チュートリアル: 開発環境を MLflow に接続する
このページでは、 MLflow エクスペリメントを作成し、開発環境をそれに接続する方法について説明します。
MLflow エクスペリメントは、生成AI アプリケーションのコンテナです。エクスペリメントの詳細についてはMLflowエクスペリメント データ モデル コンセプト ガイドを参照してください。
開発環境に関連するセクションに移動します。
ローカル開発環境
手順 1: MLflow をインストールする
Databricks 接続を使用して MLflow をインストールします。
Bash
pip install --upgrade "mlflow[databricks]>=3.1"
ステップ 2: MLflowエクスペリメントを作成する
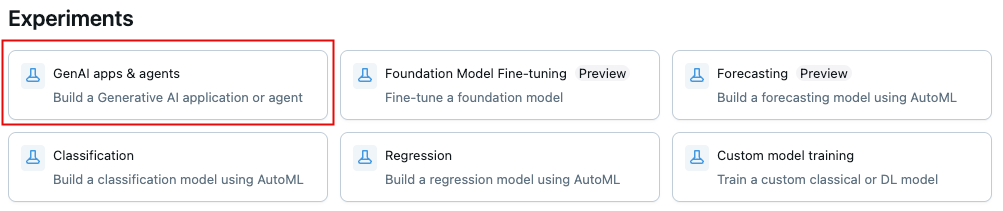
- Databricks ワークスペースを開きます。
- 左側のサイドバーの AI/ML で、 エクスペリメント をクリックします。
- エクスペリメント ページの上部にある GenAIアプリとエージェント をクリックします。
ステップ 3: 認証を構成する
注記
これらのステップでは、 Databricks Personal アクセス オンラインの使用について説明します。 MLflow は、Databricks がサポートする他の認証方法でも動作します。
次のいずれかの認証方法を選択します。
- Environment Variables
- .env File
- MLflowエクスペリメントで、ケバブメニューアイコン
 >[ Log traces locally] > [ Generate (APIキーの生成 )] をクリックします。
>[ Log traces locally] > [ Generate (APIキーの生成 )] をクリックします。 - 生成されたコードをターミナルにコピーして実行します。
Bash
export DATABRICKS_TOKEN=<databricks-personal-access-token>
export DATABRICKS_HOST=https://<workspace-name>.cloud.databricks.com
export MLFLOW_TRACKING_URI=databricks
export MLFLOW_REGISTRY_URI=databricks-uc
export MLFLOW_EXPERIMENT_ID=<experiment-id>
- MLflowエクスペリメントで、ケバブメニューアイコン >[ Log traces locally] > [ Generate (APIキーの生成 )] をクリックします。
- 生成されたコードをプロジェクト ルートの
.envファイルにコピーします。
Bash
DATABRICKS_TOKEN=<databricks-personal-access-token>
DATABRICKS_HOST=https://<workspace-name>.cloud.databricks.com
MLFLOW_TRACKING_URI=databricks
MLFLOW_REGISTRY_URI=databricks-uc
MLFLOW_EXPERIMENT_ID=<experiment-id>
python-dotenvパッケージをインストールします。
Bash
pip install python-dotenv
- コードに環境変数を読み込みます。
Python
# At the beginning of your Python script
from dotenv import load_dotenv
# Load environment variables from .env file
load_dotenv()
ステップ 4: 接続を確認する
テスト ファイルを作成し、次のコードを実行して接続を確認し、テスト トレース を MLflow エクスペリメントに記録します。
Python
import mlflow
import os
experiment_id = os.environ.get("MLFLOW_EXPERIMENT_ID")
databricks_host = os.environ.get("DATABRICKS_HOST")
mlflow_tracking_uri = os.environ.get("MLFLOW_TRACKING_URI")
if experiment_id is None or databricks_host is None or mlflow_tracking_uri is None:
raise Exception("Environment variables are not configured correctly.")
