ラベル付けセッションの作成と管理
ラベリングセッションは、生成AIアプリケーションの動作に関するドメインエキスパートからのフィードバックを収集するための構造化された方法を提供します。ラベル付けセッションは、MLflow レビュー アプリを使用してドメインの専門家にレビューしてもらう特定のトレース セットを含む特殊な種類の MLflow 実行です。
ラベル付けセッションの目的は、既存のMLflow トレース上で人間が生成した評価 (ラベル) を収集することです。FeedbackまたはExpectationのいずれかのデータをキャプチャし、体系的な評価を通じて GenAI アプリを改善することができます。アプリ開発中に評価を収集する方法の詳細については、 「開発中のラベル付け」を参照してください。
ラベル付けセッションは、MLflow UI の [評価] タブに表示されます。ラベル付けセッションは MLflow の実行時にログに記録されるため、MLflow API mlflow.search_runs()を使用してトレースと関連する評価にアクセスすることもできます。
ラベリングセッションの仕組み
ラベル付けセッションは、トレースとその関連ラベルのコンテナとして機能し、評価と改善のワークフローを推進できる体系的なフィードバック収集を可能にします。ラベル付けセッションを作成するときは、以下を定義します。
- 名前: セッションを説明する識別子。
- 割り当てられたユーザー: ラベルを提供するドメイン エキスパート。
- エージェント: (オプション) 必要に応じて応答を生成する GenAI アプリ。
- ラベリング スキーマ: フィードバック収集のための質問と形式。組み込みスキーマ (
EXPECTED_FACTS、EXPECTED_RESPONSE、GUIDELINES) を使用することも、カスタムスキーマを作成することもできます。スキーマの作成と使用の詳細については、 「ラベル付けスキーマの作成と管理」を参照してください。 - マルチターンチャット: 会話形式のラベル付けをサポートするかどうか。
オプションの エージェント フィールドは、対話型テストのためにラベル付けセッションをレビュー アプリのチャット UIに接続します。チャット UI には、モデルサービング エンドポイントにデプロイされたエージェントが必要ですが、現在、 Databricks Appsにデプロイされたエージェントはサポートされていません。 既存のトレースの確認とラベル付けは、エージェントの展開方法に関係なく機能します。
LabelingSession API の詳細については、 mlflow.genai.LabelingSessionを参照してください。
ラベル付けセッションを作成する
UI または API を使用してラベル付けセッションを作成できます。
セッション名は一意ではない可能性があります。MLflow 実行 ID ( session.mlflow_run_id ) を使用してセッションを保存および参照します。
