ノートブック コンピュート リソース
Databricksノートブックは、汎用コンピュートリソース、サーバレスコンピュート、またはSQLコマンドの場合はSQLアナリティクスに最適化されたコンピュートタイプであるSQLウェアハウス上で実行できます。コンピューティングの種類に関する詳細については、 「コンピュート」を参照してください。
デフォルトコンピュート
Unity Catalogに対応したワークスペースで、新しいノートブックがサーバレス コンピュートになりました。 手動でコンピュート リソースを選択してセルを実行しない場合、ノートブックは自動的にサーバレス コンピュートに接続します。
自動アタッチコンピュート
開発者設定では、エディターと対話するときに自動的にコンピュート リソースにアタッチし、セッションを開始するようにノートブックを構成できます。
-
右上のユーザーアイコンをクリックしてください。
-
設定 をクリックします。
-
「開発者」 をクリックして開発者設定に移動します。
-
[エディター操作でセッションを自動的に作成] をオンに切り替えて、エディター操作でコンピュート セッションを自動的に開始します。 Databricks 、ユーザーの設定 (サーバーレスまたはSQLウェアハウス) と最後に使用されたコンピュート リソースに基づいてコンピュート リソースに移行します。
または
ノートブックが自動的にコンピュート リソースに接続して開始しないようにするには、この設定をオフにします。
オートコンプリート、コードの書式設定、デバッガーなどのコード支援機能を使用するには、ノートブックがアクティブなコンピュート セッションに接続されている必要があります。 ノートブックがコンピュート セッションを開始していない場合、コード支援機能は非アクティブになります。
ノートブック向けサーバレス コンピュート
サーバレス コンピュートを使用すると、ノートブックをオンデマンド コンピューティング リソースにすばやく接続できます。
サーバレス コンピュートに接続するには、ノートブックの [コンピュート] ドロップダウン メニューをクリックし、 [サーバレス] を選択します。
詳細については、 ノートブック向けサーバレス コンピュート を参照してください。
サーバレス ノートブックの自動セッション復元
サーバレス コンピュートがアイドル状態で終了すると、ノートブック内のPython変数値などの進行中の作業が失われる可能性があります。 これを回避するには、 サーバレス ノートブックの自動セッション復元を オンにします。
- ワークスペースの右上にあるユーザー名をクリックし、ドロップダウンリストから 「設定」 をクリックします。
- 設定 サイドバーで、 開発者 を選択します。
- [試験的な機能 ] で、[ サーバレス ノートブックの自動セッション復元 ] 設定をオンに切り替えます。
この設定を有効にすると、 Databricksアイドル終了前にサーバレス ノートブックのメモリ状態をスナップショットできるようになります。 アイドル状態で切断された後にノートブックに戻ると、ページの上部にバナーが表示されます。 「再接続」 をクリックして、作業状態を復元してください。
再接続すると、Databricks は次の作業環境全体を復元します。
- Python の変数、関数、クラス定義 : Python の状態は、pickle/cloudpickle を使用してプロセス内でシリアル化され、新しい REPL に復元されるため、再インポートや再宣言は不要です。
- Spark DataFrames 、キャッシュされたビュー、および一時ビュー :ロード、変換、またはキャッシュされたデータ(一時ビューを含む)は保持されるため、コストのかかる再ロードや再計算を回避できます。
- Sparkセッションの状態 :Sparkレベルの設定、一時ビュー、カタログの変更、およびユーザー定義関数(UDF)は、Spark Connectセッション移行によって復元されるため、リセットする必要はありません。
環境が変化し、例えば互換性のないPythonやパッケージのバージョンなどによって逆シリアル化が安全でなくなった場合、スナップショットは無効になり、ノートブックは新しいセッションにフォールバックします。
スナップショットデータストレージ
スナップショットデータは、ワークスペースのデフォルトストレージに保存されます。ノートブック自体は、ノートブック ID を持つポインター、タイムスタンプ、セッション情報などのメタデータのみを保存します。 データペイロードはノートブックには保存されません。Blob パスはノートブック属性に保存される前に暗号化され、スナップショットパスはノートブックのエクスポートおよびインポートから除外されるため、別のワークスペースに状態が復元されるのを防ぎます。
