コンピュートの管理
コンピュートとは、Lakebaseプロジェクト向けにPostgresを実行する仮想化サービスのことです。各ブランチには 1 つのプライマリ (読み取り/書き込み) コンピュートがあります。 ブランチに接続してそのデータにアクセスするには、コンピュートが必要です。 コンピュートとエンドポイントの関係の概要については、 「コンピュートとエンドポイント」を参照してください。
コンピュートを理解する
コンピュートの概要
コンピュート リソースは、クエリの実行、接続の管理、データベース操作の処理に必要な処理能力とメモリを提供します。 各プロジェクトには、そのデフォルトブランチ用のプライマリ読み取り/書き込みコンピュートがあります。
ブランチ内のデータベースに接続するには、そのブランチに関連付けられたコンピュートを使用する必要があります。 コンピュートが大きいほど、同じアクティブ時間内でコンピュートが小さい場合よりも多くのコンピュート時間を消費します。
コンピュート識別子
各コンピュートには 3 つの識別子があり、[コンピュート] タブの [ID を取得] メニューからアクセスできます。
識別子 | ソース | 例 | 使用済み |
|---|---|---|---|
名前 | エンドポイント ID。安全コンピュートの場合は |
| APIリソース パス ( |
UID | システム生成 |
| 接続ホスト名 |
リソース名 | 完全なAPIパス |
| API呼び出し |
接続文字列のホスト名には、コンピュート名ではなく UID が使用されます。
コンピュートのサイジング
利用可能なコンピュート サイズ
Lakebase Postgres は、次のコンピュート サイズをサポートしています。
- オートスケール コンピュート :0.5 CUから64 CUまで(0.5、その後、1、2、3... 64のように整数で増加)
- より大規模な固定サイズ コンピュート:65 CU~112 CU
Lakebaseアプリはよく使用されるサイズの一部を表示します。Postgres API、Terraform、Databricks Asset Bundles、またはDatabricks SDK を使用して、オートスケールコンピュートには1~64、より大規模な固定サイズコンピュートには65~112の任意の整数CU値を設定できます。
コンピュートユニットには何が含まれていますか?
各コンピュート ユニット (CU) は、関連するすべての CPU およびローカルSSDリソースとともに、約 2 GB の RAM をデータベース インスタンスに割り当てます。 スケールアップすると、これらのリソースは直線的に増加します。Postgres は割り当てられたメモリを複数のコンポーネントに分散します。
- データベースキャッシュ
- ワーカーの記憶
- 固定メモリ要件を持つその他のプロセス
パフォーマンスはデータ サイズとクエリの複雑さによって異なります。スケーリングする前に、クエリをテストして最適化します。ストレージは自動的に拡張されます。
Lakebase Provisionedとオートスケール : Lakebase Provisionedでは、各コンピュート ユニットに約 16 GB の RAM が割り当てられました。 Lakebase Autoscalingでは、各 CU に 2 GB の RAM が割り当てられます。 この変更により、よりきめ細かいスケーリング オプションとコスト管理が可能になります。
コンピュート仕様
コンピュート単位 | RAM | 最大接続数 |
|---|---|---|
0.5 CU | 約1GB | 105 |
1 CU | 約2GB | 218 |
2 CU | 約4GB | 443 |
3 CU | 約6GB | 668 |
4 CU | 約8GB | 894 |
5 CU | 約10GB | 1119 |
6 CU | 約12GB | 1344 |
7 CU | 約14GB | 1570 |
8 CU | 約16GB | 1795 |
9 CU | 約18GB | 2020 |
10 CU | 約20GB | 2246 |
12 CU | 約24GB | 2696 |
14 CU | 約28GB | 3147 |
16 CU | 約32GB | 3597 |
24 CU | 約48GB | 3993 |
28 CU | 約56GB | 3993 |
32 CU | 約64GB | 3993 |
36 CU | 約72GB | 3993 |
40 CU | 約80GB | 3993 |
44 CU | 約88GB | 3993 |
48 CU | 約96GB | 3993 |
52 CU | 約104GB | 3993 |
56 CU | 約112GB | 3993 |
60 CU | 約120GB | 3993 |
64 CU | 約128GB | 3993 |
72 CU | 約144GB | 3993 |
80 CU | 約160GB | 3993 |
88 CU | 約176GB | 3993 |
96 CU | 約192GB | 3993 |
104 CU | 約208GB | 3993 |
112 CU | 約224GB | 3993 |
オートスケール コンピュートの接続制限 :オートスケールが有効になっている場合、最大接続数は、最大CUと最小CUの8倍の小さい方によって決定されます。たとえば、2~8 CU の間でオートスケールを設定した場合、接続制限は 1,795 です (8 CU の制限です)。
リードレプリカ接続制限 : リードレプリカ コンピュート接続制限は、プライマリの読み取り/書き込みコンピュート設定と同期されます。 詳細については、 「読み取りレプリカの管理」を参照してください。