UIを使用してセッションを作成する
MLflow UI でラベル付けセッションを作成するには:
-
Databricksワークスペースの左側のサイドバーで、 [エクスペリメント] をクリックします。
-
エクスペリメントの名前をクリックして開きます。
-
サイドバーの 「セッションのラベル付け」 をクリックします。
-
[セッションの作成] をクリックします。 「ラベル付けセッションの作成」 ダイアログが表示されます。
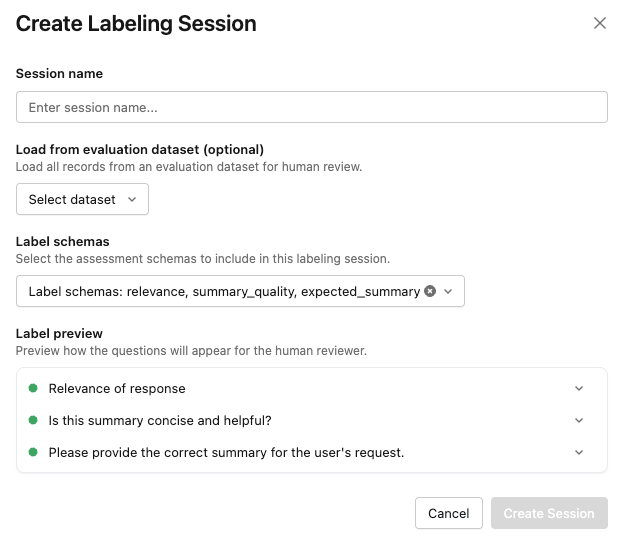
-
セッションの名前を入力します。
オプションで評価データセットを指定したり、ラベル付けスキーマを選択したりすることもできます。
ラベルのプレビュー セクションでは、質問がレビュー担当者にどのように表示されるかを確認できます。
-
準備ができたら、 「セッションを作成」 をクリックしてください。新しいセッションは、ページの左側にあるリストに表示されます。
-
セッションをレビュー担当者と共有するには、リスト内のセッション名をクリックし、右上の [共有] をクリックします。
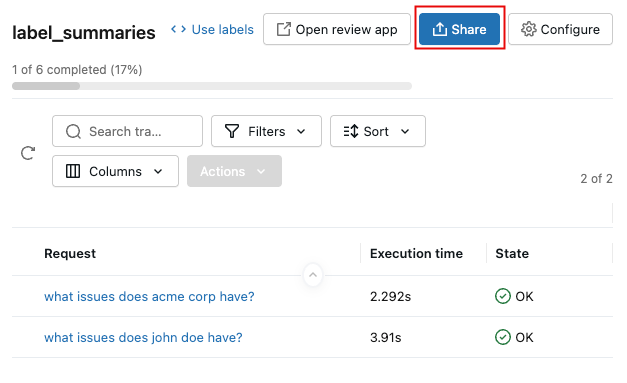
-
各レビュー担当者の電子メール アドレスを入力し、 [保存] をクリックします。 レビュー担当者には通知が送られ、レビュー アプリへのアクセス権が付与されます。
UIでセッションを表示する
セッションのレビュー担当者のフィードバックを表示するには、リスト内のセッション名をクリックし、リクエストをクリックします。
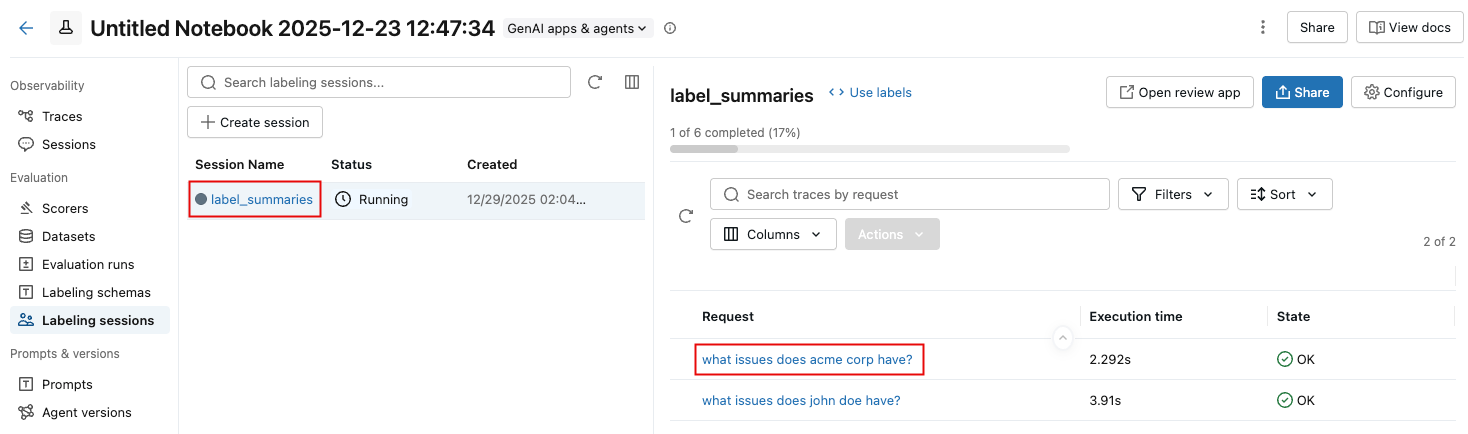
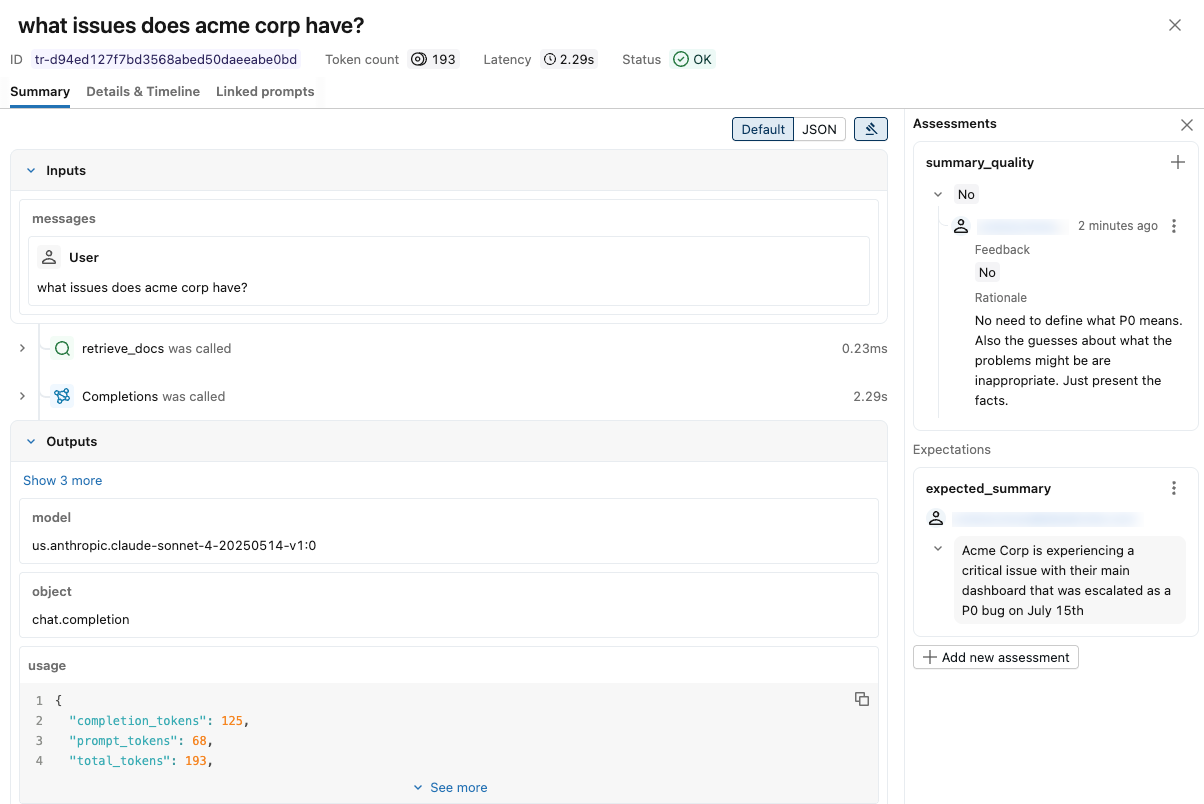
トレース情報とレビュー担当者の評価を示す通知が表示されます。レビュー担当者の意見を表示するには、右上の 「評価」 をクリックしてください。
APIを使用してセッションを作成する
すべての構成オプションをプログラムで完全に制御してセッションを作成するには、MLflow API mlflow.genai.labeling.create_labeling_session()を使用します。
基本セッションを作成する
import mlflow.genai.labeling as labeling
import mlflow.genai.label_schemas as schemas
# Create a simple labeling session with built-in schemas
session = labeling.create_labeling_session(
name="customer_service_review_jan_2024",
assigned_users=["alice@company.com", "bob@company.com"],
label_schemas=[schemas.EXPECTED_FACTS] # Required: at least one schema needed
