プロジェクトの管理
プロジェクトは、ブランチ、コンピュート、データベース、ロールを含む Lakebase リソースの最上位のコンテナーです。 このページでは、プロジェクトを作成し、その構造を理解し、設定を構成し、ライフサイクルを管理する方法について説明します。
Lakebase を初めて使用する場合は、 「はじめに」から始めて最初のプロジェクトを作成してください。
プロジェクトを理解する
プロジェクト構造
Lakebase プロジェクト構造を理解すると、リソースを効果的に整理および管理できるようになります。プロジェクトは、データベース、ブランチ、コンピュート、および関連リソースの最上位のコンテナです。 各プロジェクトには、コンピュート安全、復元ウィンドウ、およびプロジェクト内のすべてのブランチに適用される更新の設定が含まれています。
最上位レベルでは、プロジェクトには 1 つ以上のブランチが含まれます。プロジェクト内では、開発、テスト、ステージング、本番運用などのさまざまな環境のブランチを作成できます。 各ブランチには、独自のコンピュート、ロール、データベースが含まれています。
Project
└── Branches (main, development, staging, etc.)
├── Computes (R/W compute)
├── Roles (Postgres roles)
└── Databases (Postgres databases)
ブランチ
データはブランチに存在します。各 Lakebase プロジェクトは、削除できないproductionというルート ブランチを使用して作成されます。追加のブランチを作成し、別のブランチをデフォルト ブランチとして指定することはできますが、ルート ブランチを削除することはできません。
プロジェクト内の任意のブランチから子ブランチを作成できます。子ブランチを作成すると、作成時に親ブランチからすべてのデータベース、ロール、およびデータが継承されます。親ブランチでの後続の変更は子ブランチに自動的には伝播されないため、分離された開発、テスト、または実験が可能になります。
各ブランチには複数のデータベースとロールを含めることができます。詳細:ブランチの管理
コンピュート
コンピュートは、Postgres を実行するための vCPU とメモリを含む仮想化コンピューティング リソースです。 プロジェクトを作成すると、プロジェクトのデフォルトのブランチに対してプライマリ R/W (読み取り/書き込み) コンピュートが作成されます。 各ブランチには単一のプライマリ R/W コンピュートがあります。 ブランチ上にあるデータベースに接続するには、ブランチに関連付けられた R/W コンピュートを通じて接続する必要があります。
プライマリ R/W コンピュートに加えて、1 つ以上のリード レプリカ (読み取り専用) コンピュートを任意のブランチに追加できます。 リードレプリカを使用すると、水平読み取りスケーリング、アナリティクスとレポート クエリ、ユーザーまたはアプリケーションの読み取り専用アクセスなどのユースケースのために、プライマリ コンピュートから読み取り専用ワークロードをオフロードできます。 詳細:コンピュートの管理、リードレプリカ
役割
ロールは Postgres ロールです。データベースを作成してアクセスするには、ロールが必要です。ロールはブランチに属します。プロジェクトを作成すると、デフォルトdatabricks_postgresデータベースの所有者であるDatabricks ID (たとえば、 user@databricks.com ) に対して Postgres ロールが自動的に作成されます。 Lakebase UI で作成されたロールはすべてdatabricks_superuser権限で作成されます。ブランチごとに 500 ロールの制限があります。詳細:役割の管理
データベース
データベースは、スキーマ、テーブル、ビュー、関数、インデックスなどの SQL オブジェクトのコンテナーです。Lakebase では、データベースはブランチに属します。プロジェクトのデフォルト ブランチは、 databricks_postgresという名前のデータベースを使用して作成されます。ブランチごとに 500 個のデータベースの制限があります。詳細:データベースの管理
スキーマ
Lakebase 内のすべてのデータベースはpublicスキーマを使用して作成されます。これは、標準の Postgres インスタンスのデフォルトの動作です。デフォルトでは、SQL オブジェクトはpublicスキーマに作成されます。
プロジェクトの制限
Lakebase Postgres はプロジェクトに対して次の制限を適用します。
リソース | 上限 |
|---|---|
同時にアクティブなコンピュートの最大数 | 20 |
ブランチごとの最大読み取りレプリカ数 | 6 |
プロジェクトあたりのブランチの最大数 | 500 |
ブランチあたりの Postgres ロールの最大数 | 500 |
ブランチあたりの Postgres データベースの最大数 | 500 |
データベースのストレージ容量(支店ごと) | 16TB |
ワークスペースあたりのプロジェクトの最大数 | 1000 |
保護されたブランチの最大数 | 1 |
ルートブランチの最大数 | 3 |
アーカイブされていないブランチの最大数 | 10 |
手動スナップショットの最大数 | 10 |
最大履歴保存期間 | 30日 |
ゼロ時間までの最小スケール | 60秒 |
