Lakebase変更データフィード
Lakebase変更データフィード機能はパブリック プレビュー段階にあります。
Lakebase変更データフィードとは何ですか?
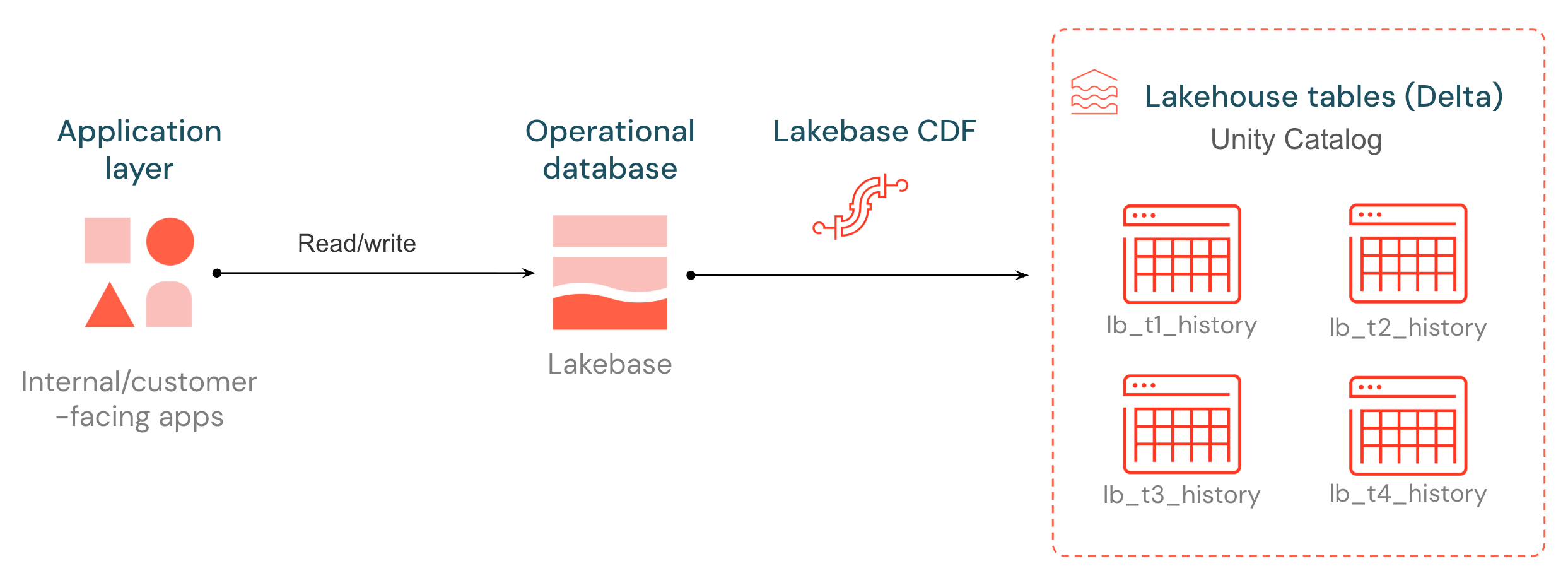
Lakebaseネイティブ変更データフィード (CDF) を導入し、下流のパイプライン、モデル、アプリケーションの運用データのロックを解除します。 Lakebase Postgres テーブルに対するすべての挿入、更新、削除は、ライトアヘッドログからキャプチャされ、 Unity Catalogで管理されるDeltaテーブルに新しい行として保存され、 約 15 秒ごとにフラッシュされます。 変更履歴は、あらゆるコンピュート エンジンが読み取ることができるオープン形式で保存されます。
宛先テーブルは、Deltaチェンジデータフィードと同じ形式に従います。各行には、 _pg_change_type 、LSN、トランザクション ID、およびタイムスタンプが含まれます。 運用上の変更は、外部のCDCスタックを構築することなく、 ETL 、監査、および下流のコンシューマーにとって第一級のサービスとなります。
ユースケース
Lakebase CDFは運用データをレイクハウスに取り込むことで、下流のパイプラインやアプリケーションが変化に即座に対応できるようにします。
ユースケース | 説明 |
|---|---|
ETLパイプライン | Lakebaseをメダリオンパイプラインのブロンズソースとして使用します。変更フィードに対してインクリメンタルなLakeflow PipelinesまたはSpark Structured Streamingジョブを構築し、ダウンストリームのシルバーおよびゴールドテーブルを更新します。 |
監査ログ | コンプライアンスおよびフォレンジック調査のために、Lakebaseテーブル上のすべての挿入、更新、削除の履歴を完全にクエリ可能な形で保持してください。履歴は不変なDeltaとなります。 |
外部システム | Lakebaseの変更データを、あらゆるエンジンが利用できるオープンフォーマットで保存します。宛先はUnity Catalog内のDeltaテーブルであるため、外部システムやDatabricks以外のリーダーからもフィードに直接アクセスできます。 |
このプレビューを有効にする
ワークスペース管理者は、ワークスペースのプレビュー ページ から Lakebase Change Data Feed を有効にする必要があります。
要件
- Lakebase Autoscaling: Postgres 17 を実行するLakebase Autoscaling プロジェクト。
- ソースデータベース: テーブルはLakebaseの
databricks_postgresデータベースに存在する必要があります。各プロジェクトは、このデフォルトデータベースを使用して作成されます。これは既知の制限事項です。 - Unity Catalog : CDFを構成するIDは、宛先カタログとスキーマに対して USE CATALOG 、 USE SCHEMA 、および CREATE TABLE 必要があります。 オブジェクトに対するアクセス許可の付与を参照してください。
- 「まだストレージ」: 「まだストレージ」で構成された宛先カタログはサポートされていません。
- Lakebaseプロジェクト: Postgresロールには、Lakebaseプロジェクトに対する CAN MANAGE 権限が必要です。プロジェクト所有者は、自分で CAN MANAGE 行うことができます。 プロジェクト権限の管理を参照してください。
- データ型: データ型マッピングを参照してください。Delta直接相当するものが存在しない型は、文字列として保存されます。
Lakebase CDF をセットアップします
