高可用性
高可用性では、プライマリ読み取り/書き込みコンピュートと、可用性ゾーン全体に分散された 1 つ以上のセカンダリ コンピュート インスタンスがペアになります。 プライマリが使用できなくなると、セカンダリ コンピュート インスタンスが自動的に昇格され、アプリケーションは最後にコミットされたトランザクションから続行されます。 接続文字列は変更されません。
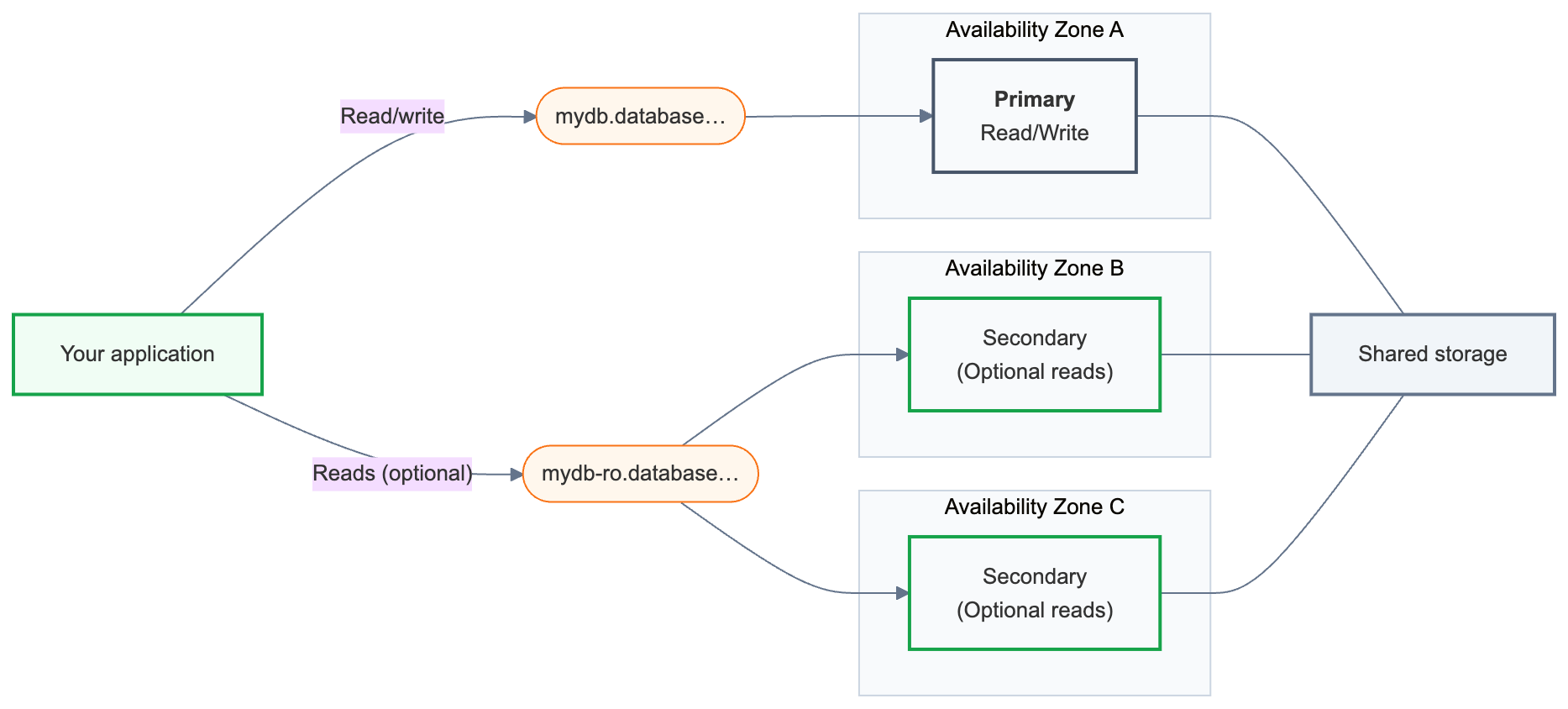
高可用性はコンピュートの冗長性のみを構成します。Lakebaseストレージは、HA設定に関わらず高い可用性を備えています。「ストレージアーキテクチャ」を参照してください。
高可用性の仕組み
Lakebaseエンドポイント とは、アプリケーションが接続するデータベースのアドレスのことです。高可用性エンドポイントは、2つの接続文字列を公開します。
- プライマリ (
{endpoint-id}.database.{region}.databricks.com) — メインの読み取り/書き込み接続。データベースに接続するすべてのアプリケーションでこれを使用します。フェイルオーバー後は、現在プライマリになっているコンピュートに自動的にルーティングされます。 - セカンダリ (
{endpoint-id}-ro.database.{region}.databricks.com) — [読み取り専用コンピュート インスタンスへのアクセスを許可する] が 有効な場合にのみ使用できます。 セカンダリ インスタンスは主にフェイルオーバー スタンバイとして存在します。読み取りアクセスを有効にすると、読み取りクエリをさらにルーティングできるようになります。
両方の接続文字列は、エンドポイントの [接続] ダイアログから利用できます。
これらの接続文字列の背後には、高可用性エンドポイントには常に 1 つの プライマリ コンピュート インスタンスと 1 ~ 3 つの セカンダリ コンピュート インスタンスがあります。 プライマリはすべての読み取り/書き込みトラフィックを処理します。セカンダリ コンピュート インスタンスは異なる可用性ゾーンで実行され、障害が発生した場合にはプライマリに昇格します。
