既存のトレースをラベル付けしてフィードバックと期待を収集する
生成AIアプリケーションを改善する最も効果的な方法の1つは、ドメインの専門家に既存のトレースをレビューし、ラベル付けしてもらうことです。MLflow のレビュー アプリは、アプリケーションとの実際の対話に関するこの専門家のフィードバックを収集するための構造化されたプロセスを提供します。

既存のトレースにラベルを付けるタイミング
専門家に依頼して、アプリとの既存のインタラクションを確認し、 フィードバック と 期待値を提供します。
レビューアプリを使って以下のことができます。
- 特定のクエリに対する高品質で正しい応答がどのようなものかを理解する
- LLMジャッジをビジネス要件に合わせて調整するための情報を収集します
- 本番運用 トレース から評価データセットを作成
専門家によるレビューのためにトレースを特定する
ラベル付けセッションを作成する前に、専門家のレビューが役立つトレースを特定します。人間の判断が必要なケースに焦点を当てます。
- 曖昧または境界線の品質のトレース
- 自動判定でカバーされないエッジケース
- 自動化されたメトリクスが期待される品質と一致しない例
- さまざまなユーザーインタラクションパターンの代表的なサンプル
MLflow UI では、ステータス、タグ、または時間範囲でトレースをフィルターできます。高度なフィルターを使用したプログラムによる選択については、 「SDK 経由のクエリ トレース」を参照してください。
前提 条件
-
MLflowとその必要なパッケージをインストールする必要があります。このガイドで説明する機能を使用するには、MLflow バージョン 3.1.0 が必要です。またはそれ以上。MLflow SDK(Databricksとの統合に必要な追加機能を含む)をインストールまたはアップグレードするには、次のコマンドを実行してください。
Bashpip install --upgrade "mlflow[databricks]>=3.1.0" openai "databricks-connect>=16.1" -
開発環境は、GenAI アプリケーション トレースが記録されるMLflowエクスペリメントに接続する必要があります。
- 開発環境を接続するには、「チュートリアル: 開発環境を MLflow に接続する」に従ってください。
-
ドメインエキスパートがレビューアプリを使用して既存のトレースにラベルを付けるには、以下の権限が必要です。
-
アカウント アクセス : Databricksアカウントでプロビジョニングを行う必要がありますが、ワークスペースにアクセスする必要はありません。
ワークスペースへのアクセス権を持たないユーザーの場合、アカウント管理者は次のことができます。
- アカウントレベルの SCIM プロビジョニングを使用して、ID プロバイダからユーザーを同期します。
- Databricksにユーザーとグループを手動で登録する
詳細については、ユーザーとグループの管理 を参照してください。
-
エクスペリメント アクセス : MLflowエクスペリメントへの
CAN_EDIT権限。
-
ステップ 1: トレースのあるアプリを作成する
フィードバックを収集するには、まずGenAIアプリケーションからログに記録されたトレースを取得する必要があります。これらのトレースは、アプリケーションの実行における入力、出力、および中間ステップ(ツール呼び出しやリトリーバ操作を含む)をキャプチャします。
以下はトレースをログに記録する方法の例です。この例には偽のリトリーバーが含まれているため、トレース内の取得されたドキュメントがレビュー アプリでどのようにレンダリングされるかを示すことができます。レビュー アプリがトレースをレンダリングする方法の詳細については、「レビュー アプリのコンテンツのレンダリング」を参照してください。
- OpenAI クライアントを初期化して、Databricks でホストされている LLM または OpenAI でホストされている LLM に接続します。
- Databricks-hosted LLMs
- OpenAI-hosted LLMs
databricks-openaiを使用して、Databricks がホストする LLM に接続する OpenAI クライアントを取得します。利用可能なプラットフォームモデルからモデルを選択します。
import mlflow
from databricks_openai import DatabricksOpenAI
# Enable MLflow's autologging to instrument your application with Tracing
mlflow.openai.autolog()
# Set up MLflow tracking to Databricks
mlflow.set_tracking_uri("databricks")
mlflow.set_experiment("/Shared/docs-demo")
# Create an OpenAI client that is connected to Databricks-hosted LLMs
client = DatabricksOpenAI()
# Select an LLM
model_name = "databricks-claude-sonnet-4"
ネイティブの OpenAI SDK を使用して、OpenAI でホストされるモデルに接続します。利用可能なOpenAIモデルからモデルを選択します。
import mlflow
import os
import openai
# Ensure your OPENAI_API_KEY is set in your environment
# os.environ["OPENAI_API_KEY"] = "<YOUR_API_KEY>" # Uncomment and set if not globally configured
# Enable auto-tracing for OpenAI
mlflow.openai.autolog()
# Set up MLflow tracking to Databricks
mlflow.set_tracking_uri("databricks")
mlflow.set_experiment("/Shared/docs-demo")
# Create an OpenAI client connected to OpenAI SDKs
client = openai.OpenAI()
# Select an LLM
model_name = "gpt-4o-mini"
