レイクハウスシンク
Lakebaseオートスケールは、オートスケールコンピュート、ゼロへのスケール、分岐、即時復元を備えたLakebaseの最新バージョンです。 サポートされているリージョンについては、 「リージョンの提供状況」を参照してください。Lakebaseプロビジョニング ユーザーの場合は、 Lakebaseプロビジョニング」を参照してください。
レイクハウス Sync はパブリック プレビュー段階です。
レイクハウスシンクとは?
レイクハウス Sync は、行レベルの変更をキャプチャし、それをSCDタイプ 2 履歴として書き込むことで、Lakebase Postgres テーブルからUnity Catalogで管理されるDeltaテーブルへの継続的かつ低レイテンシのレプリケーションを可能にします。 各変更は新しい行として追加されるため、時間の経過に伴う行の変更の完全な履歴が保持されます。この同期には、外部コンピュート、パイプライン、ジョブは必要ありません。 これは Lakebase のネイティブ機能です。
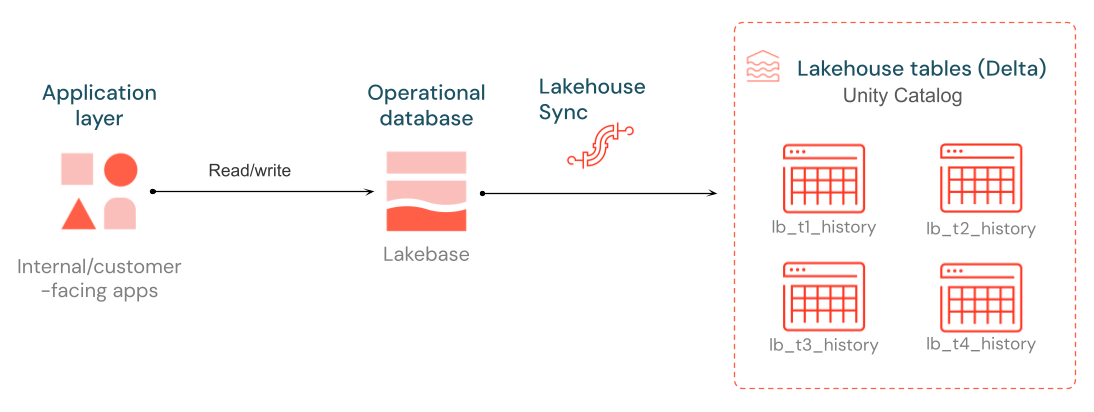
レイクハウス Sync は、変更データキャプチャ ( CDC ) を使用して、Lakebase Postgres データベースからUnity Catalogに変更をストリーミングします。 Deltaテーブルは、選択したカタログとスキーマの形式lb_<table_name>_historyに従って名前が付けられます。 各変更 (挿入、更新、削除) は行として追加されるため、時間の経過とともにデータがどのように変化したかの完全な履歴が保持されます。
使用例
以下は、Lakebase トランザクション データベースからレイクハウスにデータをストリーミング変更する、レイクハウス Sync の使用例です。
ユースケース | 説明 |
|---|---|
高速分析 | Lakebase データの実行集計と分析。 |
メダリオンのソース | Lakebase をメダリオンアーキテクチャのソースとして使用します。 Deltaテーブルは、 Databricksパイプライン、 Spark宣言型パイプライン (SDP) 、またはDelta Live Tables ( DLT )を使用して処理して、ダウンストリーム テーブルを構築できます。 |
レイクハウスの全歴史 | オプションでデータのサブセットのみを Lakebase に保持しながら、レイクハウス内のすべての変更の完全な履歴を保存します。 |
このプレビューを有効にする
レイクハウス Sync を使用するには、ワークスペース管理者は、ワークスペースの プレビューページ から レイクハウス Sync の プレビューを有効にする必要があります。
要件
- Lakebase Autoscaling: Postgres 17 を実行するLakebase Autoscaling プロジェクト。
- ソースデータベース: テーブルはLakebaseの
databricks_postgresデータベースに存在する必要があります。これは既知の制限事項です。各プロジェクトは、このデフォルトデータベースを使用して作成されます。 - データ型: 各PostgreSQL型がDeltaにどのようにマッピングされるかについては、 「データ型マッピング」を参照してください。Delta直接相当するものが存在しない型は、文字列として保存されます。
- Unity Catalog : 同期を構成する ID には、宛先カタログとスキーマに対する USE CATALOG 、 USE SCHEMA 、および CREATE TABLE 必要です。 「オブジェクトに対する権限の付与」を参照してください。
- 「まだストレージ」: 「まだストレージ」で構成された宛先カタログはサポートされていません。