各セカンダリ コンピュート インスタンスには、読み取りトラフィックも処理するかどうかを決定する アクセス 設定があります。
二次アクセス | 何をするのか |
|---|---|
読み取り専用 | セカンダリ コンピュート インスタンスは、 |
無効化済み | セカンダリ コンピュート インスタンスはアクティブでフェイルオーバーの準備ができていますが、読み取りトラフィックを処理しません |
これは、エンドポイントの [読み取り専用コンピュート インスタンスへのアクセスを許可する] 設定で制御できます。この設定には 、[編集コンピュート] ドロワーでアクセスできます。 有効にすると、すべてのセカンダリ コンピュート インスタンスが読み取りを処理します。無効にすると、フェイルオーバー専用にスタンバイになります。 どちらの場合も、コンピュート ハードウェアはすでに割り当てられ、実行されています。プロモーションには新しいプロビジョニングは必要ないため、可用性ゾーンの需要に関係なく、フェイルオーバー キャパシティが予約されます。
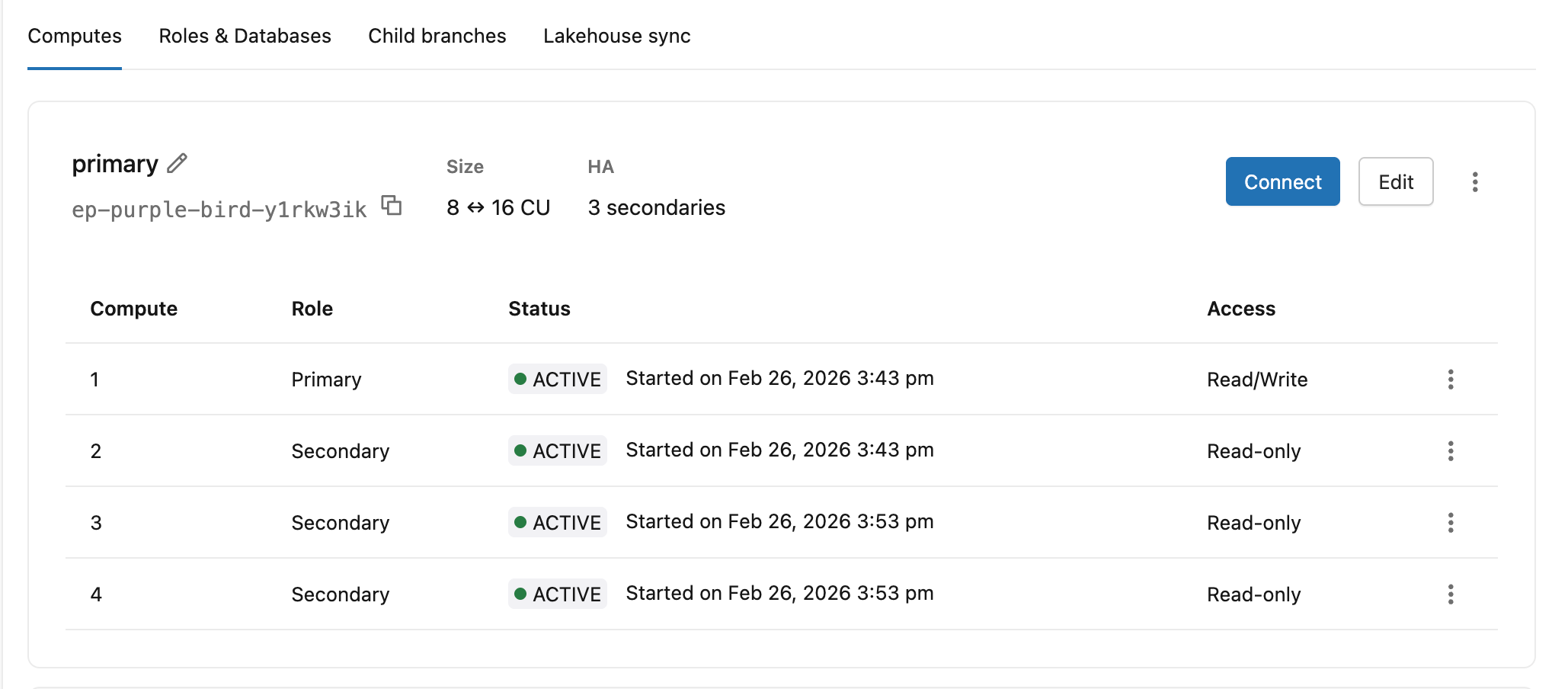
[コンピュート] タブには、各コンピュート インスタンスの 役割 (プライマリまたはセカンダリ)、 ステータス 、および アクセス レベルが一目で表示されます。
AZ分布
Lakebase は、プライマリ コンピュート インスタンスとセカンダリ コンピュート インスタンスをアベイラビリティ ゾーン全体に分散し、単一の AZ 障害がプライマリ コンピュート インスタンスとすべてのセカンダリ コンピュート インスタンスの両方に影響を与えるリスクを軽減します。
高可用性のオートスケール
高可用性構成内のすべてのコンピュート インスタンスは、同じオートスケール範囲を共有します。 最小 CU と最大 CU の間の最大スプレッドは 16 CU で、これはスタンドアロンのコンピュート インスタンスと同じ制限です。