一部の接続はシステムおよび管理用に予約されています。このため、 SHOW max_connectionsには、上記の表または Lakebase アプリの [編集] コンピュート ドロワーに表示されている 最大接続 数よりも高い値が表示される場合があります。 テーブルとドロワーの値は直接使用できる実際の接続数を反映していますが、 SHOW max_connectionsには予約済みの接続が含まれます。
サイズガイド
コンピュートのサイズを選択するときは、次の要素を考慮してください。
要素 | 推奨事項 |
|---|---|
クエリの複雑さ | 複雑な分析クエリは、コンピュート サイズを大きくするとメリットが得られます |
つながり | 接続数が増えるとCPUとメモリの追加が必要になります |
データ量 | データセットが大きい場合、最適なパフォーマンスを得るためにより多くのメモリが必要になる場合があります |
応答時間 | クリティカルなアプリケーションでは、一貫したパフォーマンスを得るためにより大きなコンピュートが必要になる場合があります |
最適なサイズ戦略
データ要件に基づいてコンピュート サイズを選択します。
- メモリ内の完全なデータセット : 最高のパフォーマンスを得るために、データセット全体をメモリ内に保持できるコンピュート サイズを選択します。
- メモリ内のワーキングセット : 大規模なデータセットの場合、頻繁にアクセスされるデータがメモリに収まるようにしてください。
- 接続制限 : 予想される最大同時接続数をサポートするサイズを選択します
オートスケール
Lakebase は、固定サイズ構成とオートスケール コンピュート構成の両方をサポートしています。 オートスケールは、ワークロードの需要に基づいてコンピュート リソースを動的に調整し、パフォーマンスとコストの両方を最適化します。
構成タイプ | 説明 |
|---|---|
固定サイズ (0.5~64 CU) | ワークロードの需要に合わせてスケーリングしない固定コンピュートサイズを選択してください。0.5 CU~64 CUのコンピュートで利用可能です。 |
オートスケール(0.5~64 CU) | スライダーを使用して、最小および最大のコンピュートサイズを指定します。Lakebase は、現在の負荷に基づいてこれらの境界内でスケールアップおよびスケールダウンを行います。64 CU (128 GB) までのコンピュートで利用できます。 |
より大きい固定サイズコンピュート(80~112 CU) | 最大112 CUまでの、より大きい固定サイズのコンピュートを選択してください。これらの大規模なコンピュートは固定サイズでのみ利用可能であり、オートスケーリングには対応していません。 |
オートスケールの制限: オートスケールは、最大64 CU(128 GB)のコンピュートまで対応しています。64 CUを超えるワークロードには、80、96、または112 CUのより大規模な固定サイズコンピュートをご利用いただけます。
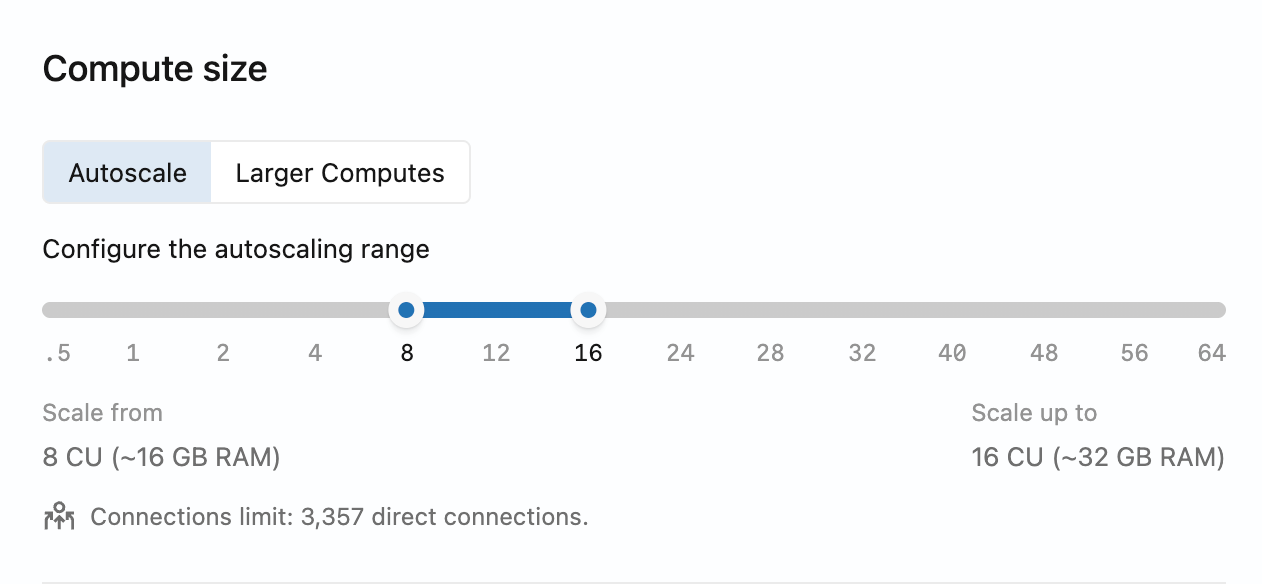
オートスケールの設定
コンピュートのオートスケールを有効または調整するには、コンピュートを編集し、スライダーを使用してコンピュートの最小サイズと最大サイズを設定します。
オートスケールの仕組みの概要については、 「オートスケール」を参照してください。
オートスケールの考慮事項
オートスケールの最適なパフォーマンスのために:
- 最小コンピュート サイズをメモリ内にワーキング セットをキャッシュできる十分な大きさに設定します。
- コンピュートがスケールアップしてデータをキャッシュするまでは、パフォーマンスの低下が発生する可能性があることを考慮してください。
- 接続制限は、最大 CU と最小 CU の 8 倍のいずれか小さい方によって決まります。
オートスケール範囲の制約 :最大コンピュートサイズと最小コンピュートサイズの差は16 CUを超えることはできません(つまり、max - min ≤ 16 CU )。たとえば、8 CU から 24 CU、または 48 CU から 64 CU の範囲でオートスケールを設定できますが、0.5 CU から 32 CU の範囲(これは 31.5 CU の範囲になります)では設定できません。Lakebase アプリのスライダーは、この制約を自動的に適用します。64 CUを超えるリソースを必要とするワークロードには、最大112 CUまでの、より大きな固定サイズのコンピュートを使用してください。
ゼロにスケール
Lakebase のスケール ツー ゼロ機能は、一定期間の非アクティブ期間後にコンピュートを自動的にアイドル状態に移行し、継続的にアクティブではないデータベースのコストを削減します。
構成 | 説明 |
|---|---|
ゼロスケールが有効 | コンピュートはコストを削減するために非アクティブな状態になると自動的に一時停止します |
ゼロスケールが無効 | 起動遅延を排除する「常にアクティブな」コンピュートを維持します。 |
「ゼロにスケーリング」の動作の仕組みの概要については、「ゼロにスケール」を参照してください。コンピュートのゼロスケールを構成するには、「ゼロスケールの構成」を参照してください。
コンピュートの作成と管理
コンピュートを見る
UIで表示
ブランチのコンピュートを表示するには、Lakebase アプリでプロジェクトの [ブランチ] ページに移動し、ブランチを選択してその コンピュート タブを表示します。
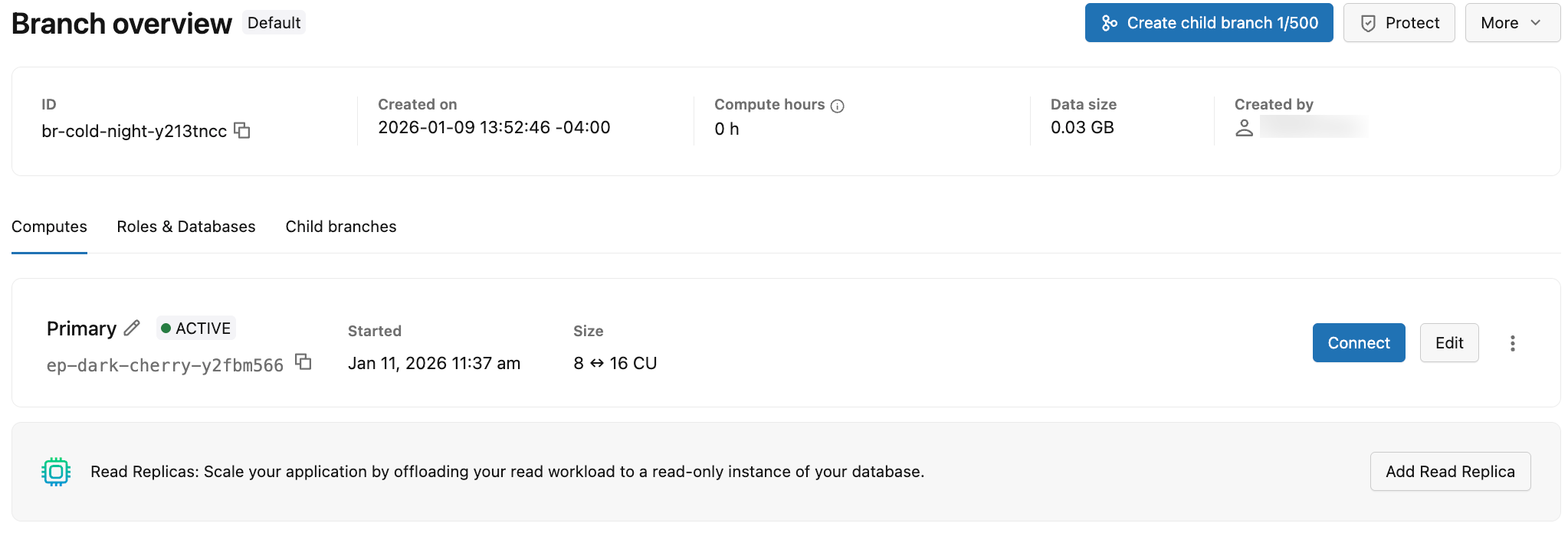
[コンピュート] タブには、ブランチに関連付けられたすべてのコンピュートに関する情報が表示されます。 [コンピュート] タブに表示される情報の概要を次の表に示します。
詳細 | 説明 |
|---|---|
クラスタータイプ | コンピュート タイプは、プライマリ (読み取り/書き込み) またはリード レプリカ(読み取り専用) のいずれかです。 ブランチには、単一のプライマリ (読み取り/書き込み) と複数のリード レプリカ (読み取り専用) コンピュートを含めることができます。 |
