Lakebase Search
ベータ版
この機能はベータ版です。ワークスペース管理者は、 プレビュー ページからこの機能へのアクセスを制御できます。Databricksのプレビューを管理するを参照してください。
Lakebase Searchは、Lakebase Autoscalingプロジェクトにハイブリッドベクトル検索とキーワード検索の機能を追加します。プロジェクト設定で一度有効にしてから、 lakebase_vectorとlakebase_text Postgres拡張機能をインストールして、検索機能の構築を開始してください。
ベクトル、キーワード、ハイブリッド検索
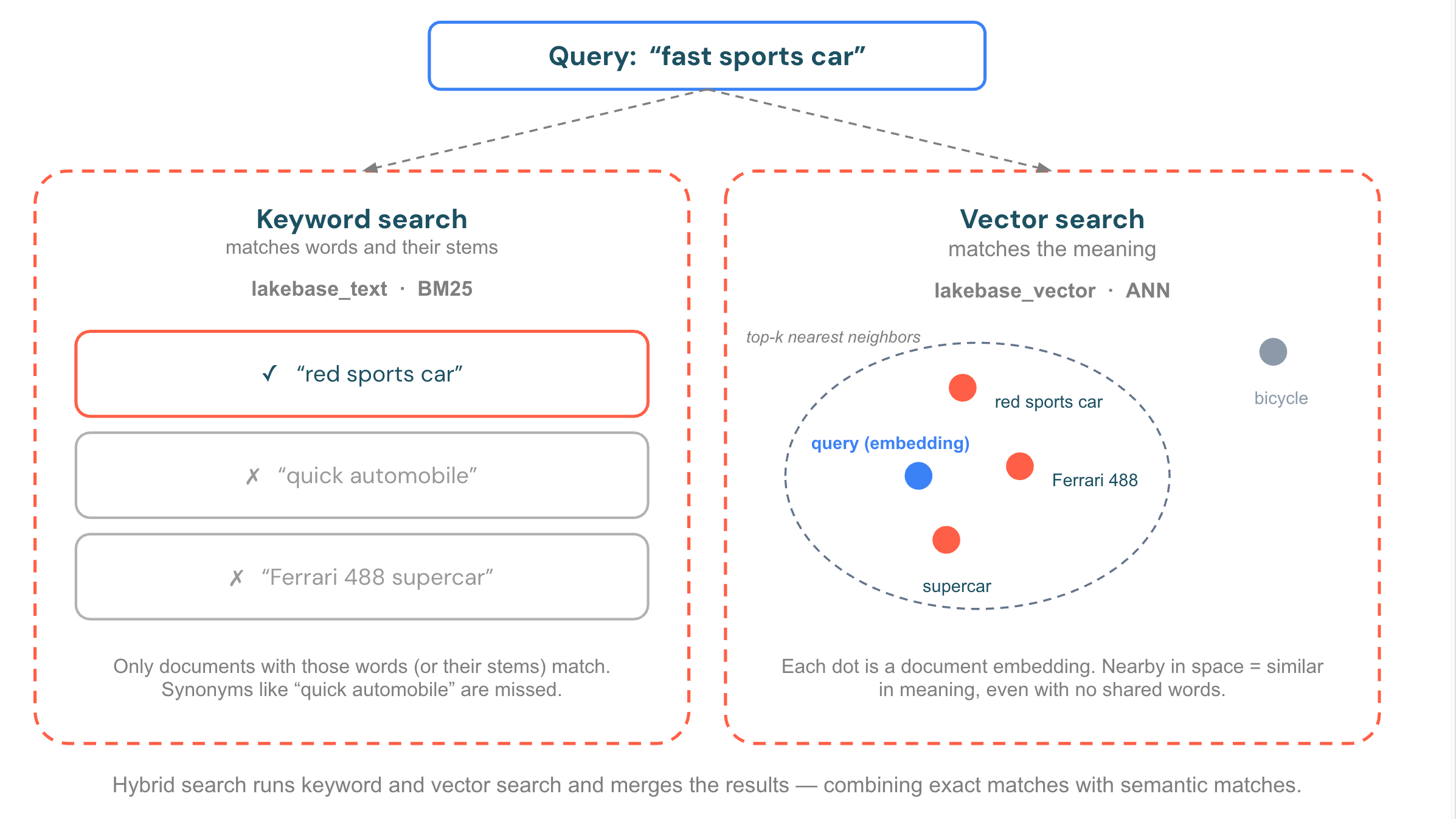
Lakebase Searchは、相補的な2つの検索方法を提供します。ハイブリッド検索のために、個別にまたは組み合わせて使用してください。
- ベクトル (セマンティック) 検索 は、共通の単語がない場合でも、クエリに最も意味が近い行を見つけます。埋め込み(モデルによって生成された数値ベクトル)を使用してクエリを実行すると、インデックスは距離に基づいて最も近いベクトルを返します。自然言語の質問、レコメンデーション、および検索拡張生成(RAG)に利用できます。
lakebase_vectorによって提供されます。 - キーワード(全文)検索 は、BM25関連性スコアリングを使用して、クエリ内の正確な用語との一致度に応じて行をランク付けします。言葉遣いが重要な場合、名前、コード、および正確な用語の検索にこれを使用してください。
lakebase_textによって実行されます。 - ハイブリッド検索 は、両方の検索を実行し、結果を1つのランク付けされたリストに結合するため、意味的に類似した一致と正確な用語の一致の両方を一緒に取得できます。クエリの意図が特定の用語と混在している場合(実際の検索で最も一般的なケース)に使用してください。
仕組み
内部的には、Lakebase Search は2つのPostgres拡張機能に基づいています。
-
lakebase_vector は、近似最近傍(ANN)ベクトル検索を
lakebase_annインデックスタイプ経由で追加します。pgvectorにそのまま使用できるコンパニオンです。同じベクトル型、距離演算子、クエリ構文が修正なしで機能します。内部的には、RaBitQ量子化を伴うIVFパーティショニングを使用しており、これにより、単一のインデックスで10億を超えるベクトルをサポートし、HNSWよりも最大50~100倍高速に構築できます。インデックスはストレージにバックアップされており、ウォームアップなしでスケールゼロを存続します。 -
lakebase_text
lakebase_bm25は、 インデックスタイプを介してBM25全文検索を追加します。PostgreSQLの標準tsvector型およびクエリ演算子と互換性があります。BM25ランキングは、単語の出現頻度、ドキュメント長、およびコーパス全体の統計を同時に考慮します。Top-Kプッシュダウン (Block-Max WAND) は、すべてのマッチをスコアリングする代わりに、インデックスからK個の最も関連性の高い結果のみを取得します。
要件
- Postgres 16以降
- プロジェクトのベータアクセス。Lakebase Searchはベータ版です。ご希望の場合は、Databricksアカウント担当者にお問い合わせください。
- プロジェクトでLakebase Searchを有効にすると、元に戻すことはできません。
Lakebase Search を有効にする
プロジェクトにアクセス権が付与されたら、プロジェクト設定でLakebase Searchを有効にします。
- Lakebaseプロジェクトで、左側のナビゲーションにある 設定 をクリックします。