- Lakebase プロジェクト: Postgres ロールには、同期元の Lakebase プロジェクトに対する CAN MANAGE 権限が必要です。自分の ID が Lakebase プロジェクトを所有している場合、デフォルトで CAN MANAGE 権限が付与されます。「プロジェクト権限の管理」を参照してください。
開始するには、同期するテーブルにレプリカ ID を完全に設定し (ステップ 1)、Lakebase アプリで同期を開始します (ステップ 2)。 データは、選択した Unity Catalog カタログとスキーマ内のlb_<table_name>_historyテーブルとして表示されます。開始する前にレイクハウス Sync の仕組みについて詳しく知りたい場合は、 「レイクハウス Sync の仕組み」を参照してください。
同期の設定
ステップ 1: レプリカ ID を完全に設定する
Lakebase テーブルを正常に同期するには、レプリカ ID を full に設定する必要があります。空のスキーマまたは既にテーブルが含まれているスキーマで同期を構成できます。パーティション化されたテーブルはサポートされていません。
デフォルトでは、Postgres は行が更新または削除されたときに主キーのみをログに記録します。REPLICA IDENTITY FULLを設定すると、Postgres は先行書き込みログに行の前後の完全な状態を記録します。これは、レイクハウス Sync が完全な更新履歴を構築できるようにするために必要です。
次のコマンドは、Lakebase SQL エディターまたは任意の Postgres クライアントから実行できます。この例では、Lakebase SQL エディターを使用します。開くには、 Databricksワークスペースで、アプリ スイッチャー (右上) から Lakebase Postgres を 開き、プロジェクトと同期するブランチ (たとえば、 本番運用 または main ) を選択して、サイドバーから SQLエディターを 選択し、ブランチとデータベースを選択します。 詳細については、 Lakebase SQL エディターからのクエリを参照してください。
- Single table
- Multiple tables
単一のテーブルでレプリカ ID を完全に設定するには、次を実行します。
ALTER TABLE <table_name> REPLICA IDENTITY FULL;
<table_name>テーブル名に置き換えます。
スキーマ内のすべてのテーブル (たとえば、 public ) のレプリカ ID を完全に設定するには、次を実行します。
DO $$
DECLARE r record;
BEGIN
FOR r IN
SELECT table_schema, table_name
FROM information_schema.tables
WHERE table_schema = 'public'
AND table_type = 'BASE TABLE'
LOOP
EXECUTE format(
'ALTER TABLE %I.%I REPLICA IDENTITY FULL;',
r.table_schema, r.table_name
);
END LOOP;
END $$;
- 既存のテーブル: 同期を開始する前に、スキーマ内のすべての既存のテーブルに対してこれを実行します。
- 新規テーブル: 同期設定後に作成されたテーブルについては、データを挿入する前にこのコマンドを実行してください。先に行を挿入した場合でも、同期処理はスナップショットを通してそれらの行を取得します。
レプリカIDが設定されているテーブルを確認する
どのテーブルにレプリカ ID が設定されているのか (そしてどれがfullのか) を確認するには、Lakebase で次のコマンドを実行します。