-
アプリケーションを定義します。
Pythonfrom mlflow.entities import Document
from typing import List, Dict
# Spans of type RETRIEVER are rendered in the Review App as documents.
@mlflow.trace(span_type="RETRIEVER")
def retrieve_docs(query: str) -> List[Document]:
normalized_query = query.lower()
if "john doe" in normalized_query:
return [
Document(
id="conversation_123",
page_content="John Doe mentioned issues with login on July 10th. Expressed interest in feature X.",
metadata={"doc_uri": "http://domain.com/conversations/123"},
),
Document(
id="conversation_124",
page_content="Follow-up call with John Doe on July 12th. Login issue resolved. Discussed pricing for feature X.",
metadata={"doc_uri": "http://domain.com/conversations/124"},
),
]
else:
return [
Document(
id="ticket_987",
page_content="Acme Corp raised a critical P0 bug regarding their main dashboard on July 15th.",
metadata={"doc_uri": "http://domain.com/tickets/987"},
)
]
# Sample app to review traces from
@mlflow.trace
def my_app(messages: List[Dict[str, str]]):
# 1. Retrieve conversations based on the last user message
last_user_message_content = messages[-1]["content"]
retrieved_documents = retrieve_docs(query=last_user_message_content)
retrieved_docs_text = "\n".join([doc.page_content for doc in retrieved_documents])
# 2. Prepare messages for the LLM
messages_for_llm = [
{"role": "system", "content": "You are a helpful assistant!"},
{
"role": "user",
"content": f"Additional retrieved context:\n{retrieved_docs_text}\n\nNow, please provide the one-paragraph summary based on the user's request {last_user_message_content} and this retrieved context.",
},
]
# 3. Call LLM to generate the summary
return client.chat.completions.create(
model=model_name, # This example uses :re[DB] hosted claude-sonnet-4-5. If you provide your own OpenAI credentials, replace with a valid OpenAI model e.g., gpt-4o, etc.
messages=messages_for_llm,
)
ステップ 2: ラベル付けスキーマを定義する
ラベリングスキーマは、ドメインの専門家がトレースに関するフィードバックを提供するために使用する質問と入力タイプを定義します。MLflow の組み込みスキーマを使用することも、特定の評価基準に合わせたカスタムスキーマを作成することもできます。
ラベリングスキーマには、主に次の 2 つのタイプがあります。
- 期待値タイプ(
type="expectation"): 専門家が「グラウンドトゥルース」または正しい答えを提供するときに使用されます。たとえば、RAG システムの応答のexpected_factsを提供します。これらのラベルは、多くの場合、評価データセットで直接使用できます。 - フィードバックの種類 (
type="feedback"): 主観的な評価、評価、または分類に使用されます。たとえば、礼儀正しさについて1〜5のスケールで回答を評価したり、回答が特定の基準を満たしているかどうかを分類したりします。