最大スケールゼロ時間 | 7日 |
同時アクティブコンピュート制限
同時にアクティブなコンピュートの制限は、リソースの枯渇を防ぐために同時に実行できるコンピュートの数を制限します。 この制限により、多くのコンピュート エンドポイントを一度に開始するなど、偶発的なリソース サージが防止されます。 安全な制限は、プロジェクトごとに同時にアクティブなコンピュート 20 です。
重要: デフォルト ブランチはこの制限から除外されるため、常に利用可能になります。
制限を超えると、制限を超えた追加のコンピュートは停止状態となり、接続しようとするとエラーが表示されます。 これを解決するには:
- 他のアクティブなコンピュートを一時停止して、再試行してください。
- このエラーが頻繁に発生する場合は、Databricks サポートに連絡して制限の引き上げをリクエストしてください。
ゼロへのスケールを有効にしたコンピュートは、非アクティブな期間が続くと自動的にサスペンドされ、同時アクティブなコンピュートの制限内に留まることができます。
データベースストレージクォータ
各ブランチには16 TBのデータベースストレージクォータがあります。これはアーキテクチャ上の制限ではなく運用上のクォータです。データはプロビジョニングされたローカルディスクではなく、クラウドオブジェクトストレージに存在するためです。
データベースが割り当て容量に達すると、書き込みパフォーマンスが低下しますが、データを削除または破棄することで領域を解放できます。より大きな割り当て量が必要な場合は、Databricksサポートにお問い合わせください。
クォータの対象となるのは、実際に存在するデータ(Postgresによって報告されるテーブルとインデックス)のみです。特定時点への復元のために保持される履歴はそうではありません。
利用可能な地域
サポートされている地域:
us-east-1(米国東部 - バージニア州北部)us-east-2(米国東部 - オハイオ州)us-west-2(米国西部 - オレゴン州)ca-central-1(カナダ - 中部)sa-east-1(南米 - サンパウロ)eu-central-1(ヨーロッパ - フランクフルト)eu-west-1(ヨーロッパ - アイルランド)eu-west-2(ヨーロッパ - ロンドン)ap-south-1(アジア太平洋 - ムンバイ)ap-southeast-1(アジア太平洋 - シンガポール)ap-southeast-2(アジア太平洋 - シドニー)ap-northeast-1(アジア太平洋 - 東京)
Lakebase プロジェクトは、Databricks ワークスペース リージョンに作成されます。
Postgresのバージョンサポート
Lakebase Postgres オートスケールは、Postgres 16、Postgres 17、および Postgres 18 をサポートしています。Postgres 17 がデフォルトバージョンです。Postgres 18 を使用するには、新しいプロジェクトを作成する際にこれを選択します。
プロジェクトの作成と管理
プロジェクトを作成する
Lakebase Postgres で複数のプロジェクトを作成して、アプリケーションまたは顧客を完全に分離し、データとリソースを明確に分離することができます。
プロジェクトを作成するには:
- UI
- Python SDK
- Java SDK
- CLI
- curl
- 右上隅のアプリスイッチャーをクリックして、Lakebase アプリを開きます。
- [新しいプロジェクト] をクリックします。
- プロジェクト設定を構成します。
- 表示名 :プロジェクトの名前を入力してください。スペースや特殊文字を含む、あらゆる文字を使用できます。一般的な命名パターンとしては、アプリケーション名(例:
My Analytics App)や、プロジェクトがサービスを提供する顧客またはテナント名(例:Acme Corp DB)にちなんで命名する方法があります。リソース名は表示名から自動的に生成され、APIおよびSDK呼び出しにおいてプロジェクトを識別するために使用されます。ダイアログには結果として生成されるリソース名(例:projects/my-analytics-app)が表示されるので、プロジェクトを作成する前に確認できます。 - Postgres バージョン : 使用する Postgres バージョンを選択します。
- サーバレス使用ポリシー (オプション): サーバレス コンピュート コストを特定のポリシーに帰属させるには、サーバレス使用ポリシーを選択します。 サーバーレス使用ポリシーを参照してください。
- 表示名 :プロジェクトの名前を入力してください。スペースや特殊文字を含む、あらゆる文字を使用できます。一般的な命名パターンとしては、アプリケーション名(例:
プロジェクトの作成 ダイアログには、プロジェクトの構成オプションが表示されます。
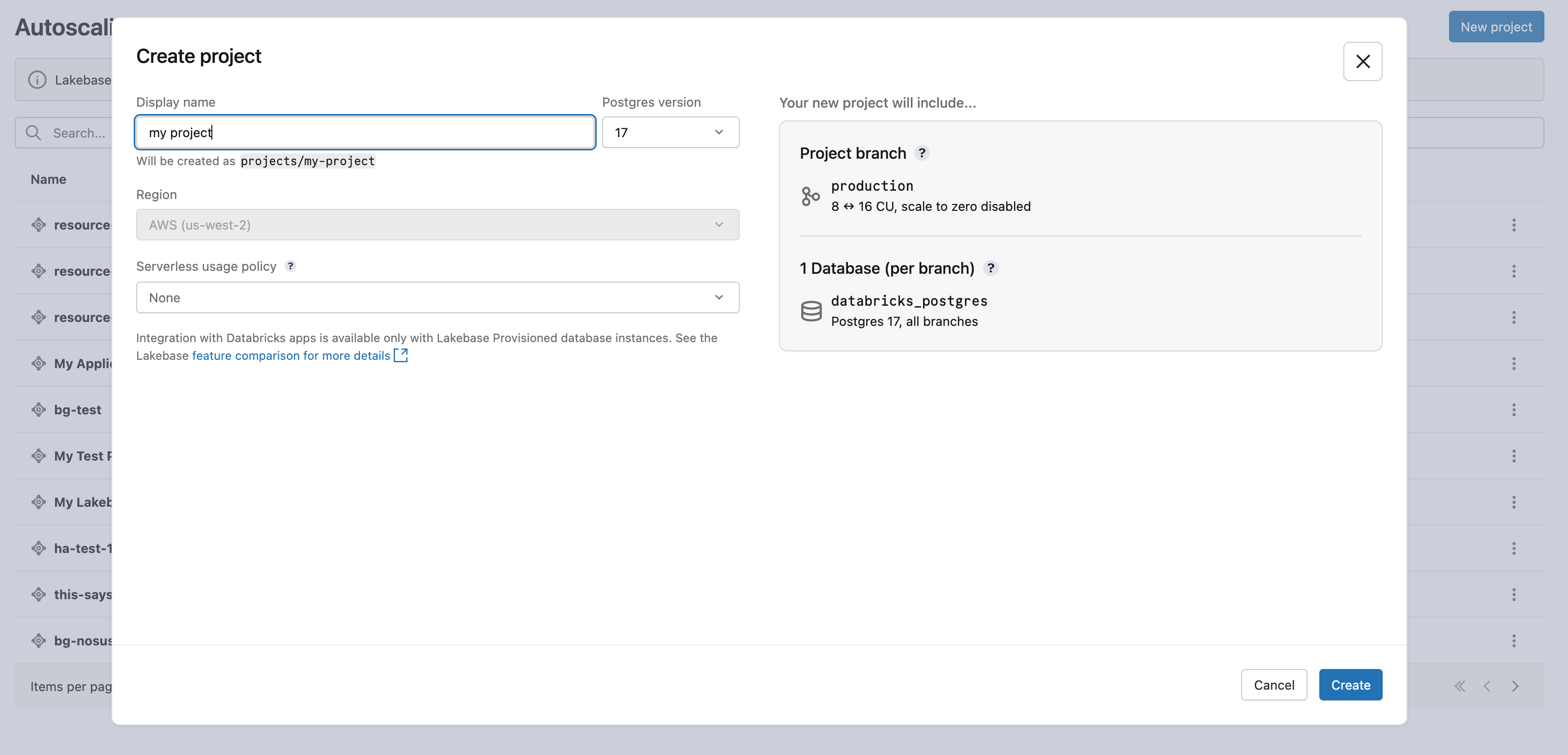
Lakebase プロジェクトの リージョン は Databricks ワークスペース リージョンに設定されており、変更することはできません。
from databricks.sdk import WorkspaceClient
from databricks.sdk.service.postgres import Project, ProjectSpec
# Initialize the Workspace client
w = WorkspaceClient()
