オートスケール
オートスケールは、現在のワークロードの需要に応じて、Lakebase コンピュートに割り当てられるコンピュート リソースの量を動的に調整します。 アプリケーションでは 1 日を通してさまざまなレベルのアクティビティが発生するため、オートスケールは使用量のピーク時には自動的にコンピュート容量を増やし、静かな時間帯にはコンピュート容量を減らすため、手動介入の必要がなくなります。
この視覚化は、オフピーク時にリソースを節約しながら、データベースに必要なリソースを確実に確保するために、需要に基づいてコンピュート リソースをスケールアップまたはスケールダウンすることで、オートスケールが通常の 1 日を通してどのように機能するかを示しています。
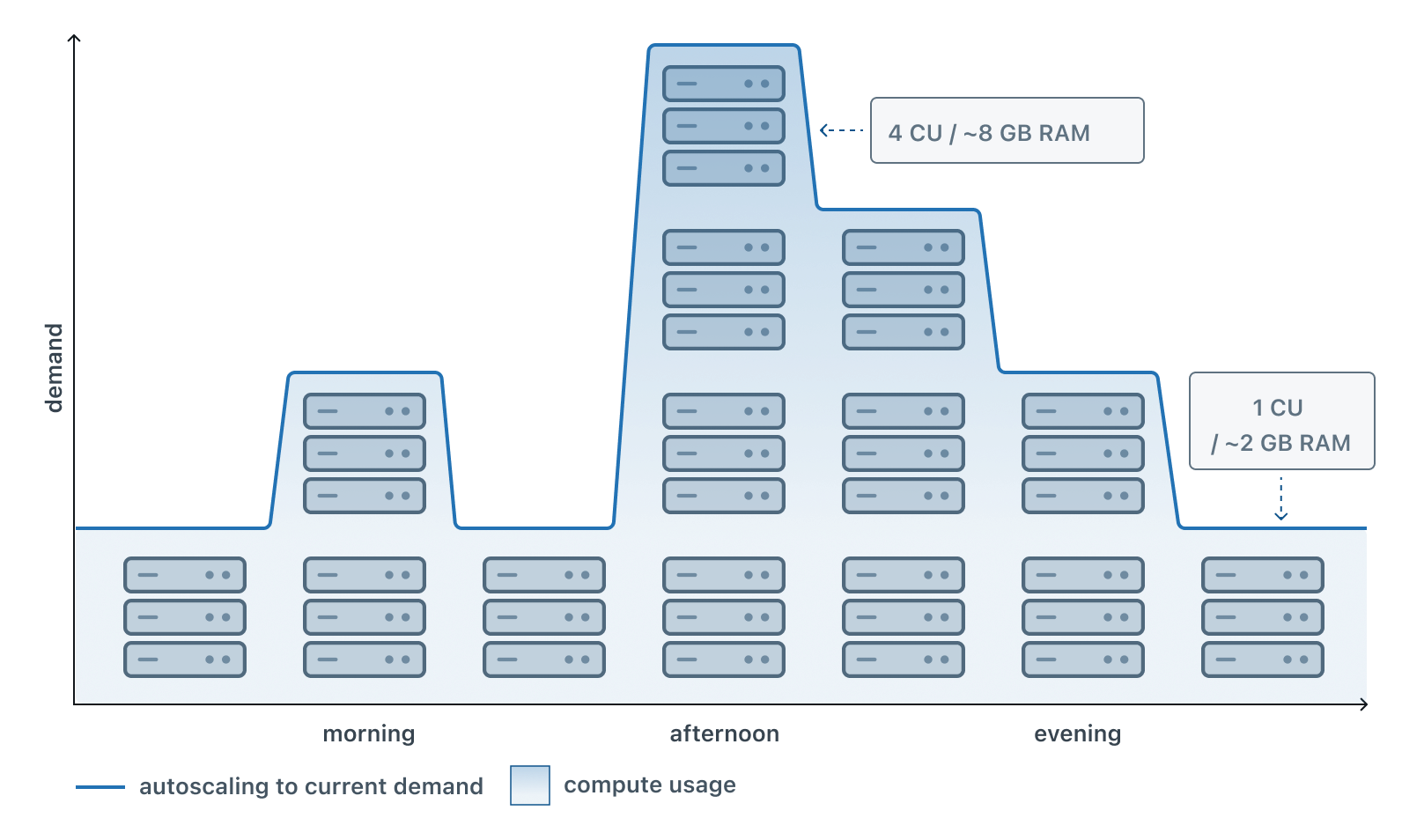
オートスケールは、ユーザー定義の範囲内で動作します。たとえば、コンピュートを2~8個のコンピュートユニット (CU) の間でスケーリングするように設定できます。各CUは2 GBのRAMを提供します。コンピュートは、ワークロードに基づいてこれらの制限内で自動的に調整され、需要に関係なく、最小値を下回ったり、最大値を超過したりすることはありません。オートスケールは、最大 64 CU(128 GB)のコンピュートで利用できます。
Lakebase Provisionedとオートスケール : Lakebase Provisionedでは、各コンピュート ユニットに約 16 GB の RAM が割り当てられました。 Lakebase Autoscalingでは、各 CU に 2 GB の RAM が割り当てられます。 この変更により、よりきめ細かいスケーリング オプションとコスト管理が可能になります。
オートスケールの仕組み
自動リソース調整
オートスケールを有効にしてコンピュートの最小サイズと最大サイズを設定すると、Lakebase はワークロードを継続的に監視し、リソースを自動的に調整します。 システムは、スケーリングの決定を行うために 3 つの主要なメトリクスを追跡します。
- CPU 負荷: プロセッサの使用率を監視して、データベースに十分な処理能力があることを確認します。
- メモリ使用量: メモリ制限を防ぐために RAM の消費量を追跡します。
- ワーキング セット サイズ: 頻繁にアクセスされるデータを推定し、キャッシュ パフォーマンスを最適化します。
これらのメトリクスに基づいて、Lakebase は、設定された範囲内に留まりながら、需要が増加するとコンピュートをスケールアップし、アクティビティが減少するとスケールダウンします。
境界を拡大する
コンピュートの最小サイズと最大サイズを設定することで、スケーリング範囲を定義します。 この範囲では以下が提供されます:
- パフォーマンス保証: 最低限のパフォーマンスにより、アクティビティが低いときでもベースライン パフォーマンスが保証されます。
- コスト管理: 最大値を設定することで、無制限のリソース消費とコストを防止します。
- 自動最適化: これらの境界内で、Lakebase がすべてのスケーリングの決定を処理します。
最大値と最小値の差は 16 CU (つまりmax - min ≤ 16 CU ) を超えることはできません。
ダウンタイムや手動介入なし
設定した範囲内でのオートスケール調整は、コンピュートの再起動や接続の中断を必要とせずに行われます。 ただし、最小または最大の CU 構成を変更すると、アクティブな接続が一時的に中断される可能性があります。一度構成すると、システムは自律的に動作し、インフラストラクチャの管理ではなくアプリケーションに集中できるようになります。
オートスケールのメリット
コスト効率: 実際に使用するコンピュート リソースに対してのみお支払いいただきます。 オフピーク時にはコンピュートがスケールダウンされ、コストが削減されます。 ピーク時には、パフォーマンスを維持するためにスケールアップします。
パフォーマンスの最適化: ワークロードが増加すると、データベースは自動的に追加のリソースを受け取り、トラフィックの急増や集中的な操作中のパフォーマンスの低下を防ぎます。
予測可能なコスト: コンピュートの最大サイズを設定することで、コンピュート コストの上限を制御し、リソースの暴走による予期せぬ出費を防ぎます。