ラベル付けスキーマの作成と管理を参照して、カテゴリ選択、数値尺度、自由形式のテキストなど、スキーマのさまざまな入力方法を理解してください。
from mlflow.genai.label_schemas import create_label_schema, InputCategorical, InputText
# Collect feedback on the summary
summary_quality = create_label_schema(
name="summary_quality",
type="feedback",
title="Is this summary concise and helpful?",
input=InputCategorical(options=["Yes", "No"]),
instruction="Please provide a rationale below.",
enable_comment=True,
overwrite=True,
)
# Collect a ground truth summary
expected_summary = create_label_schema(
name="expected_summary",
type="expectation",
title="Please provide the correct summary for the user's request.",
input=InputText(),
overwrite=True,
)
ステップ 3: ラベル付けセッションを作成する
ラベリングセッションは、選択されたラベリングスキーマを使用して特定の専門家によるレビューのために一連のトレースを整理する、 MLflow実行の特殊なタイプです。 これは審査プロセスのキューとして機能します。
詳細については、 「ラベル付けセッションの作成と管理」を参照してください。
ラベル付けセッションを作成する方法は次のとおりです。
from mlflow.genai.labeling import create_labeling_session
# Create the labeling session with the schemas we created in the previous step
label_summaries = create_labeling_session(
name="label_summaries",
assigned_users=[],
label_schemas=[summary_quality.name, expected_summary.name],
)
ステップ 4: トレースを生成し、ラベル付けセッションに追加します
ラベリングセッションを作成したら、そこにトレースを追加する必要があります。トレースデータはラベル付けセッションにコピーされるため、レビュープロセス中に作成されたラベルや変更は、元のログに記録されたトレースデータには影響しません。
MLflowエクスペリメントには任意のトレースを追加できます。 詳細については、 「ラベル付けセッションの作成と管理」を参照してください。
トレースが生成された後、トレースタブでトレースを選択し、「トレース のエクスポート」 をクリックして、以前に作成したラベリングセッションを選択することで、それらをラベリングセッションに追加することもできます。
import mlflow
# Use version tracking to be able to easily query for the traces
tracked_model = mlflow.set_active_model(name="my_app")
# Run the app to generate traces
sample_messages_1 = [
{"role": "user", "content": "what issues does john doe have?"},
]
summary1_output = my_app(sample_messages_1)
sample_messages_2 = [
{"role": "user", "content": "what issues does acme corp have?"},
]
summary2_output = my_app(sample_messages_2)
# Query for the traces we just generated
traces = mlflow.search_traces(model_id=tracked_model.model_id)
# Add the traces to the session
label_summaries.add_traces(traces)
# Print the URL to share with your domain experts
print(f"Share this Review App with your team: {label_summaries.url}")
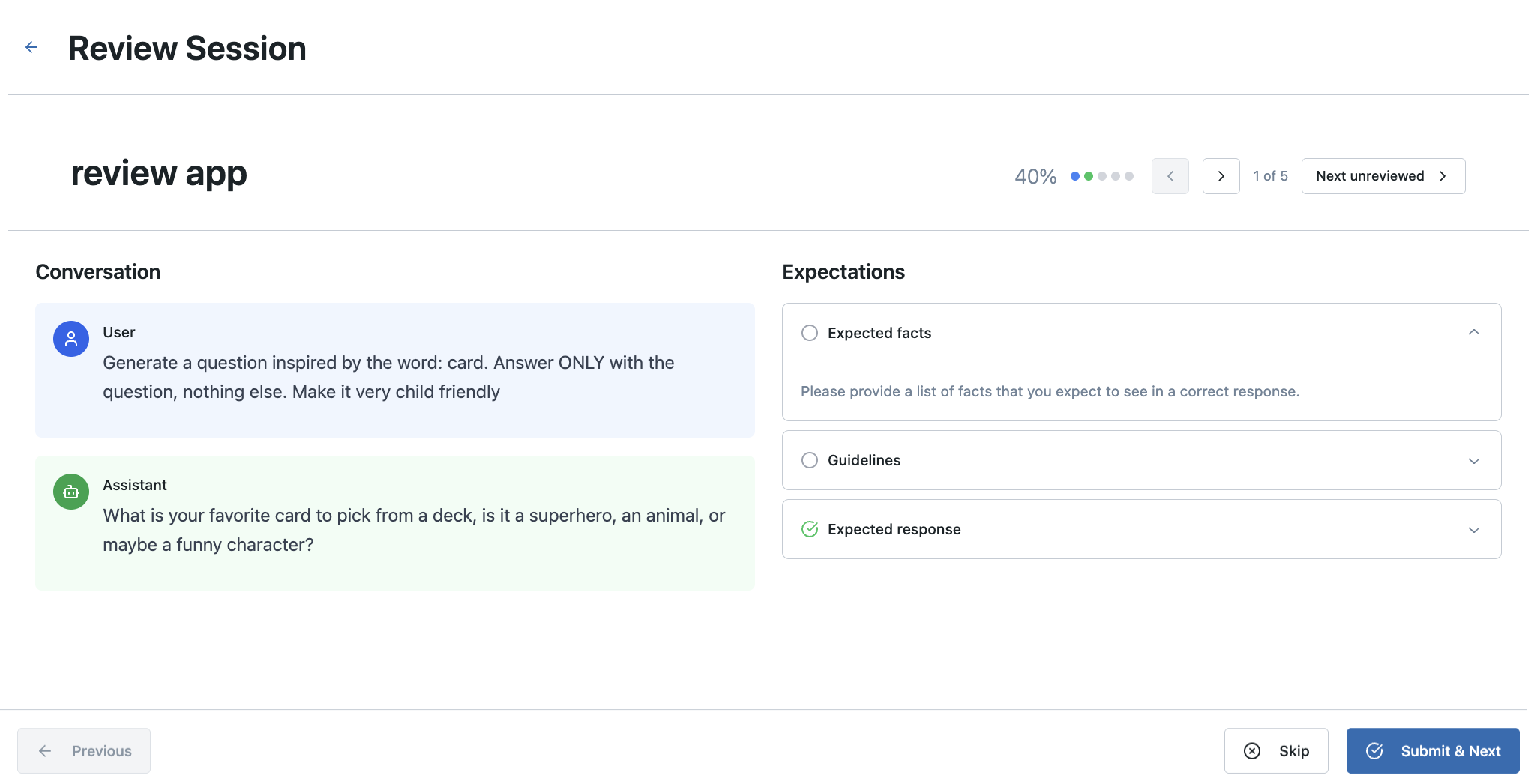
ステップ 5: レビュー アプリを専門家と共有する
