MLflow評価データセットの構築
GenAI アプリケーションを体系的にテストして改善するには、評価データセットを使用します。評価データセットは、ラベル付き(予想される出力が既知)またはラベルなし(真の回答なし)のいずれかのサンプル入力の選択されたセットです。評価データセットは、次の方法でアプリのパフォーマンスを向上させるのに役立ちます。
- 本番運用での既知の問題例に対する修正をテストすることで、品質を向上させます。
- 回帰を防止します。常に正しく動作する例の「ゴールデン セット」を作成します。
- アプリのバージョンを比較します。同じデータに対して、さまざまなプロンプト、モデル、またはアプリ ロジックをテストします。
- 特定の機能をターゲットにします。安全性、ドメイン知識、またはエッジケースに特化したデータセットを構築します。
- LLMOps の一環として、さまざまな環境にわたってアプリを検証します。
MLflow評価データセットはUnity Catalogに保存され、統合されたバージョニング、リネージ、共有、ガバナンスが提供されます。
要件
- 評価データセットを作成するには、Unity Catalog スキーマに対する
CREATE TABLE権限が必要です。 - MLflowエクスペリメントには評価データセットが添付されます。 まだエクスペリメントをお持ちでない場合は、 MLflowエクスペリメントの作成」を参照してエクスペリメントを作成してください。
評価データセットのデータソース
評価データセットを作成するには、次のいずれかを使用できます。
- 既存のトレース。GenAI アプリケーションからすでにトレースをキャプチャしている場合は、それを使用して、実際のシナリオに基づいた評価データセットを作成できます。
- 既存のデータセット、または直接入力された例。このオプションは、迅速なプロトタイピングや特定の機能を対象としたテストに役立ちます。
- 合成データ。Databricks はドキュメントから代表的な評価セットを自動的に生成できるため、テスト ケースを十分にカバーしたエージェントを迅速に評価できます。
このページでは、MLflow 評価データセットを作成する方法について説明します。Pandas DataFrames や辞書のリストなど、他の種類のデータセットを使用することもできます。例については、 GenAI の MLflow 評価例を参照してください。
UI を使用してデータセットを作成する
これらのステップに従って、UI を使用して既存のトレースからデータセットを作成します。
-
サイドバーの 「体験」 をクリックして「体験」ページを表示します。
-
表で、実験の名前をクリックして開きます。
-
左側のサイドバーで、 [Traces] をクリックします。
-
トレース リストの左側にあるチェックボックスを使用して、データセットにエクスポートするトレースを選択します。すべてのトレースを選択するには、 トレース ID の横にあるボックスをクリックします。
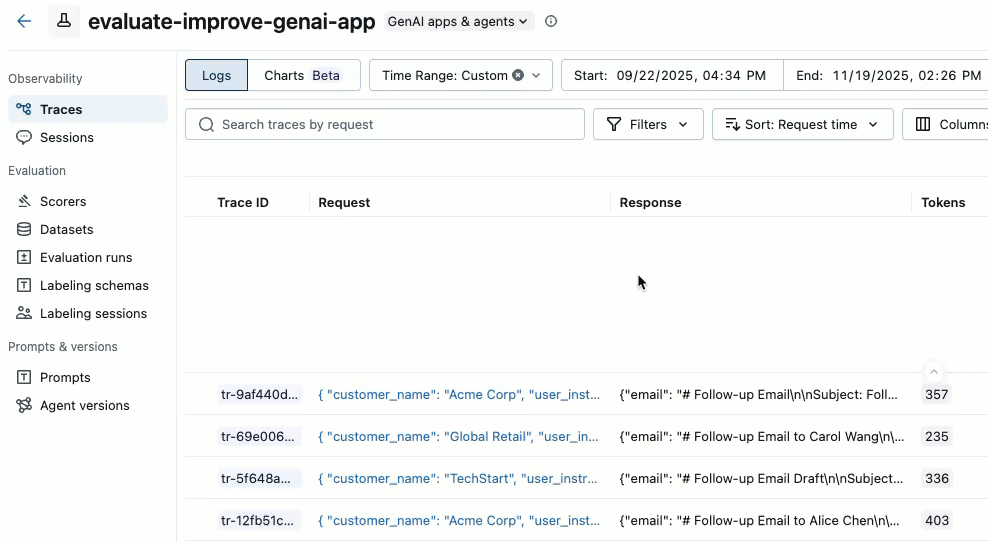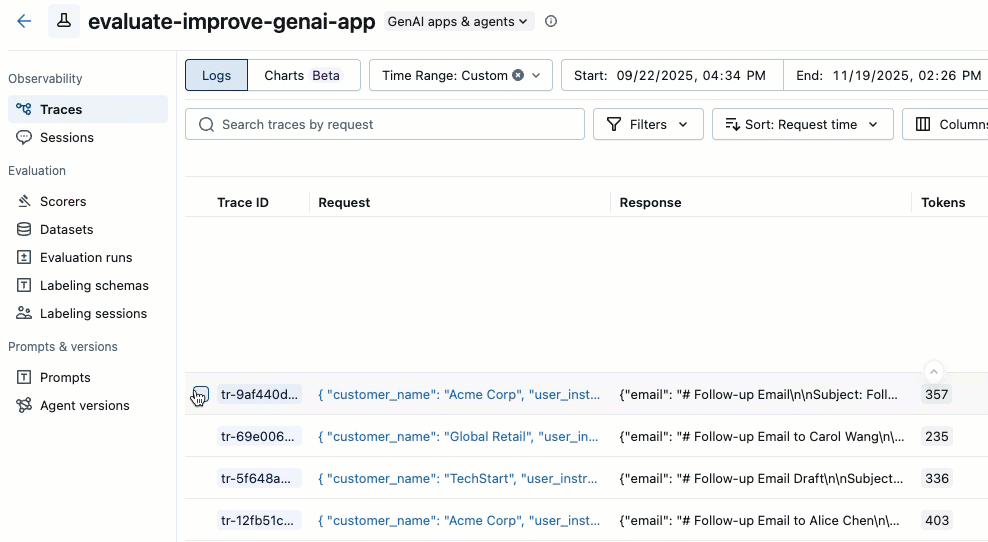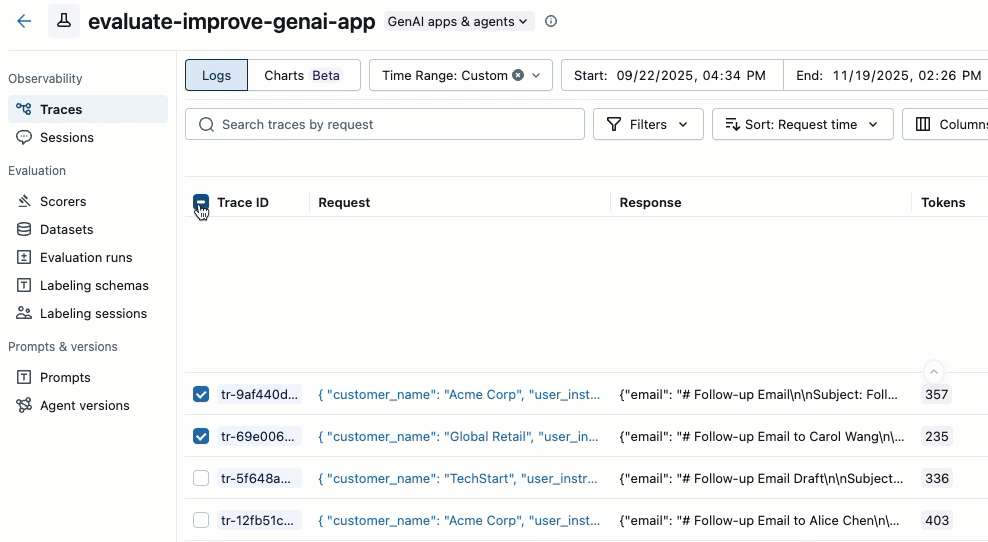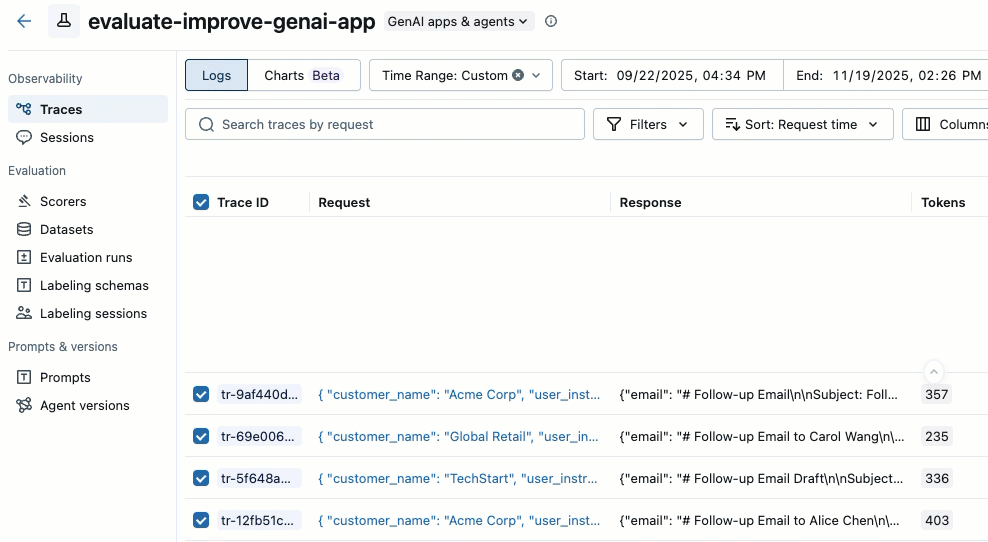
-
[アクション] をクリックします。ドロップダウン メニューから、 評価データセットに追加を 選択します。
