LlamaIndex のトレース
LlamaIndex は、大規模言語モデルが任意の形式のデータを操作できるようにするエージェント生成AI アプリケーションを構築するためのオープンソースフレームワークです。
MLflow Tracing は、LlamaIndex の自動トレース機能を提供します。トレースを有効にすることができます
LlamaIndex の mlflow.llama_index.autolog 関数を呼び出して、ネストされたトレースは、LlamaIndex エンジンとワークフローの呼び出し時にアクティブなMLflowエクスペリメントに自動的に記録されます。
import mlflow
mlflow.llama_index.autolog()
サーバレス コンピュート クラスターでは、自動ログは自動的に有効になりません。 この統合の自動トレースを有効にするには、明示的に mlflow.llama_index.autolog() を呼び出す必要があります。
MLflow LlamaIndex の統合は、トレースだけではありません。MLflow は、モデルの追跡、インデックス管理、評価など、LlamaIndex の完全な追跡エクスペリエンスを提供します。
前提 条件
LlamaIndex で MLflow Tracing を使用するには、 MLflow と llama-index ライブラリをインストールする必要があります。
- Development
- Production
開発環境の場合は、Databricks の追加機能と llama-indexを含む完全な MLflow パッケージをインストールします。
pip install --upgrade "mlflow[databricks]>=3.1" llama-index