# Create a project with a custom project ID
operation = w.postgres.create_project(
project=Project(
spec=ProjectSpec(
display_name="My Application",
pg_version=17,
budget_policy_id="<policy-id>"
)
),
project_id="my-app"
)
# Wait for operation to complete
result = operation.wait()
print(f"Created project: {result.name}")
print(f"Display name: {result.status.display_name}")
print(f"Postgres version: {result.status.pg_version}")
import com.databricks.sdk.WorkspaceClient;
import com.databricks.sdk.service.postgres.*;
// Initialize the Workspace client
WorkspaceClient w = new WorkspaceClient();
// Create a project with a custom project ID
CreateProjectOperation operation = w.postgres().createProject(
new CreateProjectRequest()
.setProjectId("my-app")
.setProject(new Project()
.setSpec(new ProjectSpec()
.setDisplayName("My Application")
.setPgVersion(17L)))
);
// Wait for operation to complete
Project result = operation.waitForCompletion();
System.out.println("Created project: " + result.getName());
System.out.println("Display name: " + result.getStatus().getDisplayName());
System.out.println("Postgres version: " + result.getStatus().getPgVersion());
# Create a project with a custom project ID
databricks postgres create-project my-app \
--json '{
"spec": {
"display_name": "My Application",
"pg_version": 17,
"budget_policy_id": "<policy-id>"
}
}'
カスタム プロジェクト ID を使用してプロジェクトを作成します。project_idはクエリとして指定され、プロジェクトのリソース名の一部になります (例: projects/my-app )。
curl -X POST "$WORKSPACE/api/2.0/postgres/projects?project_id=my-app" \
-H "Authorization: Bearer ${DATABRICKS_TOKEN}" \
-H "Content-Type: application/json" \
-d '{
"spec": {
"display_name": "My Application",
"pg_version": 17,
"budget_policy_id": "<policy-id>"
}
}' | jq
これは長時間実行される操作です。応答には、ステータスを確認するために使用できる操作名が含まれます。通常、操作は数秒以内に完了します。
project_idは必須です。
最近削除されたプロジェクトと同じIDでプロジェクトを作成する場合、削除されたプロジェクトのIDは7日間予約されることに注意してください。IDをすぐに再利用するには、まず元のプロジェクトを完全に削除してください。
新しいプロジェクトには、デフォルトで次のリソースが含まれます。
-
単一の
productionブランチ(デフォルトのブランチ) -
単一のプライマリ読み取り/書き込みコンピュートは、次の確実な設定でブランチに関連付けられています。
プロジェクトを作成すると、24 時間の非アクティブ タイムアウトを備えたスケール トゥ ゼロが自動的に有効になっているコンピュートを使用して
productionブランチが作成されます。 必要に応じて、このコンピュートのタイムアウトを調整したり、ゼロへのスケールをオフにしたりできます。 -
Postgres データベース (名前:
databricks_postgres) -
Databricks ID の Postgres ロール (例:
user@databricks.com)
既存のプロジェクトのコンピュート設定を変更するには、 プロジェクト設定を構成するを参照してください。 新しいプロジェクトのデフォルトコンピュート設定を変更するには、 プロジェクト設定を構成するの コンピュートのデフォルト を参照してください。
プロジェクトの詳細を取得する
