MLflow の OpenTelemetry スパン属性を設定します
カスタムのOpenTelemetry計測(OTel)アプリケーションからDatabricks MLflowにトレースを送信する場合、MLflowのUIでトレースデータを正しく表示するために、特定のスパン属性を設定する必要があります。このページでは、設定すべきOpenTelemetry GenAIセマンティック規約属性について説明します。
Langfuseなどの既製の統合機能を使用する場合、その統合機能によってこれらの属性が自動的に設定されます。このページは、OTel社製のカスタム計測機器を使用するアプリケーション向けです。
Databricksが管理するMLflowの属性は、OSS(オープンソースソフトウェア)のMLflowとは異なります。OSS MLflowの属性マッピングについては、 MLflowのドキュメントを参照してください。
要件
始める前に、以下のものを用意してください。
- OTel トレース プレビューが有効になっているDatabricksワークスペース
- OTLPエクスポーターは、トレースをワークスペースに送信するように設定されています。Unity Catalogテーブルへのログトレースを参照してください。
- OpenTelemetry SDKで計測されたアプリケーション
スパンタイプを設定します
トレース内の各スパンにはタイプラベルが必要です。そうすることで、MLflowはそれがどのような種類の操作を表しているかを識別できます。span.set_attribute("gen_ai.operation.name", "<value>")を呼び出すことで、 gen_ai.operation.name次の表のいずれかの値に設定します。MLflowはこの属性を読み取り、対応するMLflowスパンタイプをトレースUIに表示します。
OTel | MLflow スパンタイプ |
|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
span.set_attribute("gen_ai.operation.name", "chat")
入力と出力を設定する
入力と出力を表示する各スパンにgen_ai.input.messagesとgen_ai.output.messagesを設定してください。これらを ルートスパン に設定すると、トレースレベルのリクエストとレスポンスのプレビューにも情報が表示されます。
OTel属性 | MLflow属性 |
|---|---|
|
|
|
|
値は、 プレーンな文字列 または JSONシリアル化された文字列 のいずれかです。roleとcontentフィールドを持つメッセージオブジェクトのJSON配列を使用すると、MLflow UIでよりリッチなレンダリングが可能になります(たとえば、「ユーザー」と「アシスタント」というラベルの付いた吹き出しなど)。
import json
# Plain string — displays as-is in the UI
span.set_attribute("gen_ai.input.messages", "What is the weather today?")
# JSON message array — renders with role labels in the UI
span.set_attribute("gen_ai.input.messages", json.dumps([
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "What is the weather today?"}
]))
span.set_attribute("gen_ai.output.messages", json.dumps([
{"role": "assistant", "content": "It is sunny and 72°F in San Francisco."}
]))
トークンの使用状況を設定する
UIトレースサマリーにトークン数を表示するには、ルートスパンでspan.set_attribute()を呼び出してgen_ai.usage.input_tokensとgen_ai.usage.output_tokensを設定します。MLflowは、トレースレベルでカウントを集計するため、これらの値をルートスパンから読み取ります。
OTel | MLflowフィールド |
|---|---|
| 入力トークン数 |
| 出力トークン数 |
(未設定 — 自動計算) | トークンの総数 |
root.set_attribute("gen_ai.usage.input_tokens", 150)
root.set_attribute("gen_ai.usage.output_tokens", 42)
セッションとユーザーを設定する
トレースを特定のセッションまたはユーザーに関連付けるには、 span.set_attribute()を呼び出して任意のスパンにsession.idとuser.idを設定します。MLflowはこれらの属性をルートスパンから読み取り、トレースレベルのメタデータとして表示します。設定session.idにより、MLflow UIのセッションタブが有効になります。
OTel属性 | MLflowメタデータフィールド |
|---|---|
| セッションまたは会話の識別子 |
| アプリケーションエンドユーザー識別子 |
span.set_attribute("session.id", "conversation-123")
span.set_attribute("user.id", "user-456")
完全な例:Pythonエージェントを計測する
次の例では、4つの属性カテゴリすべてを、LLM子スパンを持つシンプルなエージェントにまとめています。これは、OTLPエクスポーターが既にDatabricksにトレースを送信するように設定済みであることを前提としています。
import json
from opentelemetry import trace
tracer = trace.get_tracer("my-agent")
def run_agent(query: str) -> str:
with tracer.start_as_current_span("agent-run") as root:
# Child LLM span — set gen_ai attributes for this individual call
with tracer.start_as_current_span("chat") as llm:
llm.set_attribute("gen_ai.operation.name", "chat")
messages = [
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": query}
]
response = call_llm(messages)
llm.set_attribute("gen_ai.input.messages", json.dumps(messages))
llm.set_attribute("gen_ai.output.messages", json.dumps([
{"role": "assistant", "content": response}
]))
llm.set_attribute("gen_ai.usage.input_tokens", 150)
llm.set_attribute("gen_ai.usage.output_tokens", 42)