まず、フィード内で必要なテーブルにレプリカ ID を完全に設定し (ステップ 1)、 Lakebaseアプリで CDF を開始します (ステップ 2)。 選択したUnity Catalogカタログとスキーマでは、データはlb_<table_name>_history Deltaテーブルとして表示されます。
ステップ 1: レプリカ ID を完全に設定する
LakebaseテーブルがCDFに参加するには、 REPLICA IDENTITY FULLが設定されている必要があります。デフォルトでは、Postgresは行が更新または削除されたときに主キーのみをログに記録します。完全なIDを設定すると、Postgresは変更前と変更後の行の状態の両方をライトアヘッドログに記録します。これは、CDFが完全な変更履歴を構築するために必要な情報です。
これらのコマンドは、Lakebase SQL Editorまたは任意のPostgresクライアントで実行できます。
- Single table
- All existing tables in a schema
- Auto-apply to future tables
ALTER TABLE <table_name> REPLICA IDENTITY FULL;
スキーマ内の既存のすべてのテーブル(この例ではpublic )にレプリカ ID を設定するには、以下を実行します。
DO $$
DECLARE r record;
BEGIN
FOR r IN
SELECT table_schema, table_name
FROM information_schema.tables
WHERE table_schema = 'public'
AND table_type = 'BASE TABLE'
LOOP
EXECUTE format(
'ALTER TABLE %I.%I REPLICA IDENTITY FULL;',
r.table_schema, r.table_name
);
END LOOP;
END $$;
新しく作成されたすべてのテーブルに自動的にREPLICA IDENTITY FULLが渡されるようにするには、 Postgres イベント トリガーをインストールします。これはCREATE TABLEごとに実行され、新しいテーブルにIDを設定します。
CREATE OR REPLACE FUNCTION public.set_full_replica_identity()
RETURNS event_trigger
LANGUAGE plpgsql
AS $$
DECLARE
obj record;
BEGIN
FOR obj IN
SELECT * FROM pg_event_trigger_ddl_commands()
WHERE command_tag = 'CREATE TABLE'
LOOP
EXECUTE format(
'ALTER TABLE %s REPLICA IDENTITY FULL;',
obj.object_identity
);
END LOOP;
END $$;
CREATE EVENT TRIGGER set_full_replica_identity_on_create
ON ddl_command_end
WHEN TAG IN ('CREATE TABLE')
EXECUTE FUNCTION public.set_full_replica_identity();
前のタブのループとイベントトリガーを組み合わせることで、既存のテーブルと将来のテーブルの両方を1つの設定でカバーできます。
レプリカIDセットを持つテーブルを確認してください
スキーマ内のどのテーブルにレプリカIDが構成されているかを確認するには、以下を実行します。
SELECT n.nspname AS table_schema,
c.relname AS table_name,
CASE c.relreplident
WHEN 'd' THEN 'default'