特定のプロジェクトの詳細を取得します。
- UI
- Python SDK
- Java SDK
- CLI
- curl
- 右上隅のアプリスイッチャーをクリックして、Lakebase アプリを開きます。
- プロジェクト リストからプロジェクトを選択して、詳細を表示します。
from databricks.sdk import WorkspaceClient
w = WorkspaceClient()
# Get project details
project = w.postgres.get_project(name="projects/my-project")
print(f"Project: {project.name}")
print(f"Display name: {project.status.display_name}")
print(f"Postgres version: {project.status.pg_version}")
import com.databricks.sdk.WorkspaceClient;
import com.databricks.sdk.service.postgres.Project;
WorkspaceClient w = new WorkspaceClient();
// Get project details
Project project = w.postgres().getProject("projects/my-project");
System.out.println("Project: " + project.getName());
System.out.println("Display name: " + project.getStatus().getDisplayName());
System.out.println("Postgres version: " + project.getStatus().getPgVersion());
# Get project details
databricks postgres get-project projects/my-project
curl -X GET "$WORKSPACE/api/2.0/postgres/projects/my-project" \
-H "Authorization: Bearer ${DATABRICKS_TOKEN}" | jq
応答には以下が含まれます:
name: リソース名 (projects/my-project)statusプロジェクトの設定と現在の状態(表示名、pg_versionなど)
注: GET 操作の場合、 specフィールドは入力されません。すべてのリソース プロパティはstatusフィールドに返されます。
プロジェクトの一覧
ワークスペース内のすべてのプロジェクトを一覧表示します。
- UI
- Python SDK
- Java SDK
- CLI
- curl
- 右上隅のアプリスイッチャーをクリックして、Lakebase アプリを開きます。
- プロジェクト リストには、アクセスできるすべてのプロジェクトが表示されます。
from databricks.sdk import WorkspaceClient
w = WorkspaceClient()
# List all projects
projects = w.postgres.list_projects()
for project in projects:
print(f"Project: {project.name}")
print(f" Display name: {project.status.display_name}")
print(f" Postgres version: {project.status.pg_version}")
import com.databricks.sdk.WorkspaceClient;
import com.databricks.sdk.service.postgres.*;
WorkspaceClient w = new WorkspaceClient();
// List all projects
for (Project project : w.postgres().listProjects(new ListProjectsRequest())) {
System.out.println("Project: " + project.getName());
System.out.println(" Display name: " + project.getStatus().getDisplayName());
System.out.println(" Postgres version: " + project.getStatus().getPgVersion());
}
# List all projects
databricks postgres list-projects
curl -X GET "$WORKSPACE/api/2.0/postgres/projects" \
-H "Authorization: Bearer ${DATABRICKS_TOKEN}" | jq
応答形式:
{
"projects": [
{
"name": "projects/my-project",
"status": {
"display_name": "My Project",
"pg_version": 17
}
}
]
}
プロジェクト設定を構成する