ステータス | 現在のステータス: アクティブまたは一時停止 (コンピュートがゼロにスケールされたために一時停止されている場合)。 コンピュートが一時停止された日時を表示します。 |
UID | システムが生成したコンピュートの一意の識別子。 |
サイズ | コンピュート単位 (CU)で表されるコンピュート サイズ。 固定サイズのコンピュートの単一の CU 値 (たとえば、8 CU) を表示します。 オートスケールが有効な場合のコンピュートの範囲 (たとえば、8 ~ 16) を表示します。 |
最終アクティブ | コンピュートが最後にアクティブだった日時。 |
コンピュートごとに、次のことができます。
- 「接続」 をクリックすると、コンピュートに関連付けられたブランチの接続詳細を含む接続ダイアログが開きます。 このダイアログには、ネイティブのPostgresパスワードロール用の 接続プーリングの切り替え オプションが含まれています。「データベースへの接続」および「接続プーリングの使用」を参照してください。
- [編集] をクリックしてコンピュート サイズ (固定またはオートスケール範囲) を変更し、スケールからゼロまでの設定を構成します。 「コンピュートの編集」を参照してください。
- 追加のオプションにアクセスするには、メニュー アイコンをクリックします。
- アクティビティの監視 : コンピュートのアクティビティとパフォーマンスのメトリクスを表示します。 「データベースを監視する」を参照してください。
- コンピュートの再起動 : 接続の問題を解決するか、構成の変更を適用するには、コンピュートを再起動します。 「コンピュートの再起動」を参照してください。
リードレプリカ コンピュートをブランチに追加するには、 [リードレプリカの追加] をクリックします。 リードレプリカは読み取り専用コンピュートであり、プライマリ コンピュートから読み取りワークロードをオフロードできるようにすることで、水平スケーリングを可能にします。 「読み取りレプリカ」および「読み取りレプリカの管理」を参照してください。
プログラムでコンピュートを取得する
Postgres APIを使用して特定のコンピュートに関する詳細を取得するには:
- Python SDK
- Java SDK
- CLI
- curl
from databricks.sdk import WorkspaceClient
w = WorkspaceClient()
# Get endpoint details
endpoint = w.postgres.get_endpoint(
name="projects/my-project/branches/production/endpoints/my-compute"
)
print(f"Endpoint: {endpoint.name}")
print(f"Type: {endpoint.status.endpoint_type}")
print(f"State: {endpoint.status.current_state}")
print(f"Host: {endpoint.status.hosts.host}")
print(f"Min CU: {endpoint.status.autoscaling_limit_min_cu}")
print(f"Max CU: {endpoint.status.autoscaling_limit_max_cu}")
SDK では、 endpoint.status.hostではなくendpoint.status.hosts.host経由でホストにアクセスします。
import com.databricks.sdk.WorkspaceClient;
import com.databricks.sdk.service.postgres.Endpoint;
WorkspaceClient w = new WorkspaceClient();
// Get endpoint details
Endpoint endpoint = w.postgres().getEndpoint(
"projects/my-project/branches/production/endpoints/my-compute"
);
System.out.println("Endpoint: " + endpoint.getName());
System.out.println("Type: " + endpoint.getStatus().getEndpointType());
System.out.println("State: " + endpoint.getStatus().getCurrentState());
System.out.println("Host: " + endpoint.getStatus().getHosts().getHost());
System.out.println("Min CU: " + endpoint.getStatus().getAutoscalingLimitMinCu());
System.out.println("Max CU: " + endpoint.getStatus().getAutoscalingLimitMaxCu());
# Get endpoint details
databricks postgres get-endpoint projects/my-project/branches/production/endpoints/my-compute --output json | jq
curl "$WORKSPACE/api/2.0/postgres/projects/my-project/branches/production/endpoints/my-compute" \
-H "Authorization: Bearer ${DATABRICKS_TOKEN}" | jq
プログラムによるリストコンピュート
