Lakebase Databricks Appsで使用する
Databricks Apps使用すると、対話型アプリケーションをDatabricksワークスペースに直接構築してデプロイできます。 Lakebaseリソースとして追加すると、アプリにフルマネージド Postgres バックエンドが与えられます。 Databricksは、アプリ用のサービスプリンシパルを作成し、それに対応するPostgresロールを付与し、接続の詳細を環境変数として挿入します。アプリは、資格情報や接続文字列を管理せずに、フルマネージド Postgres データベースに接続します。
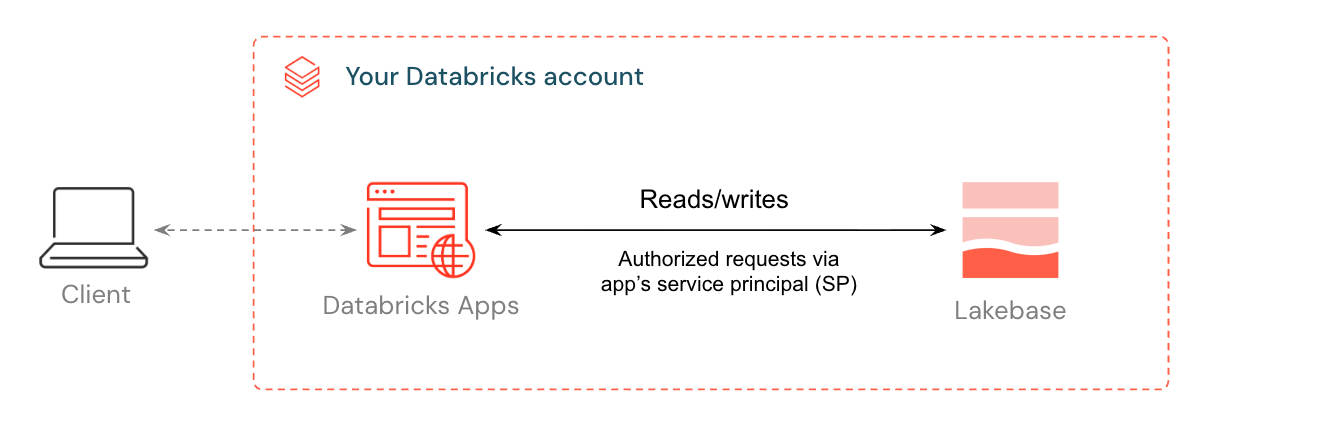
このチュートリアルでは、Lakebaseデータベースに接続されたテンプレートアプリをデプロイする手順を説明します。最終的には、 Lakebaseから直接検査およびクエリできるデータを含む実行中のアプリが完成し、オプションでレイクハウス データと一緒にUnity Catalogに登録することもできます。
前提条件
始める前に、以下のものを用意してください。
- Lakebaseとサーバレス コンピューティングが有効になっているDatabricksワークスペースへのアクセス。 必要に応じてワークスペース管理者に連絡してください。
- コンピュートリソースとアプリを作成する権限。
ステップ 1: Lakebase インスタンスのプロビジョニング