プロジェクトを作成した後、プロジェクトダッシュボードの 「設定」 に移動してさまざまな設定を変更できます。
一般設定
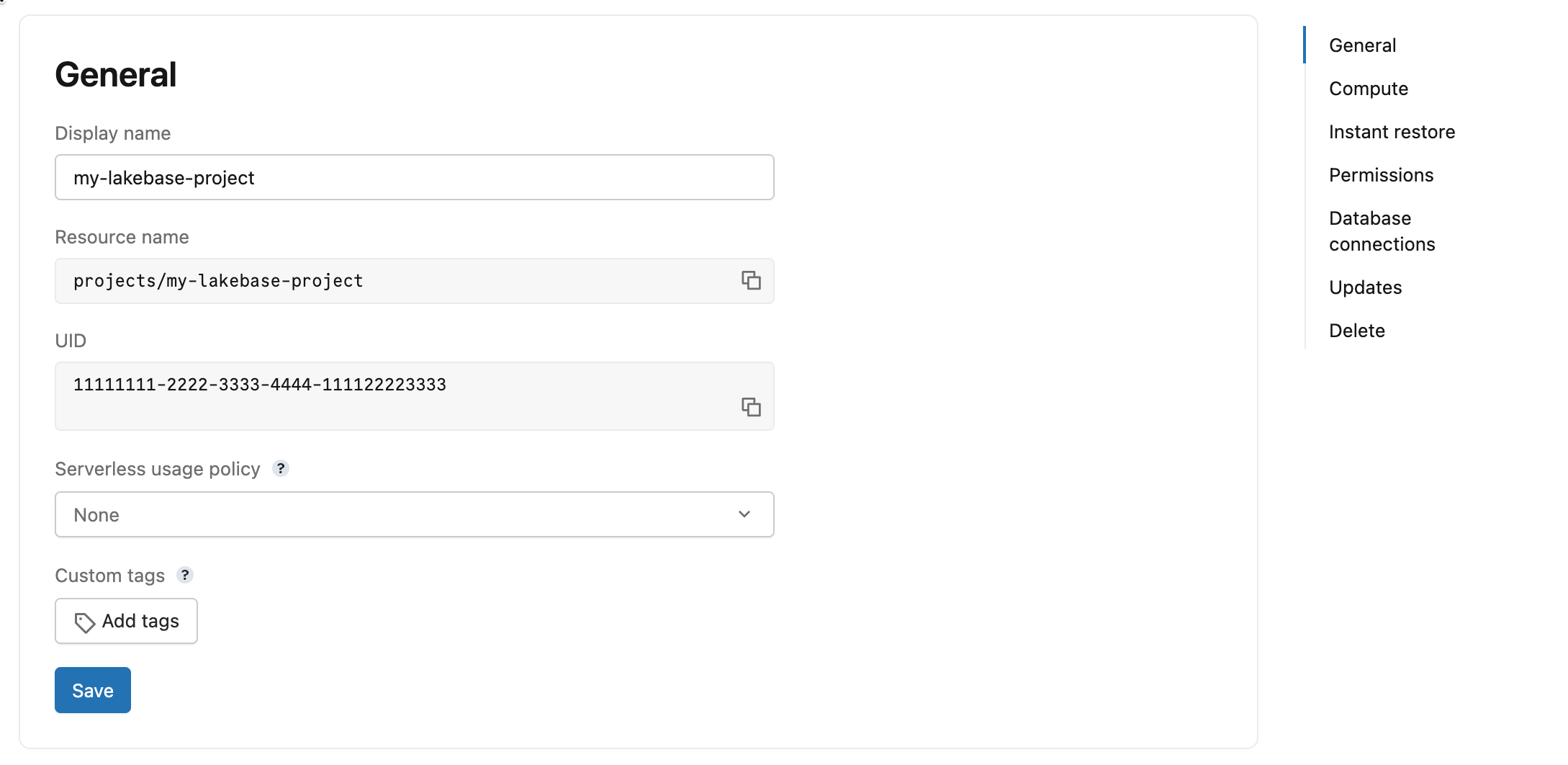
一般設定ページには次のフィールドが表示されます。
- 表示名 : プロジェクトの編集可能な表示名。
- リソース名 : 読み取り専用。プロジェクトの完全なリソース パス (形式:
projects/{project_id})。プロジェクトを識別するには、API および SDK 呼び出しでこの値を使用します。 - UID : 読み取り専用。プロジェクトのシステム生成の一意の識別子。
- サーバーレス使用ポリシー : サーバーレス使用ポリシーをプロジェクトに関連付けて、サーバーレス コンピュートのコストを特定のポリシーに帰属させます。 サーバーレス使用ポリシーを参照してください。
- カスタム タグ : プロジェクトにキーと値のタグを追加します。タグはアカウントの課金利用レコード (
system.billing.usage) に記録され、チーム、プロジェクト、またはコスト センターごとにコストを追跡するために使用できます。 カスタム タグを参照してください。API または CLI を使用してカスタム タグを更新すると、既存のタグがすべて新しいリストに置き換えられます。
- UI
- Python SDK
- CLI
- curl
from databricks.sdk import WorkspaceClient
from databricks.sdk.service.postgres import Project, ProjectSpec, ProjectCustomTag, FieldMask
w = WorkspaceClient()
# Update project display name
w.postgres.update_project(
name="projects/my-project",
update_mask=FieldMask(field_mask=["spec.display_name"]),
project=Project(spec=ProjectSpec(display_name="My Updated Project Name"))
).wait()
# Update serverless usage policy
w.postgres.update_project(
name="projects/my-project",
update_mask=FieldMask(field_mask=["spec.budget_policy_id"]),
project=Project(spec=ProjectSpec(budget_policy_id="<policy-id>"))
).wait()
# Update custom tags (replaces all existing tags)
w.postgres.update_project(
name="projects/my-project",
update_mask=FieldMask(field_mask=["spec.custom_tags"]),
project=Project(spec=ProjectSpec(custom_tags=[
ProjectCustomTag(key="team", value="data-eng"),
ProjectCustomTag(key="cost-center", value="1234")
]))
).wait()
# Update project display name
databricks postgres update-project projects/my-project spec.display_name \
--json '{
"spec": {
"display_name": "My Updated Project Name"
}
}'
# Update serverless usage policy
databricks postgres update-project projects/my-project spec.budget_policy_id \
--json '{
"spec": {
"budget_policy_id": "<policy-id>"
}
}'
# Update custom tags
databricks postgres update-project projects/my-project spec.custom_tags \
--json '{
"spec": {
"custom_tags": [
{"key": "team", "value": "data-eng"},
{"key": "cost-center", "value": "1234"}
]
}
}'
# Update project display name
curl -X PATCH "$WORKSPACE/api/2.0/postgres/projects/my-project?update_mask=spec.display_name" \
-H "Authorization: Bearer ${DATABRICKS_TOKEN}" \
-H "Content-Type: application/json" \
-d '{
"spec": {
"display_name": "My Updated Project Name"
}
}' | jq
