生成AI アプリとエージェントのための MLflow
従来のソフトウェアと ML テストは、生成AI の自由形式言語用に構築されていない ため、チームが品質を測定して改善することは困難です。
MLflow は、 生成AI の品質を確実に測定する AI を活用したメトリクス と包括的な トレースの可観測性 を組み合わせることでこれを解決し、アプリケーションのライフサイクル全体を通じて品質 を測定、改善、監視 できるようにします。
MLflow が 生成AI アプリとエージェントの品質の測定と改善にどのように役立つか
MLflow は、ユーザーからのフィードバックとドメインの専門家の判断の両方を組み込んだ継続的な改善サイクルを調整するのに役立ちます。開発から本番運用まで、人間の専門知識に合わせて調整された一貫した品質メトリクス(スコアラー)を使用し、自動化された評価が実際の品質基準を反映するようにします。
継続的な改善サイクル
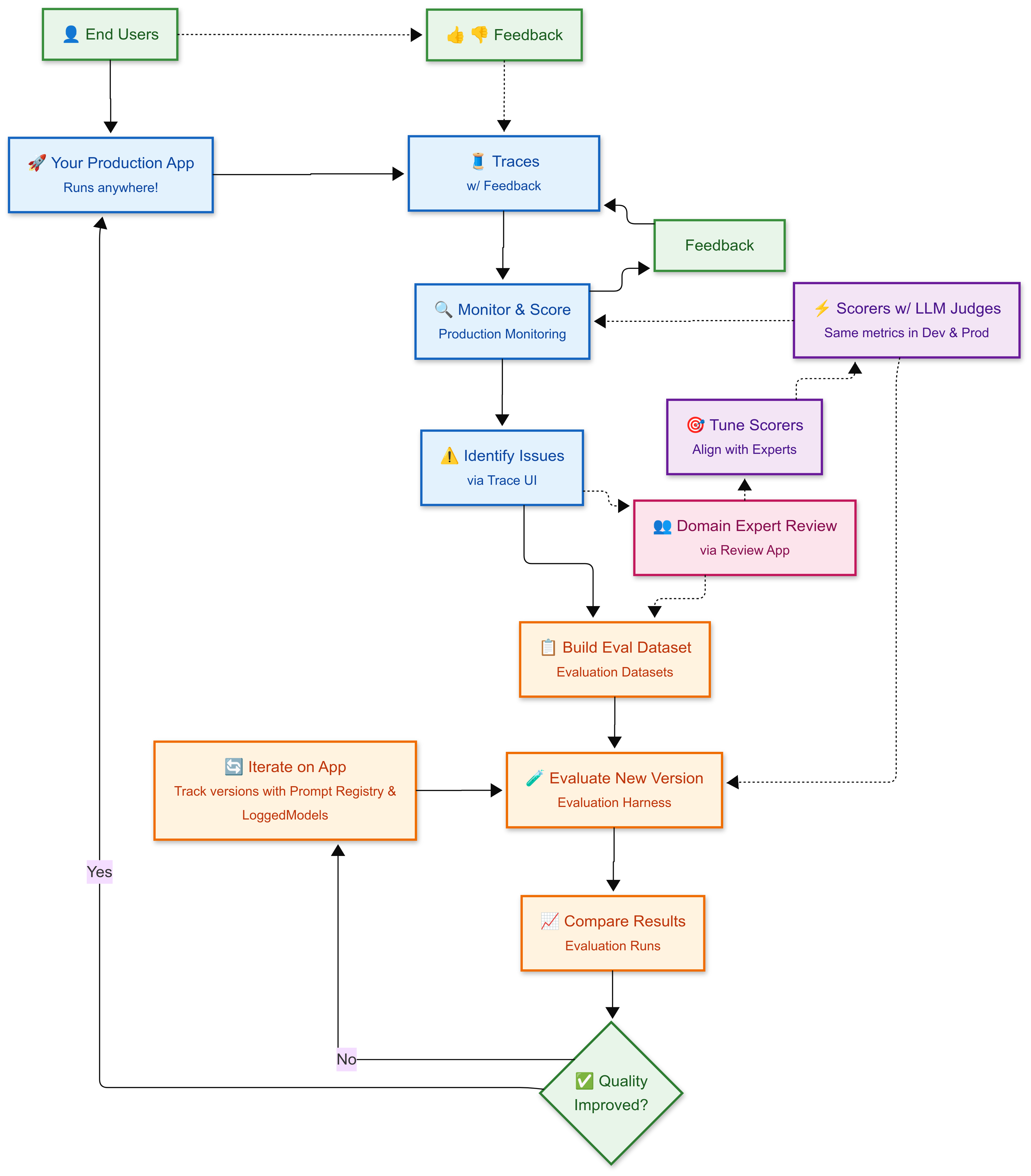
-
🚀 本番運用アプリ : デプロイされた 生成AI アプリは、ユーザーにサービスを提供し、すべてのインタラクションのすべてのステップ、入力、出力を含む詳細な実行トレースを含む トレース を生成します
-
👍 👎 ユーザーフィードバック :エンドユーザーは、各トレースに添付されるフィードバック(親指のアップ/ダウン、評価)を提供し、品質問題の特定に役立ちます
-
🔍 モニター & スコア : 本番運用 モニタリングは品質を評価するために、トレースに対してスコアラーを自動で実行し、各トレースにフィードバックを添付します
-
⚠️ 問題の特定 : Trace UI を使用して、エンドユーザーと LLM ジャッジのフィードバックを通じて、低スコアのトレースのパターンを見つけます
-
👥 ドメインエキスパートレビュー :オプションで、 レビューアプリ を介してトレースのサンプルをドメインエキスパートに送信し、詳細なラベリングと品質評価を行います
-
📋 評価データセットの構築 : 問題のあるトレースと高品質のトレースの両方を 評価データセット にキュレーションして、良い点を維持しながら悪い点を修正できるようにします
-
🎯 スコアラーの調整 : 必要に応じて、専門家のフィードバックを使用して、スコアラーとジャッジを人間の判断に合わせ、自動スコアラーが人間の判断を表すようにします
-
🧪 新しいバージョンの評価 : 評価ハーネス を使用して、評価データセットに対して改善されたアプリのバージョンをテストし、モニタリングと同じ スコアラー を適用して品質が向上したか後退したかを評価します。オプションで、 バージョン 管理と プロンプト 管理を使用して作業を追跡します。
-
📈 結果の比較 : 評価ハーネスによって生成された 評価ランを使用して、バージョン間で比較し、パフォーマンスの高いバージョンを特定します
-
✅ デプロイまたは反復 : 品質がリグレッションなしで改善された場合は、デプロイします。それ以外の場合は、反復して再評価します
このアプローチが有効な理由
- 人間によって調整されたメトリクス : スコアラー は、ドメインの専門家の判断に合わせて調整され、自動評価が人間の品質基準を反映するようにします
- 一貫性のあるメトリクス : 開発と本番運用の両方で同じスコアラーが働きます
- 実世界のデータ :本番運用トレースがテストケースとなり、実際のユーザーの問題を確実に解決
- 体系的な検証 : すべての変更は、デプロイ前に回帰データセットに対してテストされます
- 継続的な学習 : 各サイクルでは、アプリと評価データセットの両方が改善されます
次のステップ
- クイックスタート ガイドに従ってトレースを設定し、最初の評価を実行し、ドメイン エキスパートからのフィードバックを収集します。
- MLflow を駆動する主要な抽象化 (トレースから評価データセット、スコアラーまで) の概念 的な理解 を得ます。