Postgres APIを使用してブランチのすべてのコンピュート レプリカとリード レプリカを一覧表示するには、次のようにします。
- Python SDK
- Java SDK
- CLI
- curl
from databricks.sdk import WorkspaceClient
w = WorkspaceClient()
# List all endpoints for a branch
endpoints = list(w.postgres.list_endpoints(
parent="projects/my-project/branches/production"
))
for endpoint in endpoints:
print(f"Endpoint: {endpoint.name}")
print(f" Type: {endpoint.status.endpoint_type}")
print(f" State: {endpoint.status.current_state}")
print(f" Host: {endpoint.status.hosts.host}")
print(f" CU Range: {endpoint.status.autoscaling_limit_min_cu}-{endpoint.status.autoscaling_limit_max_cu}")
print()
SDK では、 endpoint.status.hostではなくendpoint.status.hosts.host経由でホストにアクセスします。
import com.databricks.sdk.WorkspaceClient;
import com.databricks.sdk.service.postgres.*;
WorkspaceClient w = new WorkspaceClient();
// List all endpoints for a branch
for (Endpoint endpoint : w.postgres().listEndpoints("projects/my-project/branches/production")) {
System.out.println("Endpoint: " + endpoint.getName());
System.out.println(" Type: " + endpoint.getStatus().getEndpointType());
System.out.println(" State: " + endpoint.getStatus().getCurrentState());
System.out.println(" Host: " + endpoint.getStatus().getHosts().getHost());
System.out.println(" CU Range: " + endpoint.getStatus().getAutoscalingLimitMinCu() +
"-" + endpoint.getStatus().getAutoscalingLimitMaxCu());
System.out.println();
}
# List endpoints for a branch
databricks postgres list-endpoints projects/my-project/branches/production --output json | jq
curl "$WORKSPACE/api/2.0/postgres/projects/my-project/branches/production/endpoints" \
-H "Authorization: Bearer ${DATABRICKS_TOKEN}" | jq
一般的なブランチ構成:
- 1 エンドポイント: プライマリ読み取り/書き込みコンピュートのみ
- 2 つ以上のエンドポイント: プライマリ コンピュートと 1 つ以上のリードレプリカ
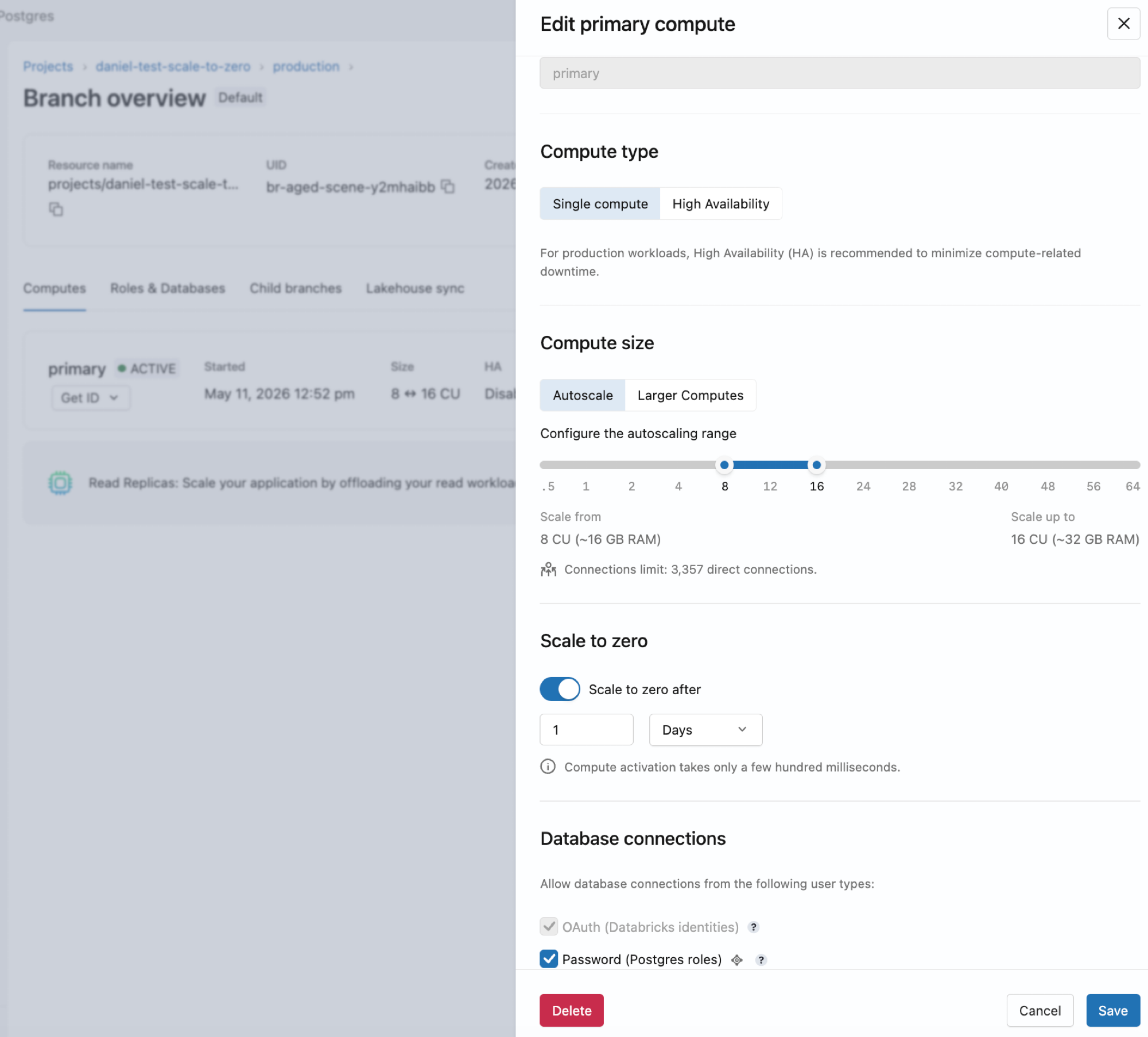
コンピュートを編集する
コンピュートを編集して、そのサイズ、オートスケール設定、またはゼロスケール設定を変更できます。 コンピュート名は読み取り専用であり、名前を変更することはできません。
コンピュートを編集するには:
- UI
- Python SDK
- Java SDK
- CLI
- curl
- Lakebaseアプリで、ブランチの コンピュート タブに移動してください。
- コンピュートの [編集] を クリックし、設定を調整して、 [保存] をクリックします。
from databricks.sdk import WorkspaceClient
from databricks.sdk.service.postgres import Endpoint, EndpointSpec, EndpointType, FieldMask
w = WorkspaceClient()
# Update a single field (max CU)
endpoint_spec = EndpointSpec(endpoint_type=EndpointType.ENDPOINT_TYPE_READ_WRITE, autoscaling_limit_max_cu=6.0)
endpoint = Endpoint(
name="projects/my-project/branches/production/endpoints/my-compute",
spec=endpoint_spec
)
result = w.postgres.update_endpoint(
name="projects/my-project/branches/production/endpoints/my-compute",
endpoint=endpoint,
update_mask=FieldMask(field_mask=["spec.autoscaling_limit_max_cu"])