)
print(f"Created session: {session.name}")
print(f"Session ID: {session.labeling_session_id}")
カスタムラベルスキーマを使用してセッションを作成する
import mlflow.genai.labeling as labeling
import mlflow.genai.label_schemas as schemas
# Create custom schemas first
quality_schema = schemas.create_label_schema(
name="response_quality",
type="feedback",
title="Rate the response quality",
input=schemas.InputCategorical(options=["Poor", "Fair", "Good", "Excellent"]),
overwrite=True,
)
# Create session using the schemas
session = labeling.create_labeling_session(
name="quality_assessment_session",
assigned_users=["expert@company.com"],
label_schemas=["response_quality", schemas.EXPECTED_FACTS],
)
ラベル付けセッションを管理する
APIの詳細については、 mlflow.genai.get_labeling_sessionsとmlflow.genai.delete_labeling_sessionsを参照してください。
セッションを取得する
import mlflow.genai.labeling as labeling
# Get all labeling sessions
all_sessions = labeling.get_labeling_sessions()
print(f"Found {len(all_sessions)} sessions")
for session in all_sessions:
print(f"- {session.name} (ID: {session.labeling_session_id})")
print(f" Assigned users: {session.assigned_users}")
特定のセッションを取得する
import mlflow
import mlflow.genai.labeling as labeling
import pandas as pd
# Get all labeling sessions first
all_sessions = labeling.get_labeling_sessions()