# Update serverless usage policy
curl -X PATCH "$WORKSPACE/api/2.0/postgres/projects/my-project?update_mask=spec.budget_policy_id" \
-H "Authorization: Bearer ${DATABRICKS_TOKEN}" \
-H "Content-Type: application/json" \
-d '{
"spec": {
"budget_policy_id": "<policy-id>"
}
}' | jq
# Update custom tags
curl -X PATCH "$WORKSPACE/api/2.0/postgres/projects/my-project?update_mask=spec.custom_tags" \
-H "Authorization: Bearer ${DATABRICKS_TOKEN}" \
-H "Content-Type: application/json" \
-d '{
"spec": {
"custom_tags": [
{"key": "team", "value": "data-eng"},
{"key": "cost-center", "value": "1234"}
]
}
}' | jq
これらは長時間実行される操作です。応答には、ステータスを確認するために使用できる操作名が含まれます。
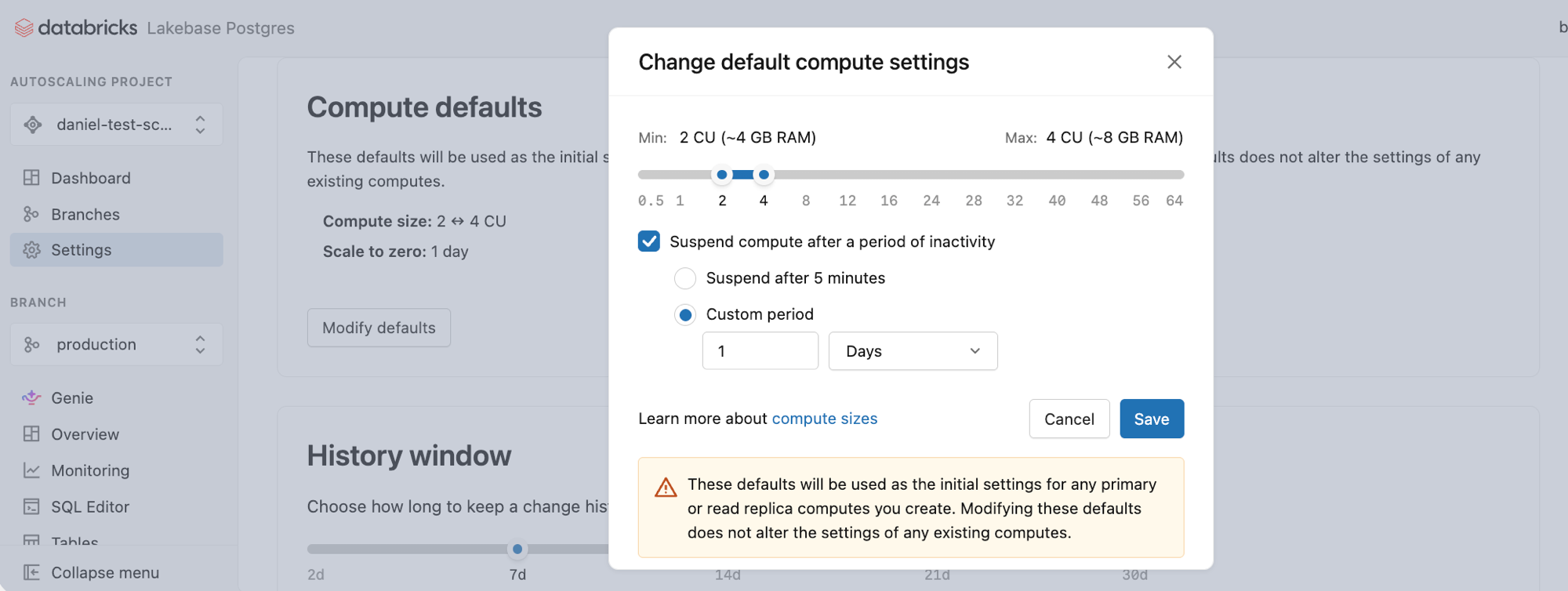
コンピュートのデフォルト
これらは、作成するプライマリまたはリードレプリカ コンピュートの初期設定として使用されます。 これらを変更しても、既存のコンピュートの設定は変更されません。
デフォルト値:
- コンピュートサイズ: 2 ↔ 4 CU (オートスケール範囲; ~4–8 GB RAM)
- ゼロにスケール: [24 時間後にサスペンド] を選択した状態で、 一定期間の非アクティブ状態がチェックされた後 、自動的にサスペンド コンピュートによって有効になります。
「デフォルトの変更」 をクリックしてダイアログを開き、これらの値を変更します。
既存のコンピュートの設定を変更するには、 「コンピュートの管理」を参照してください。
Lakebase Postgres は0.5 CUから112 CUまでのコンピュートサイズをサポートしています。オートスケールは、最大64 CUのコンピュートで利用可能です(0.5 CUから始まり、その後1、2、3... 64と整数単位で増加します)。より大規模な固定サイズのコンピュートは、最大112 CUまでご利用いただけます。各コンピュート ユニット(CU)は 2 GB の RAM を搭載しています。
Lakebase Provisionedとオートスケール : Lakebase Provisionedでは、各コンピュート ユニットに約 16 GB の RAM が割り当てられました。 Lakebase Autoscalingでは、各 CU に 2 GB の RAM が割り当てられます。 この変更により、よりきめ細かいスケーリング オプションとコスト管理が可能になります。
代表的なサイズ:
コンピュート単位 | メモリサイズ |
|---|---|
0.5 CU | 1 GB |
1 CU | 2 GB |
4 CU | 8GB |
8 CU | 16 GB |
16 CU | 32GB |
32 CU | 64GB |
64 CU | 128GB |
112 CU | 224GB |
- オートスケールを有効にするには、スライダーを使用してコンピュートのサイズ範囲を設定します。 オートスケールは、ワークロードの需要に基づいてコンピュート リソースを動的に調整します。 詳細はこちら:オートスケール
- ゼロへのスケール設定を調整して、コンピュートが一時停止するまでの非アクティブなコンピュート時間を増減します (有効な場合は 60 秒から最大 7 日間)。 常にアクティブなコンピュートの ゼロへのスケール を無効にすることもできます。 詳細はこちら:スケール・トゥ・ゼロ
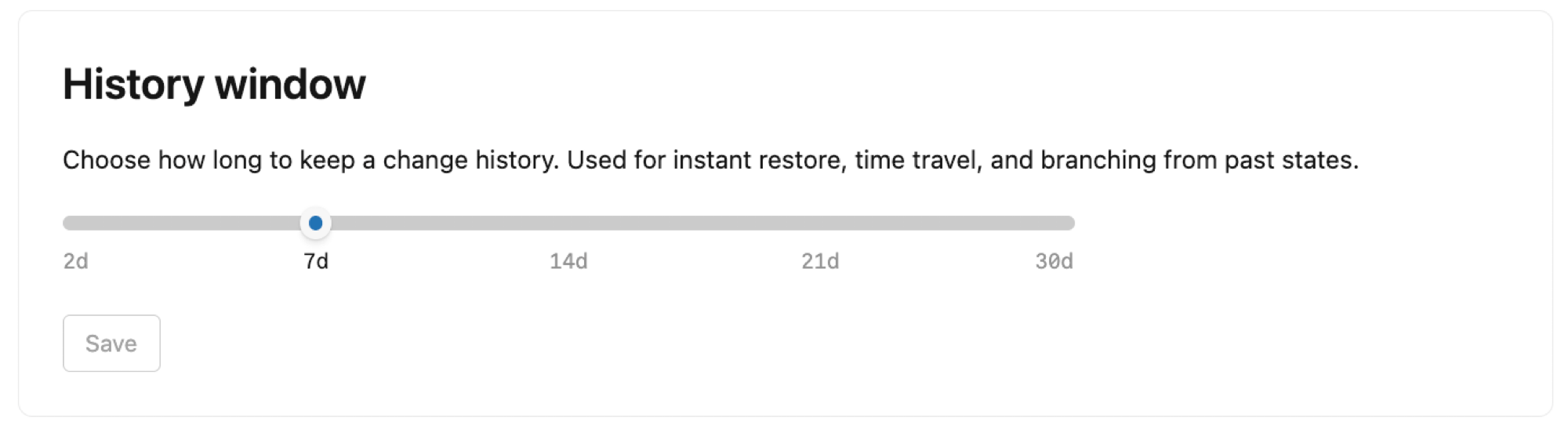
履歴ウィンドウ
プロジェクトの履歴ウィンドウの長さを設定します。Lakebaseはデフォルトで、プロジェクトのルートブランチの変更履歴を保持します。これにより、失われたデータを復元するための特定時点への復元、データの問題調査のための特定時点のデータへのクエリ、および開発ワークフローのための過去の状態からの分岐が可能になります。
履歴表示期間は2日から30日まで設定可能で、デフォルトは7日間です。ご了承ください:
- 履歴ウィンドウを拡張すると、ストレージ容量が増加します。
- 履歴ウィンドウの設定は、プロジェクト内のすべてのブランチに影響します。
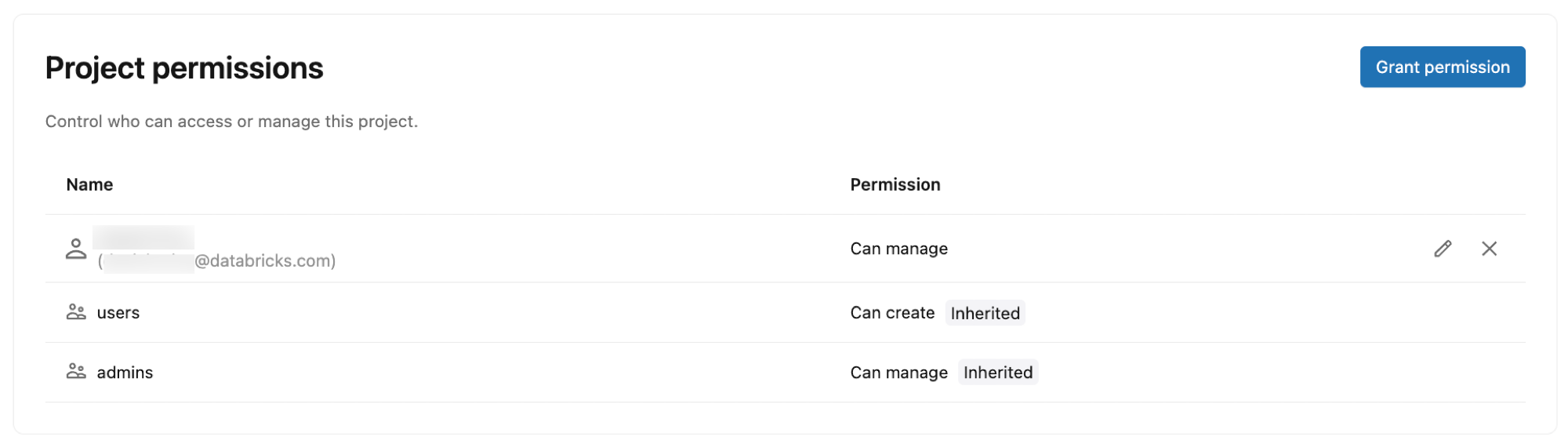
プロジェクト権限
Databricks ID、グループ、サービスプリンシパルにアクセス許可を付与することで、Lakebase プロジェクトにアクセスして管理できるユーザーを制御します。 プロジェクト権限は、ブランチの作成、コンピュートの管理、接続の詳細の表示など、プロジェクト内でユーザーが実行できるアクションを決定します。
権限の種類:
- 作成可能 : プロジェクト リソースの表示と作成
- 使用可能 : プロジェクトまたはブランチを作成または削除せずに、プロジェクト リソースを表示および使用する (一覧表示、表示、接続、および特定のブランチ操作の実行)