SELECT n.nspname AS table_schema,
c.relname AS table_name,
CASE c.relreplident
WHEN 'd' THEN 'default'
WHEN 'n' THEN 'nothing'
WHEN 'f' THEN 'full'
WHEN 'i' THEN 'index'
END AS replica_identity
FROM pg_class c
JOIN pg_namespace n ON n.oid = c.relnamespace
WHERE c.relkind = 'r'
AND n.nspname = 'public'
ORDER BY n.nspname, c.relname;
異なる場合は、 n.nspname = 'public'スキーマ名に変更します。replica_identity = fullの行のみが同期の準備ができています。
ステップ 2: レイクハウス同期を開始する
レイクハウス Sync はスキーマ レベルで構成されます。 一度設定すると、そのスキーマ内の現在のテーブルと将来のテーブルはすべて Unity Catalog に同期されます。
-
Databricks ワークスペースで、アプリ スイッチャー (右上) から Lakebase Postgres を開きます。
-
Lakebase プロジェクトと同期するブランチ (たとえば、 本番運用 または main ) を選択します。
-
ブランチの概要 を開き、 レイクハウスの同期 タブをクリックします。
-
[同期を開始] をクリックします。
-
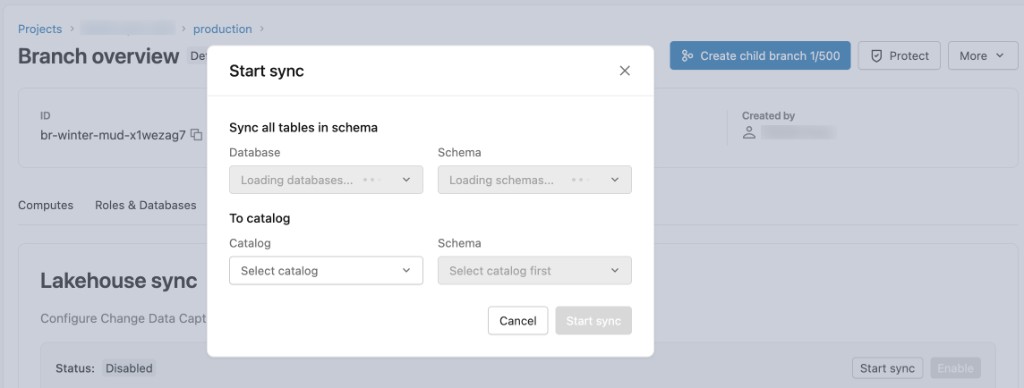
構成ダイアログで:
- データベース: デフォルトは
databricks_postgresです。 - スキーマ: 同期するソース Postgres スキーマを選択します。
- カタログへ: 宛先の Unity Catalog カタログを選択します。
- スキーマ: 宛先のUnity Catalogスキーマを選択します。
- データベース: デフォルトは
-
データの同期を開始するには、 「同期の開始」 をクリックします。
テーブルは、選択した Unity Catalog カタログとスキーマにlb_<table_name>_historyとして表示されます。レイクハウスで、サイドバーの [カタログ] を開き、目的のカタログとスキーマに移動して、スキーマの [概要] にある [ テーブル] タブを開いてDeltaテーブルを表示します。 Lakebase の レイクハウス sync タブでは、ステータスを確認し、何が同期しているかを検査できます。
レイクハウスの同期タブに表示される内容
同期が有効になっている場合、タブの上部に 「ステータス: 同期中」 と表示され、変更がキャプチャされて Delta テーブルに同期されていることが示されます。
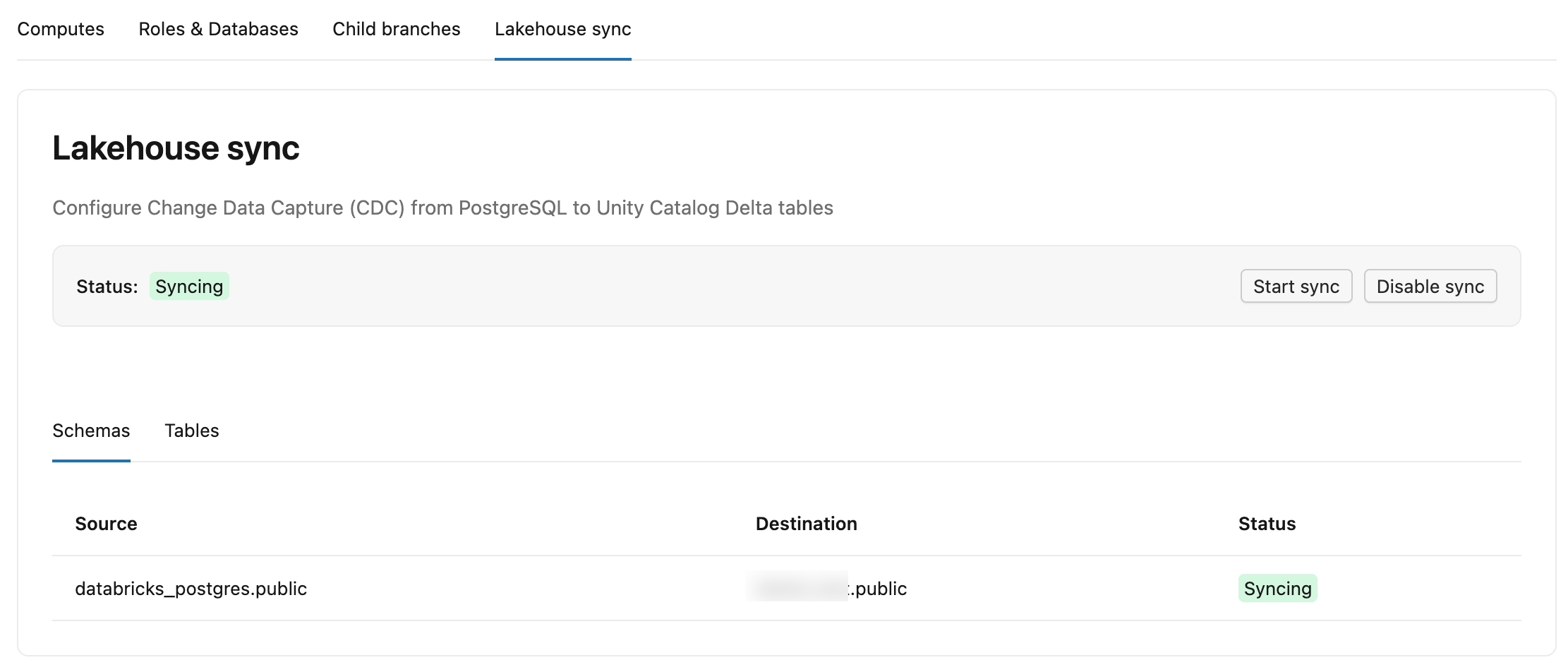
2 つのサブタブにマッピングとテーブルごとの進行状況が表示されます。
- スキーマ: 各ソース スキーマとその宛先カタログおよびUnity Catalog内のスキーマを、そのスキーマの ステータス ( 同期中 など) とともに一覧表示します。
- テーブル: 各ソース テーブル、 Unity Catalog内のその宛先
lb_<table_name>_historyテーブル、 ステータス ( 同期中 または スナップショット中 )、 コミット済み LSN (同期がDeltaにどの程度書き込まれたか。テーブルがまだ初期状態の間は-と表示されます)、および 最終同期 (テーブルが最後に同期された日時) を一覧表示します。
