Postgresデータベースを取得する
このガイドを読み終える頃には、サンプルデータを含む稼働中のPostgresデータベースが完成し、アプリケーションに接続したり、 Databricksと統合したりする準備が整っているでしょう。
ステップ: ①プロジェクトを作成する→ ②接続する→ ③テーブルを作成する
ステップ 1: 最初のプロジェクトを作成する
アプリスイッチャーから Lakebase アプリを開きます。
オートスケール を選択して、Lakebase Autoscaling UI にアクセスします。
[新しいプロジェクト] をクリックします。プロジェクトに名前を付け、Postgres のバージョンを選択します。プロジェクトは、単一のproductionブランチ、デフォルトのdatabricks_postgresデータベース、およびブランチ用に構成されたコンピュート リソースを使用して作成されます。
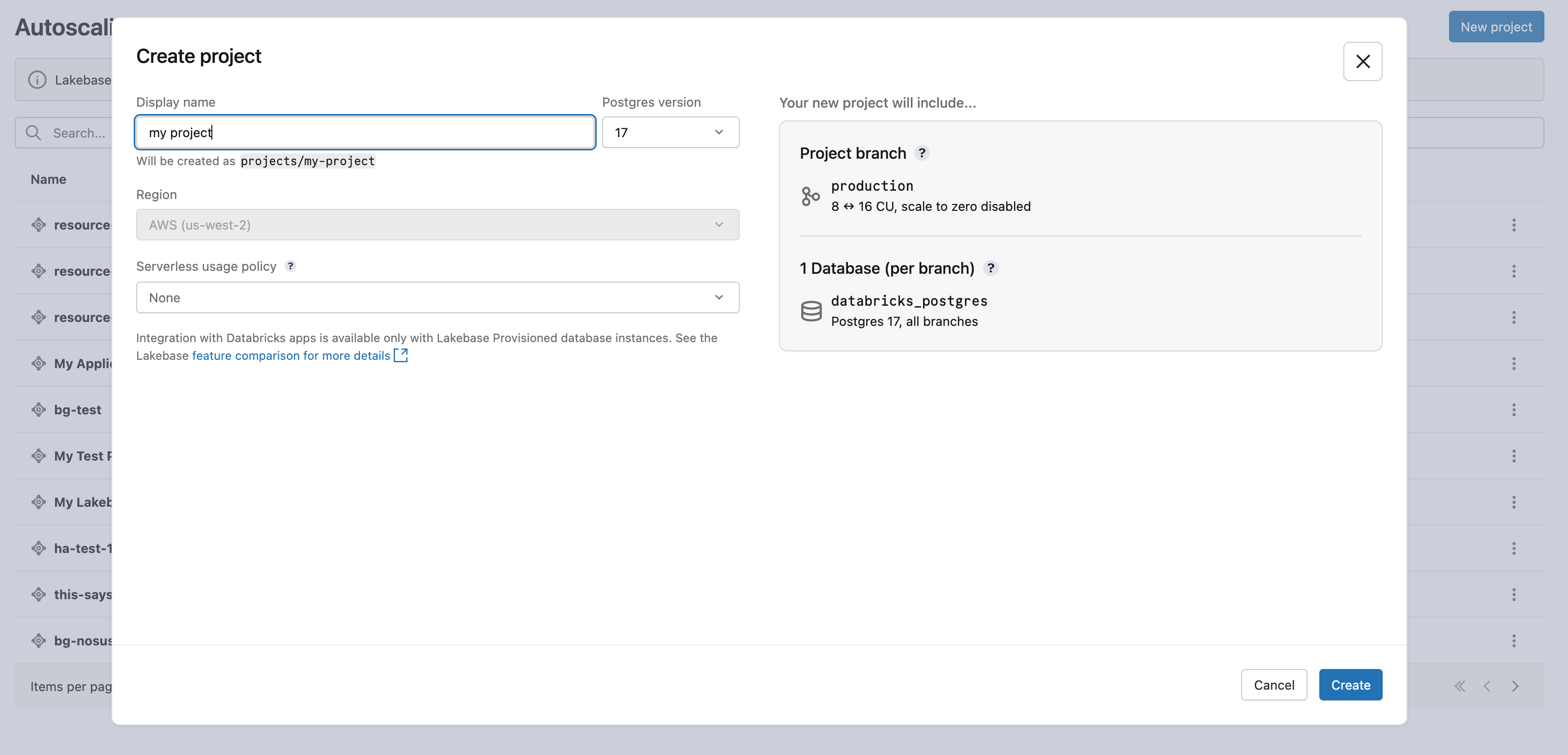
コンピュートがアクティブになるまでに少し時間がかかる場合があります。 productionブランチのコンピュートでは、24 時間の非アクティブ タイムアウトを使用してゼロへのスケールが有効になっていますが、必要に応じてこの設定を構成できます。