- Lakebase Search の下で、 Enable Lakebase Search をクリックします。
Lakebase Search の有効化:
- プロジェクト内のすべてのコンピュートを再起動し、アクティブな接続をすべて切断します。
lakebase_vectorとlakebase_text拡張機能をインストール可能にします- 一度有効にすると無効にすることはできません
拡張機能をインストールする
Lakebase Search を有効にした後、データベースに拡張機能をインストールします。
-- Required: vector search (CASCADE installs pgvector as a dependency)
CREATE EXTENSION IF NOT EXISTS lakebase_vector CASCADE;
-- Required: BM25 full-text search
CREATE EXTENSION IF NOT EXISTS lakebase_text;
使い始める
次の例では、ベクトル列と全文検索列の両方を含むdocumentsテーブルを作成し、その後、ベクトルとキーワードのクエリを実行します:
これらの例では、説明のために'[0.1, 0.2, 0.3]'のような小さなリテラルベクトルを使用します。実際のアプリケーションでは、エンべディングモデルで外部からエンべディングを生成し、その結果をVECTOR列に保存します。Databricksでは、Model Servingを使用してエンべディングモデルをクエリーできます。たとえば、ノートブックまたはDatabricks SQLでai_queryを使用して、その結果のベクトルをLakebaseに挿入します。VECTOR(n)列とインデックスは、モデルの出力と同じディメンション n を使用する必要があります (通常は384~1536)。
-- Create a table with a vector column and a tsvector column
CREATE TABLE documents (
id SERIAL PRIMARY KEY,
title TEXT NOT NULL,
body TEXT NOT NULL,
embedding VECTOR(3),
body_tsv TSVECTOR
);
-- Create a vector search index
CREATE INDEX ON documents USING lakebase_ann (embedding vector_cosine_ops);
-- Insert sample data and populate the tsvector column
INSERT INTO documents (title, body, embedding, body_tsv) VALUES
('Postgres overview', 'Postgres is an open-source relational database.', '[0.1, 0.2, 0.3]', to_tsvector('english', 'Postgres is an open-source relational database.')),
('Vector search guide', 'Vector search finds semantically similar results.', '[0.4, 0.5, 0.6]', to_tsvector('english', 'Vector search finds semantically similar results.')),
('Full-text search', 'BM25 ranking improves keyword search relevance.', '[0.7, 0.8, 0.9]', to_tsvector('english', 'BM25 ranking improves keyword search relevance.'));
