OTelトレースからのPIIのマスキングリファレンス
このページでは、Unity Catalogに保存されているOpenTelemetry(OTel)スパンからPIIを編集するためのリファレンスアーキテクチャについて説明します。2つの補完的なフローをカバーしています: サーバーサイドバッチ処理と、ビューベースの読み取り時編集。どちらのフローもAI FunctionsとSpark宣言型パイプラインを使用します。デプロイ手順とダウンロード可能なアセットについては、Unity CatalogでOpenTelemetryトレースからPIIを編集するを参照してください。
パラメーター
このソリューションのすべてのコンポーネントは、複数の環境で再利用できるようパラメーター化されています。
テーブルのパラメーター
パラメーター | 説明 | 例 |
|---|---|---|
| 生OTelテーブルを含むUnity Catalogのカタログ。 |
|
| 生のOTelテーブルを含むUnity Catalogスキーマ。 |
|
| OTELトレース保存を設定する際に使用されるプレフィックス。 |
|
| 編集された出力テーブルのUnity Catalog カタログ。 |
|
| Unity Catalog 編集済み出力テーブルのスキーマ |
|
| 未編集データのTTL(GDPR への準拠)。自動削除を無効にするには、 |
|
派生ソーステーブル名称:
{source_catalog}.{source_schema}.{table_prefix}_otel_spans{source_catalog}.{source_schema}.{table_prefix}_otel_logs{source_catalog}.{source_schema}.{table_prefix}_otel_annotations
PIIのマスキングルール
パラメーター | 説明 | 例 |
|---|---|---|
| マスキング対象のPIIタイプの一覧。 |
|
| PIIをマスクする方法: |
|
| マスキングに使用される文字。 |
|
| 秘匿化を適用するOTelフィールド |
|
| 編集対象外とする属性キー(例: |
|
| ドメイン固有の個人識別情報に対する正規表現パターン |
|
フロー 1: サーバーサイド バッチ処理 (推奨)
このフローは、Spark宣言型パイプライン を使用して、生OTelテーブルから編集済みテーブルを実体化します。
なぜ宣言型パイプラインを使用するのか
考慮事項 | Lakeflow Pipelines(ストリーミングテーブル) | ノートブックとスケジュールされたジョブ |
|---|---|---|
インクリメンタル処理 | 組み込み — ストリーミングテーブルは新しい行のみを処理します。 | 構造化ストリーミングによる手動チェックポイント管理。 |
AI関数のサポート | SQLに組み込まれています。 | SQLに組み込まれています。 |
モニタリングとアラート | 組み込みパイプライン UI およびイベントログ。 | 個別に設定する必要があります。 |
再試行と障害処理 | 自動。 | 手動。 |
依存関係 | Unity Catalog の自動リネージ追跡 | 手動。 |
サーバーレスコンピュート | はい。 | はい (サーバレス ジョブに対応しています)。 |
運用オーバーヘッド | 低・フルマネージド型 | Medium ― 状態、スケジュール、およびアラートの管理 |
ストリーミングテーブルを使用するLakeFlow Pipelinesが最適です。OTel スパンは追記専用であるため、増分ストリーミングテーブルの取り込みに最適です。ai_mask などの AI 関数は SQL に組み込みであるため、SQL パイプラインが最もシンプルな実装です。
アーキテクチャ
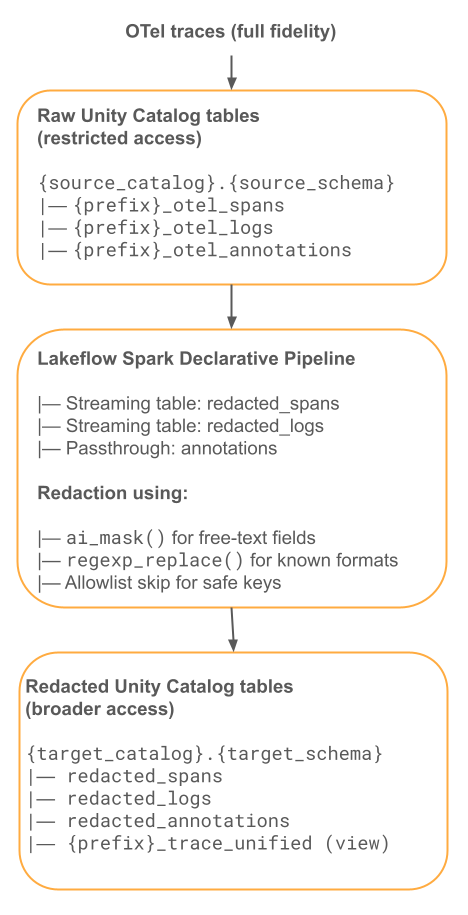
実装
ステップ1: 生テーブルをロックダウンする
生テーブルへのアクセスは、パイプラインサービスプリンシパルと管理者ユーザーにのみ付与します。
-- Restrict raw table access
GRANT USE CATALOG ON CATALOG ${source_catalog} TO `pii_pipeline_sp`;
GRANT USE SCHEMA ON SCHEMA ${source_catalog}.${source_schema} TO `pii_pipeline_sp`;
GRANT SELECT ON TABLE ${source_catalog}.${source_schema}.${table_prefix}_otel_spans TO `pii_pipeline_sp`;
GRANT SELECT ON TABLE ${source_catalog}.${source_schema}.${table_prefix}_otel_logs TO `pii_pipeline_sp`;
-- Revoke broader access
REVOKE SELECT ON TABLE ${source_catalog}.${source_schema}.${table_prefix}_otel_spans FROM `data_team`;
ステップ 2: SQLパイプラインを作成する
pii_redaction_pipeline.sql で伏字化されたストリーミングテーブルを定義します。
-- =============================================================
-- Streaming Table: Redacted Spans
-- =============================================================