# Find session by name (note: names may not be unique)
target_session = None
for session in all_sessions:
if session.name == "customer_service_review_jan_2024":
target_session = session
break
if target_session:
print(f"Session name: {target_session.name}")
print(f"Experiment ID: {target_session.experiment_id}")
print(f"MLflow Run ID: {target_session.mlflow_run_id}")
print(f"Label schemas: {target_session.label_schemas}")
else:
print("Session not found")
# Alternative: Get session by MLflow Run ID (if you know it)
run_id = "your_labeling_session_run_id"
run = mlflow.search_runs(
experiment_ids=["your_experiment_id"],
filter_string=f"tags.mlflow.runName LIKE '%labeling_session%' AND attribute.run_id = '{run_id}'"
).iloc[0]
print(f"Found labeling session run: {run['run_id']}")
print(f"Session name: {run['tags.mlflow.runName']}")
セッションを削除する
import mlflow.genai.labeling as labeling
# Find the session to delete by name
all_sessions = labeling.get_labeling_sessions()
session_to_delete = None
for session in all_sessions:
if session.name == "customer_service_review_jan_2024":
session_to_delete = session
break
if session_to_delete:
# Delete the session (removes from Review App)
review_app = labeling.delete_labeling_session(session_to_delete)
print(f"Deleted session: {session_to_delete.name}")
else:
print("Session not found")