# Root span — MLflow reads inputs, outputs, token usage, and session ID
# from the root span to populate the trace summary in the UI.
root.set_attribute("gen_ai.operation.name", "chat")
root.set_attribute("session.id", "conversation-123")
root.set_attribute("user.id", "user-456")
root.set_attribute("gen_ai.input.messages", json.dumps([
{"role": "user", "content": query}
]))
root.set_attribute("gen_ai.output.messages", json.dumps([
{"role": "assistant", "content": response}
]))
root.set_attribute("gen_ai.usage.input_tokens", 150)
root.set_attribute("gen_ai.usage.output_tokens", 42)
return response
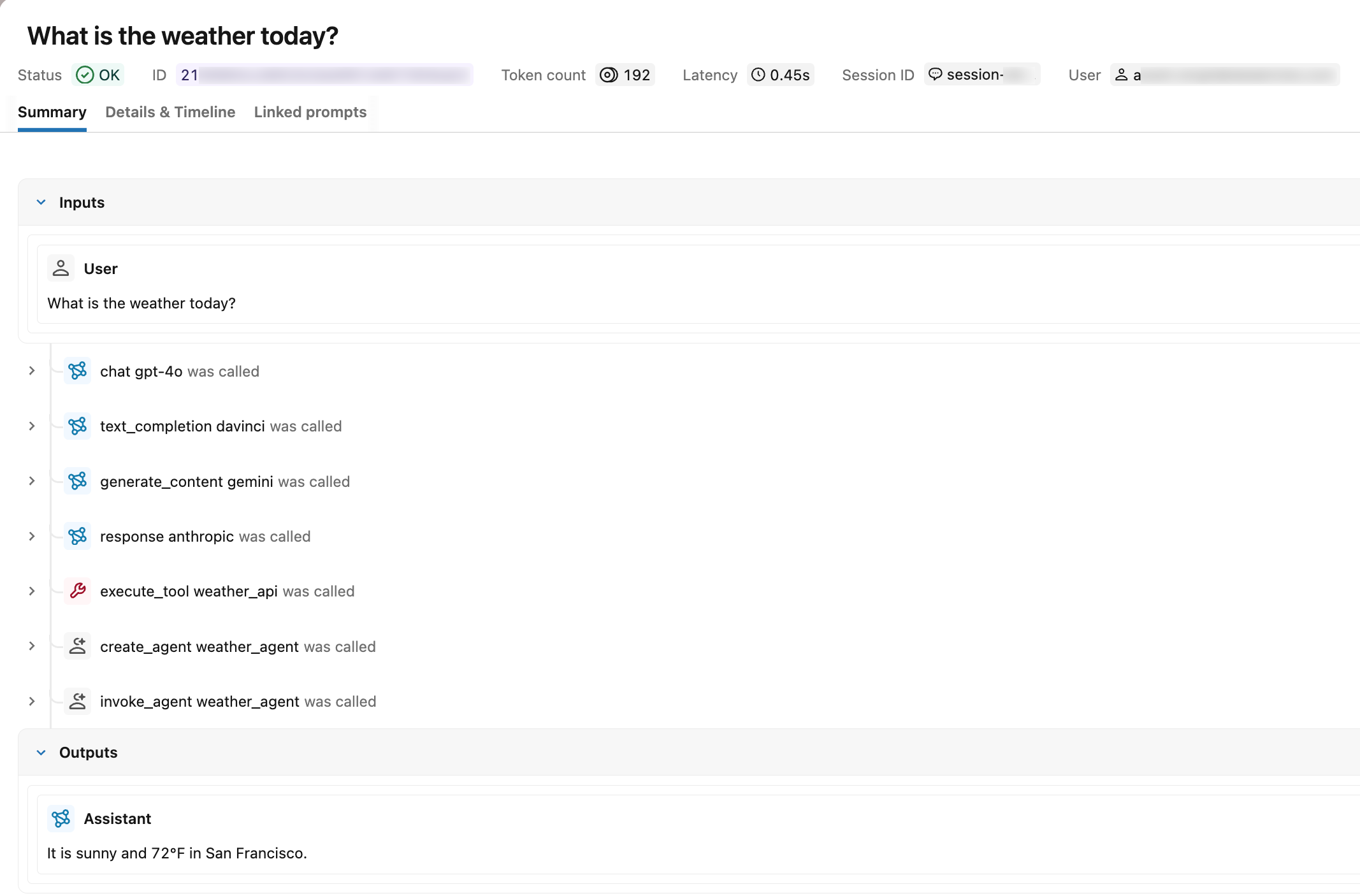
MLflow UIで確認する
run_agent()を呼び出した後、エクスペリメントでMLflow Traces] タブを開きます。 正しく計測されたトレースは次のことを示しています。
- スパンタイプ : 各スパンは、タイプラベル(例:
chat)の代わりに、UNKNOWN - リクエストとレスポンス :ルートスパンには入力メッセージと出力メッセージが表示されます。
- VPN の使用法 : トレースの概要には、入力、出力、および合計カウントが表示されます。
- セッションとユーザー :トレースは指定されたセッション識別子の下にあるセッションタブに表示され、ユーザーIDはトレースメタデータに表示されます。
OTelスパン属性によるトレースの検索
Unity CatalogにOTelトレースを取り込んだ後、 mlflow.search_traces()のspan.attributes.*プレフィックスを使用して、設定したOTel属性値でフィルタリングします。接頭辞の後の属性名は、 span.set_attribute()で設定した OTel 属性名と同じです。
import mlflow
# experiment_id is visible in the MLflow UI URL and experiment details panel
mlflow.set_experiment(experiment_id="<experiment-id>")
# Find traces from a specific session (set using session.id)
traces = mlflow.search_traces(
