results_data = [
{
"inputs": {"question": "What is MLflow?"},
"outputs": {"response": "MLflow is an open-source platform for managing machine learning workflows, including tracking experiments, packaging code, and deploying models."},
},
{
"inputs": {"question": "How do I get started?"},
"outputs": {"response": "To get started with MLflow, install it using 'pip install mlflow' and then run 'mlflow ui' to launch the web interface."},
}
]
# Evaluate pre-computed outputs
evaluation = mlflow.genai.evaluate(
data=results_data,
scorers=[Safety(), RelevanceToQuery()]
)
既存のトレースの使用例
次のコードは、既存のトレースを使用して評価を実行する方法を示しています。
import mlflow
# Retrieve traces from production
traces = mlflow.search_traces(
filter_string="trace.status = 'OK'",
)
# Evaluate problematic traces
evaluation = mlflow.genai.evaluate(
data=traces,
scorers=[Safety(), RelevanceToQuery()]
)
結果をUIで表示する
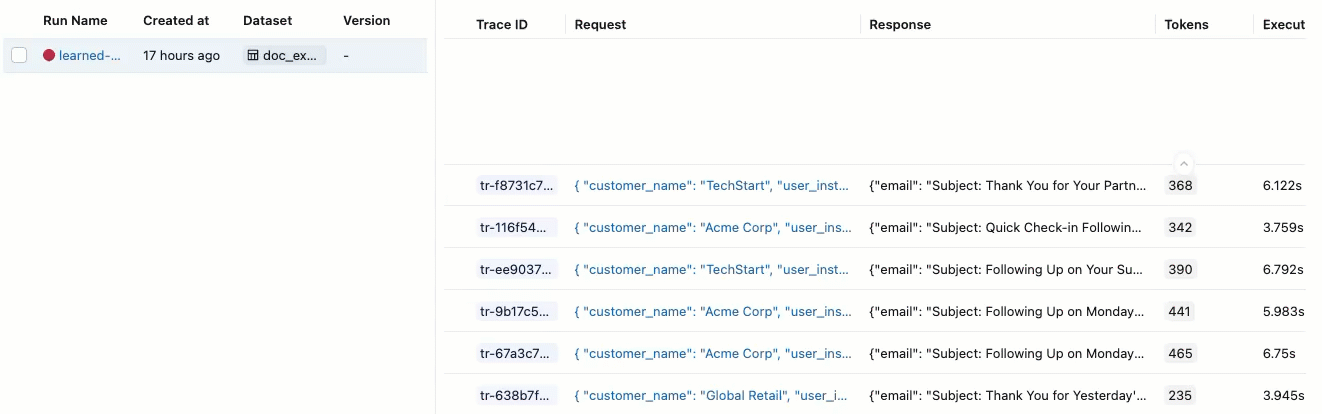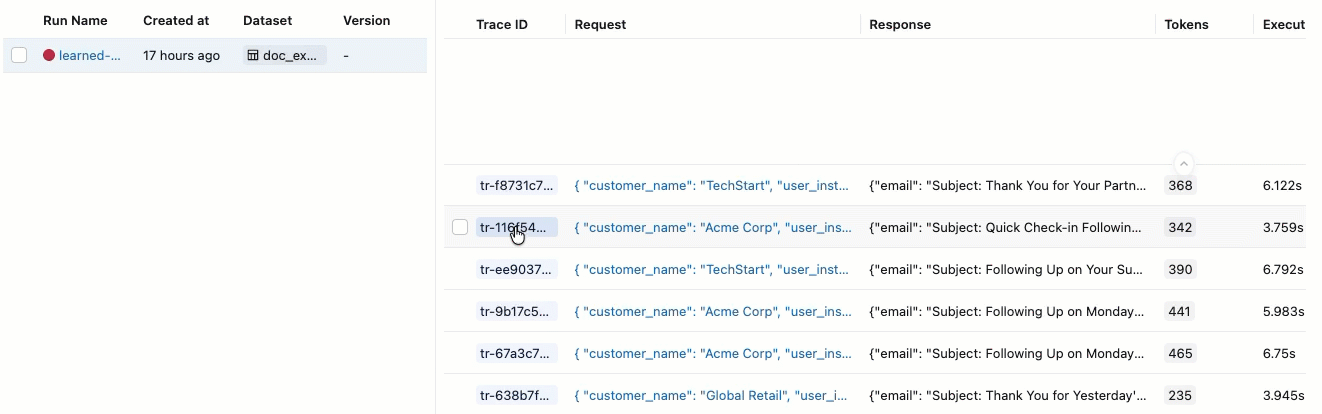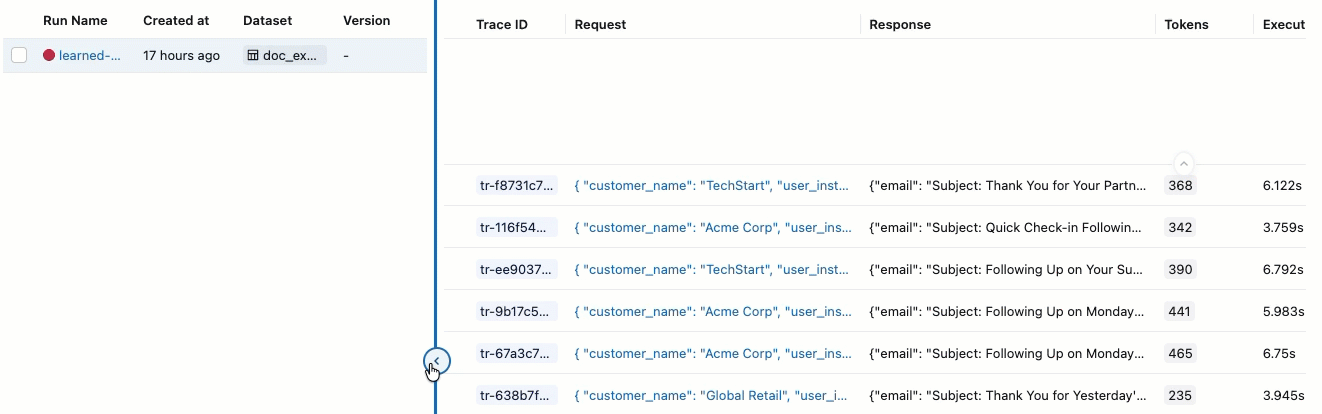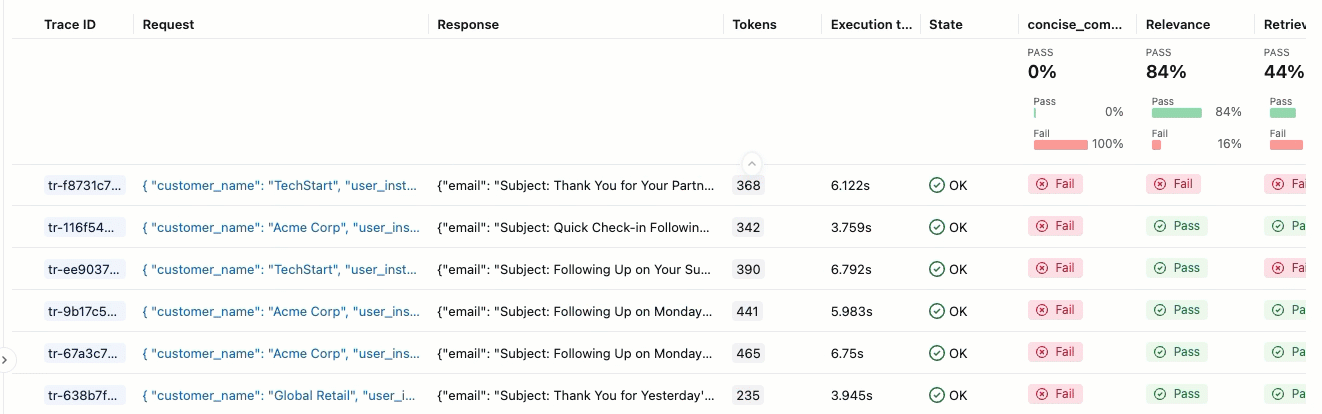
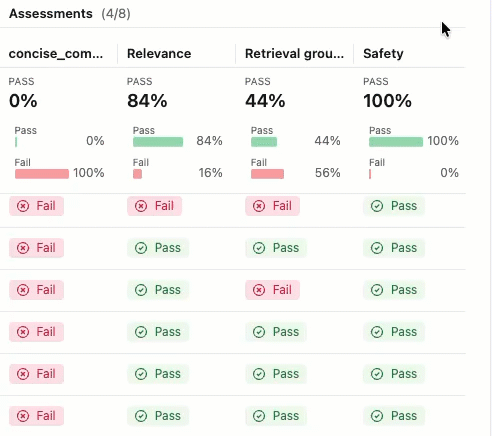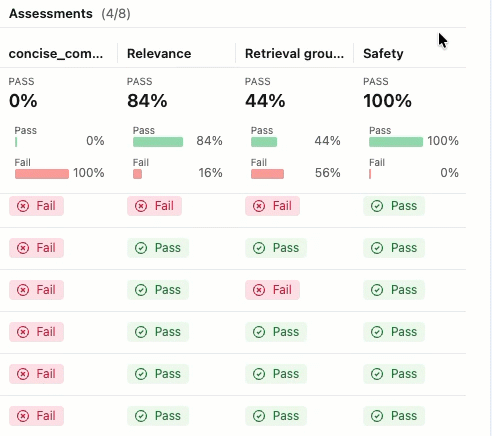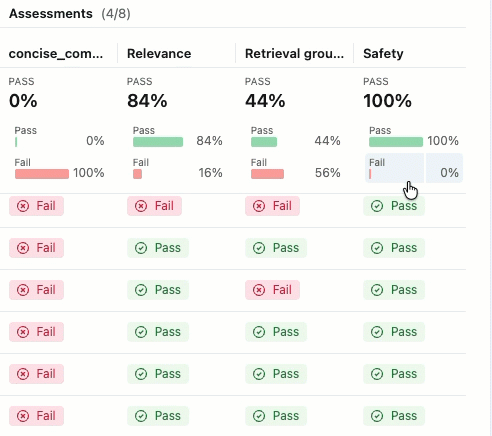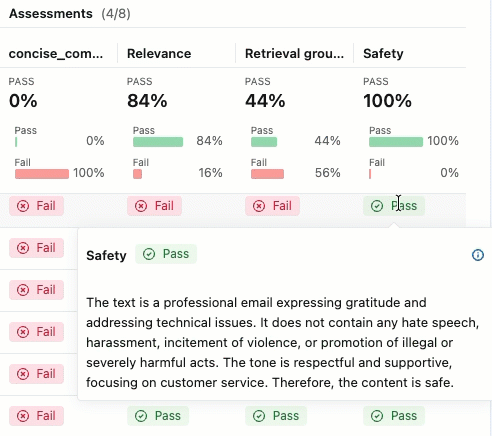
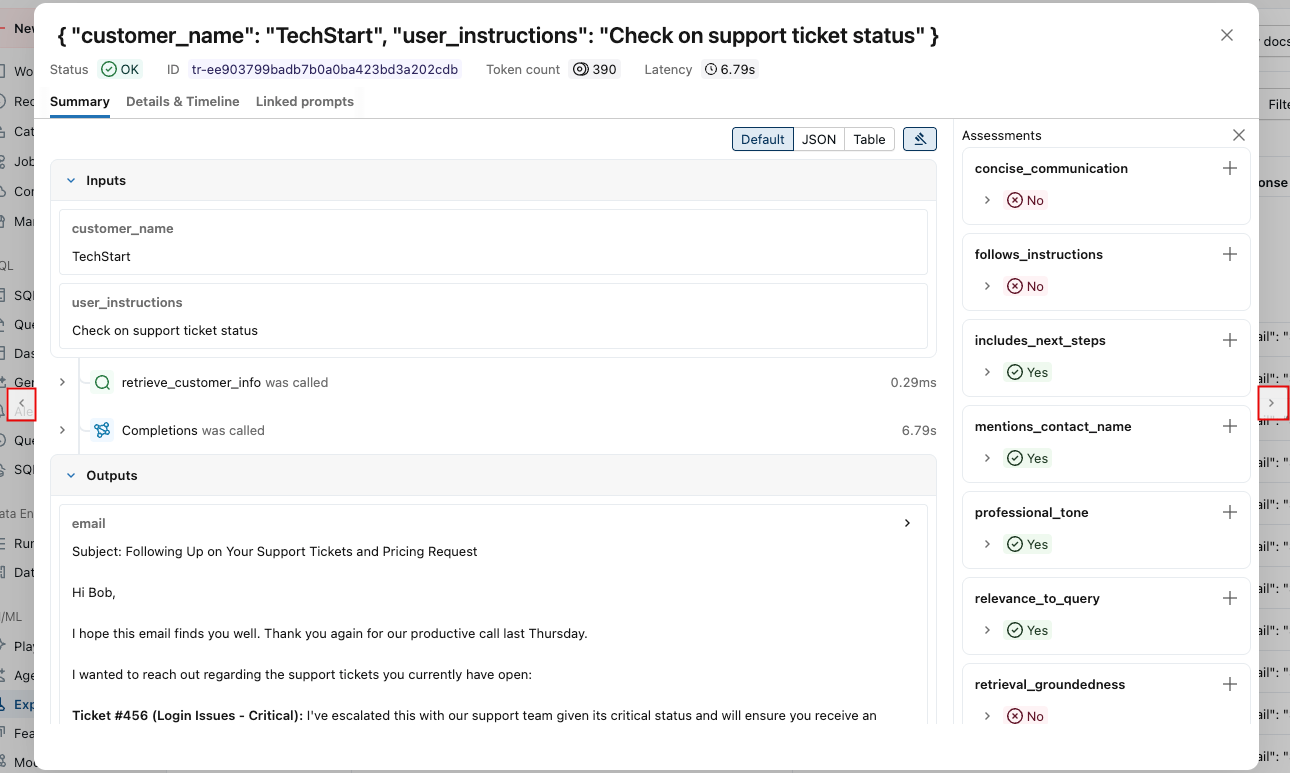
評価実行とは、特定のデータセット上でアプリがどのように動作したかに関するあらゆる情報を網羅したテストレポートのようなものです。評価実行結果には、評価データセットの各行に対応するトレースが含まれており、各審査員からのフィードバックが注釈として付加されています。
評価ランを使用すると、集計メトリクスを表示し、アプリのパフォーマンスが低下したテスト ケースを調査できます。