セッションにトレースを追加する
セッションを作成した後、専門家によるレビューのためにトレースを追加する必要があります。これは UI またはadd_traces() API を使用して実行できます。APIの詳細については、 mlflow.genai.LabelingSession.add_tracesを参照してください。
さまざまなデータ タイプ (辞書、OpenAI メッセージ、ツール呼び出し) の表示方法など、レビュー アプリ UI でトレースがどのようにレンダリングされ、ラベラーに表示されるかの詳細については、 「レビュー アプリ コンテンツのレンダリング」を参照してください。
UIを使用してトレースを追加する
ラベル付けセッションにトレースを追加するには:
-
Databricksワークスペースの左側のサイドバーで、 [エクスペリメント] をクリックします。
-
エクスペリメントの名前をクリックして開きます。
-
サイドバーの 「トレース」 をクリックします。
-
トレース ID の左側にあるボックスをチェックして、追加するトレースを選択します。
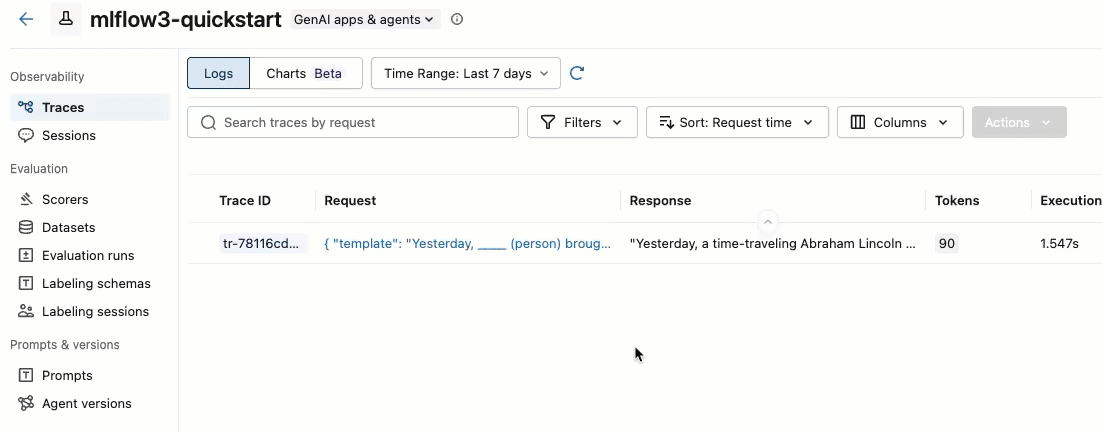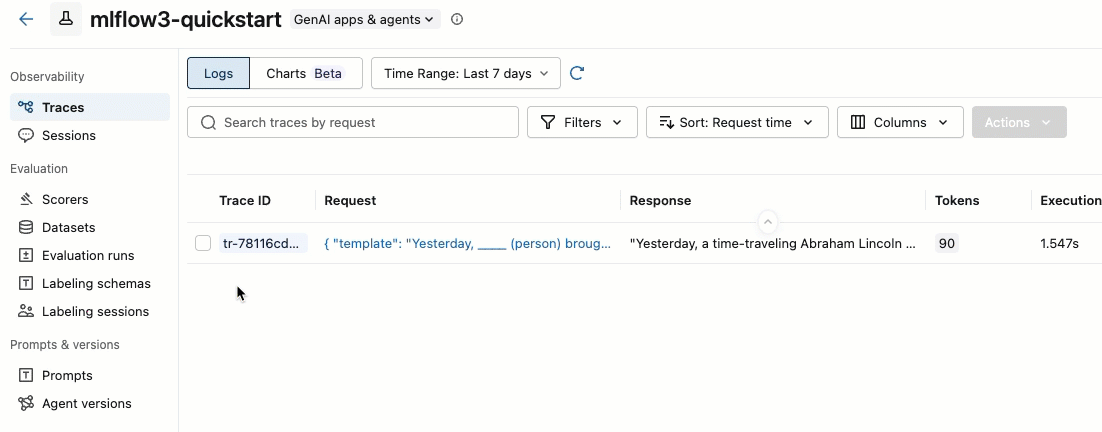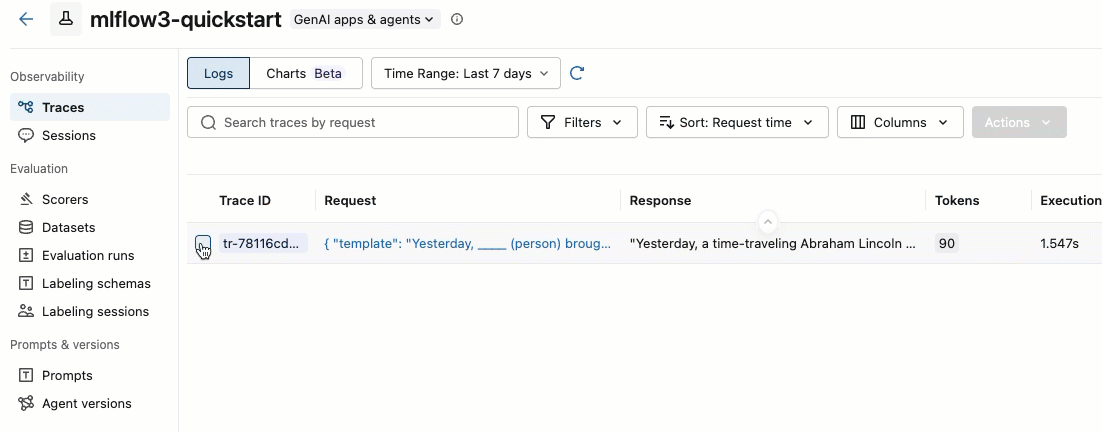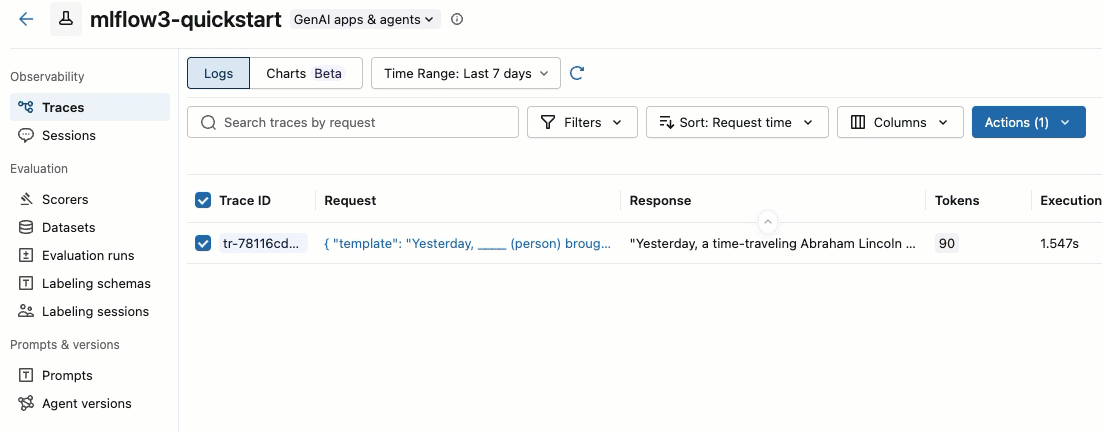
-
[アクション] ドロップダウン メニューから、 [ラベル付けセッションに追加] を選択します。
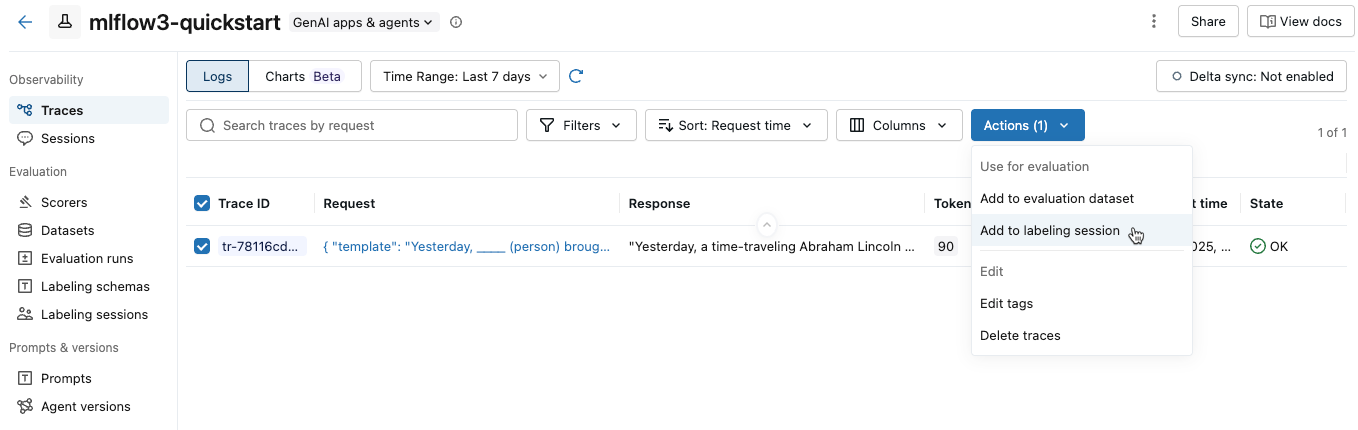
エクスペリメントの既存のラベル付けセッションを示すダイアログが表示されます。
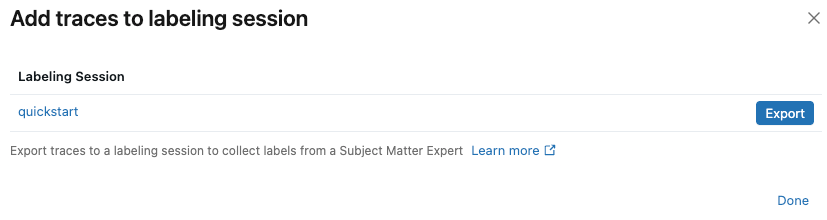
-
ダイアログで、トレースを追加するラベル付けセッションの横にある [エクスポート] をクリックし、 [完了] をクリックします。
検索結果からトレースを追加する
- OpenAI クライアントを初期化して、Databricks でホストされている LLM または OpenAI でホストされている LLM に接続します。
- Databricks-hosted LLMs
- OpenAI-hosted LLMs
databricks-openaiを使用して、Databricks がホストする LLM に接続する OpenAI クライアントを取得します。利用可能なプラットフォームモデルからモデルを選択します。
import mlflow
from databricks_openai import DatabricksOpenAI
# Enable MLflow's autologging to instrument your application with Tracing
mlflow.openai.autolog()