-
「評価データセットにトレースを追加」 ダイアログが表示されます。
このエクスペリメントの評価データセットが存在する場合、ダイアログに表示されます。
- これらのトレースを追加するデータセットの横にある [エクスポート] をクリックします。
- トレースがエクスポートされると、ボタンが 「エクスポート済み」 に変わります。 「完了」 をクリックします。
エクスペリメントの評価データセットが存在しない場合:
- [新しいデータセットの作成] をクリックします。
- [データセットの作成] ダイアログで、 [スキーマの選択] をクリックし、データセットを保持するスキーマを選択します。
- 確認 をクリックします。
- 「評価データセットの作成」 ダイアログの 「テーブル名」 フィールドに評価データセットの名前を入力し、 「データセットの作成」を クリックします。
- 「評価データセットにトレースを追加」 ダイアログが表示され、作成したデータセットが表示されます。データセットの横にある [エクスポート] をクリックします。
- トレースがエクスポートされると、ボタンが 「エクスポート済み」 に変わります。 「完了」 をクリックします。
SDKを使用してデータセットを作成する
SDKを使用してデータセットを作成するには、次のステップに従ってください。
ステップ 1. データセットを作成する
import mlflow
import mlflow.genai.datasets
import time
from databricks.connect import DatabricksSession
# 0. If you are using a local development environment, connect to Serverless Spark which powers MLflow's evaluation dataset service
spark = DatabricksSession.builder.remote(serverless=True).getOrCreate()
# 1. Create an evaluation dataset
# Replace with a Unity Catalog schema where you have CREATE TABLE permission
uc_schema = "workspace.default"
# This table will be created in the above UC schema
evaluation_dataset_table_name = "email_generation_eval"
eval_dataset = mlflow.genai.datasets.create_dataset(
name=f"{uc_schema}.{evaluation_dataset_table_name}",
)
print(f"Created evaluation dataset: {uc_schema}.{evaluation_dataset_table_name}")
ステップ 2: データセットにレコードを追加する
このセクションでは、評価データセットにレコードを追加するためのいくつかのオプションについて説明します。
- From existing traces
- From domain expert labels