フル mlflow[databricks] パッケージには、Databricks でのローカル開発と実験のためのすべての機能が含まれています。
本番運用デプロイメントの場合は、 mlflow-tracing と llama-indexをインストールします。
pip install --upgrade mlflow-tracing llama-index
mlflow-tracingパッケージは、本番運用での使用に最適化されています。
MLflow 3 は、LlamaIndex で最高のトレース エクスペリエンスを実現することを強くお勧めします。
例を実行する前に、環境を構成する必要があります。
Databricks ノートブックの外部ユーザーの場合 : Databricks 環境変数を設定します。
export DATABRICKS_HOST="https://your-workspace.cloud.databricks.com"
export DATABRICKS_TOKEN="your-personal-access-token"
Databricks ノートブック内のユーザーの場合 : これらの資格情報は自動的に設定されます。
APIキー :LLMプロバイダーのAPIキーが正しく設定されていることを確認してください。本番運用環境の場合は、安全なAPIキー管理のために、ハードコードされた値の代わりにAI Gateway またはDatabricksシークレットを使用します。
export OPENAI_API_KEY="your-openai-api-key"
# Add other provider keys as needed
使用例
まず、テストデータをダウンロードしておもちゃのインデックスを作成しましょう。
!mkdir -p data
!curl -L https://raw.githubusercontent.com/run-llama/llama_index/main/docs/docs/examples/data/paul_graham/paul_graham_essay.txt -o ./data/paul_graham_essay.txt
それらを単純なメモリ内ベクトルインデックスにロードします。
from llama_index.core import VectorStoreIndex, SimpleDirectoryReader
documents = SimpleDirectoryReader("data").load_data()
index = VectorStoreIndex.from_documents(documents)
これで、LlamaIndex 自動トレースを有効にして、インデックスのクエリを開始できます。
import mlflow
import os
# Ensure your OPENAI_API_KEY (or other LLM provider keys) is set in your environment
# os.environ["OPENAI_API_KEY"] = "your-openai-api-key" # Uncomment and set if not globally configured
# Enabling tracing for LlamaIndex
mlflow.llama_index.autolog()
# Set up MLflow tracking to Databricks
mlflow.set_tracking_uri("databricks")
mlflow.set_experiment("/Shared/llamaindex-demo")