# Set up MLflow tracking to Databricks
mlflow.set_tracking_uri("databricks")
mlflow.set_experiment("/Shared/docs-demo")
# Create an OpenAI client that is connected to Databricks-hosted LLMs
client = DatabricksOpenAI()
# Select an LLM
model_name = "databricks-claude-sonnet-4"
ネイティブの OpenAI SDK を使用して、OpenAI でホストされるモデルに接続します。利用可能なOpenAIモデルからモデルを選択します。
import mlflow
import os
import openai
# Ensure your OPENAI_API_KEY is set in your environment
# os.environ["OPENAI_API_KEY"] = "<YOUR_API_KEY>" # Uncomment and set if not globally configured
# Enable auto-tracing for OpenAI
mlflow.openai.autolog()
# Set up MLflow tracking to Databricks
mlflow.set_tracking_uri("databricks")
mlflow.set_experiment("/Shared/docs-demo")
# Create an OpenAI client connected to OpenAI SDKs
client = openai.OpenAI()
# Select an LLM
model_name = "gpt-4o-mini"
-
サンプルトレースを作成し、ラベリングセッションに追加します。
Pythonimport mlflow.genai.labeling as labeling
# First, create some sample traces with a simple app
@mlflow.trace
def support_app(question: str):
"""Simple support app that generates responses"""
mlflow.update_current_trace(tags={"test_tag": "C001"})
response = client.chat.completions.create(
model=model_name, # This example uses Databricks hosted Claude 3.5 Sonnet. If you provide your own OpenAI credentials, replace with a valid OpenAI model e.g., gpt-4o, etc.