- Build from scratch or import existing
- Seed using synthetic data
関連する評価データセットを構築する最も効果的な方法の 1 つは、MLflow Tracing によってキャプチャされたアプリケーションの過去のインタラクションから直接例をキュレーションすることです。トレースからデータセットを作成するには、 MLflow モニタリング UI または SDKを使用します。
プログラムでトレースを検索し、 search_traces()を使用してデータセットに追加します。フィルターを使用して、成功、失敗、本番運用での使用、またはその他のプロパティによってトレースを識別します。 「プログラムによるトレースの検索」を参照してください。
import mlflow
# 2. Search for traces
traces = mlflow.search_traces(
filter_string="attributes.status = 'OK'",
order_by=["attributes.timestamp_ms DESC"],
tags.environment = 'production',
max_results=10
)
print(f"Found {len(traces)} successful traces")
# 3. Add the traces to the evaluation dataset
eval_dataset = eval_dataset.merge_records(traces)
print(f"Added {len(traces)} records to evaluation dataset")
# Preview the dataset
df = eval_dataset.to_df()
print(f"\nDataset preview:")
print(f"Total records: {len(df)}")
print("\nSample record:")
sample = df.iloc[0]
print(f"Inputs: {sample['inputs']}")
評価データセットのトレースの選択
トレースをデータセットに追加する前に、評価ニーズにとって重要なテスト ケースを表すトレースを特定します。代表的なトレースを選択するために、定量分析と定性分析の両方を使用できます。
定量的トレース選択
MLflow UI または SDK を使用して、測定可能な特性に基づいてトレースをフィルター処理および分析します。
- MLflow UI では 、タグ (例:
tag.quality_score < 0.7) でフィルタリングしたり、特定の入力/出力を検索したり、レイテンシやトークンの使用状況で並べ替えたりできます。 - プログラムで : トレースをクエリして高度な分析を実行する
import mlflow
import pandas as pd
# Search for traces with potential quality issues
traces_df = mlflow.search_traces(
filter_string="tag.quality_score < 0.7",
max_results=100
)