).wait()
print(f"Updated max CU: {result.status.autoscaling_limit_max_cu}")
複数のフィールドを更新するには、それらを仕様と更新マスクの両方に含めます。
# Update multiple fields (min and max CU)
endpoint_spec = EndpointSpec(
endpoint_type=EndpointType.ENDPOINT_TYPE_READ_WRITE,
autoscaling_limit_min_cu=1.0,
autoscaling_limit_max_cu=8.0
)
endpoint = Endpoint(
name="projects/my-project/branches/production/endpoints/my-compute",
spec=endpoint_spec
)
result = w.postgres.update_endpoint(
name="projects/my-project/branches/production/endpoints/my-compute",
endpoint=endpoint,
update_mask=FieldMask(field_mask=[
"spec.autoscaling_limit_min_cu",
"spec.autoscaling_limit_max_cu"
])
).wait()
print(f"Updated min CU: {result.status.autoscaling_limit_min_cu}")
print(f"Updated max CU: {result.status.autoscaling_limit_max_cu}")
import com.databricks.sdk.WorkspaceClient;
import com.databricks.sdk.service.postgres.*;
import com.google.protobuf.FieldMask;
WorkspaceClient w = new WorkspaceClient();
// Update a single field (max CU)
EndpointSpec endpointSpec = new EndpointSpec()
.setAutoscalingLimitMaxCu(6.0);
FieldMask updateMask = FieldMask.newBuilder()
.addPaths("spec.autoscaling_limit_max_cu")
.build();
w.postgres().updateEndpoint(
new UpdateEndpointRequest()
.setName("projects/my-project/branches/production/endpoints/my-compute")
.setEndpoint(new Endpoint().setSpec(endpointSpec))
.setUpdateMask(updateMask)
);
System.out.println("Update initiated");
複数のフィールドを更新するには、それらを仕様と更新マスクの両方に含めます。
// Update multiple fields (min and max CU)
EndpointSpec endpointSpec = new EndpointSpec()
.setAutoscalingLimitMinCu(1.0)
.setAutoscalingLimitMaxCu(8.0);
FieldMask updateMask = FieldMask.newBuilder()
.addPaths("spec.autoscaling_limit_min_cu")
.addPaths("spec.autoscaling_limit_max_cu")
.build();
w.postgres().updateEndpoint(
new UpdateEndpointRequest()
.setName("projects/my-project/branches/production/endpoints/my-compute")
.setEndpoint(new Endpoint().setSpec(endpointSpec))
.setUpdateMask(updateMask)
);
System.out.println("Update initiated");
# Update a single field (max CU)
databricks postgres update-endpoint projects/my-project/branches/production/endpoints/my-compute spec.autoscaling_limit_max_cu \
--json '{
"spec": {
"autoscaling_limit_max_cu": 6.0
}
}'
# Update multiple fields (min and max CU)
databricks postgres update-endpoint projects/my-project/branches/production/endpoints/my-compute "spec.autoscaling_limit_min_cu,spec.autoscaling_limit_max_cu" \
--json '{
"spec": {
"autoscaling_limit_min_cu": 1.0,
"autoscaling_limit_max_cu": 8.0
}
}'