スナップショットはクラウドストレージのTTL(有効期限)のデフォルト設定(約1ヶ月)に従い、自動的に期限切れとなります。ノートブックを削除すると、そのノートブックに保存されているスナップショットも削除されます。クラウドアカウントでは、標準的なワークスペースストレージ使用量の一部としてストレージ料金が発生します。この機能は、コンテナレベルのチェックポイント処理ではなく、Pythonのプロセスシリアル化を利用することで、スナップショットのサイズを小さくし、作成速度を向上させています。
セキュリティとアクセス制御
スナップショットの復元は、ノートブックのアクセス許可を尊重します。状態を復元するには、ノートブックに対する実行権限が必要です。暗号化されたメタデータにより、ビューアがスナップショットのブロブを直接取得することはできず、復元時には権限チェックが強制されます。
制限事項
この機能には制限があり、以下の項目の復元はサポートしていません。
- 4日以上経過したSpark状態
- 50 MBを超えるSpark状態
- SQLスクリプトに関連するデータ
- ファイルハンドル
- ロックとその他の同時実行プリミティブ
- ネットワーク接続
ノートブックを汎用コンピュート リソースにアタッチする
ノートブックを汎用コンピュート リソースにアタッチするには、コンピュート リソースに対する Can Attach To 権限 が必要です。
ノートブックがコンピュート リソースにアタッチされている限り、ノートブックに対するCAN RUN アクセス許可を持つすべてのユーザーは、コンピュート リソースにアクセスするための暗黙的なアクセス許可を持っています。
ノートブックをコンピュート リソースに添付するには、ノートブック ツールバーのコンピュート セレクターをクリックし、ドロップダウン メニューからリソースを選択します。
メニューには、最近使用した、または現在稼働している汎用コンピュートと SQLウェアハウスのセレクションが表示されます。
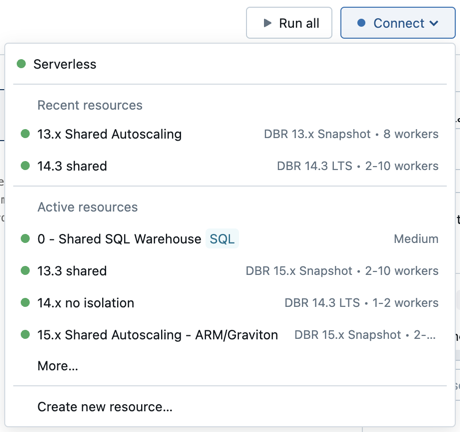
利用可能なすべてのコンピュートから選択するには、[ その他... ] をクリックします。 利用可能な一般的なコンピュートまたは SQLウェアハウスから選択します。
ドロップダウン メニューから[新しいリソースの作成] を選択して、 新しい汎用コンピュート リソースを作成する こともできます。
アタッチされたノートブックには、以下のApache Spark変数が定義されています。
クラス | 変数名 |
|---|---|
|
|
|
|
|
|
SparkSession 、 SparkContext 、またはSQLContextを作成しないでください。そうすると、一貫性のない行動につながる。
SQLウェアハウスでノートブックを使用する
ノートブックが SQLウェアハウスにアタッチされている場合、 SQL セルと Markdown セルを実行できます。 他の言語 (Python や R など) でセルを実行すると、エラーが発生します。SQLウェアハウスで実行されたセルSQL、SQLウェアハウスのクエリ履歴に表示されます。クエリを実行したユーザーは、出力の下部にある経過時間をクリックすることで、ノートブックから クエリ プロファイルを表示できます 。
SQLウェアハウスに接続されているノートブックはSQLウェアハウス セッションをサポートしており、変数を定義したり、一時ビューを作成したり、複数のクエリ実行にわたって状態を保持したりできます。 すべてのステートメントを一度に実行することなく、SQLロジックを反復的に構築できます。SQLウェアハウスセッションとは何か?を参照してください。
ノートブックを実行するには、Pro または サーバレス SQLウェアハウスが必要です。 ワークスペースと SQLウェアハウスにアクセスできる必要があります。
ノートブックを SQLウェアハウス にアタッチするには、次の手順を実行します。
-
ノートブック ツールバーのコンピュート セレクターをクリックします。 ドロップダウン メニューには、現在実行中または最近使用したコンピュート リソースが表示されます。 SQLウェアハウスには、
 。
。 -
メニューからSQLウェアハウスを選択します。
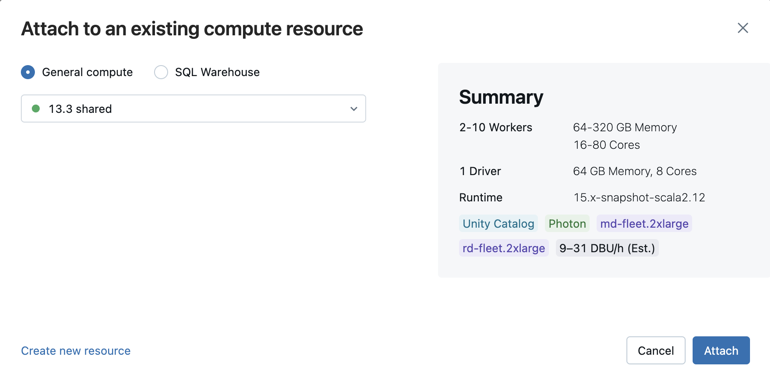
利用可能なすべてのSQLウェアハウスを表示するには、ドロップダウンメニューから 「詳細…」 を選択してください。ノートブックで使用できるコンピュート リソースを示すダイアログが表示されます。 SQLウェアハウス] を選択し、使用するウェアハウスを選択して、 [添付] をクリックします。
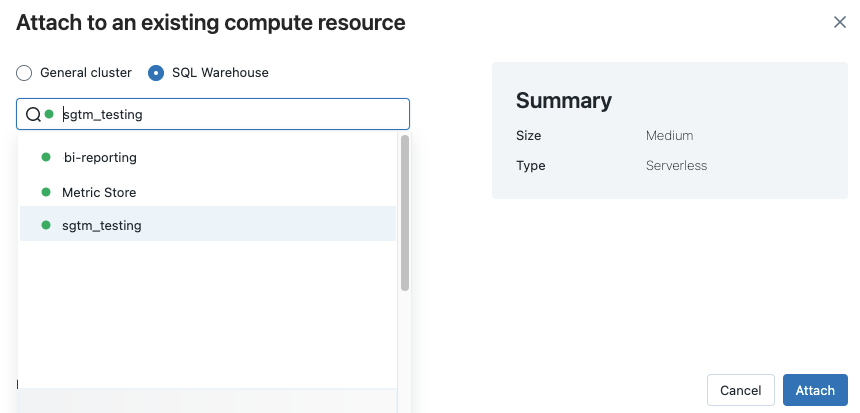
また、ワークフローまたはスケジュールされたジョブを作成するときに、SQL ノートブックのコンピュート リソースとして SQLウェアハウスを選択することもできます。
SQLウェアハウスの制限
詳細については、 Databricksノートブックの既知の制限」を参照してください。