# Analyze patterns
# For example, check if quality issues correlate with token usage
correlation = traces_df["span.attributes.usage.total_tokens"].corr(traces_df["tag.quality_score"])
print(f"Correlation between token usage and quality: {correlation}")
完全なトレース クエリ構文と例については、 「プログラムによるトレースの検索」を参照してください。
定性的なトレースの選択
個々のトレースをレビューして、人間の判断が必要なパターンを特定します。
- 低品質の出力につながった入力を調べる
- アプリケーションがエッジケースをどのように処理したかのパターンを探す
- 文脈の欠落や誤った推論を特定する
- 高品質のトレースと低品質のトレースを比較して差別化要因を理解する
代表的なトレースを特定したら、上記の検索およびマージ方法を使用して、それらをデータセットに追加します。
予想される出力や品質インジケーターを使用してトレースを充実させ、グラウンドトゥルースの比較を可能にします。人間によるラベルを追加するには、 「ドメイン エキスパートのフィードバックを収集」を参照してください。
MLflow ラベル付けセッションで収集されたドメイン エキスパートからのフィードバックを活用して、グラウンド トゥルース ラベルで評価データセットを充実させます。これらのステップを実行する前に、ドメイン エキスパート フィードバックの収集ガイドに従ってラベル付けセッションを作成してください。
import mlflow.genai.labeling as labeling
# Get a labeling sessions
all_sessions = labeling.get_labeling_sessions()
print(f"Found {len(all_sessions)} sessions")
for session in all_sessions:
print(f"- {session.name} (ID: {session.labeling_session_id})")
print(f" Assigned users: {session.assigned_users}")
# Sync from the labeling session to the dataset
all_sessions[0].sync(dataset_name=f"{uc_schema}.{evaluation_dataset_table_name}")
専門家のフィードバックを収集した後、人間のフィードバックに合わせてジャッジを調整できます。「ジャッジを人間に合わせる」を参照してください。
既存のデータセットをインポートしたり、例を最初からキュレーションしたりできます。データは 、評価データセットのスキーマと一致する (または一致するように変換される) 必要があります。
# Define comprehensive test cases
evaluation_examples = [
{
"inputs": {"question": "What is MLflow?"},
"expected": {
"expected_response": "MLflow is an open source platform for managing the end-to-end machine learning lifecycle.",