messages=[
{"role": "system", "content": "You are a helpful customer support agent."},
{"role": "user", "content": question},
],
)
return {"response": response.choices[0].message.content}
# Generate some sample traces
with mlflow.start_run():
# Create traces with negative feedback for demonstration
support_app("My order is delayed")
support_app("I can't log into my account")
# Now search for traces to label
traces_df = mlflow.search_traces(
filter_string="tags.test_tag = 'C001'", max_results=50
)
# Create session and add traces
session = labeling.create_labeling_session(
name="negative_feedback_review",
assigned_users=["quality_expert@company.com"],
label_schemas=["response_quality", "expected_facts"]
)
# Add traces from search results
session.add_traces(traces_df)
print(f"Added {len(traces_df)} traces to session")
個々のトレースオブジェクトを追加する
- OpenAI クライアントを初期化して、Databricks でホストされている LLM または OpenAI でホストされている LLM に接続します。
- Databricks-hosted LLMs
- OpenAI-hosted LLMs
databricks-openaiを使用して、Databricks がホストする LLM に接続する OpenAI クライアントを取得します。利用可能なプラットフォームモデルからモデルを選択します。
import mlflow
from databricks_openai import DatabricksOpenAI
# Enable MLflow's autologging to instrument your application with Tracing
mlflow.openai.autolog()
# Set up MLflow tracking to Databricks
mlflow.set_tracking_uri("databricks")
mlflow.set_experiment("/Shared/docs-demo")
# Create an OpenAI client that is connected to Databricks-hosted LLMs
client = DatabricksOpenAI()
# Select an LLM
model_name = "databricks-claude-sonnet-4"
ネイティブの OpenAI SDK を使用して、OpenAI でホストされるモデルに接続します。利用可能なOpenAIモデルからモデルを選択します。
import mlflow
import os
import openai
# Ensure your OPENAI_API_KEY is set in your environment
# os.environ["OPENAI_API_KEY"] = "<YOUR_API_KEY>" # Uncomment and set if not globally configured
# Enable auto-tracing for OpenAI
mlflow.openai.autolog()
# Set up MLflow tracking to Databricks
mlflow.set_tracking_uri("databricks")
mlflow.set_experiment("/Shared/docs-demo")
# Create an OpenAI client connected to OpenAI SDKs
client = openai.OpenAI()
# Select an LLM
model_name = "gpt-4o-mini"
-
個々のトレースオブジェクトを作成し、ラベリングセッションに追加します。
Pythonimport mlflow.genai.labeling as labeling
# Set up the app to generate traces
@mlflow.trace
def support_app(question: str):
"""Simple support app that generates responses"""
mlflow.update_current_trace(tags={"test_tag": "C001"})
response = client.chat.completions.create(
model=model_name, # This example uses Databricks hosted Claude 3.5 Sonnet. If you provide your own OpenAI credentials, replace with a valid OpenAI model e.g., gpt-4o, etc.
messages=[
{"role": "system", "content": "You are a helpful customer support agent."},
{"role": "user", "content": question},
],
)
return {"response": response.choices[0].message.content}
# Generate specific traces for edge cases
with mlflow.start_run() as run:
# Create traces for specific scenarios
support_app("What's your refund policy?")
trace_id_1 = mlflow.get_last_active_trace_id()
support_app("How do I cancel my subscription?")
trace_id_2 = mlflow.get_last_active_trace_id()
support_app("The website is down")
trace_id_3 = mlflow.get_last_active_trace_id()
# Get the trace objects
trace1 = mlflow.get_trace(trace_id_1)
trace2 = mlflow.get_trace(trace_id_2)
trace3 = mlflow.get_trace(trace_id_3)
# Create session and add traces
session = labeling.create_labeling_session(
name="negative_feedback_review",
assigned_users=["name@databricks.com"],
label_schemas=["response_quality", schemas.EXPECTED_FACTS],
)
# Add individual traces
session.add_traces([trace1, trace2, trace3])
フィードバック回答を取得
レビュアーがラベリングセッションを完了した後、MLflow はその応答をセッション内のトレース上に Assessments として保存します。UIまたはMLflow APIを使用して取得できます。
- UI
- API