プロジェクトのリージョンは、ワークスペースのリージョンに自動的に設定されます。地域での提供状況をご覧ください。
詳細:プロジェクトの作成|オートスケール|ゼロにスケールする
ステップ 2: データベースに接続する
プロジェクトから 本番運用 ブランチを選択し、 「接続」 をクリックします。 接続文字列は、標準的なPostgresクライアント( psql 、pgAdmin、DBeaver、またはアプリケーションフレームワーク)であればどれでも機能します。
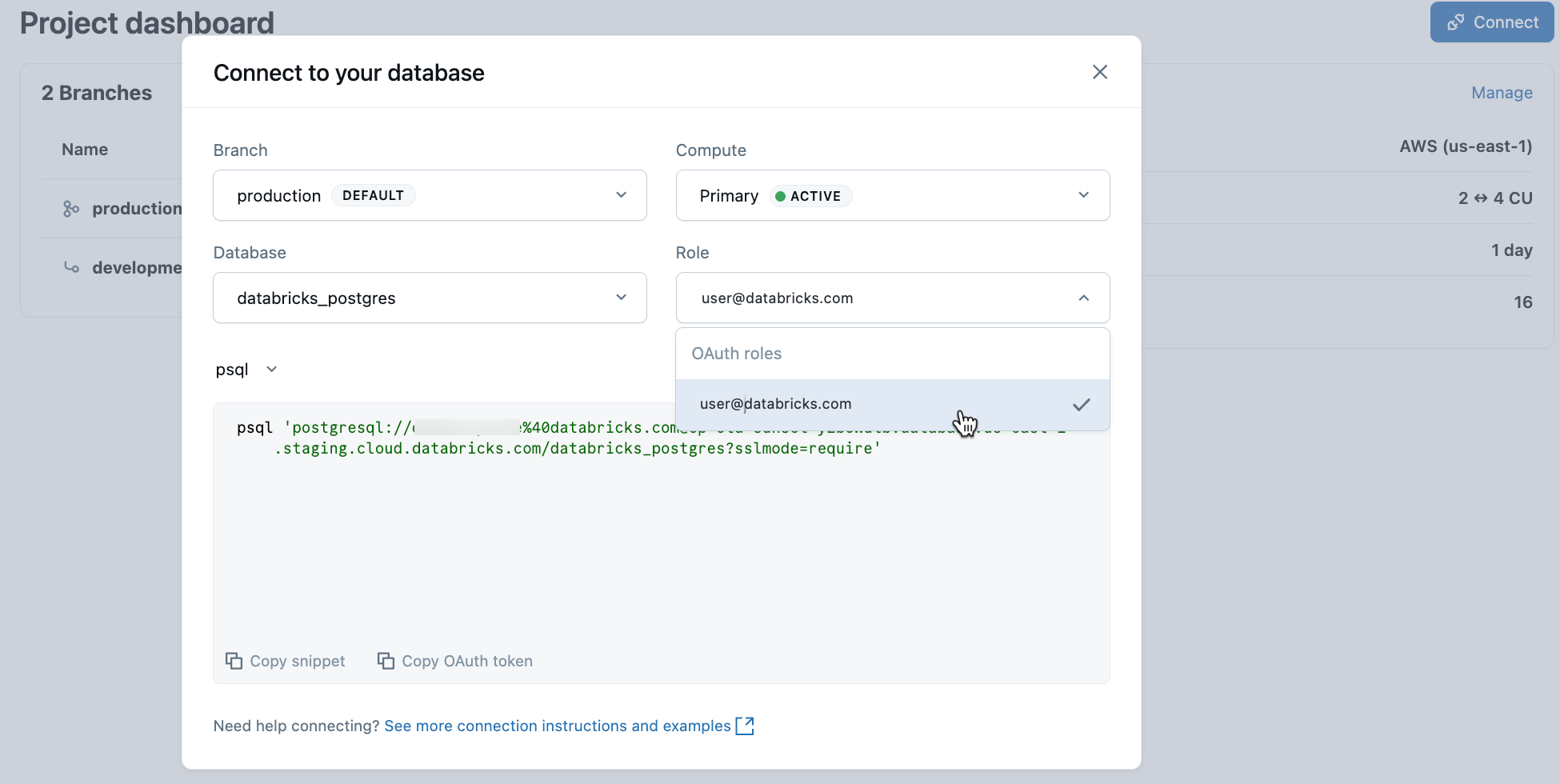
Databricks IDに接続するには、接続ダイアログからpsqlスニペットをコピーし、 OAuthを貼り付けてください。 プロンプトが表示されたら:
psql 'postgresql://your-email@databricks.com@ep-abc-123.databricks.com/databricks_postgres?sslmode=require'
詳細はこちら:接続クイックスタート| psql | pgAdmin | Postgresクライアント
ステップ 3: 最初のテーブルを作成する