CREATE OR REFRESH STREAMING TABLE redacted_spans
COMMENT 'PII-redacted OTel spans'
TBLPROPERTIES (
'quality' = 'gold',
'pipelines.autoOptimize.zOrderCols' = 'trace_id,date'
)
AS
SELECT
trace_id,
span_id,
parent_span_id,
name,
kind,
start_time,
end_time,
status,
date,
record_id,
service_name,
time,
instrumentation_scope,
-- Redact span attributes (VARIANT field)
-- ai_mask replaces PII with masked values in free-text content
CASE
WHEN attributes IS NOT NULL THEN
ai_mask(
CAST(attributes AS STRING),
array(${pii_categories}) -- e.g. array('email','phone','ssn','name','address')
)
ELSE attributes
END AS attributes,
-- Redact resource attributes
CASE
WHEN resource:attributes IS NOT NULL THEN
named_struct(
'attributes',
ai_mask(
CAST(resource:attributes AS STRING),
array(${pii_categories})
),
'dropped_attributes_count',
resource:dropped_attributes_count
)
ELSE resource
END AS resource,
-- Redact events (may contain exception messages with PII)
CASE
WHEN events IS NOT NULL THEN
ai_mask(
CAST(events AS STRING),
array(${pii_categories})
)
ELSE events
END AS events,
-- Pass through links unchanged (typically just trace/span IDs)
links
FROM STREAM(${source_catalog}.${source_schema}.${table_prefix}_otel_spans);
-- =============================================================
-- Streaming Table: Redacted Logs
-- =============================================================
CREATE OR REFRESH STREAMING TABLE redacted_logs
COMMENT 'PII-redacted OTel logs'
AS
SELECT
trace_id,
span_id,
severity_number,
severity_text,
date,
record_id,
service_name,
time,
instrumentation_scope,
-- Redact log body
CASE
WHEN body IS NOT NULL THEN
ai_mask(
CAST(body AS STRING),
array(${pii_categories})
)
ELSE body
END AS body,
-- Redact log attributes
CASE
WHEN attributes IS NOT NULL THEN
ai_mask(
CAST(attributes AS STRING),
array(${pii_categories})
)
ELSE attributes
END AS attributes,
-- Redact resource attributes
CASE
WHEN resource:attributes IS NOT NULL THEN
named_struct(
'attributes',
ai_mask(
CAST(resource:attributes AS STRING),
array(${pii_categories})
),
'dropped_attributes_count',
resource:dropped_attributes_count
)
ELSE resource
END AS resource
FROM STREAM(${source_catalog}.${source_schema}.${table_prefix}_otel_logs);
-- =============================================================
-- Streaming Table: Annotations (passthrough — no PII expected)
-- =============================================================
CREATE OR REFRESH STREAMING TABLE redacted_annotations