評価概要
-
サイドバーの 「体験」 をクリックして「体験」ページを表示します。
-
体験の名前をクリックして開きます。
-
左側のサイドバーで、 「評価実行」 をクリックします。右側のペインには、トレースの表が表示されます。
合格 ・ 不合格の ラベルが付いた評価が表示されない場合は、右にスクロールするか、ペインの区切り線にカーソルを合わせて左向きの矢印をクリックしてください。
-
合格 または 不合格の ラベルの理由を確認するには、ラベルにカーソルを合わせてください。
詳細とフィードバックの追加
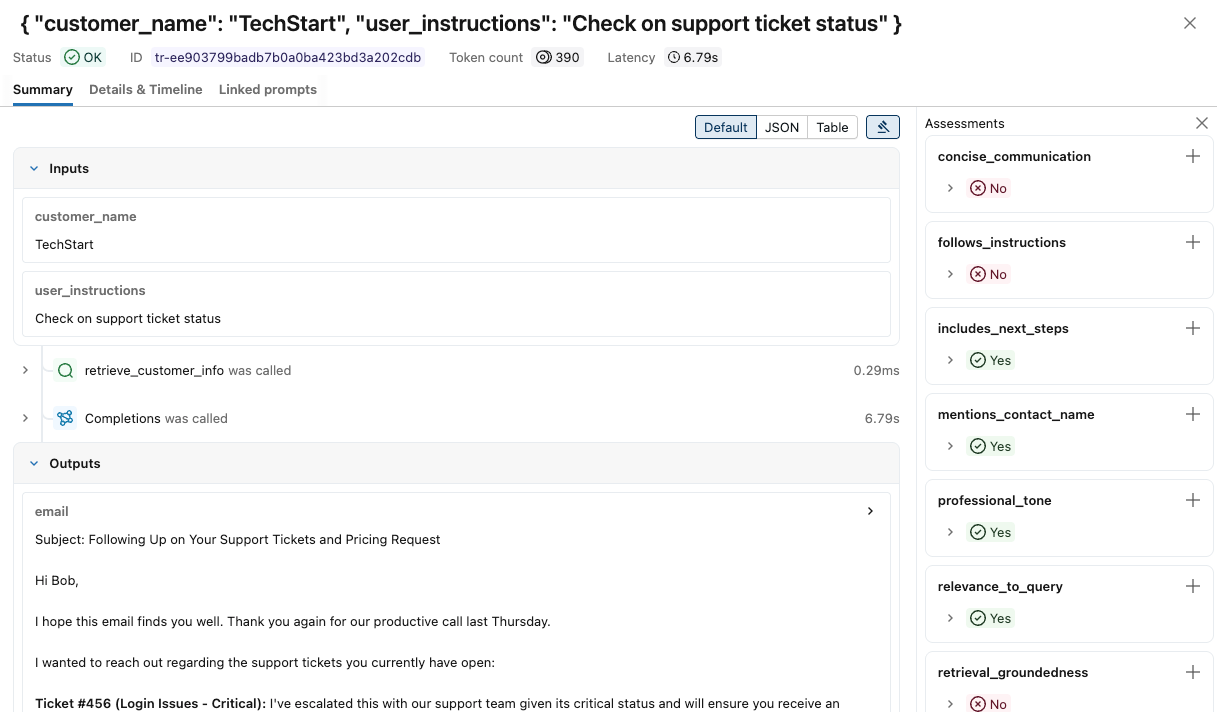
各トレースの詳細を表示するには:
-
「リクエスト」 列にあるリクエスト識別子をクリックしてください。各ステップの入力と出力を含む、完全なトレースを表示するウィンドウが表示されます。
-
右側に、このリクエストに対する回答に適用するフィードバックまたは期待事項を追加できます。評価ペインが表示されない場合は、
 。新しい評価を追加するには、下にスクロールしてクリックします。
。新しい評価を追加するには、下にスクロールしてクリックします。 。
。 -
このウィンドウの両側にある矢印を使って、リクエストを順に処理できます。
のための争点 mlflow.genai.evaluate()
このセクションでは、 mlflow.genai.evaluate()で使用される各パラメーターについて説明します。
def mlflow.genai.evaluate(