WHEN 'n' THEN 'nothing'
WHEN 'f' THEN 'full'
WHEN 'i' THEN 'index'
END AS replica_identity
FROM pg_class c
JOIN pg_namespace n ON n.oid = c.relnamespace
WHERE c.relkind = 'r'
AND n.nspname = 'public'
ORDER BY n.nspname, c.relname;
replica_identity = 'full'を含む行のみが CDF の計算対象となります。
ステップ 2: 変更データフィードを開始する
Lakebase CDFはスキーマレベルで設定されます。一度開始されると、ソーススキーマ内の現在および将来のすべてのテーブルがフィードに含まれます。
-
Databricksワークスペースで、アプリ スイッチャー (右上) から Lakebase Postgres を開きます。
-
Lakebaseプロジェクトと使用するブランチ(例: 本番運用 または main )を選択してください。
-
上部のパンくずリストでBranch名をクリックして Branch概要 を開き、次に Lakebase チェンジデータフィード tabをクリックします。
-
「開始」 をクリックしてください。
-
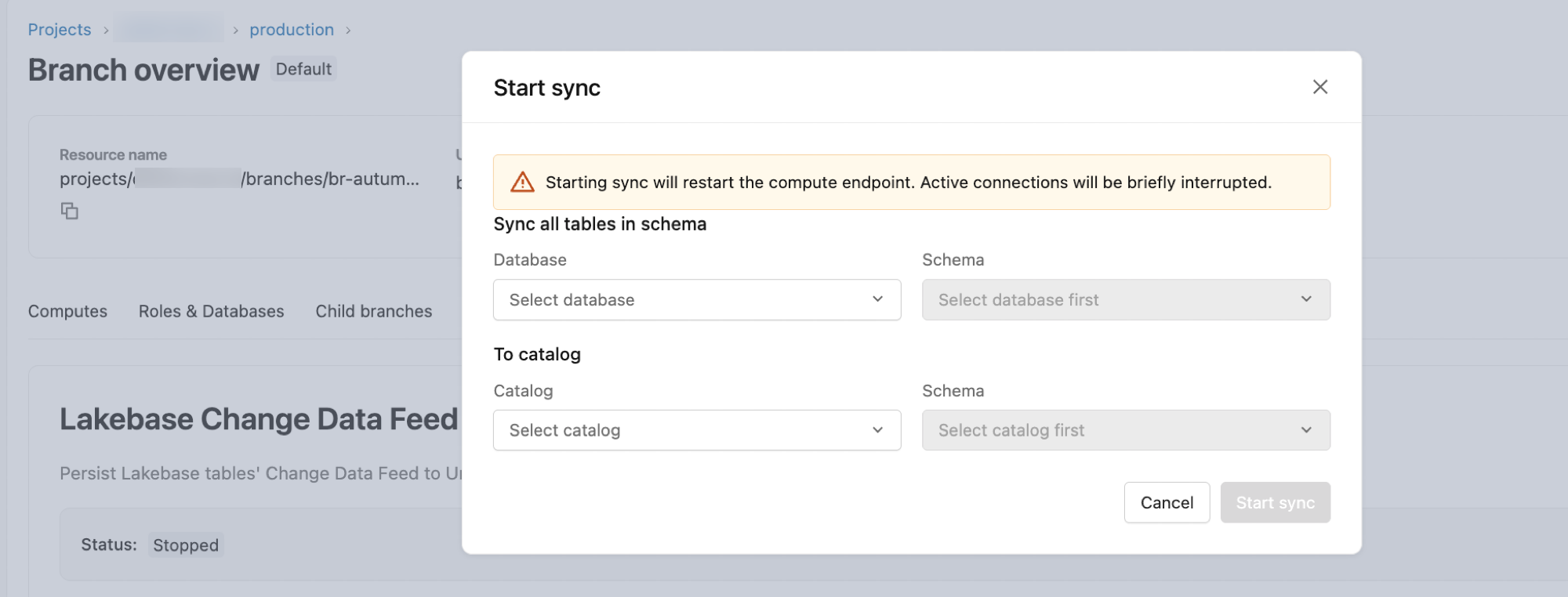
設定ダイアログで:
- データベース: デフォルトは
databricks_postgresです。 - スキーマ: ソースとなるPostgresスキーマを選択してください。
- カタログ化: 保存先のUnity Catalogカタログを選択してください。
- スキーマ: Unity Catalog保存先スキーマを選択してください。
- データベース: デフォルトは
-
フィードを開始するには、 「開始」 をクリックしてください。
テーブルは宛先ではlb_<table_name>_historyとして表示されます。それらを見つけるには、サイドバーの 「カタログ」 を開き、目的のカタログとスキーマに移動して、 「テーブル」 タブを開きます。
Lakebase チェンジデータフィード tabには、2つのサブタブがあります。
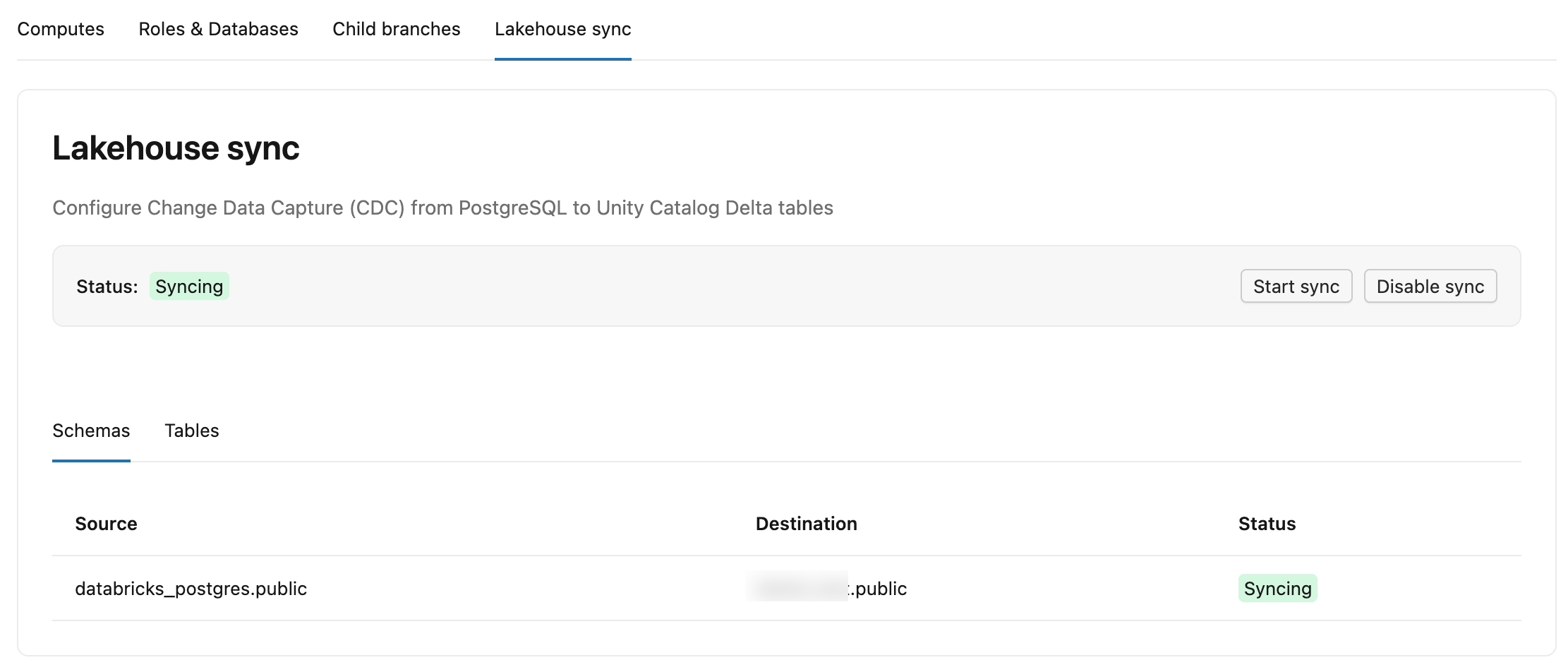
- スキーマ: 各スキーマ、その宛先カタログ、 Unity Catalog内のスキーマ、およびステータスを一覧表示します。
- テーブル: 各ソース テーブル、その宛先テーブル
lb_<table_name>_history、ステータス (StreamingまたはSnapshotting)、 コミット済み LSN (フィードが Delta に書き込まれた範囲。初期スナップショットの場合は-と表示されます)、および 最終更新 (テーブルが最後に変更を受け取った日時) を一覧表示します。
Lakebase SQL Editorで以下のコマンドを実行することで、Postgresからのフィードの状態を確認することもできます。
SELECT * FROM wal2delta.tables;
結果には、テーブルごとにtable_oid 、 status ( STREAMINGまたはSNAPSHOTTING )、 committed_lsn 、およびlast_write_timeが含まれます。
wal2deltaとは何ですか? Lakebase CDF は、 Lakebaseコンピュート内で実行される wal2delta Postgres 拡張機能を利用しています。 論理デコードを使用してライトアヘッドログ(WAL)の変更をキャプチャし、 Unity CatalogのDeltaテーブルに書き込みます。
宛先テーブルスキーマ