-- Build the BM25 index after inserting data
-- BM25 computes corpus statistics at build time, not incrementally
CREATE INDEX documents_body_bm25 ON documents USING lakebase_bm25 (body_tsv);
-- Vector similarity search
SELECT id, title
FROM documents
ORDER BY embedding <=> '[0.1, 0.2, 0.3]'
LIMIT 5;
-- BM25 keyword search (lower score = more relevant)
SELECT id, title,
body_tsv <@> to_bm25query(to_tsvector('english', 'database'), 'documents_body_bm25') AS score
FROM documents
ORDER BY score
LIMIT 5;
ハイブリッド検索で結果を結合する
次のハイブリッド検索の例では、使い始めるからdocumentsテーブルとインデックスを再利用します。それぞれ独立して各検索から上位候補を取得し、それらをReciprocal Rank Fusion(RRF)を使用して単一のランキングに結合します。どちらか一方または両方の検索で上位にランク付けされる結果は、より高いスコアを獲得します。
WITH vector_ranked AS (
SELECT id, RANK() OVER (ORDER BY dist) AS rank
FROM (
SELECT id, embedding <=> '[0.1, 0.2, 0.3]' AS dist
FROM documents
ORDER BY dist
LIMIT 40
) v
),
keyword_ranked AS (
SELECT id, RANK() OVER (ORDER BY score) AS rank
FROM (
SELECT id, body_tsv <@> to_bm25query(to_tsvector('english', 'database'), 'documents_body_bm25') AS score
FROM documents
ORDER BY score
LIMIT 40
) k
)
SELECT d.id, d.title,
COALESCE(1.0 / (60 + v.rank), 0) + COALESCE(1.0 / (60 + k.rank), 0) AS rrf_score
FROM documents d
LEFT JOIN vector_ranked v ON d.id = v.id
LEFT JOIN keyword_ranked k ON d.id = k.id
WHERE v.id IS NOT NULL OR k.id IS NOT NULL
ORDER BY rrf_score DESC, d.id
LIMIT 10;
各CTEは独自のトップ40候補を取得します。RANK()は同点スコアに同じランクを割り当てます。定数60は低ランク結果の影響を抑制し、d.idは安定したページネーションのために同点を解消します。データに合わせて、リストごとのLIMITとRRF定数を調整してください。重み付けスコアリングなどの他の融合方法も有効です。
拡張機能
拡張機能 | 目的 | インデックスタイプ |
|---|---|---|
ANNベクトル検索、pgvector互換 |
| |
BM25全文検索、FTS互換 |
|