# Update a single field (max CU)
curl -X PATCH "$WORKSPACE/api/2.0/postgres/projects/my-project/branches/production/endpoints/my-compute?update_mask=spec.autoscaling_limit_max_cu" \
-H "Authorization: Bearer ${DATABRICKS_TOKEN}" \
-H "Content-Type: application/json" \
-d '{
"name": "projects/my-project/branches/production/endpoints/my-compute",
"spec": {
"autoscaling_limit_max_cu": 6.0
}
}' | jq
# Update multiple fields (min and max CU)
curl -X PATCH "$WORKSPACE/api/2.0/postgres/projects/my-project/branches/production/endpoints/my-compute?update_mask=spec.autoscaling_limit_min_cu,spec.autoscaling_limit_max_cu" \
-H "Authorization: Bearer ${DATABRICKS_TOKEN}" \
-H "Content-Type: application/json" \
-d '{
"name": "projects/my-project/branches/production/endpoints/my-compute",
"spec": {
"autoscaling_limit_min_cu": 1.0,
"autoscaling_limit_max_cu": 8.0
}
}' | jq
コンピュート設定への変更はすぐに反映され、再起動中に接続が短時間中断される場合があります。
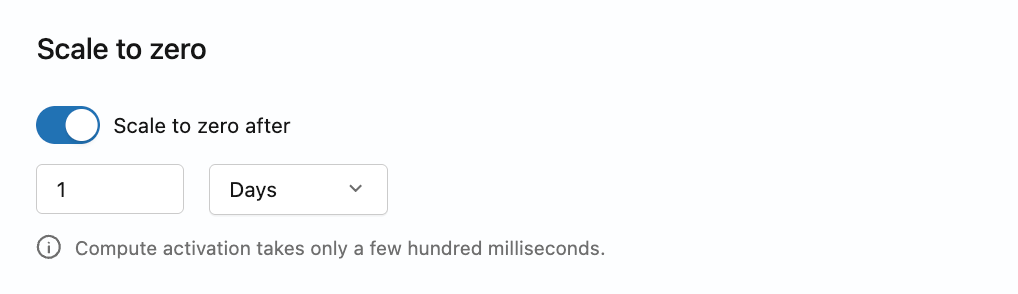
ゼロにスケーリングを構成
ゼロにスケーリングを設定するには、更新マスクにspec.suspensionを含めます。suspend_timeout_duration (60秒~604800秒) を設定して非アクティブタイムアウトを定義するか、no_suspension: true を設定して無効にしてください。両方を設定しないでください。設定no_suspension: falseは無効であり、エラーを返します。デフォルトでは、productionブランチではゼロへのスケールが有効になっており、タイムアウトは24時間です。
- UI
- Python SDK
- Java SDK
- CLI
- curl
- Lakebaseアプリで、ブランチの コンピュート タブに移動してください。
- コンピュートの**編集**をクリックして、スケール・トゥ・ゼロ設定を有効または無効にします。有効にした場合、非アクティブタイムアウトを60秒から7日間の間で設定してください。
- 保存 をクリックします。
from databricks.sdk import WorkspaceClient
from databricks.sdk.service.postgres import Endpoint, EndpointSpec, EndpointType, FieldMask
from google.protobuf.duration_pb2 import Duration
w = WorkspaceClient()
endpoint_name = "projects/my-project/branches/production/endpoints/my-compute"
# Disable scale to zero (compute stays active indefinitely)
endpoint_spec = EndpointSpec(
endpoint_type=EndpointType.ENDPOINT_TYPE_READ_WRITE,
no_suspension=True
)
w.postgres.update_endpoint(
name=endpoint_name,
endpoint=Endpoint(name=endpoint_name, spec=endpoint_spec),
update_mask=FieldMask(field_mask=["spec.suspension"])
).wait()
# Enable scale to zero with a 5-minute inactivity timeout (60s–604800s)
endpoint_spec = EndpointSpec(
endpoint_type=EndpointType.ENDPOINT_TYPE_READ_WRITE,
suspend_timeout_duration=Duration(seconds=300)
)
w.postgres.update_endpoint(
name=endpoint_name,
endpoint=Endpoint(name=endpoint_name, spec=endpoint_spec),
update_mask=FieldMask(field_mask=["spec.suspension"])
).wait()
import com.databricks.sdk.WorkspaceClient;
import com.databricks.sdk.service.postgres.*;
import com.google.protobuf.Duration;
import com.google.protobuf.FieldMask;
WorkspaceClient w = new WorkspaceClient();
String endpointName = "projects/my-project/branches/production/endpoints/my-compute";