CDF は、ソース テーブルごとに 1 つの Delta テーブルを書き込みます。このテーブルは、宛先カタログとスキーマにlb_<table_name>_historyという名前で保存されます。ソース列に加えて、各行には以下のシステム列が含まれます。
列 | Type | 説明 |
|---|---|---|
| TEXT | 操作タイプ: |
| BIGINT | PostgreSQLログシーケンス番号。 |
| Integer | PostgreSQLトランザクションID。 |
| TIMESTAMP | 変更が処理された時刻のタイムスタンプ(タイムゾーン情報なし)。 |
| BIGINT | すべての変更を並べ替えるために使用される単調増加のソートキー。 |
一般的な変化パターン
- 初期スナップショット: CDF が既存の Lakebase テーブルで初めて実行されると、既存の各行に
_pg_change_type = 'insert'が書き込まれます。 - 更新: 更新を行うと、
_pg_change_type = 'update_preimage'(古い行) と_pg_change_type = 'update_postimage'(新しい行) の 2 つの行が生成されます。 - 削除: 削除すると、
_pg_change_type = 'delete'行が 1 つ生成されます。
これらはDeltaデータフィードと同じ変更イベントであるため、同じダウンストリーム パターンが適用されます。
運用上の挙動
- 名前の衝突: 2 つのソース テーブルが同じ宛先名にマッピングされる場合 (たとえば、
sales.usersとmarketing.users両方がlb_users_historyにマッピングされる場合)、CDF は最初のテーブルをlb_users_historyに書き込み、2 番目のテーブルに自動的に接尾辞を付けてlb_users_history_1にします。Unity Catalogで宛先テーブルの名前を変更しても、フィードは引き続き機能します。 - スキーマレベルのスコープ: LakebaseスキーマでCDFを起動すると、そのスキーマ内の現在および将来のすべてのテーブルが含まれます。空のテーブルはスキップされます。宛先に表示されるには、テーブルに少なくとも1行のデータが必要です。
- 削除されたソーステーブル: Lakebaseでテーブルを削除した場合、Unity Catalogの宛先Deltaテーブルは保持されます。
下流パイプラインを構築する
Lakebase CDFは、運用上の変更に対応する下流パイプライン向けに設計されています。以下の図は、飼料を摂取する3つの方法を、最も簡単なものから最も柔軟なものへと順に示しています。
シナリオの例。 eコマースアプリは、各行にitem_idとquantityが含まれるPostgres ordersテーブルに注文を記録します。物流チームはリアルタイムの在庫レベルを必要としています。CDF を使用すると、orders へのすべての変更は Unity Catalog の lb_orders_history Delta テーブルに保存されます。ダウンストリームパイプラインは、その変更データフィードを読み取り、注文が発注、編集、またはキャンセルされるたびに、inventory_levels テーブルを更新します。
マテリアライズドビューで現在の在庫を計算
最もシンプルなパターンは、履歴テーブルに対するSQLマテリアライズドビューです。MVは新しい変更イベントが発生するたびに段階的に更新され、下流のコンシューマーは他のテーブルと同様にそれを照会します。
CREATE MATERIALIZED VIEW inventory_levels AS
SELECT
item_id,
SUM(
CASE
-- New orders (and the "new half" of updates) decrement inventory
WHEN _pg_change_type IN ('insert', 'update_postimage') THEN -quantity