Lakebase プロジェクトは、アプリがリソースとして接続する管理された Postgres インスタンスです。プロジェクトはブランチに編成され、各ブランチは独立したデータベース環境を表します。
Lakebaseプロジェクトを作成するには、 「Postgresデータベースを取得する」を参照してください。Lakebaseは、 productionブランチとdatabricks_postgresデータベースを使用してプロジェクトを作成します。
ステップ 2: Databricksアプリを作成する
Databricks 、todos アプリを使用したLakebase統合を示す 3 つのオートスケール アプリ テンプレート (Dash、Flask、Streamlit) を提供します。 テンプレートからアプリを作成するには:
- Databricksワークスペースで、
 アプリスイッチャーで Databricks Apps を選択します。
アプリスイッチャーで Databricks Apps を選択します。 - 「+ アプリを作成」 をクリックします。
- データベース タブからお好みのテンプレートを選択してください。
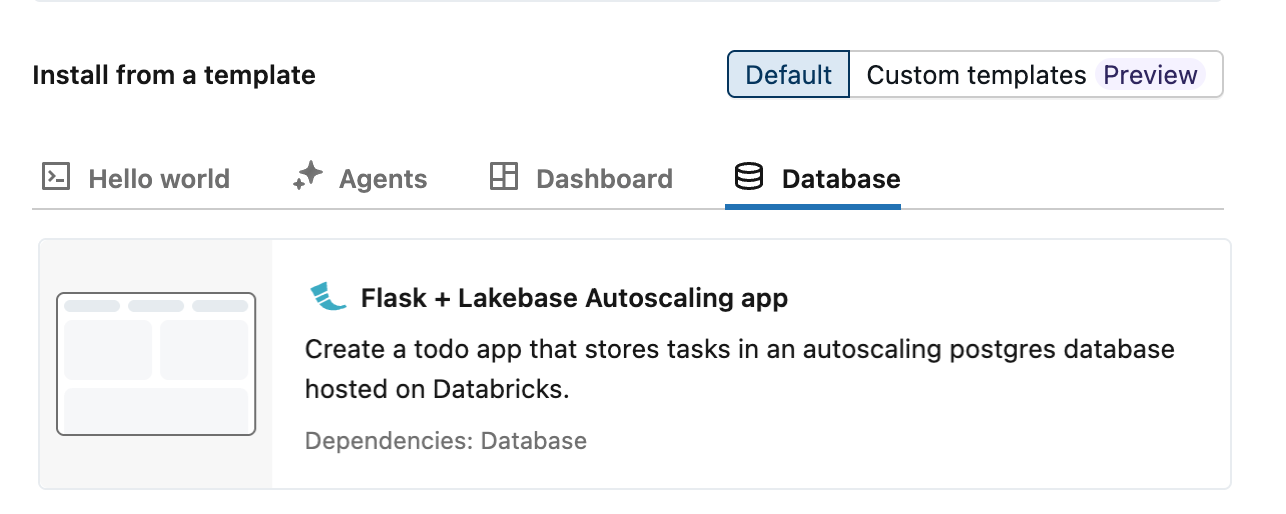
ステップ 3: データベース リソースを構成する
Lakebaseをリソースとして追加すると、適切なデータベース権限を持つサービスプリンシパルが作成され、接続情報が環境変数としてアプリに挿入されます。これにより、コード内に接続文字列を記述することなく、テンプレートが自動的にデータベースに接続できるようになります。