Lakebase SQL Editorには、サンプルSQLがプリロードされています。プロジェクトから 本番運用 ブランチを選択し、 SQLエディターを開き、提供されたステートメントを実行してplaying_with_lakebaseテーブルを作成し、サンプル データを挿入します。
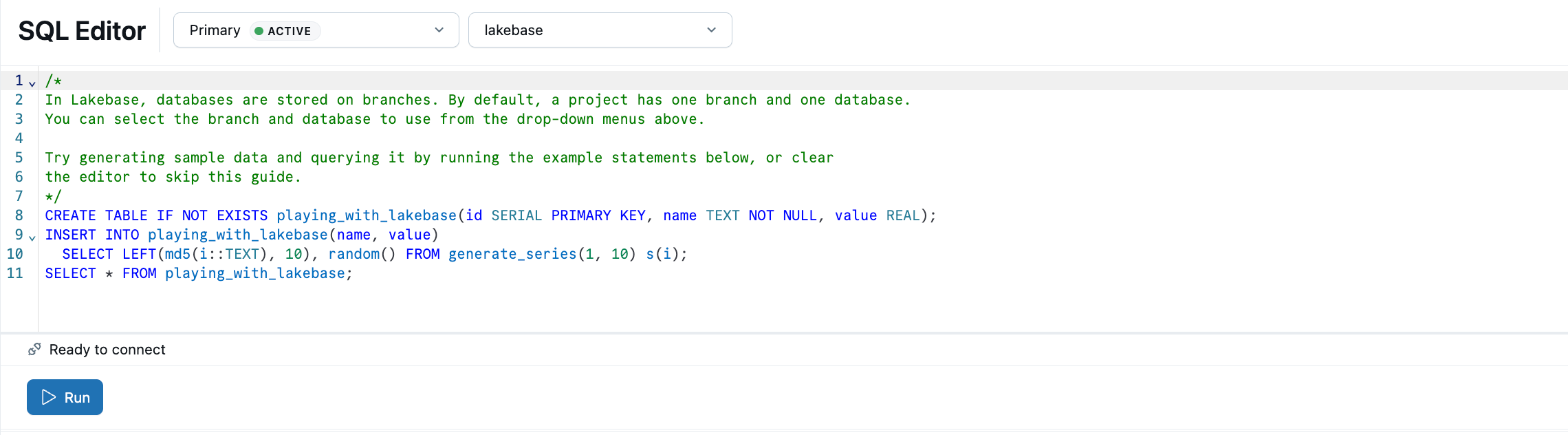
詳細はこちら: SQLエディタ|テーブルエディタ| Postgresクライアント
次のステップ
次のステップ | 説明 |
|---|---|
Unity CatalogテーブルをPostgresに同期することで、アプリの読み取り遅延を低減します。 | |
Lakebase CDFを使用して、Postgresの変更をDeltaとして保存します。 (一般公開プレビュー) |
もっと詳しく知る
-
- アプリを作成する
- Lakebaseへの自動接続機能を備えたDatabricksアプリをデプロイします。
-
- Unity Catalogに登録する
- 統合ガバナンス、リネージ、およびクロスソース クエリ。
-
- 中核概念
- オートスケール、ゼロへのスケール、分岐、およびそれらの仕組み。
-
- プロジェクト
- アーキテクチャ、分岐モデル、および製品概要。