簡素化された操作: オートスケールにより、ワークロード パターンを手動で監視してコンピュート サイズを調整する必要がなくなり、操作上のオーバーヘッドと人的エラーのリスクが軽減されます。
オートスケールの設定
オートスケールを設定するには、最小および最大コンピュートサイズを設定します。オートスケールは、最大 64 CU(128 GB)のコンピュートで利用できます。64 CU を超えるワークロードには、より大規模な固定サイズコンピュートが利用可能です。
オートスケールの有効化と構成の詳細な手順については、 「コンピュートの管理」を参照してください。
一般的なオートスケールのシナリオ
AIエージェントとアプリケーションのワークロード
Databricks 上に構築された AI エージェントとインタラクティブ アプリケーションでは、さまざまなリクエスト パターンが発生することがよくあります。オートスケールにより、アクティブなユーザー セッション中のトラフィックの急増にデータベースが確実に対処できるようになり、静かな期間のコストが削減されます。
LakebaseとDatabricks AIおよびアプリケーションサービスを接続する方法の詳細については、 Databricksの統合に関するドキュメントを参照してください。
開発およびテスト環境
スキーマ変更のテストまたはデータ パイプラインの検証のための開発ブランチでは、通常、断続的なアクティビティが発生します。 オートスケールは、アクティブな開発中に適切なパフォーマンスを確保しながら、アイドル期間中のリソースを最小限に抑えます。
顧客向けダッシュボードとアプリケーション
アナリティクスや運用に関する知識をエンド ユーザーに提供するアプリケーションには、多くの場合、時間帯に応じた使用パターンがあります。 オートスケールは、1 日を通してユーザーのアクティビティに合わせてリソースを自動的に調整します。
オートスケールしてゼロにスケールする
オートスケールは、 scale to zeroと組み合わせて機能します。 オートスケールはワークロードの需要に基づいてリソースを調整しますが、ゼロにスケールすると、一定期間非アクティブになった後にコンピュートが完全に一時停止され、アイドル期間中のコンピュートのコストがゼロに削減されます。
両方の機能を構成する場合:
- アクティブ期間: オートスケールは、定義された範囲内のワークロードに基づいてコンピュート サイズを調整します。
- 非アクティブ期間: ゼロへのスケール タイムアウトの後、コンピュートは完全に一時停止します。
- アクティビティの再開: 新しいクエリが到着すると、コンピュートは最小オートスケール サイズで再開します。
この組み合わせにより、特にアイドル期間が長くなる開発、テスト、ステージング環境においてコスト効率が最大化されます。
オートスケールと高可用性
オートスケールは高可用性エンドポイントでサポートされています。 CU サイズの調整は、高可用性構成のすべてのコンピュートに均一に適用されます。設定したオートスケール範囲は、プライマリとすべてのセカンダリに一緒に適用されます。
オートスケールと高可用性を組み合わせる場合、次の 2 つの制約が適用されます。
- セカンダリはプライマリの現在の CU サイズを下回る規模に拡張できません。 これにより、昇格後にパフォーマンスのギャップが生じることなく、セカンダリが常にプライマリの役割を引き継ぐ準備が整います。
- 高可用性構成では、ゼロへのスケールはコンピュートでは使用できません。 非アクティブ時のコストを削減するには、代わりに非 HA ブランチでスケール ゼロを使用することを検討してください。
その他のリソース
- コンピュートを管理して、オートスケールを有効にして構成する方法を学びます
- CPU、RAM、ワーキング セットのサイズを表示するメトリクス ダッシュボード メトリクス
- 非アクティブ時にコンピュートがどのように一時停止できるかを理解するには、ゼロにスケールします。
- 高可用性:高可用性構成でオートスケールがどのように機能するかを理解するための
- 分離されたデータベース環境の作成について学習するためのデータベースブランチ
- AIとML統合