-- Cancellations (and the "old half" of updates) restore inventory
WHEN _pg_change_type IN ('delete', 'update_preimage') THEN quantity
ELSE 0
END
) AS current_inventory,
MAX(_timestamp) AS last_transaction_ts,
MAX(_pg_lsn) AS last_lsn
FROM lb_orders_history
GROUP BY item_id;
更新のたびに生成される2つの行は、正味の変更を除いて互いに相殺されるため、注文が編集されても累積合計は正しいままです。
Spark宣言型パイプラインによるストリームの変化
構造化されたメダリオンアーキテクチャの場合、LakeFlow Pipelinesを使用してブロンズ、シルバー、ゴールドテーブルを宣言します。Lakeflow pipelinesは、チェックポイントと依存関係管理が自動的に処理される接続されたパイプラインとしてそれらを実行します。
import dlt
from pyspark.sql import functions as F
@dlt.table
def inventory_adjustments():
return (
spark.readStream.table("<catalog>.<schema>.lb_orders_history")
.withColumn(
"delta",
F.when(F.col("_pg_change_type").isin("insert", "update_postimage"), -F.col("quantity"))
.when(F.col("_pg_change_type").isin("delete", "update_preimage"), F.col("quantity"))
.otherwise(0),
)
.select("item_id", "delta", "_timestamp")
)
@dlt.expect_or_drop("non_negative_stock", "on_hand >= 0")
@dlt.table
def inventory_levels():
return (
spark.read.table("LIVE.inventory_adjustments")
.groupBy("item_id")
.agg(F.sum("delta").alias("on_hand"))
)
inventory_adjustments readStreamで増分的にlb_orders_historyを読み込み、イベントごとの差分を生成します。現在の在庫を計算するために、 item_idごとにinventory_levelsを集計します。 エクスペクテーションは、在庫をマイナスに押し下げるような行を削除し、上流工程でバグが発生していることを示唆します。
完全なエンドツーエンドのチュートリアルについては、 「チュートリアル: チェンジデータ キャプチャを使用してETLパイプラインを構築する」を参照してください。
Spark構造化ストリーミングによるカスタム処理
カスタム マージ、副作用、複数のシンクなど、完全な制御が必要な場合は、 Spark構造化ストリーミングを使用して履歴テーブルを直接読み取り、 foreachBatchを使用して宛先に書き込みます。
from pyspark.sql import functions as F
from delta.tables import DeltaTable
def update_inventory(batch_df, batch_id):
deltas = (
batch_df
.withColumn(
"delta",