@mlflow.trace
def hello_mlflow(message: str):
hello_data = {
"experiment_url": f"{databricks_host}/mlflow/experiments/{experiment_id}",
"experiment_name": mlflow.get_experiment(experiment_id=experiment_id).name,
"message": message,
}
return hello_data
result = hello_mlflow("hello, world!")
print(result)

Databricks でホストされているノートブックで開発する
ステップ 1: ノートブックを作成する
Databricks ノートブックを作成すると、生成AIアプリケーションのコンテナである MLflow エクスペリメントが作成されます。エクスペリメントの詳細については、「 データ モデル」を参照してください。
- Databricks ワークスペースを開きます。
- 左側のサイドバーの上部にある[ 新規 ]に移動します。
- [ノートブック] をクリックします。
手順 2: MLflow をインストールする
Databricks ランタイムには MLflow が含まれていますが、生成AI 機能を最大限に活用するには、最新バージョンに更新してください。
Python
%pip install --upgrade "mlflow[databricks]>=3.1"
dbutils.library.restartPython()
ステップ 3: 認証を構成する
Databricks ノートブック内で作業する場合、追加の認証設定は必要ありません。ノートブックは、ワークスペースと関連する MLflow エクスペリメントに自動的にアクセスできます。
ステップ 4: 接続を確認する
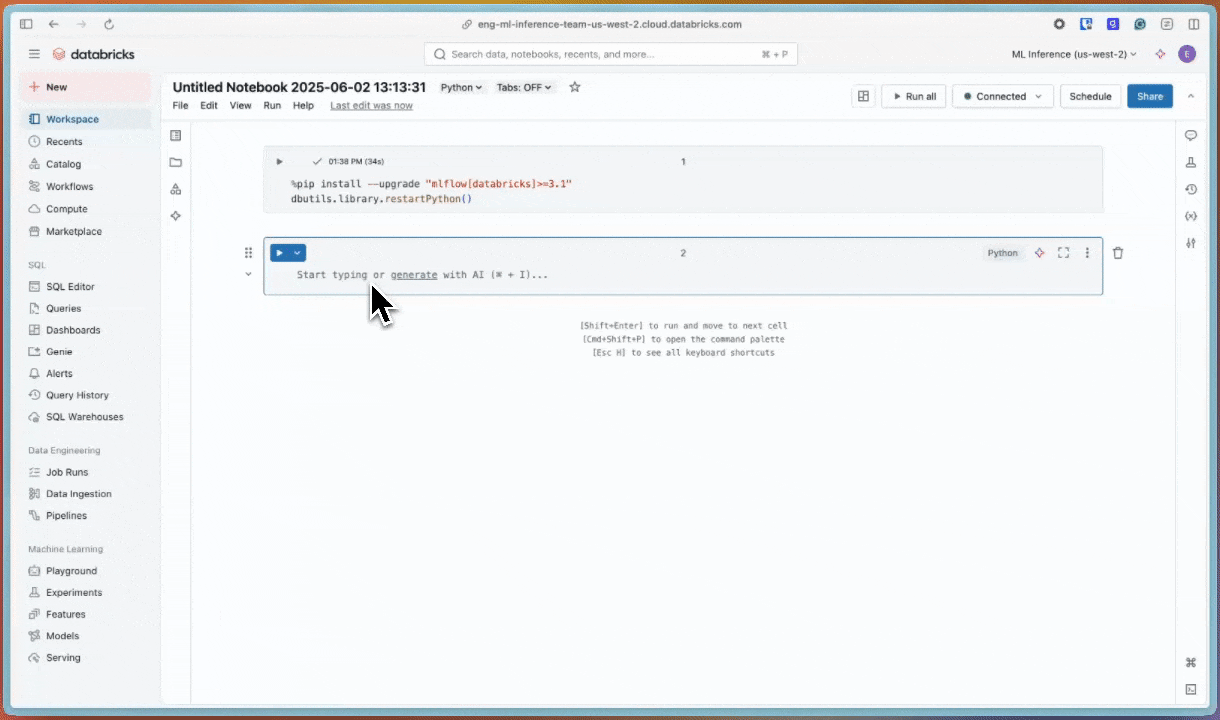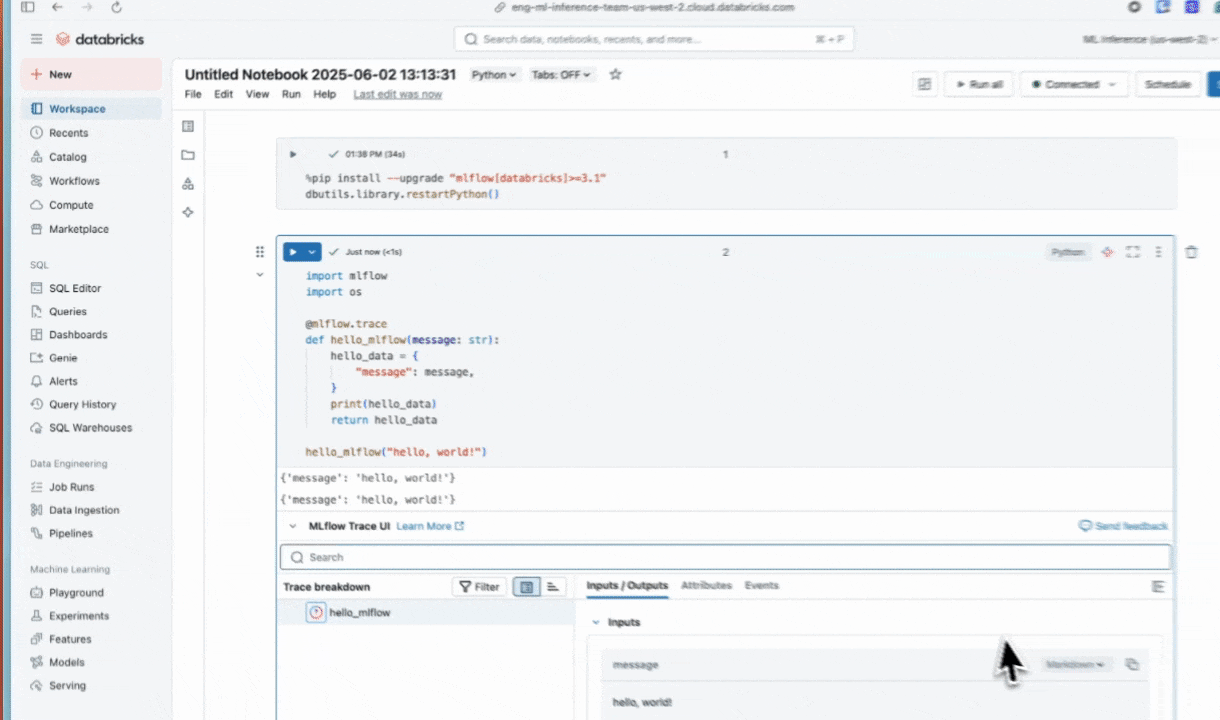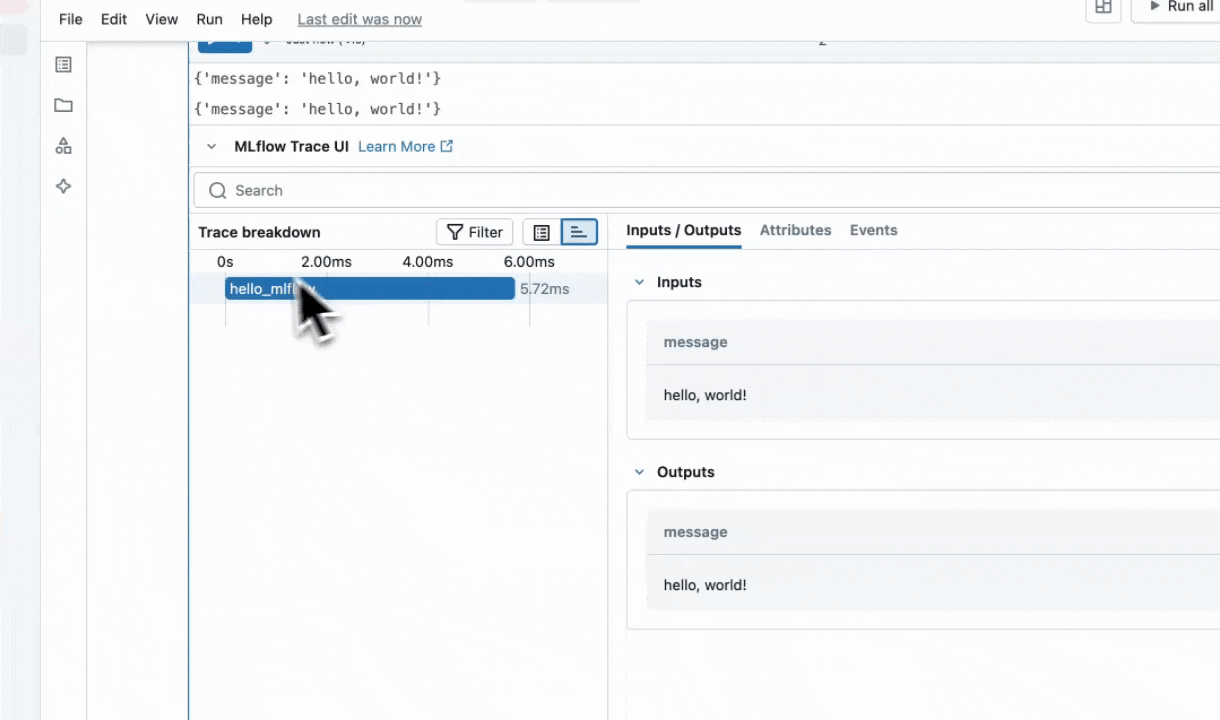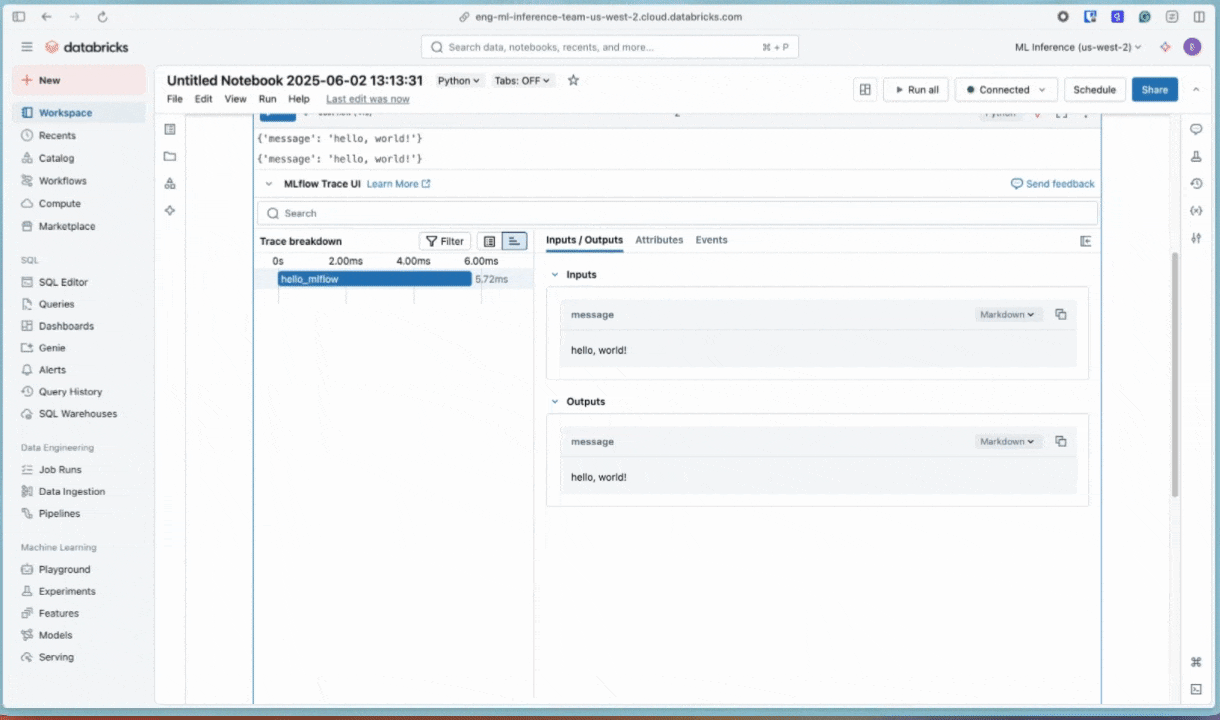
ノートブックのセルでこのコードを実行して、接続を確認します。ノートブックのセルの下に MLflow トレースが表示されます。
Python
import mlflow
import os
@mlflow.trace
def hello_mlflow(message: str):
hello_data = {
"message": message,
}
return hello_data
result = hello_mlflow("hello, world!")
print(result)
その他のリソース
- トレースを使用してアプリを計測可能にする (IDE) - ローカル IDE で 生成AI アプリに MLflow Tracing を追加する
- トレースを使用してアプリを計測可能にする (ノートブック) -MLflow Tracing Databricksノートブックに を追加する
このガイドの概念と機能の詳細については、以下を参照してください。
- MLflow エクスペリメント - 生成AI アプリケーションのエクスペリメント コンテナを理解する
- Databricks 認証 - 利用可能なすべての認証方法を調べる
- トレーシングの概念 - MLflow Tracingの基礎を学ぶ