FieldMask updateMask = FieldMask.newBuilder()
.addPaths("spec.suspension")
.build();
// Disable scale to zero (compute stays active indefinitely)
EndpointSpec noSuspensionSpec = new EndpointSpec()
.setNoSuspension(true);
w.postgres().updateEndpoint(
new UpdateEndpointRequest()
.setName(endpointName)
.setEndpoint(new Endpoint().setSpec(noSuspensionSpec))
.setUpdateMask(updateMask)
);
// Enable scale to zero with a 5-minute inactivity timeout (60s–604800s)
EndpointSpec timeoutSpec = new EndpointSpec()
.setSuspendTimeoutDuration(
Duration.newBuilder().setSeconds(300).build()
);
w.postgres().updateEndpoint(
new UpdateEndpointRequest()
.setName(endpointName)
.setEndpoint(new Endpoint().setSpec(timeoutSpec))
.setUpdateMask(updateMask)
);
# Disable scale to zero (compute stays active indefinitely)
databricks postgres update-endpoint \
projects/my-project/branches/production/endpoints/my-compute \
spec.suspension \
--json '{
"spec": {
"no_suspension": true
}
}'
# Enable scale to zero with a 5-minute inactivity timeout (60s–604800s)
databricks postgres update-endpoint \
projects/my-project/branches/production/endpoints/my-compute \
spec.suspension \
--json '{
"spec": {
"suspend_timeout_duration": "300s"
}
}'
# Disable scale to zero (compute stays active indefinitely)
curl -X PATCH "$WORKSPACE/api/2.0/postgres/projects/my-project/branches/production/endpoints/my-compute?update_mask=spec.suspension" \
-H "Authorization: Bearer ${DATABRICKS_TOKEN}" \
-H "Content-Type: application/json" \
-d '{
"name": "projects/my-project/branches/production/endpoints/my-compute",
"spec": {
"no_suspension": true
}
}' | jq
# Enable scale to zero with a 5-minute inactivity timeout (60s–604800s)
curl -X PATCH "$WORKSPACE/api/2.0/postgres/projects/my-project/branches/production/endpoints/my-compute?update_mask=spec.suspension" \
-H "Authorization: Bearer ${DATABRICKS_TOKEN}" \
-H "Content-Type: application/json" \
-d '{
"name": "projects/my-project/branches/production/endpoints/my-compute",
"spec": {
"suspend_timeout_duration": "300s"
}
}' | jq
コンピュートの無効化または有効化
コンピュートを無効にすると、停止し、すべての新しい接続がブロックされます。ゼロへのスケールとは異なり、無効化されたコンピュートは接続試行によって、またはLakebaseアプリから起動することはできません。再度有効にするには、APIを使用してください。
- Python SDK
- CLI
- curl
from databricks.sdk import WorkspaceClient
from databricks.sdk.service.postgres import Endpoint, EndpointSpec, EndpointType, FieldMask
w = WorkspaceClient()
endpoint_name = "projects/my-project/branches/production/endpoints/my-compute"
# Disable a compute (blocks all connections)
endpoint_spec = EndpointSpec(
endpoint_type=EndpointType.ENDPOINT_TYPE_READ_WRITE,
disabled=True
)