F.when(F.col("_pg_change_type").isin("insert", "update_postimage"), -F.col("quantity"))
.when(F.col("_pg_change_type").isin("delete", "update_preimage"), F.col("quantity"))
.otherwise(0),
)
.groupBy("item_id")
.agg(F.sum("delta").alias("delta"))
)
target = DeltaTable.forName(spark, "<catalog>.<schema>.inventory_levels")
(target.alias("t")
.merge(deltas.alias("s"), "t.item_id = s.item_id")
.whenMatchedUpdate(set={"on_hand": F.expr("t.on_hand + s.delta")})
.whenNotMatchedInsert(values={"item_id": "s.item_id", "on_hand": "s.delta"})
.execute())
(spark.readStream.table("<catalog>.<schema>.lb_orders_history")
.writeStream
.foreachBatch(update_inventory)
.option("checkpointLocation", "/Volumes/<catalog>/<schema>/checkpoints/inventory_levels")
.start())
各マイクロバッチは、 item_idごとに変更イベントを集約し、正味の差分をinventory_levelsにマージします。
設計によるインクリメンタル。 各lb_<table_name>_historyテーブルは追加のみのDeltaテーブルです。すべてのソース変更は、_pg_change_typeが操作を示す新しい行として記録されます。Databricks SQL マテリアライズドビュー、LakeFlow Pipelines、およびSpark Structured Streamingジョブはすべて、DeltaトランザクションLogから新しい行をインクリメンタルに処理するため、ダウンストリームパイプラインは変更されたものに比例した作業のみを行います。変更セマンティクスはすでにローデータにエンコードされているため、履歴テーブルでDelta チェンジデータフィードを有効にする必要はありません。
データ型マッピング
CDFは、ほとんどの標準的なPostgreSQLプリミティブ型をサポートしています。Delta直接相当するものが存在しない型は、文字列として保存されます。
PostgreSQL型 | Databricks Deltaタイプ | 注 |
|---|---|---|
BOOLEAN | BOOLEAN | |
INT、SMALLINT、BIGINT | INT、SMALLINT、BIGINT | |
TEXT 、VARCHAR、CHAR | STRING | |
JSONB | STRING | JSON文字列として保存されます。 |
ENUM | STRING | 列挙型ラベルとして保存されます。 |
NUMERIC / DECIMAL | DECIMALまたはSTRING | 可能な場合は、ソースの精度/スケールを使用します。互換性のない精度/スケール値に対して、ロスレスなリスケーリングを実行します。精度が38を超える場合、または精度/スケールが定義されていない場合(無制限の数値)は、 にフォールバックします。 NaN値はNULLにマッピングされるため、すべてのNUMERIC/DECIMAL型の列はNULLを許容します。PostgreSQLの数値型を参照してください。 |
DATE | DATE | |