- CAN MANAGE : プロジェクトの構成とリソースを完全に制御
デフォルトの権限:
プロジェクトを作成すると、次の権限が自動的に割り当てられます。
- プロジェクトオーナー (プロジェクトを作成したユーザー): CAN MANAGE (フルコントロール)
- ワークスペース ユーザー : 作成可能 (プロジェクトの表示と作成が可能)
- ワークスペース管理者 : CAN MANAGE (フルコントロール)
他のユーザーにアクセス権を付与するには、 「プロジェクト権限の管理」を参照してください。
プロジェクト権限とデータベースアクセスは別々です
プロジェクト権限は Lakebase プラットフォームのアクションを制御し、データベース アクセスは Postgres のロールとそれに関連付けられた権限によって制御されます。「Postgres ロールの作成」および「データベース権限の管理」を参照してください。
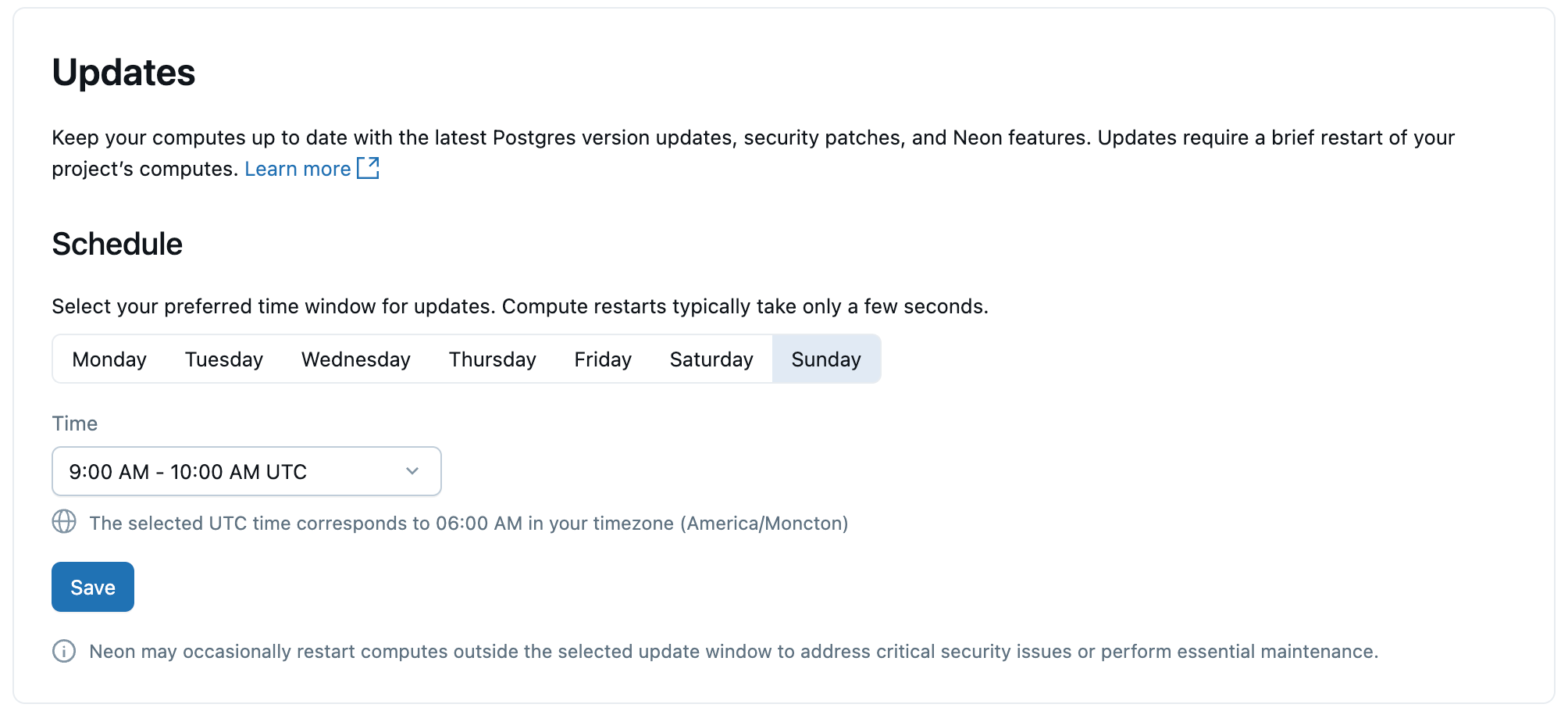
アップデート
Lakebase コンピュートおよび Postgres インスタンスを最新の状態に保つために、Lakebase は、Postgres のマイナー バージョンのアップグレード、セキュリティ パッチ、プラットフォーム機能を含むスケジュールされた更新を自動的に適用します。 更新はプロジェクト内のコンピュートに適用され、数秒かかる短いコンピュートの再起動が必要になります。
更新は自動的に適用されますが、更新の希望日時を設定することもできます。再起動は選択した時間枠内で行われます。
アップデートに関する詳細情報については、 「アップデートの管理」を参照してください。
プロジェクトを削除する
プロジェクトを削除すると、デフォルトではソフト削除状態になり、完全に削除されるまで7日間保持されます。この期間中に、プロジェクトを復元し、すべてのデータを復元することができます。削除されたプロジェクトを復元する方法を参照してください。保持期間をスキップしてプロジェクトをすぐに削除するには、 「プロジェクトを完全に削除する」を参照してください。
プロジェクトがソフト削除されている間は、プロジェクトへの接続やデータベース認証情報の取得を試みると、プロジェクトが削除されたことを示すエラーではなく、一般的なエラー(エンドポイントが見つからない、接続が拒否されたなど)が返されます。これらのエラーが予期せず発生した場合は、 show_deleted=trueのプロジェクトを一覧表示して、プロジェクトがソフト削除されていないかどうかを確認してください。ソフト削除されたプロジェクトを検索するを参照してください。
削除する前に
Databricks では、プロジェクトを削除する前に、関連付けられているすべての Unity Catalog カタログと同期されたテーブルを削除することをお勧めします。そうでない場合、カタログを表示したり、カタログを参照する SQL クエリを実行しようとするとエラーが発生します。
テーブルまたはカタログの所有者でない場合は、削除する前に所有権を自分に再割り当てする必要があります。
Lakebase プロジェクトに対する CAN MANAGE 権限を持つユーザーのみがそれを削除できます。詳細については、 「プロジェクト ACL」および「プロジェクト権限の管理」を参照してください。
プロジェクトを削除する
プロジェクトを削除するには:
- UI
- Python SDK
- Java SDK
- CLI
- curl
- Lakebase アプリでプロジェクトの 設定 に移動します。
- 「 プロジェクトの削除」 セクションで、 「削除」 をクリックし、プロジェクト名を入力して削除を確認します。
from databricks.sdk import WorkspaceClient
w = WorkspaceClient()
# Delete a project
operation = w.postgres.delete_project(name="projects/my-project")
print(f"Delete operation started: {operation.name()}")
これは長時間実行される操作です。プロジェクトとそのすべてのリソース (ブランチ、エンドポイント、データベース、ロール、データ) が削除されます。
import com.databricks.sdk.WorkspaceClient;
WorkspaceClient w = new WorkspaceClient();
// Delete a project
w.postgres().deleteProject("projects/my-project");
System.out.println("Delete operation started");
これは長時間実行される操作です。プロジェクトとそのすべてのリソース (ブランチ、エンドポイント、データベース、ロール、データ) が削除されます。
# Delete a project
databricks postgres delete-project projects/my-project
このコマンドはすぐに戻ります。プロジェクトとそのすべてのリソースが削除されます。
curl -X DELETE "$WORKSPACE/api/2.0/postgres/projects/my-project" \
-H "Authorization: Bearer ${DATABRICKS_TOKEN}" | jq