Lakebase SQL エディター(または任意の Postgres クライアント) からSELECT * FROM wal2delta.tables;実行して、同期ステータスを検査することもできます。結果には、テーブルごとにtable_oid 、 status (たとえば、 STREAMINGまたはSNAPSHOTTING )、 committed_lsn 、およびlast_write_timeが含まれます。
wal2deltaとは何ですか? レイクハウス Sync は、Lakebase コンピュート内で実行される wal2delta Postgres 拡張機能を利用しています。 論理デコードを使用して、先行書き込みログ (WAL) の変更をキャプチャし、Unity Catalog の Delta テーブルに書き込みます。
同期を無効にする
同期を無効にすると、同期していたすべての Lakebase スキーマのレプリケーションが停止します。
- Databricks ワークスペースで、アプリ スイッチャー (右上) から Lakebase Postgres を開きます。
- Lakebase プロジェクトと、同期を構成したブランチ (例: 本番運用 または main ) を選択します。
- ブランチの概要 を開き、 レイクハウスの同期 タブをクリックします。
- 同期を無効にするを クリックします。確認ダイアログで、変更によって Delta テーブルへの同期が停止されるという警告を確認し、もう一度 [無効にする] をクリックして確認します。
同期を無効にしてもコンピュートは再起動されません。
後で同期を再度有効にした場合、システムは完全な再スナップショットを実行しません。同期が無効になっている間に発生した変更は、宛先 Delta テーブルから永久に失われます。
レイクハウス Sync の仕組み
同期では、Lakebase 内のデータの現在の状態をミラーリングするために宛先の Unity Catalog テーブルを上書きするのではなく、変更イベントごとに新しい行を追加します。これにより、時間の経過とともにデータがどのように変化したかを示す完全かつ不変のログが提供されます。
- 宛先の命名: DeltaテーブルはUnity Catalogに作成され、命名パターン
lb_<table_name>_historyが使用されます。 これらは UC 管理の Delta テーブルです。 - 名前付けの衝突: 2 つのソース テーブルが同じ宛先名にマッピングされる場合 (たとえば、
sales.usersとmarketing.usersはどちらもlb_users_historyにマッピングされます)、レイクハウス Sync は検出した最初のテーブルをlb_users_historyに書き込み、2 番目のテーブルに自動サフィックスをlb_users_history_1に付けます。 Unity Catalog内の宛先テーブルの名前は、必要に応じて変更できます。変更後も同期は引き続き機能します。Unity Catalogはスキーマ内で一意のテーブル名を強制するため、2つのDeltaテーブルが同じ宛先名を共有することはできません。 - スキーマ レベルの同期: Lakebase スキーマの同期を構成すると、そのスキーマ内の現在のテーブルと将来のテーブルがすべて同期されます。空のテーブルは同期されません。同期に表示されるためには、Lakebase テーブルに少なくとも 1 つの行が必要です。
- 削除されたテーブル: Lakebase でテーブルを削除した場合、Unity Catalog 内の宛先 Delta テーブルは保持されます (削除されません)。
同期ステータスは、ブランチ概要の レイクハウス sync タブで監視するか、Lakebase でSELECT * FROM wal2delta.tables;実行することで監視できます。
宛先Deltaテーブルスキーマ