# Query the index
query_engine = index.as_query_engine()
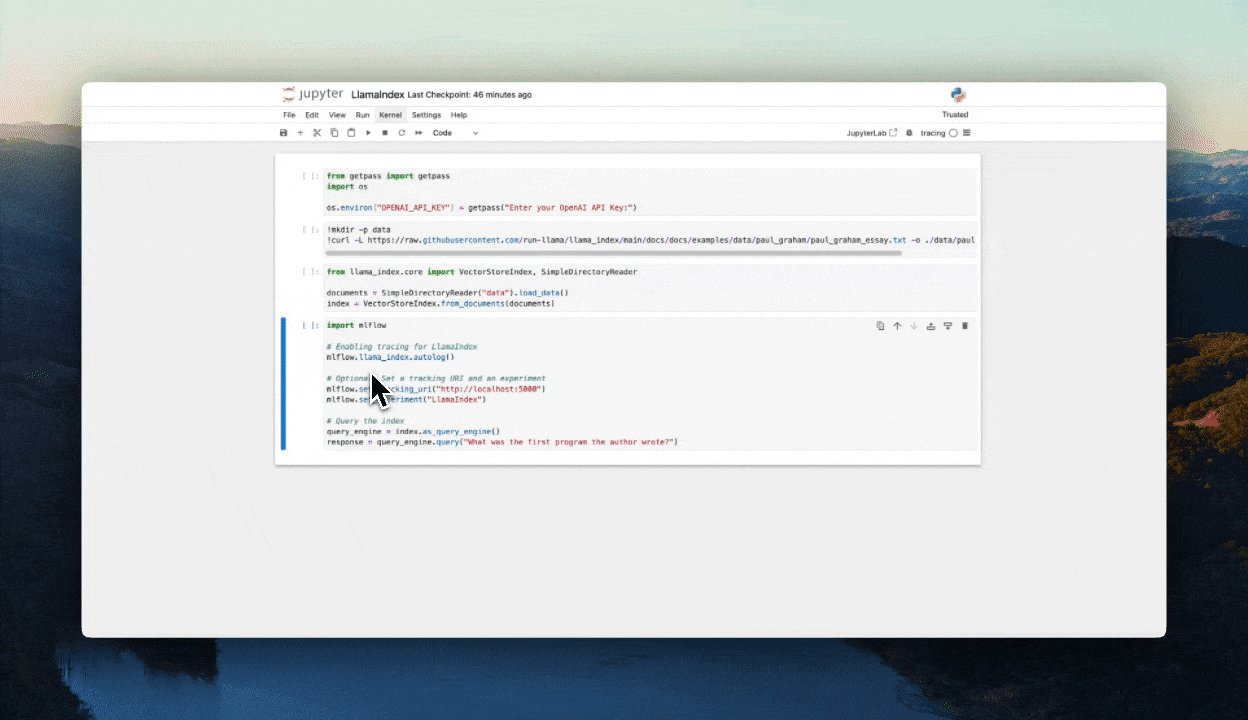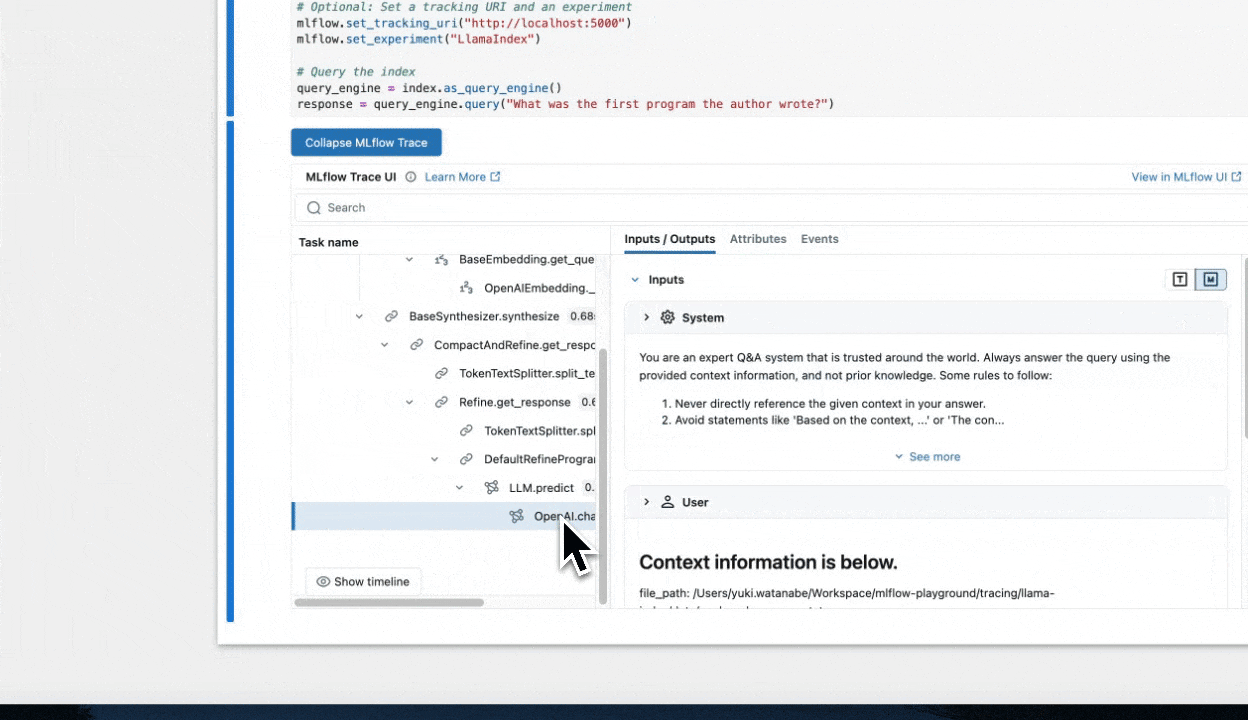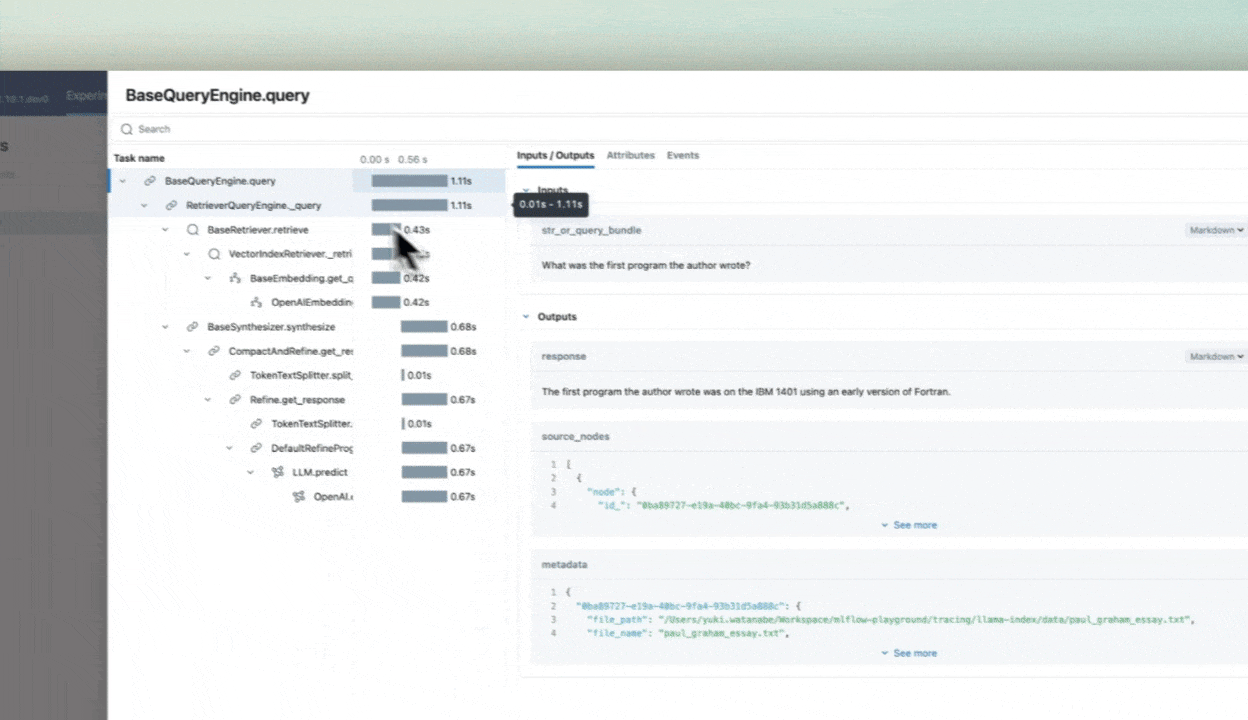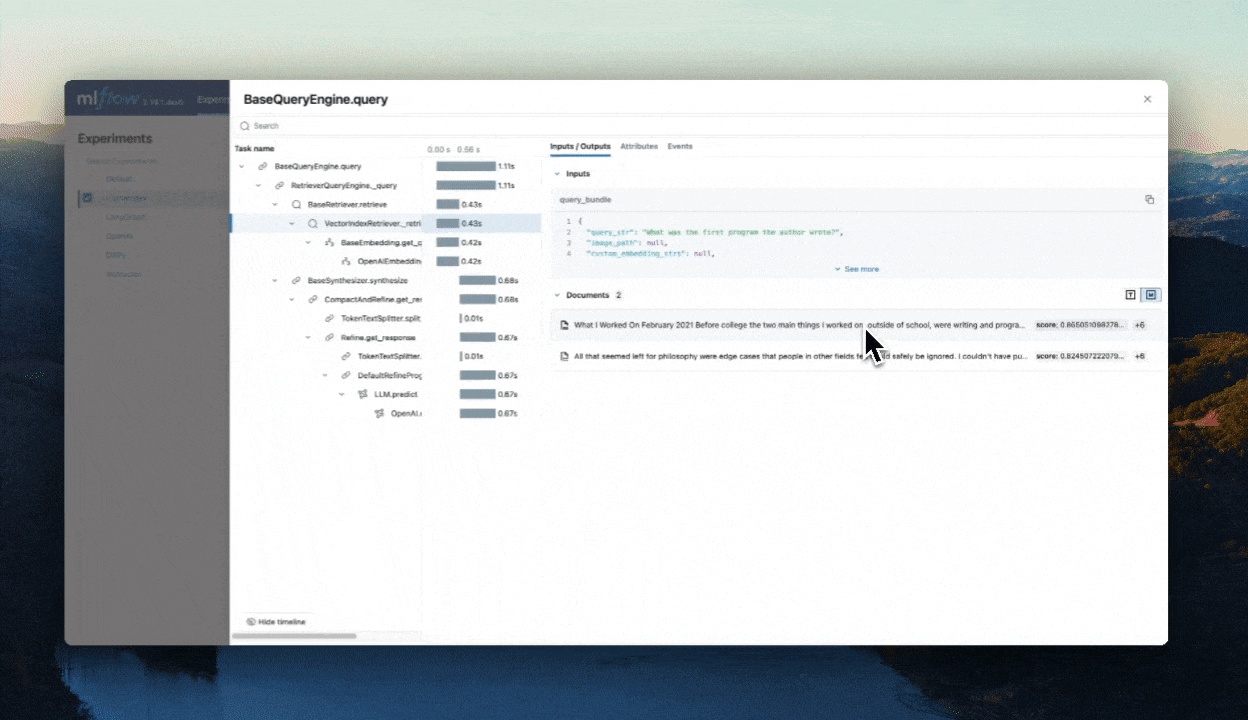
response = query_engine.query("What was the first program the author wrote?")
本番運用環境の場合は、安全なAPIキー管理のために、ハードコードされた値の代わりにAI Gateway またはDatabricksシークレットを使用します。
LlamaIndex ワークフロー
Workflowは、LlamaIndexの次世代生成AIオーケストレーションフレームワークです。これは、エージェント、RAG フロー、データ抽出パイプラインなどの任意の LLM アプリケーションを構築するための柔軟で解釈可能なフレームワークとして設計されています。MLflow は、ワークフロー オブジェクトの追跡、評価、トレースをサポートしているため、オブジェクトの観察と保守が容易になります。
LlamaIndex ワークフローの自動トレースは、同じ mlflow.llama_index.autolog()を呼び出すことで既製で機能します。
自動トレースを無効にする
LlamaIndex の自動トレースは、 mlflow.llama_index.autolog(disable=True) または mlflow.autolog(disable=True)を呼び出すことでグローバルに無効にできます。