LakebasePostgres
Lakebaseは、Databricksプラットフォームに統合された、フルマネージド型のPostgresデータベースです。自動スケーリング、即時分岐、ネイティブのUnity Catalog統合を使用して、レイクハウス データと一緒にトランザクション アプリケーションを構築します。
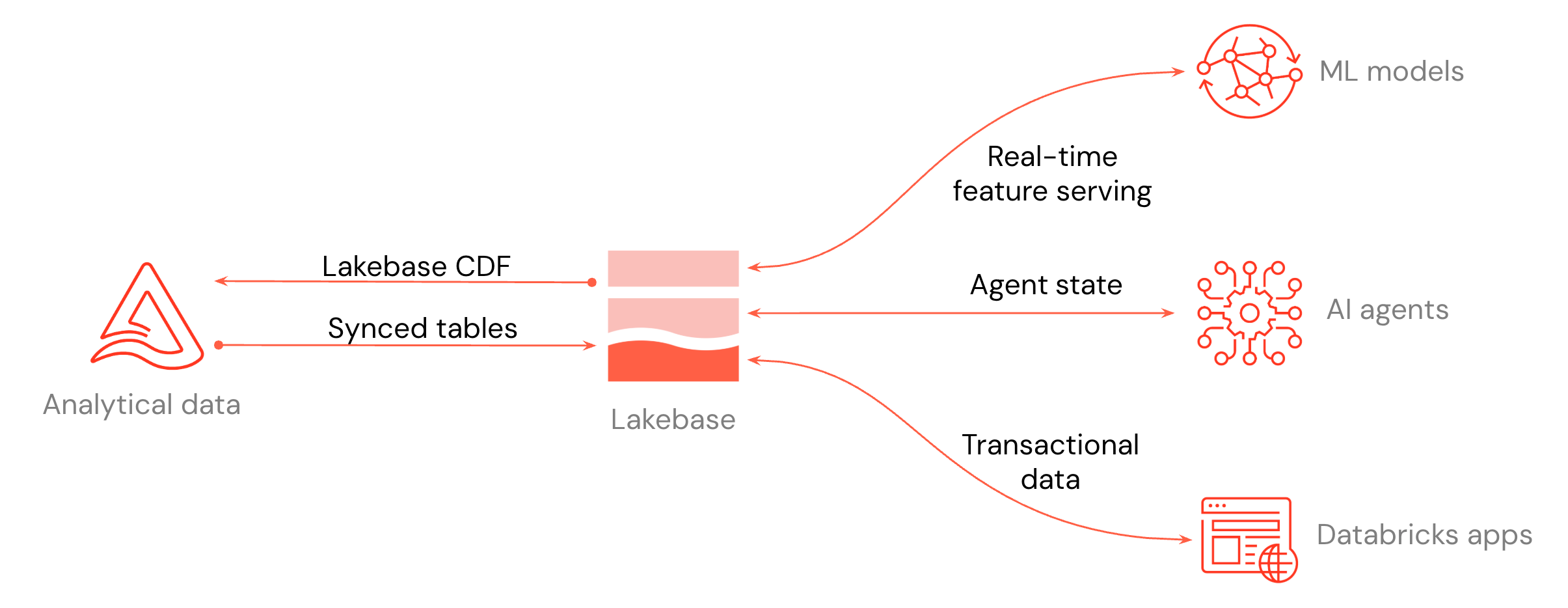
- 低遅延アプリケーションの構築: Databricks Appsまたは任意のアプリケーションをLakebaseに接続して、トランザクションワークロードを実行します。
- レイクハウス データの提供: Unity CatalogテーブルをLakebaseに同期して、アプリケーションが低レイテンシーでテーブルをクエリできるようにします。
- Postgres の変更を保存する: Postgres の変更を、ダウンストリームのパイプラインと監査のためにDeltaテーブルとして保存します。
- AIとML : Lakebase MLモデルのオンライン機能ストアとして、またはAIエージェントの状態ストアとして使用します。
注記
このドキュメントではLakebaseオートスケールについて説明します。 Lakebaseプロビジョニングを使用する場合は、 Lakebaseプロビジョニング」を参照してください。
さあ始めましょう
-
- Postgresデータベースを取得する
- プロジェクト、ブランチ、データベースを作成します。
psqlまたは任意のPostgresドライバを使用して接続します。
-
- レイクハウスデータの提供
- Unity CatalogテーブルをPostgresに同期することで、アプリの読み取り遅延を低減します。
-
- Postgres の変更をレイクハウスに保存する
- (パブリックプレビュー)Postgresの変更を、完全な変更履歴とともにDeltaとして保存します。
-
- アプリケーションを構築する
- Databricks Apps、外部連携、またはデータAPIを使用して、Lakebaseを基盤としたアプリケーションを構築します。
主な特徴
パフォーマンスを最適化し、コストを削減し、柔軟な開発ワークフローを可能にする機能をご確認ください。
接続してクエリ
さまざまなツールとインターフェースを使用して、データベースに接続し、クエリを実行します。
-
- データベースに接続する
- Lakebase データベースに接続するさまざまな方法を学習します。
-
- SQLエディタでクエリを実行する
- 組み込みの SQL エディターを使用して、データベースをクエリおよび管理します。
-
- テーブルエディター
- ビジュアル インターフェースを使用して、データとスキーマを表示、編集、管理します。
-
- Postgresクライアント
- 標準の Postgres クライアントとツールを使用して接続します。
-
- ある時点でのデータのクエリ
- ポイントインタイムブランチを使用してデータをクエリします。