リードレプリカの管理
このガイドでは、プロジェクトの読み取りレプリカの作成と管理について説明します。リードレプリカは、水平スケーリングからアナリティクス ワークロードに至るまでのアプリケーションを使用して、本番運用データベース操作から読み取り専用作業を分離します。 読み取りレプリカのアーキテクチャとユースケースの詳細については、 「読み取りレプリカ」を参照してください。
リードレプリカの理解
リードレプリカを使用すると、プロジェクト内の任意のブランチに 1 つ以上の読み取り専用コンピュートを作成できます。 各レプリカに割り当てられるコンピュート サイズを構成でき、オートスケールとスケール トゥ ゼロ機能の両方がサポートされているため、リード レプリカ コンピュートの使用量を制御できます。
読み取りレプリカの作成、構成、接続の手順は、ユースケースに関係なく同じです。
API および SDK では、読み取りレプリカは、 endpoint_typeがENDPOINT_TYPE_READ_ONLYに設定されたエンドポイントです。
地域サポート
Lakebase は、プロジェクトと 同じリージョンでの 読み取りレプリカの作成をサポートしています。クロスリージョン読み取りレプリカはサポートされていません。
コンピュート設定の同期
Lakebase リードレプリカの場合、特定の Postgres 設定の値がプライマリの読み取り/書き込みコンピュートよりも低い値であってはなりません。 このため、リード レプリカ コンピュートの次の設定は、リード レプリカ コンピュートの起動時にプライマリ読み取り/書き込みコンピュートの設定と同期されます。
max_connectionsmax_prepared_transactionsmax_locks_per_transactionmax_wal_sendersmax_worker_processes
ユーザーの操作は必要ありません。読み取りレプリカを作成すると、設定は自動的に同期されます。ただし、プライマリ読み取り/書き込みコンピュートのコンピュート サイズ構成を変更した場合は、設定の同期を確保するためにリード レプリカ コンピュートを再起動する必要があります。 詳細については、 「レプリケーション遅延のトラブルシューティング」を参照してください。
リードレプリカの作成と管理
制限
- ブランチごとに最大6つのリードレプリカ 。
- リードレプリカは 、同時にアクティブなコンピュート インスタンスのプロジェクト全体の制限 20 にカウントされます。 プロジェクトの制限事項を参照してください。
前提条件
- Lakebase プロジェクト。「プロジェクトの作成」を参照してください。
リードレプリカを作成する
読み取りレプリカを作成するには:
- UI
- Python SDK
- Java SDK
- CLI
- curl
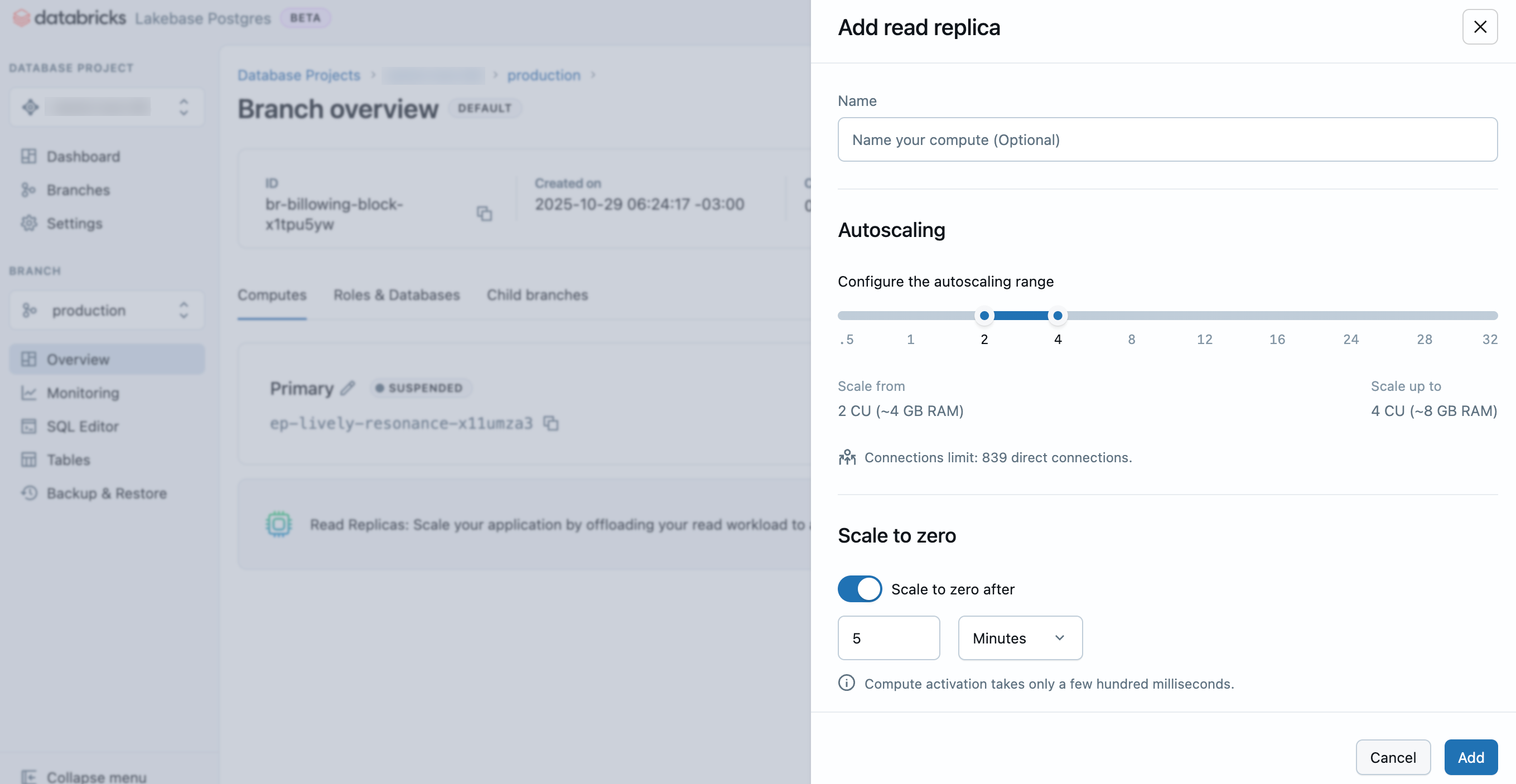
- Lakebase アプリで、プロジェクト、ブランチ、 [コンピュート] タブに移動します。
- [読み取りレプリカの追加] をクリックします。
- リードレプリカの名前を入力し、コンピュート設定 (オートスケール範囲とゼロへのスケール動作) を構成し、 [追加] をクリックします。
from databricks.sdk import WorkspaceClient
from databricks.sdk.service.postgres import Endpoint, EndpointSpec, EndpointType
w = WorkspaceClient()
# Create read replica endpoint (READ_ONLY)
endpoint_spec = EndpointSpec(
endpoint_type=EndpointType.ENDPOINT_TYPE_READ_ONLY,
autoscaling_limit_max_cu=2.0
)
endpoint = Endpoint(spec=endpoint_spec)
result = w.postgres.create_endpoint(
parent="projects/my-project/branches/production",
endpoint=endpoint,
endpoint_id="my-read-replica"
).wait()
print(f"Endpoint created: {result.name}")
print(f"Host: {result.status.hosts.host}")
import com.databricks.sdk.WorkspaceClient;
import com.databricks.sdk.service.postgres.*;
WorkspaceClient w = new WorkspaceClient();