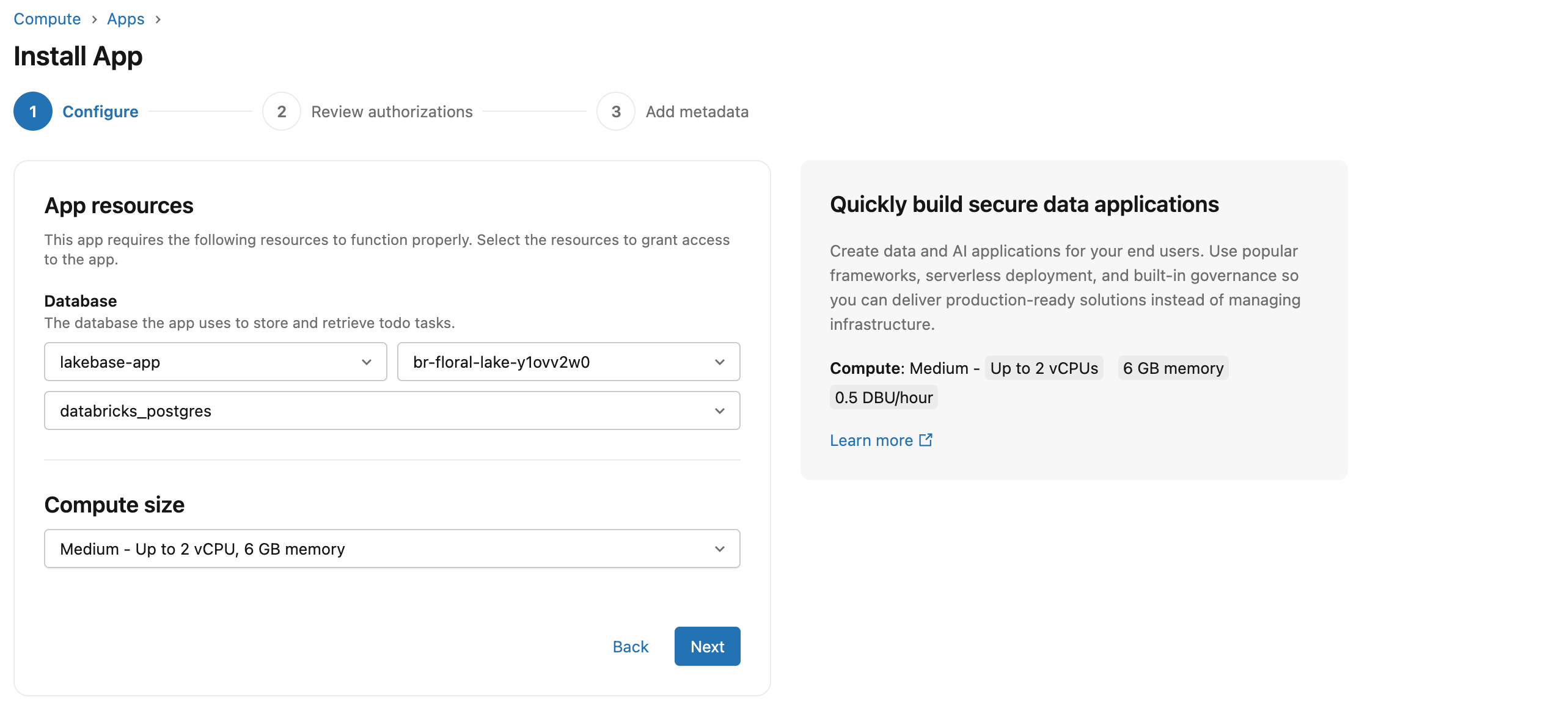
「設定」 ステップで、以下の設定を行います。
- アプリのリソース については、Lakebaseのプロジェクト、ブランチ、およびデータベースを選択してください。支店名はIDとして表示されます。IDと名前を照合するには、プロジェクトのブランチページを参照してください。
- コンピュート サイズ には、 「中」 を選択します。 これは、 Lakebaseデータベース コンピュートとは別個のアプリ サーバー コンピュートを制御し、独立してスケーリングします。
詳細については、 DatabricksアプリにLakebaseリソースを追加する」を参照してください。
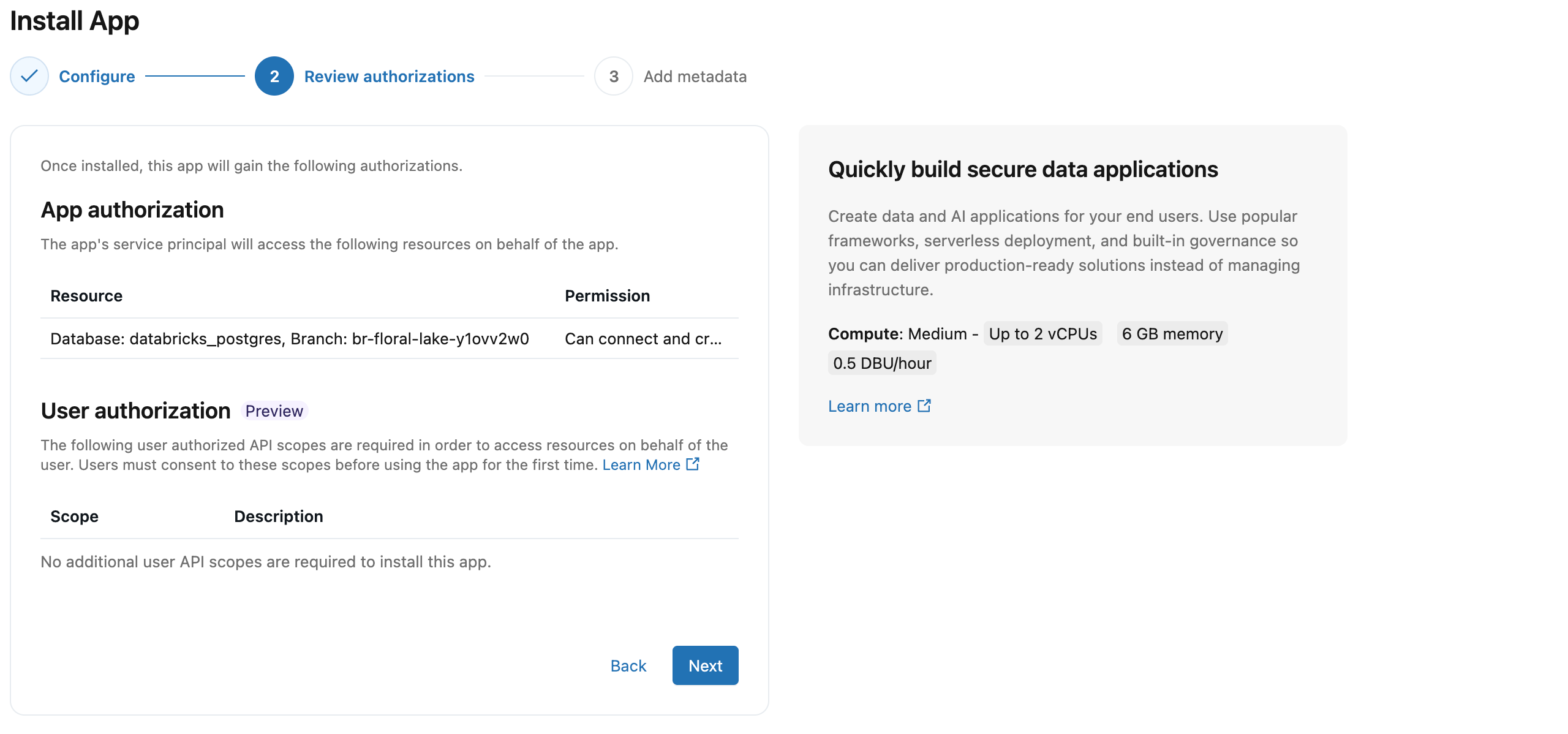
ステップ 4: 承認を確認する
Databricksの各アプリは、それぞれ独自のサービスプリンシパルとして実行されます。これは、個々のユーザーとは切り離された専用のIDです。Lakebaseをリソースとして接続すると、Databricksはそのサービスプリンシパルに対応するPostgresロールを作成し、データベースへの完全なアクセス権を付与します。手動での役割設定は不要です。
ステップ 5: アプリに名前を付けてインストールします