これは長時間実行される操作です。応答には、削除ステータスを確認するために使用できる操作名が含まれます。
プロジェクトを完全に削除する
Lakebaseプロジェクトを7日間のソフト削除保持期間の満了を待たずに即座に完全に削除するには:
- Python SDK
- Java SDK
- CLI
- curl
from databricks.sdk import WorkspaceClient
w = WorkspaceClient()
operation = w.postgres.delete_project(name="projects/my-project", purge=True)
operation.wait()
import com.databricks.sdk.WorkspaceClient;
import com.databricks.sdk.service.postgres.DeleteProjectRequest;
WorkspaceClient w = new WorkspaceClient();
w.postgres().deleteProject(
new DeleteProjectRequest()
.setName("projects/my-project")
.setPurge(true)
).waitForCompletion();
databricks postgres delete-project projects/my-project --purge
curl -X DELETE "$WORKSPACE/api/2.0/postgres/projects/my-project?purge=true" \
-H "Authorization: Bearer ${DATABRICKS_TOKEN}" | jq
削除されたプロジェクトを復元する
Lakebaseプロジェクトを削除すると、ソフト削除状態になり、完全に削除されるまで7日間保持されます。この期間中に、プロジェクトを復元し、すべてのデータを復元することができます。
何が修復されるのか
ソフト削除されたプロジェクトを復元すると、以下の内容が復元されます。
- すべての支店とそのデータ
- すべてのPostgresデータベースとロール
- すべてのコンピュート エンドポイントとその構成
- コンピュート安全を含むプロジェクト設定、ウィンドウ設定の復元、環境設定の更新
- プロジェクト権限
復旧後、一部のリソースは再構成が必要になる場合があります。プロジェクトの復元後に問題が発生した場合は、 Databricksサポートにお問い合わせください。
ソフト削除されたプロジェクトを探す
論理的に削除されたプロジェクトを含むすべてのプロジェクトを一覧表示するには、 show_deletedを使用します。 これは、復元したいプロジェクトのリソース名を見つけるのに役立ちます。
- Python SDK
- CLI
- curl
from databricks.sdk import WorkspaceClient
w = WorkspaceClient()
for project in w.postgres.list_projects(show_deleted=True):
print(f"Project: {project.name}")
print(f" Display name: {project.status.display_name}")
if project.delete_time:
print(f" Deleted: {project.delete_time}")
print(f" Purge time: {project.purge_time}")
databricks postgres list-projects --show-deleted
curl -X GET "$WORKSPACE/api/2.0/postgres/projects?show_deleted=true" \
-H "Authorization: Bearer ${DATABRICKS_TOKEN}" | jq
プロジェクトを復元する
ソフト削除されたLakebaseプロジェクトを復元するには:
- Python SDK
- Java SDK
- CLI
- curl
from databricks.sdk import WorkspaceClient
w = WorkspaceClient()
operation = w.postgres.undelete_project(name="projects/my-project")
operation.wait()
import com.databricks.sdk.WorkspaceClient;
import com.databricks.sdk.service.postgres.UndeleteProjectRequest;
WorkspaceClient w = new WorkspaceClient();
w.postgres().undeleteProject(
new UndeleteProjectRequest().setName("projects/my-project")
).waitForCompletion();
databricks postgres undelete-project projects/my-project
curl -X POST "$WORKSPACE/api/2.0/postgres/projects/my-project/undelete" \
-H "Authorization: Bearer ${DATABRICKS_TOKEN}" | jq