// Create read replica endpoint (READ_ONLY)
EndpointSpec endpointSpec = new EndpointSpec()
.setEndpointType(EndpointType.ENDPOINT_TYPE_READ_ONLY)
.setAutoscalingLimitMaxCu(2.0);
Endpoint endpoint = new Endpoint()
.setSpec(endpointSpec);
Endpoint result = w.postgres().createEndpoint(
new CreateEndpointRequest()
.setParent("projects/my-project/branches/production")
.setEndpoint(endpoint)
.setEndpointId("my-read-replica")
).waitForCompletion();
System.out.println("Endpoint created: " + result.getName());
System.out.println("Host: " + result.getStatus().getHosts().getHost());
# Create a read replica for a branch
databricks postgres create-endpoint projects/my-project/branches/production my-read-replica \
--json '{
"spec": {
"endpoint_type": "ENDPOINT_TYPE_READ_ONLY",
"autoscaling_limit_min_cu": 0.5,
"autoscaling_limit_max_cu": 4.0
}
}'
curl -X POST "$WORKSPACE/api/2.0/postgres/projects/my-project/branches/production/endpoints?endpoint_id=my-read-replica" \
-H "Authorization: Bearer ${DATABRICKS_TOKEN}" \
-H "Content-Type: application/json" \
-d '{
"spec": {
"endpoint_type": "ENDPOINT_TYPE_READ_ONLY",
"autoscaling_limit_min_cu": 0.5,
"autoscaling_limit_max_cu": 4.0
}
}' | jq
コンピュートのサイズ構成によって、データベースの処理能力が決まります。 詳細:コンピュートの管理
リードレプリカは数秒以内にプロビジョニングされ、ブランチの [コンピュート] タブに表示されます。
リードレプリカを表示する
ブランチのリードレプリカを表示するには、Lakebase アプリでプロジェクトに移動し、 [ブランチ] ページからブランチを選択して、すべてのリードレプリカ コンピュートがリストされている [コンピュート] タブを表示します。
リードレプリカに接続する
リードレプリカへの接続は、接続情報を取得するときにリードレプリカ コンピュートを選択することを除いて、プライマリ読み取り/書き込みコンピュートに接続するのと同じプロセスに従います。
読み取りレプリカの接続情報を取得するには:
- Lakebase アプリで、プロジェクト ダッシュボードの [接続] をクリックします。
- コンピュート ドロップ ダウンからブランチ、データベース、ロール、リード レプリカ コンピュートを選択し、指定された接続文字列をコピーします。
プライマリの読み取り/書き込みコンピュートの場合と同様に、 OAuth Postgres ロールを使用して接続できます。
読み取りレプリカ接続では書き込み操作は許可されません。書き込み操作を実行しようとするとエラーが発生します。
認証方法と接続オプションの詳細については、 「プロジェクトへの接続」を参照してください。
リードレプリカを編集する
リードレプリカを編集して、コンピュートのサイズまたはゼロへのスケール構成を変更できます。
リードレプリカを編集するには:
- UI
- Python SDK
- Java SDK
- CLI
- curl
- Lakebase アプリでブランチの コンピュート タブに移動します。
- リードレプリカを見つけて [編集] をクリックし、コンピュート設定を更新して、 [保存] をクリックします。
from databricks.sdk import WorkspaceClient
from databricks.sdk.service.postgres import Endpoint, EndpointSpec, EndpointType, FieldMask