セカンダリ インスタンスは常にプライマリと少なくとも同じ CU サイズにスケーリングされ、フェイルオーバー後もデータベース容量の一貫性が確保されます。
高可用性構成のコンピュート インスタンスでは、ゼロへのスケールは使用できません。 すべてのコンピュート インスタンスを手動で停止することはできますが、停止している間はエンドポイントが利用できなくなります。
セカンダリ コンピュート インスタンスとスタンドアロン リード レプリカの比較
セカンダリ コンピュート インスタンスとスタンドアロン リード レプリカは、同じブランチ上に共存できる異なる機能です。
セカンダリ コンピュート インスタンス | スタンドアロンのリードレプリカ | |
|---|---|---|
目的 | フェイルオーバー + オプションの読み取りオフロード | 読み取りオフロードのみ |
追加経由 | 高可用性構成 | リードレプリカの追加 |
フェイルオーバーに参加する | はい | No |
接続文字列 |
| 個別のエンドポイントを所有 |
サイジング | プライマリと共有(エンドポイントレベル) | 独立したサイズ |
高可用性と、セカンダリ コンピュート インスタンスが提供する以上の追加の読み取り容量の両方が必要な場合は、同じブランチで両方の機能を組み合わせることができます。 「リードレプリカ」を参照してください。
フェイルオーバー動作
自動フェイルオーバー
Lakebase は、プライマリ コンピュートの健全性を継続的に監視します。 プライマリが使用できなくなった場合、フェイルオーバーが自動的にトリガーされます。
フェイルオーバーでは、コミットされたすべてのトランザクションが保持されます。
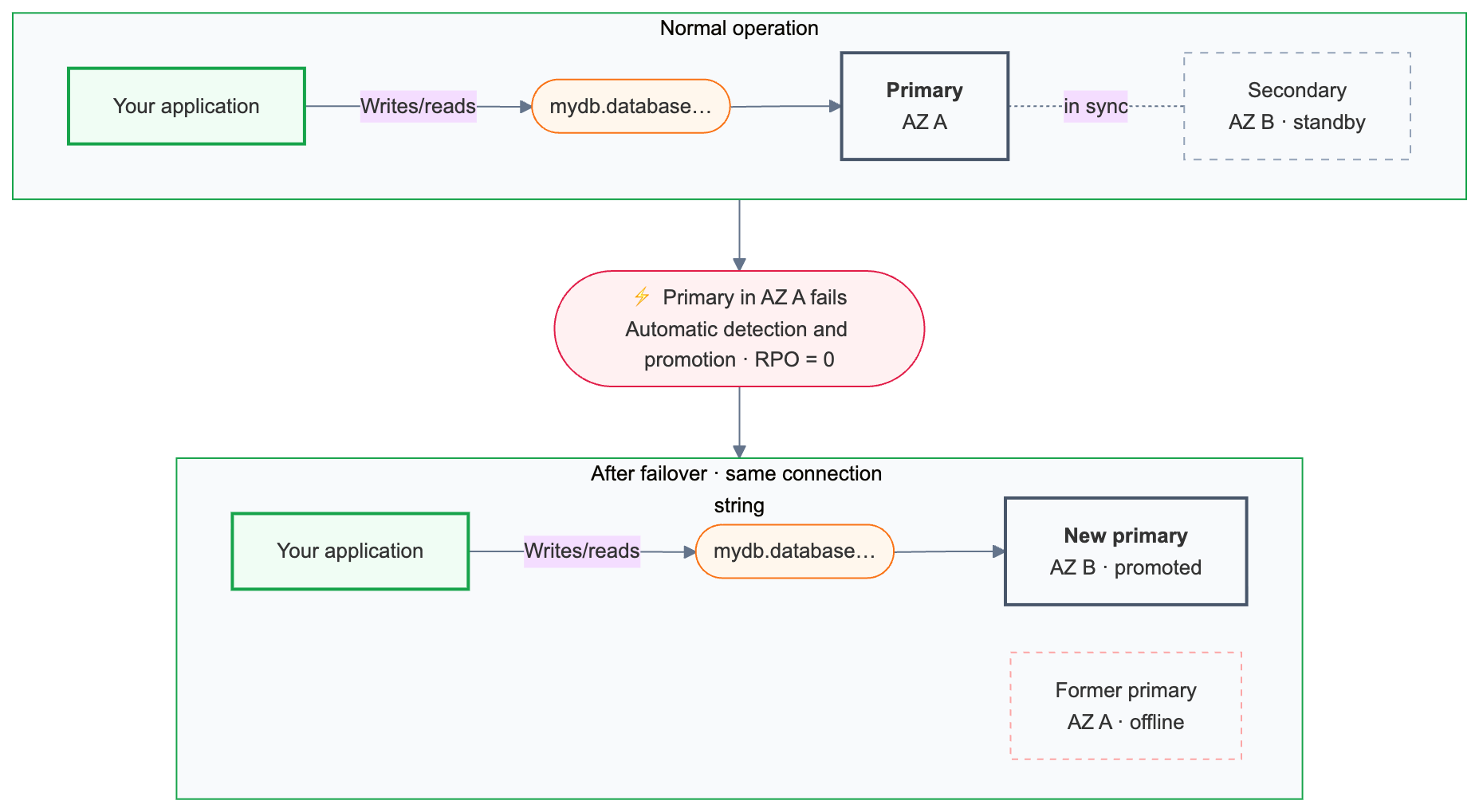