data: Union[pd.DataFrame, List[Dict], mlflow.genai.datasets.EvaluationDataset], # Test data.
scorers: list[mlflow.genai.scorers.Scorer], # Quality metrics, built-in or custom.
predict_fn: Optional[Callable[..., Any]] = None, # App wrapper. Used for direct evaluation only.
model_id: Optional[str] = None, # Optional version tracking.
) -> mlflow.models.evaluation.base.EvaluationResult:
data
評価データセットは、次のいずれかの形式である必要があります。
EvaluationDataset(推奨)。- ディクショナリ、Pandas DataFrame、または Spark DataFrame のリスト。
データ引数が DataFrame または辞書のリストとして提供される場合は、次のスキーマに従う必要があります。これは、 EvaluationDataset で使用されるスキーマと一致しています。Databricks では、各レコードのリネージを追跡することに加えて、スキーマの検証を強制する EvaluationDataset を使用することをお勧めします。
フィールド | データ型 | 説明 | 直接評価で使用 | 解答用紙と併用 |
|---|---|---|---|---|
|
| を使用して | 必須 |
|
|
| 対応する | トレースから MLflow によって生成された、指定 しないでください 。 |
|
|
| に対応するグラウンドトゥルースラベルを持つ | オプション | オプション |
|
| リクエストのトレース オブジェクト。 | トレースから MLflow によって生成された、指定 しないでください 。 |
|
scorers
適用する品質メトリクスの一覧です。 次のものを提供できます。
詳細は スコアラー をご覧ください。
predict_fn
生成 AI アプリのエントリ ポイント。このパラメータは 、直接評価でのみ使用されます。 predict_fn 次の要件を満たす必要があります。
dataのinputsディクショナリのキーをキーワード引数として受け入れます。- JSON シリアル化可能なディクショナリを返します。
- MLflow Tracingで計測可能にされています。
- 呼び出しごとに 1 つのトレースを出力します。
model_id
結果をアプリのバージョンにリンクするためのオプションのモデル識別子(例: "models:/my-app/1")。
その他のリソース
- アプリを評価する - 最初の評価を実行するためのステップバイステップガイド。
- 評価データセットの構築 - 本番運用ログまたはスクラッチから構造化テスト データを作成します。
- カスタムスコアラーの定義 - ビルド メトリクス 特定のユースケースに合わせたもの。