w = WorkspaceClient()
# Update read replica size
endpoint_name = "projects/my-project/branches/production/endpoints/my-read-replica"
endpoint_spec = EndpointSpec(
endpoint_type=EndpointType.ENDPOINT_TYPE_READ_ONLY,
autoscaling_limit_min_cu=1.0,
autoscaling_limit_max_cu=8.0
)
endpoint = Endpoint(name=endpoint_name, spec=endpoint_spec)
update_mask = FieldMask(field_mask=[
"spec.autoscaling_limit_min_cu",
"spec.autoscaling_limit_max_cu"
])
result = w.postgres.update_endpoint(
name=endpoint_name,
endpoint=endpoint,
update_mask=update_mask
).wait()
print(f"Updated read replica size: {result.status.autoscaling_limit_min_cu}-{result.status.autoscaling_limit_max_cu} CU")
import com.databricks.sdk.WorkspaceClient;
import com.databricks.sdk.service.postgres.*;
import com.google.protobuf.FieldMask;
WorkspaceClient w = new WorkspaceClient();
// Update read replica size
String endpointName = "projects/my-project/branches/production/endpoints/my-read-replica";
EndpointSpec endpointSpec = new EndpointSpec()
.setAutoscalingLimitMinCu(1.0)
.setAutoscalingLimitMaxCu(8.0);
FieldMask updateMask = FieldMask.newBuilder()
.addPaths("spec.autoscaling_limit_min_cu")
.addPaths("spec.autoscaling_limit_max_cu")
.build();
w.postgres().updateEndpoint(
new UpdateEndpointRequest()
.setName(endpointName)
.setEndpoint(new Endpoint().setSpec(endpointSpec))
.setUpdateMask(updateMask)
);
System.out.println("Update initiated");
# Update a read replica's autoscaling settings
databricks postgres update-endpoint projects/my-project/branches/production/endpoints/my-read-replica "spec.autoscaling_limit_min_cu,spec.autoscaling_limit_max_cu" \
--json '{
"spec": {
"autoscaling_limit_min_cu": 1.0,
"autoscaling_limit_max_cu": 8.0
}
}'
# Update a read replica's autoscaling settings
curl -X PATCH "$WORKSPACE/api/2.0/postgres/projects/my-project/branches/production/endpoints/my-read-replica?update_mask=spec.autoscaling_limit_min_cu,spec.autoscaling_limit_max_cu" \
-H "Authorization: Bearer ${DATABRICKS_TOKEN}" \
-H "Content-Type: application/json" \
-d '{
"name": "projects/my-project/branches/production/endpoints/my-read-replica",