Lakebaseはアプリ名を使用して、 {app-name}_schema_{service-principal-id} (IDからハイフンを削除)の形式でスキーマ名を生成します。アプリ名は作成後に変更できませんが、スキーマ名は後から変更できます。テンプレートのデフォルト値はlakebase-autoscaling-appです。
アプリを作成するには、「アプリ を作成」 をクリックしてください。
ステップ 6: アプリをデプロイする
アプリを作成すると、コンピュートが自動的に開始され、それ以上何もしなくても約 2 ~ 3 分でアプリがデプロイされます。 アプリの状態が 「実行中」 と表示されたら、その横にあるURLをクリックしてアプリを開いてください。
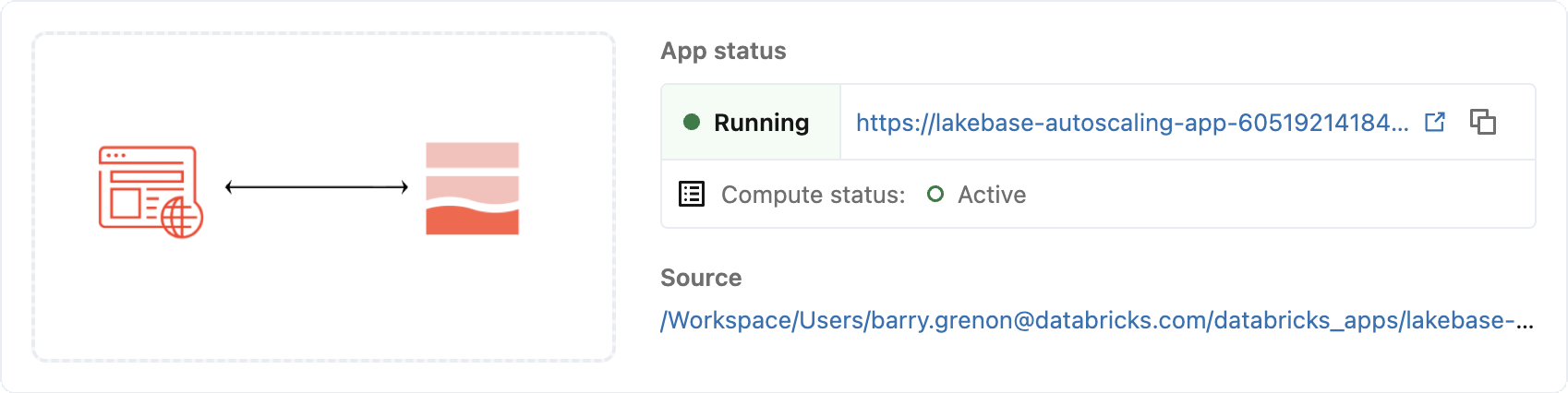
ステップ 7: 統合を確認する
アプリにToDoリストをいくつか追加してください。Lakebaseプロジェクトで、 「テーブル」 を開き、アプリのスキーマの下にある「todos」テーブルを選択します。アプリのサービスプリンシパルは、ステップ 3 で挿入された接続の詳細を使用してこれらの行を書き込みました。
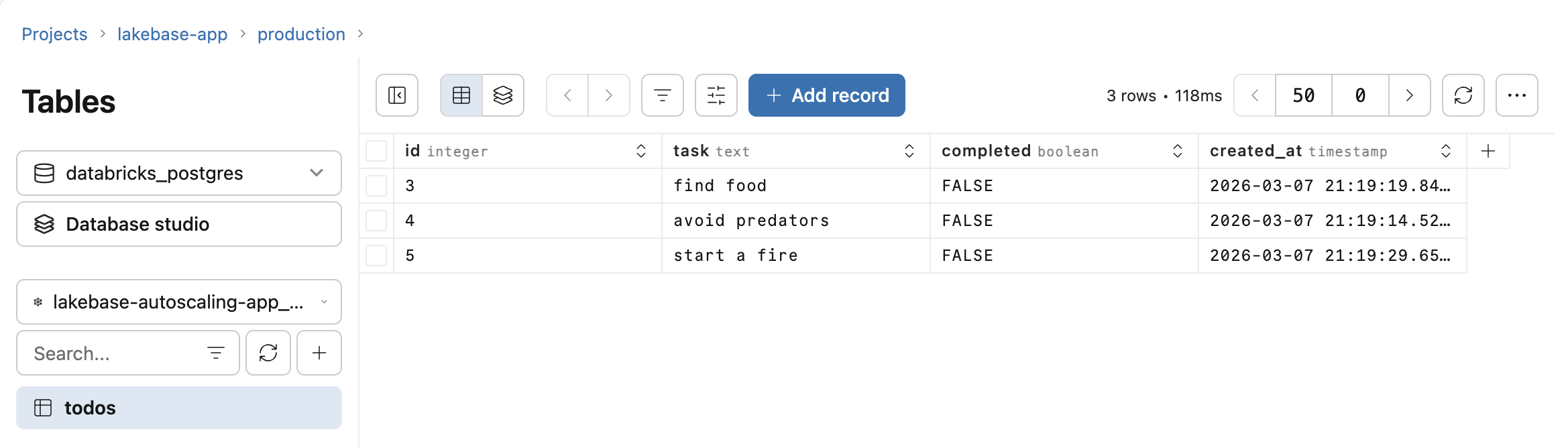
データを直接クエリするには、LakebaseプロジェクトのSQLエディタを使用してください。Lakebaseアイドル状態のときにスケールをゼロにするため、長時間停止した後の最初のクエリの応答には数秒かかる場合があります。 その他の接続オプションについては、 「データベースへの接続」を参照してください。
ステップ 8: Unity Catalogを介したクエリ (オプション)
デフォルトでは、アプリのLakebaseデータにはPostgres接続を介して直接アクセスできます。Unity Catalogに登録すると、標準のDatabricks SQLを使用してレイクハウス データと一緒にクエリできるようになります。 その後、同じクエリ内でアプリのトランザクションテーブルとDeltaテーブルを結合できます。
登録するには、Catalog Explorer を開いて、新しいカタログを作成します。カタログタイプとして Lakebase Postgres を選択し、 オートスケール を選択して、アプリと同じプロジェクトとブランチを選択してください。詳細については、Lakebase データベースを Unity Catalog に登録するを参照してください。
Unity Catalogのスキーマ名は、アプリ名に含まれるハイフンを保持することに注意してください。カタログ名とスキーマ名はどちらもバッククォートで囲む必要があります。
SELECT * FROM `your-catalog-name`.`lakebase-autoscaling-app_schema_aeb6ff9198ff4752af7dfc6d4cf570d0`.todos;