フェイルオーバー後、プライマリ接続文字列 ( {endpoint-id}.database.{region}.databricks.com ) は、新しく昇格されたコンピュート インスタンスに自動的にルーティングされます。 アプリケーションは接続構成を変更する必要はありませんが、フェイルオーバー中に既存の接続が終了し、再接続する必要があります。再試行ロジックを備えたアプリケーションはこれを自動的に処理します。
読み取り専用アクセスを有効にしたフェイルオーバー
読み取り専用インスタンスへのアクセスを許可する が有効になっている場合にフェイルオーバーが発生すると、昇格されたセカンダリが新しいプライマリになり、読み取りの処理を停止します。 読み取り可能なセカンダリが 2 つ以上ある場合、 -ro接続文字列の読み取りトラフィックは、代わりのセカンダリがプロビジョニングされるまで、容量が減少した状態で継続されます。1 つしかない場合は、交換品の準備ができるまで読み取りは完全に中断されます。
接続文字列
[ 接続] ダイアログには、両方の接続文字列と現在のコンピュート ステータスが表示されます。
「接続」ダイアログの「コンピュート」オプション | 接続文字列 | 用途 |
|---|---|---|
|
| すべての書き込み、現在のプライマリにヒットする必要がある読み取り |
|
| セカンダリ コンピュート インスタンスへの読み取りオフロード ( 読み取り専用コンピュート インスタンスへのアクセスを許可する が有効な場合のみ利用可能) |
プライマリ接続文字列は、フェイルオーバー後も含め、常に現在のプライマリにルーティングされます。
各コンピュート インスタンスには独自の直接接続文字列もあり、各行のアクション メニュー (⋮) を介して コンピュート タブからアクセスできます。 直接接続は、アプリケーションでの使用ではなく、個々のコンピュート インスタンスのトラブルシューティングを目的としています。 直接接続の文字列はコンピュートごとにあり、セカンダリが追加、削除、または昇格されると変更される可能性があります。
高可用性の制限
上限 | Value |
|---|---|
コンピュートインスタンス | 2、3、または 4 (プライマリ 1 個 + セカンダリ コンピュート インスタンス 1 ~ 3 個) |