エクスペリメント UI を開き、ラベル付けセッションをクリックしてから、リクエストをクリックします。右上の 評価 をクリックして、各レビュアーの回答を表示します。スクリーンショットについては、「UI を使用したセッションの表示」を参照してください。
mlflow.search_traces() をセッションの mlflow_run_id で使用します。返されたDataFrameには、各レビュアーのラベルを含むassessments列が含まれています。
import mlflow
traces = mlflow.search_traces(run_id=session.mlflow_run_id)
print(traces[["trace_id", "assessments"]])
APIの詳細については、 mlflow.search_tracesを参照してください。
割り当てられたユーザーの管理
ユーザーアクセス要件
Databricks アカウント内のすべてのユーザーは、ワークスペースへのアクセス権があるかどうかに関係なく、ラベル付けセッションに割り当てることができます。ただし、ラベル付けセッションに対するアクセス許可をユーザーに付与すると、ラベル付けセッションの MLflow エクスペリメントにアクセスできるようになります。
ユーザーのアクセス許可を設定する
- ワークスペースにアクセスできないユーザーの場合、アカウント管理者はアカウント レベルの SCIM プロビジョニングを使用して、ユーザーとグループを ID プロバイダーから Databricks アカウントに自動的に同期します。また、これらのユーザーとグループを手動で登録して、 Databricksで ID を設定するときにアクセス権を付与することもできます。 ユーザーとグループの管理を参照してください。
- レビュー アプリを含むワークスペースへのアクセス権を既に持っているユーザーの場合、追加の構成は必要ありません。
ユーザーをラベル付けセッションに割り当てると、システムは、ラベル付けセッションを含むMLflow拡張機能に対する必要なWRITE権限を自動的に付与します。 これにより、割り当てられたユーザーには、実験データを表示および操作するためのアクセス権が付与されます。
既存のセッションにユーザーを追加する
既存のセッションにユーザーを追加するには、 set_assigned_usersを使用します。APIの詳細については、 mlflow.genai.LabelingSession.set_assigned_usersを参照してください。
import mlflow.genai.labeling as labeling
# Find existing session by name
all_sessions = labeling.get_labeling_sessions()
session = None
for s in all_sessions:
if s.name == "customer_review_session":
session = s
break
if session:
# Add more users to the session
new_users = ["expert2@company.com", "expert3@company.com"]
session.set_assigned_users(session.assigned_users + new_users)
print(f"Session now has users: {session.assigned_users}")
else:
print("Session not found")
割り当てられたユーザーを置き換える
import mlflow.genai.labeling as labeling
# Find session by name
all_sessions = labeling.get_labeling_sessions()
session = None
for s in all_sessions:
if s.name == "session_name":
session = s
break
if session:
# Replace all assigned users
session.set_assigned_users(["new_expert@company.com", "lead_reviewer@company.com"])
print("Updated assigned users list")
else:
print("Session not found")
評価データセットへの同期
収集したExpectationsを評価データセットに同期できます。
データセット同期の仕組み
sync()メソッドはインテリジェントな upsert 操作を実行します。APIの詳細については、 mlflow.genai.LabelingSession.syncを参照してください。
- 各トレースの入力は、データセット内のレコードを識別するための一意のキーとして機能します。
- 一致する入力を持つトレースの場合、期待値の名前が同じであれば、ラベル付けセッションからの期待値がデータセット内の既存の期待値を上書きします。
- データセット内の既存のトレース入力と一致しないラベリング セッションからのトレースは、新しいレコードとして追加されます。
- 異なる入力を持つ既存のデータセット レコードは変更されません。
このアプローチにより、新しい例を追加し、既存の例のグラウンドトゥルースを更新することで、評価データセットを反復的に改善できます。
データセットの同期
import mlflow.genai.labeling as labeling
# Find session with completed labels by name
all_sessions = labeling.get_labeling_sessions()
session = None
for s in all_sessions:
if s.name == "completed_review_session":
session = s
break
if session:
# Sync expectations to dataset
session.sync(to_dataset="customer_service_eval_dataset")
print("Synced expectations to evaluation dataset")
else:
print("Session not found")
ベストプラクティス
セッションの構成
-
customer_service_review_march_2024のような、明確で説明的な日付入りの名前を使用します。 -
特定の評価目標または期間に焦点を絞ったセッションを維持します。
-
レビュー担当者の疲労を避けるために、1 セッションあたり 25 ~ 100 件のトレースを目標にしてください。
-
セッションを作成するときは常に
session.mlflow_run_idを保存します。セッション名は一意ではない可能性があるため、プログラムによるアクセスにはセッション名に頼るのではなく、実行 ID を使用します。Pythonimport mlflow.genai.labeling as labeling
# Good: Store run ID for later reference
session = labeling.create_labeling_session(name="my_session", ...)
session_run_id = session.mlflow_run_id # Store this!
# Later: Use run ID to find session via mlflow.search_runs()
# rather than searching by name through all sessions
ユーザー管理
- ドメインの専門知識と可用性に基づいてユーザーを割り当てます。
- ラベル付け作業を複数の専門家に均等に分散します。
- ユーザーは Databricks ワークスペースにアクセスできる必要があることに注意してください。
その他のリソース
- 既存のトレースのラベル付け - ラベル付けセッションを使用したステップバイステップガイド
- カスタムラベリングスキーマの作成 - 構造化されたフィードバックの質問を定義します
- 評価データセットの構築 - ラベル付けされたセッションをテスト データセットに変換します