COMMENT 'OTel annotations (passthrough, no PII redaction applied)'
AS
SELECT *
FROM STREAM(${source_catalog}.${source_schema}.${table_prefix}_otel_annotations);
ステップ 3: パイプラインリソースを作成する
以下の構成をテンプレートとして使用します。
{
"name": "otel-pii-redaction",
"catalog": "${target_catalog}",
"schema": "${target_schema}",
"serverless": true,
"continuous": false,
"channel": "CURRENT",
"configuration": {
"source_catalog": "<value>",
"source_schema": "<value>",
"table_prefix": "<value>",
"pii_categories": "'email','phone','ssn','credit_card','name','address'"
},
"libraries": [{ "file": { "path": "/Workspace/path/to/pii_redaction_pipeline.sql" } }]
}
レイテンシ要件に応じて、パイプラインをトリガーモードで実行します(例えば、15分ごと、または1時間ごと)。連続モードも利用可能ですが、コストが増大します。
ステップ4:編集済みテーブル上に統合ビューを作成する
-- Recreate the trace_unified view pointing at redacted tables
CREATE OR REPLACE VIEW ${target_catalog}.${target_schema}.${table_prefix}_trace_unified AS
SELECT
s.trace_id,
s.date,
min(s.start_time) AS request_time,
max(s.end_time) - min(s.start_time) AS execution_duration,
collect_list(
named_struct(
'span_id', s.span_id,
'parent_span_id', s.parent_span_id,
'name', s.name,
'kind', s.kind,
'start_time', s.start_time,
'end_time', s.end_time,
'status', s.status,
'attributes', s.attributes,
'events', s.events
)
) AS spans,
a.tags,
a.assessments
FROM ${target_catalog}.${target_schema}.redacted_spans s
LEFT JOIN ${target_catalog}.${target_schema}.redacted_annotations a
ON s.trace_id = a.target_id
GROUP BY s.trace_id, s.date, a.tags, a.assessments;
ステップ 5: 編集済みテーブルへの広範なアクセス権限を付与する
GRANT USE CATALOG ON CATALOG ${target_catalog} TO `data_team`;
GRANT USE SCHEMA ON SCHEMA ${target_catalog}.${target_schema} TO `data_team`;
GRANT SELECT ON SCHEMA ${target_catalog}.${target_schema} TO `data_team`;
ステップ6:未加工テーブルで保持を設定する(オプション、GDPRコンプライアンスのため)
retention_daysが設定されている場合(0より大きい場合)、自動 TTLを使用して、期限切れの行を自動的に削除します。OTel トレーステーブルは、time TIMESTAMP 列を備えた Unity Catalog マネージド Delta テーブルであるため、auto-TTL がサポートされています。予測的最適化はワークスペース (またはテーブル) で有効にする必要があります。
ALTER TABLE ${source_catalog}.${source_schema}.${table_prefix}_otel_spans
DELETE ROWS ${retention_days} DAYS AFTER time;
ALTER TABLE ${source_catalog}.${source_schema}.${table_prefix}_otel_logs
DELETE ROWS ${retention_days} DAYS AFTER time;
Databricks は、DELETE、PURGE、および VACUUM の操作をバックグラウンドで自動的に実行します。スケジュールされたジョブは不要です。
削除のタイミングは厳密には保証されません。行の期限切れから完全削除までには最大 6 日間の猶予期間があり、これにデータ保持期間(デフォルト 7 日間)が加わります。コンプライアンス要件により厳格な削除期間が求められる場合は、手動のDELETEとVACUUMをフォールバックとして使用するスケジュールされたジョブを使用してください。ターゲットの有効期限の構成値の計算に関する詳細については、「自動有効期限」を参照してください。
フロー 2: ビューベースの秘匿化(データ重複なし)