ラベル付けセッションにトレースデータが入力されたら、そのURLをドメインエキスパートと共有できます。このURLを使用してレビューアプリにアクセスし、自分に割り当てられたトレースを表示したり(または未割り当てのトレースから選択したり)、設定したラベル付けスキームを使用してフィードバックを提供したりできます。
ドメイン エキスパートは、 Databricksアカウントでプロビジョニングを行っており、 MLflowエクスペリメントに対するCAN_EDIT権限を持っている必要があります。 Databricksワークスペースにアクセスする必要はありません。 アカウントレベルのアクセス設定方法の詳細については、「前提条件」セクションを参照してください。

レビューアプリのUIをカスタマイズする(オプション)
カスタム トレースの視覚化、カスタマイズされたラベル付けインターフェース、または特定のワークフローを必要とするユース ケースでは、カスタマイズ可能なレビュー アプリ テンプレートを展開します。この オープンソース テンプレートは、同じMLflowバックエンドAPIsとデータ モデル (ラベル付けセッション、スキーマ、評価) を使用しながら、フロントエンド エクスペリエンスを完全に制御できます。 カスタマイズ オプションには次のものが含まれます。
- エージェントタイプに特化したトレースレンダラー
- カスタムラベルインターフェースのレイアウトとインタラクション
- ドメイン固有の視覚化
- レビュー担当者に表示されるトレース情報を制御する
テンプレート リポジトリには、プログラムによるセットアップ用のコマンド ライン ツールや、対話型カスタマイズ用の AI アシスタント (Claude Code) が含まれています: GitHub - custom-mlflow-review-app 。カスタマイズされたレビュー アプリはDatabricksアプリとして展開され、既存のMLflowエクスペリメントおよびラベル付けセッションと直接統合されます。 完全なカスタマイズとデプロイメントの手順については、テンプレート リポジトリのドキュメントを参照してください。
カスタマイズ可能なテンプレートは、カスタム トレースの視覚化、評価ワークフロー、または標準のレビュー アプリ インターフェースを超える特定の UI 要件を必要とするチームに最適です。標準評価ワークフローの場合、組み込みレビュー アプリは、追加のセットアップなしで本番運用に対応したソリューションを提供します。
ステップ 6: 収集したラベルを表示して使用する
ドメインの専門家がレビューを完了すると、収集されたフィードバックがラベリングセッション内のトレースに添付されます。これらのラベルは、プログラムで取得して分析したり、評価データセットの作成に使用したりできます。
ラベルは、ラベル付けセッション内の各 にAssessment Traceオブジェクトとして保存されます。
MLflow UI を使用する
結果を確認するには、 MLflowエクスペリメントにアクセスしてください。

MLflow SDK を使用する
次のコードは、ラベル付けセッションの実行からすべてのトレースをフェッチし、評価 (ラベル) を Pandas DataFrame に抽出して分析を容易にします。
labeled_traces_df = mlflow.search_traces(run_id=label_summaries.mlflow_run_id)
アプリコンテンツのレンダリングを確認する
既存のトレースにラベルを付ける際、レビューアプリは既存のトレースの入力と出力を使用し、結果をラベル付けセッション内のMLflowトレースに保存します。ユースケースにおける質問と基準を定義するには、独自のラベル付けスキーマを提供する必要があります。
レビュー アプリは、MLflow トレースからさまざまなコンテンツ タイプを自動的にレンダリングします。
-
取得されたドキュメント :
RETRIEVERの範囲内のドキュメントが表示用にレンダリングされます -
OpenAI 形式のメッセージ : OpenAI チャット会話に続く MLflow トレースの入力と出力がレンダリングされます。
outputsOpenAI形式のChatCompletionsオブジェクトを含むinputsまたは、 OpenAI 形式のチャット メッセージの配列を含むmessagesキーを含むoutputsの辞書messages配列にOpenAI形式のツール呼び出しが含まれている場合、ツール呼び出しもレンダリングされます。
-
辞書 : 辞書であるMLflowトレースの入力と出力は、きれいに印刷されたJSONとしてレンダリングされます。
それ以外の場合は、各トレースのルートスパンのinputとoutputコンテンツがレビューの主なコンテンツとして使用されます。
ノートブックの例
次のノートブックには、このページのすべてのコードが含まれています。
ドメイン専門家のフィードバック ノートブックを収集する
次のステップ
評価データセットへの変換
「期待値」タイプのラベル(例の expected_summary など)は、 評価データセットを作成するのに特に役立ちます。これらのデータセットを mlflow.genai.evaluate() とともに使用して、専門家が定義したグラウンドトゥルースに対して生成AIアプリケーションの新しいバージョンを体系的にテストできます。