同期により、データ列に加えて、次のシステム列が Unity Catalog 内の各宛先 Delta テーブルに追加されます。
列 | Type | 説明 |
|---|---|---|
| TEXT | 操作タイプ: |
| BIGINT | Postgres ログ シーケンス番号。 |
| Integer | Postgres トランザクション ID。 |
| TIMESTAMP | 同期処理が変更を処理した時点のタイムスタンプ(タイムゾーンは含まない)。 |
| BIGINT | すべての変更を並べ替えるために使用される単調増加のソートキー。 |
一般的な変化のパターン
これらのパターンは、Unity Catalog の宛先 Delta テーブルに表示されます。
- 初期ロード: 既存の Lakebase テーブルで初めて同期が実行されると、既存の各行に
_pg_change_type=insertが書き込まれます。 - 更新: 更新により 2 つの行が生成されます。1 つは
_pg_change_type=update_preimage(古い行)、もう 1 つは_pg_change_type=update_postimage(新しい行) です。 - 削除: 削除により、
_pg_change_type=deleteの行が 1 つ生成されます。
制限事項とトラブルシューティング
テーブルのステータス (どのテーブルがスナップショットしているか、スキップされているか、ストリーミングしているか) は 、レイクハウスの sync タブで、または Lakebase で実行することで確認できます。
SELECT * FROM wal2delta.tables;
テーブルが同期されない一般的な理由:
- REPLICA IDENTITY FULL が設定されていません: 各テーブルに対して
ALTER TABLE <table_name> REPLICA IDENTITY FULL;を実行したことを確認してください。 - パーティション テーブル: Lakebase パーティション テーブルはサポートされていません。パーティション化されたテーブルを含むスキーマを同期すると、それらのテーブルの同期が失敗します。
データ型のマッピング
同期機能は、ほとんどの標準的なPostgreSQLプリミティブ型をサポートしています。Delta直接相当するものが存在しない型は、文字列として保存されます。
PostgreSQL型 | Databricks Delta型 | 注 |
|---|---|---|
ブール値 | ブール値 | |
INT、SMALLINT、BIGINT | INT、SMALLINT、BIGINT | |
TEXT 、VARCHAR、CHAR | STRING | |
JSONB | STRING | JSON 文字列として保存されます。 |
enum | STRING | 列挙ラベルとして保存されます。 |
数値 / 小数点 | 小数点または文字列 | 可能な場合は、ソースの精度/スケールを使用します。互換性のない精度/スケール値に対して、ロスレスなリスケーリングを実行します。精度が38を超える場合、または精度/スケールが定義されていない場合(無制限の数値)は、 にフォールバックします。 NaN値はNULLにマッピングされるため、すべてのNUMERIC/DECIMAL型の列はNULLを許容します。PostgreSQLの数値型を参照してください。 |
DATE | DATE | |
TIMESTAMP | タイムスタンプ_NTZ | |
タイムスタンプ | TIMESTAMP | |
浮動小数点数、倍精度浮動小数点数 | 浮動小数点数、倍精度浮動小数点数 |
文字列として保存されるタイプ:
- 地理/ジオメトリ (PostGIS): PostGIS 拡張機能のタイプ (例:
geometry、geography)。 - ベクター (pgvector): pgvector 拡張機能の
vector型。 - 複合型/構造体型:
CREATE TYPE ... AS (field_name type, ...)で定義されたカスタム型。これらは、名前付きフィールドを持つ行のような型です(構造体と呼ばれることもあります)。 - マップ: hstore などのマップのようなキー値型 (
hstore拡張機能から)。Postgres には組み込みのマップ タイプはありません。hstoreは、列にキーと値のペアを格納する通常の方法です。
スキーマ変更の管理
Postgresで テーブルの名前を変更すると (例えば、 ALTER TABLE users RENAME TO customers )、同期が継続されます。宛先のDeltaテーブル名は変更されません。 それはlb_users_historyままです。
スキーマの変更 (列の追加、列の削除、または列のデータ型の変更)は、影響を受けるテーブルの再スナップショットをトリガーします。レイクハウス Sync は、Postgres からテーブル全体を再読み取り、宛先のDeltaテーブルに再書き込みします。
重複排除して現在の状態のミラーを作成する
完全な履歴ではなく、 Lakebaseテーブルの現在の状態 (ミラー) が必要な分析の場合は、 Databricks SQL (たとえば、 レイクハウスSQLエディター やSQLウェアハウスに接続されたノートブック) で主キーをグループ化し、 max_byを使用して各列の最新値を選択することで重複排除できます。
SELECT
id,
max_by(<column>, _sort_by) AS <column>
FROM `<catalog>.<schema>.lb_<table_name>_history`
GROUP BY id
HAVING max_by(_pg_change_type, _sort_by) IN ('insert', 'update_postimage');
idテーブルの主キー列に置き換え、保持したい非キー列ごとにmax_by(<column>, _sort_by) AS <column>射影を追加してください。このクエリはキーでグループ化し、 max_byと_sort_byを使用して各列の最新の値を選択します。HAVING句は、最新のイベントがinsertまたはupdate_postimageであったキーのみを保持し、最新のイベントが削除であったキーは除外します。
次のステップ
目的に応じて、 lb_<table_name>_history Delta テーブルを他の Databricks 機能と組み合わせて使用します。
- 高速分析: Databricks SQL ( SQLウェアハウスに接続されたクエリ エディター、ダッシュボード、ノートブック) を使用して、同期されたデータの実行集計とアドホック分析を実行します。 完全なチュートリアルについては、 「 Databricks SQLを使用してデータウェアハウジングを開始する」を参照してください。
- メダリオン ソース: Deltaテーブルをブロンズ レイヤーとして使用し、パイプラインでシルバーとゴールド レイヤーを構築します。 メダリオン レイクハウス建築とは何かをご覧ください。パターンとチュートリアルについて: LakeFlow Spark 宣言型パイプラインを使用してETL CDCとメダリオン レイヤーを備えたLakeFlowデータSparkを使用して ETL パイプラインを構築します。
- レイクハウスの全履歴: テーブル履歴の操作 (タイムトラベル) を使用して、特定の時点でのDeltaテーブルをクエリします。 Deltaテーブルから現在の状態のミラーを取得するには、上記の「重複排除による現在の状態のミラーの作成」を参照してください。