filter_string="span.attributes.session.id = 'conversation-123'"
)
# Find traces from a specific user (set using user.id)
traces = mlflow.search_traces(
filter_string="span.attributes.user.id = 'user-456'"
)
# Find traces from a specific model (set using gen_ai.request.model)
traces = mlflow.search_traces(
filter_string="span.attributes.gen_ai.request.model LIKE '%gpt%'"
)
# Find traces by operation type (set using gen_ai.operation.name)
traces = mlflow.search_traces(
filter_string="span.attributes.gen_ai.operation.name = 'chat'"
)
# Find high-token traces (set using gen_ai.usage.input_tokens)
traces = mlflow.search_traces(
filter_string="span.attributes.gen_ai.usage.input_tokens > 1000"
)
サポートされている演算子や比較演算子を含む完全なfilter_string構文については、 「プログラムによるトレースの検索」を参照してください。
制限事項
カスタムOTelスパン属性は、MLflowトレースタグとして表示されません。このページで認識されているOTel-to-MLflowマッピング以外でspan.set_attribute()を使用して設定した属性は、以下の場所には表示されません。
- MLflow UI の タグ 列または統合トレースビュー
_traces_unifiedUnity Catalogテーブルmlflow.search_traces()によって返されるtagsフィールド
これらの属性は、基となるスパンに保持されます。これらはMLflowトレースUIの 属性 タブに表示され、OTelスパンテーブルの<prefix>_otel_spans.attributesフィールドを介してクエリを実行できます。
統合トレース ビューに表示される検索可能なタグを添付するには、代わりにMLflowタグAPIs使用します。 カスタムタグとメタデータの添付を参照してください。
その他のリソース
- トレースをプログラムで検索 - MLflow SDKを使用して、トレースをプログラムで検索およびフィルタリングします。
- Unity Catalogに保存されているOpenTelemetryトレースをクエリ - Databricks SQLを使用して、大規模なトレースデータをクエリします。