"spec": {
"autoscaling_limit_min_cu": 1.0,
"autoscaling_limit_max_cu": 8.0
}
}' | jq
詳細:コンピュートの管理
リードレプリカを削除する
リードレプリカの削除は永続的なアクションです。ただし、必要な場合は、新しい読み取りレプリカをすぐに作成できます。
リードレプリカを削除するには:
- UI
- Python SDK
- Java SDK
- CLI
- curl
- Lakebase アプリでブランチの コンピュート タブに移動します。
- 読み取りレプリカを見つけて、 [編集] 、 [削除] の順にクリックし、削除を確認します。
from databricks.sdk import WorkspaceClient
w = WorkspaceClient()
# Delete endpoint
w.postgres.delete_endpoint(
name="projects/my-project/branches/production/endpoints/my-read-replica"
).wait()
print("Endpoint deleted")
削除操作は非同期です。.wait()メソッドは削除が完了するまでブロックします。
import com.databricks.sdk.WorkspaceClient;
WorkspaceClient w = new WorkspaceClient();
// Delete endpoint
w.postgres().deleteEndpoint(
"projects/my-project/branches/production/endpoints/my-read-replica"
);
System.out.println("Delete initiated");
# Delete a read replica
databricks postgres delete-endpoint projects/my-project/branches/production/endpoints/my-read-replica
curl -X DELETE "$WORKSPACE/api/2.0/postgres/projects/my-project/branches/production/endpoints/my-read-replica" \
-H "Authorization: Bearer ${DATABRICKS_TOKEN}" | jq
応答:
{
"name": "projects/my-project/branches/production/endpoints/my-read-replica/operations/...",
"done": true,
"response": {
"@type": "type.googleapis.com/google.protobuf.Empty"
}
}
レプリケーション遅延のトラブルシューティング
リードレプリカが遅れている場合は、次のステップに従って問題を診断し、解決してください。
構成の整合性を確認する
レプリケーションの遅延が検出された場合は、プライマリ コンピューティングとリード レプリカ コンピュートの構成が一致していることを確認してください。 具体的には、プライマリ コンピュートとリード レプリカ コンピュートの間で次の点が一致することを確認します。
max_connectionsmax_prepared_transactionsmax_locks_per_transactionmax_wal_sendersmax_worker_processes
Lakebase SQLエディターまたはpsqlのようなSQLクライアントを使用して、プライマリ読み取り/書き込みコンピュートとリードレプリカ コンピュートの両方で次のクエリを実行できます。
SELECT name, setting
FROM pg_settings
WHERE name IN (
'max_connections',
'max_prepared_transactions',
'max_locks_per_transaction',
'max_wal_senders',
'max_worker_processes'
);
両方のコンピュートの結果を比較して、調整されていない設定を特定します。
リードレプリカコンピュートを再起動します
構成が調整されていない場合は、リードレプリカ コンピュートを再起動して、設定を自動的に更新します。 ブランチの [コンピュート ] タブに移動し、リードレプリカを見つけて、 [編集] 、 [再起動] の 順にクリックします。
プライマリ読み取り/書き込みコンピュートのサイズを増やすときは、必ず関連する読み取りレプリカを再起動して、構成が維持されるようにしてください。