TIMESTAMP | TIMESTAMP_NTZ | |
TIMESTAMPTZ | TIMESTAMP | |
FLOAT, DOUBLE | FLOAT, DOUBLE |
文字列として保存されるタイプ:
- Geography/Geometry (PostGIS): PostGIS 拡張機能の型 (例:
geometry、geography)。 - Vector (pgvector): pgvector 拡張機能の
vector型。 - Composite/struct型:
CREATE TYPE ... AS (field_name type, ...)で定義されたカスタム型。これらは、名前付きフィールドを持つ行型です。 - Map: hstore (
hstore拡張機能から) のようなマップに似たキーと値の型。PostgreSQLには組み込みのマップ型はありません。hstoreは、キーと値のペアを列に格納する一般的な方法です。
スキーマ変更の管理
- Postgresで テーブル名を変更する (例えば、
ALTER TABLE users RENAME TO customers)と、フィードが継続されます。宛先Deltaテーブル名は変更されません。lb_users_historyのままです。 - スキーマの変更 (列の追加、列の削除、または列のデータ型の変更)は、影響を受けるテーブルの再スナップショットをトリガーします。CDFはPostgresからテーブル全体を再読み込みし、宛先のDeltaテーブルに書き戻します。
Lakebase CDFを無効にする
CDFを無効にすると、プロジェクト内のすべてのLakebaseスキーマへのフィードが停止します。
- Databricksワークスペースで、アプリ スイッチャー (右上) から Lakebase Postgres を開きます。
- Lakebaseプロジェクトと、CDFを設定したブランチを選択してください。
- 上部のパンくずリストでBranch名をクリックして Branch概要 を開き、次に Lakebase チェンジデータフィード tabをクリックします。
- 「無効にする」 をクリックしてください。確認ダイアログで、変更がDeltaテーブルに反映されなくなるという警告を確認し、再度 「無効にする」 をクリックして確定します。
CDF を無効にしてもコンピュートは再起動されません。
制限事項とトラブルシューティング
テーブルごとのステータス (スナップショット、スキップ、またはストリーミング) は、 Lakebase チェンジデータフィード tabで、またはLakebaseでこれを実行することで確認できます。
SELECT * FROM wal2delta.tables;
テーブルがフィードに表示されない一般的な理由:
REPLICA IDENTITY FULLが設定されていない場合: テーブルに対してALTER TABLE <table_name> REPLICA IDENTITY FULL;を実行します。ステップ 1: レプリカ ID を完全に設定するを参照してください。- パーティションテーブル: Lakebaseのパーティションテーブルはサポートされていません。パーティション化されたテーブルを含むスキーマは、それらのテーブルの動作不良を引き起こします。
- 空のテーブル: 行数がゼロのテーブルは、少なくとも1行が存在するまでスキップされます。
次のステップ
- Spark宣言型パイプライン を使用して インクリメンタルETLを構築 します 。完全なチュートリアルについては、「チュートリアル: チェンジデータ キャプチャを使用してETLパイプラインを構築する」を参照してください。
- Databricks SQLを使用して ブロンズ レイヤーをクエリします 。Databricks SQL を使用したデータウェアハウジングの開始を参照してください。
- 宛先Deltaテーブルに対するタイムトラベルクエリーによる 履歴の監査 。