このフローは Unity Catalog ビューで ai_mask を適用するため、読み取り時に編集が行われ、編集されたコピーは保存されません。
使用する場合
- ストレージ コストは主な懸念事項です。
- 編集済みデータはめったにクエリされません。
- クエリごとにコンピュートコストを支払っても問題ありません。
アーキテクチャ
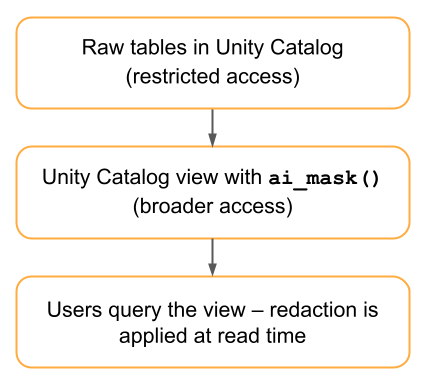
実装
CREATE OR REPLACE VIEW ${target_catalog}.${target_schema}.${table_prefix}_otel_spans_redacted
AS
SELECT
trace_id,
span_id,
parent_span_id,
name,
kind,
start_time,
end_time,
status,
date,
service_name,
time,
instrumentation_scope,
links,
ai_mask(
CAST(attributes AS STRING),
array(${pii_categories})
) AS attributes,
ai_mask(
CAST(events AS STRING),
array(${pii_categories})
) AS events,
named_struct(
'attributes',
ai_mask(CAST(resource:attributes AS STRING), array(${pii_categories})),
'dropped_attributes_count',
resource:dropped_attributes_count
) AS resource
FROM ${source_catalog}.${source_schema}.${table_prefix}_otel_spans;
トレードオフ
観点 | 利点 | デメリット |
|---|---|---|
ストレージ | 重複はありません。 | — |
コンピュート | — |
|
レイテンシー | すぐに新しいデータが反映されます。 | クエリー応答が遅くなります。 |
柔軟性 | 秘匿化ルールは即時に更新されます。 | — |
フローの比較
ディメンション | フロー 1: バッチパイプライン | フロー 2:ビューベース |
|---|---|---|
データ忠実性が保持されています | はい(未処理テーブル保持)。 | はい(未処理テーブル保持)。 |
ストレージコスト | 2倍(時間枠あり、または自動TTLが適用される場合は約1倍)。 | 1x。 |
コンピュートコスト | レコードごとに1回 | クエリごと。 |
クエリーのパフォーマンス | 迅速な(事前にマテリアライズされた)。 | 遅い(再計算)。 |
アベイラビリティまでのレイテンシー | 分(パイプライン間隔) | 即時。 |
規則変更の展開 | パイプラインの更新です。 | 即時。 |
GDPR コンプライアンス | 自動TTL または 未処理テーブルの定期的なクリーンアップ | 自動TTL または 未処理テーブルの定期的なクリーンアップ |
どのようなタスクにベストなのか | 主な本番運用用途。 | 低クエリー量の利用。 |
Databricks機能 | LakeFlow Pipelines. | Unity Catalog ビューと AI Functions |
推奨されるアプローチ
ほとんどのエンタープライズ展開において、**フロー1(バッチパイプライン)**を主要なソリューションとして使用してください。
- 認証されたデバッグのために、忠実性の高いデータを保持します。
- マテリアライズによって、クエリのパフォーマンスを最適化します。
- 生データにおける自動TTL保持により、GDPRコンプライアンスをサポートします。
- PIIのマスキングとトレースのフィルタリングの両方を1つのパイプラインで処理します。
- フルマネージドで、組み込みのモニタリングとアラートを備えています。
フロー 1 を設定するまでの間、クエリボリュームの少ないシナリオ向けに軽量なオプションとして、または迅速な暫定ソリューションとして、フロー 2(ビューベース)をご使用ください。
前提条件
- AI Functionsが有効 — AI Functionsへのアクセス権を持つSQLウェアハウスまたはサーバレスコンピュートが必要です。
- Unity Catalog — OTel トレースは、MLflow のトレース・ツー・Unity Catalog バインディングが構成された Unity Catalog テーブルに保存する必要があります。「Unity Catalog に OpenTelemetry トレースを保存する」をご覧ください。
- サービスプリンシパル — パイプライン実行用で、ソーステーブルに適切な権限を付与して使用します。
- 基盤モデルのエンドポイント :
ai_maskは基盤モデルを使用します。エンドポイントが利用可能であり、スループットに対応するサイズになっていることを確認してください。
実装チェックリスト
- OTel スパンのサンプルデータを使用して、VARIANT 型の列で
ai_maskの動作を検証します。 ai_maskスループットをベンチマークし、パイプラインのスケジュール間隔を決定します。- 匿名化の対象外とする許可された属性キーを定義します。
- アクセス制御グループを設定します(生データアクセス対編集済みアクセス)。
- 生テーブル保持の自動TTLを設定します(厳密な削除タイミングが必要な場合は、スケジュールされた
DELETEおよびVACUUMジョブを使用することもできます)。 - パイプラインの健全性と編集範囲のモニタリングダッシュボードを作成します。