オートスケール範囲(最大−最小) | 最小値と最大値の差が16 CU以下 |
ゼロにスケーリング | 高可用性構成のコンピュート インスタンスでは利用できません |
ベストプラクティス
これらのプラクティスに従うことで、フェイルオーバー イベント中でもアプリケーションの回復力と可用性を維持できます。
練習する | 詳細 |
|---|---|
接続再試行ロジックを実装する | フェイルオーバー中はアクティブな接続が終了します。障害が発生したプライマリへの接続は、タイムアウトするまでハングする可能性があります。障害を速やかに検出するには、ドライバーで TCP キープアライブまたは接続タイムアウトを構成してください。昇格されるセカンダリへの接続はアクティブに終了され、直ちにエラーが返されます。再試行ロジックを備えたアプリケーションは、数秒以内に自動的に再接続します。 |
ユースケースに合わせてセカンダリカウントを構成する | 各セカンダリ コンピュート インスタンスは、フェイルオーバー用に予約された事前に割り当てられたハードウェアを表します。 セカンダリ数を減らすと、フェイルオーバー容量が減少し、カバーされる可用性ゾーンも減少します。1 つのセカンダリ コンピュート インスタンスがフェイルオーバーをカバーします。 読み取り可能なセカンダリを有効にする場合は、2 つ以上構成します。1 つだけの場合、代替がプロビジョニングされるまで、フェイルオーバー中に読み取りが完全に中断されます。 |
セカンダリ コンピュート インスタンスの過負荷を避ける | サービスは、過負荷または遅延しているセカンダリ コンピュート インスタンスを再起動する場合があります。 クエリの負荷と接続数を監視し、高い使用率が持続している場合は CU サイズを増やします。 |
その他のリソース
- 高可用性を有効にして構成するための高可用性の管理
- オートスケールCUのサイジングとオートスケールの範囲の詳細については、
- 完全な接続のための接続文字列文字列のリファレンス