w.postgres.update_endpoint(
name=endpoint_name,
endpoint=Endpoint(name=endpoint_name, spec=endpoint_spec),
update_mask=FieldMask(field_mask=["spec.disabled"])
).wait()
# Re-enable a compute
endpoint_spec = EndpointSpec(
endpoint_type=EndpointType.ENDPOINT_TYPE_READ_WRITE,
disabled=False
)
w.postgres.update_endpoint(
name=endpoint_name,
endpoint=Endpoint(name=endpoint_name, spec=endpoint_spec),
update_mask=FieldMask(field_mask=["spec.disabled"])
).wait()
コンピュートが現在無効になっているか確認するには、エンドポイントのステータスの値を読み取ります。spec.disabledに値を設定しますが、status.disabledから読み取ります:
endpoint = w.postgres.get_endpoint(
name="projects/my-project/branches/production/endpoints/my-compute"
)
print(endpoint.status.disabled) # True = disabled, False or None = enabled
# Disable a compute (blocks all connections)
databricks postgres update-endpoint \
projects/my-project/branches/production/endpoints/my-compute \
spec.disabled \
--json '{
"spec": {
"disabled": true
}
}'
# Re-enable a compute
databricks postgres update-endpoint \
projects/my-project/branches/production/endpoints/my-compute \
spec.disabled \
--json '{
"spec": {
"disabled": false
}
}'
コンピュートが現在無効になっているかを確認するには、エンドポイントからstatus.disabledを読み取ります。
databricks postgres get-endpoint projects/my-project/branches/production/endpoints/my-compute --output json | jq '.status.disabled'
# Disable a compute (blocks all connections)
curl -X PATCH "$WORKSPACE/api/2.0/postgres/projects/my-project/branches/production/endpoints/my-compute?update_mask=spec.disabled" \
-H "Authorization: Bearer ${DATABRICKS_TOKEN}" \
-H "Content-Type: application/json" \
-d '{
"name": "projects/my-project/branches/production/endpoints/my-compute",
"spec": {
"disabled": true
}
}' | jq
# Re-enable a compute
curl -X PATCH "$WORKSPACE/api/2.0/postgres/projects/my-project/branches/production/endpoints/my-compute?update_mask=spec.disabled" \
-H "Authorization: Bearer ${DATABRICKS_TOKEN}" \
-H "Content-Type: application/json" \
-d '{
"name": "projects/my-project/branches/production/endpoints/my-compute",
"spec": {
"disabled": false
}
}' | jq
コンピュートが現在無効になっているかを確認するには、エンドポイントからstatus.disabledを読み取ります。
curl "$WORKSPACE/api/2.0/postgres/projects/my-project/branches/production/endpoints/my-compute" \
-H "Authorization: Bearer ${DATABRICKS_TOKEN}" | jq '.status.disabled'
コンピュートを再度有効にした後、コンピュートの再起動が完了するまで、新しい接続試行が失敗する場合があります。
コンピュートを再起動する
コンピュートを再起動して、アップデートを適用したり、パフォーマンスの問題を解決したり、構成の変更を取得したりします。
コンピュートを再起動するには:
- Lakebaseアプリで、ブランチの コンピュート タブに移動してください。
- クリック
 コンピュートのメニューから 「再起動」 を選択し、動作を確認します。
コンピュートのメニューから 「再起動」 を選択し、動作を確認します。
コンピュートを再起動すると、アクティブな接続が中断されます。 長時間の中断を避けるために、アプリケーションが自動的に再接続するように構成します。