"expected_facts": [
"open source platform",
"manages ML lifecycle",
"experiment tracking",
"model deployment"
]
},
},
]
eval_dataset = eval_dataset.merge_records(evaluation_examples)
合成データを生成すると、多様な入力を迅速に作成し、エッジケースをカバーすることで、テストの取り組みを拡大できます。評価セットの合成を参照してください。
既存のデータセットを更新する
評価データセットを更新するには、UI または SDK を使用できます。
- Databricks UI
- MLflow SDK
UI を使用して、既存の評価データセットにレコードを追加します。
-
Databricks ワークスペースでデータセット ページを開きます。
- Databricksワークスペースで、エクスペリメントに移動します。
- 左側のサイドバーで、 [データセット] をクリックします。
- リスト内のデータセットの名前をクリックします。
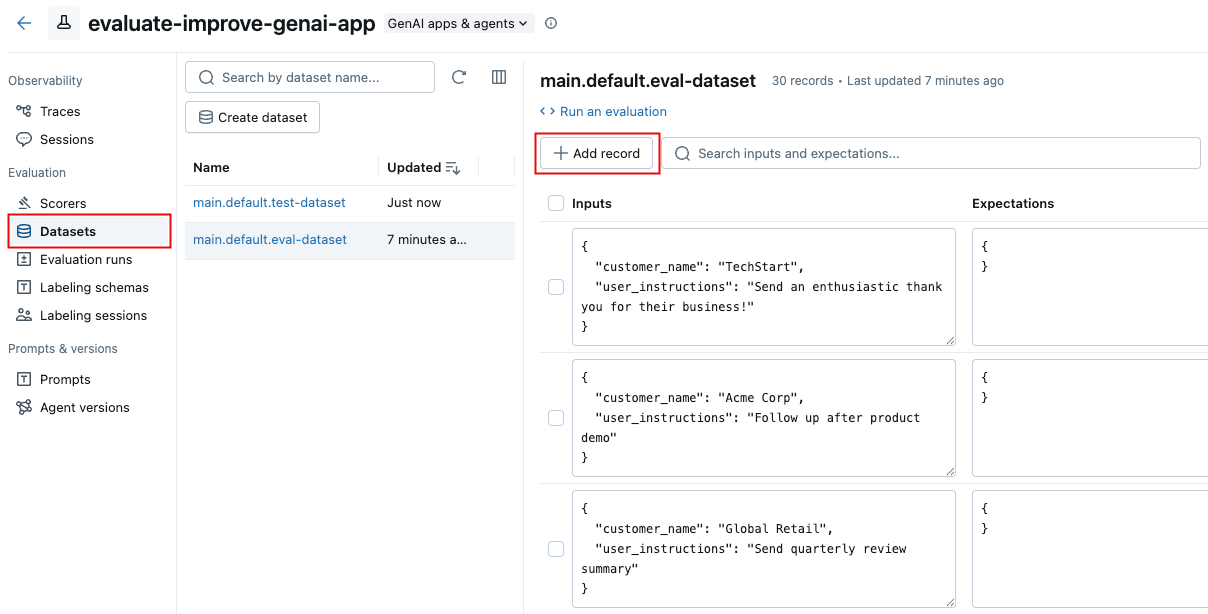
-
[レコードの追加] をクリックします。一般的なコンテンツを含む新しい行が表示されます。
-
新しい行を直接編集して、新しいレコードの入力内容と期待値を入力します。必要に応じて、新しいレコードのタグを設定します。
-
[変更を保存] をクリックします。
MLflow SDK を使用して既存の評価データセットを更新します。
import mlflow.genai.datasets
import pandas as pd
# Load existing dataset
dataset = mlflow.genai.datasets.get_dataset(name="catalog.schema.eval_dataset")
# Add new test cases
new_cases = [
{
"inputs": {"question": "What are MLflow models?"},
"expectations": {
"expected_facts": ["model packaging", "deployment", "registry"],
"min_response_length": 100
}
}
]
# Merge new cases
dataset = dataset.merge_records(new_cases)
制限事項
- 顧客管理キー (CMK) はサポートされていません。
- 評価データセットごとに最大 2000 行。
- データセット レコードあたりの期待値は最大 20 件です。
ユースケースに合わせてこれらの制限を緩和する必要がある場合は、Databricks の担当者にお問い合わせください。
次のステップ
- アプリの評価 - 新しく作成したデータセットを評価に使用します
- カスタムジャッジの作成- アプリケーションの出力を評価するカスタム LLM ジャッジを構築します
- ジャッジと専門家のフィードバックを一致させる- ジャッジと専門家のフィードバックを一致させることで、評価を継続的に改善します。
- SDK 経由のクエリ トレース- データセット選択のための高度なプログラムによるトレース分析