LakebaseプロジェクトによるリバースETL
Lakebase オートスケールは次のリージョンで利用できます: us-east-1 、 us-east-2 、 us-west-2 、 eu-central-1 、 eu-west-1 、 ap-south-1 、 ap-southeast-1 、 ap-southeast-2 。
Lakebase オートスケールは、オートスケール コンピュート、ゼロへのスケール、分岐、即時復元を備えた Lakebase の最新バージョンです。 Lakebase プロビジョニングとの機能の比較については、 「バージョン間の選択」を参照してください。
Lakebase のリバース ETL は、Unity Catalog テーブルを Postgres に同期し、アプリケーションがキュレーションされたレイクハウスデータを直接使用できるようにします。レイクハウスは分析と強化のために最適化されており、Lakebase は高速なクエリとトランザクションの一貫性を必要とする運用ワークロード向けに設計されています。
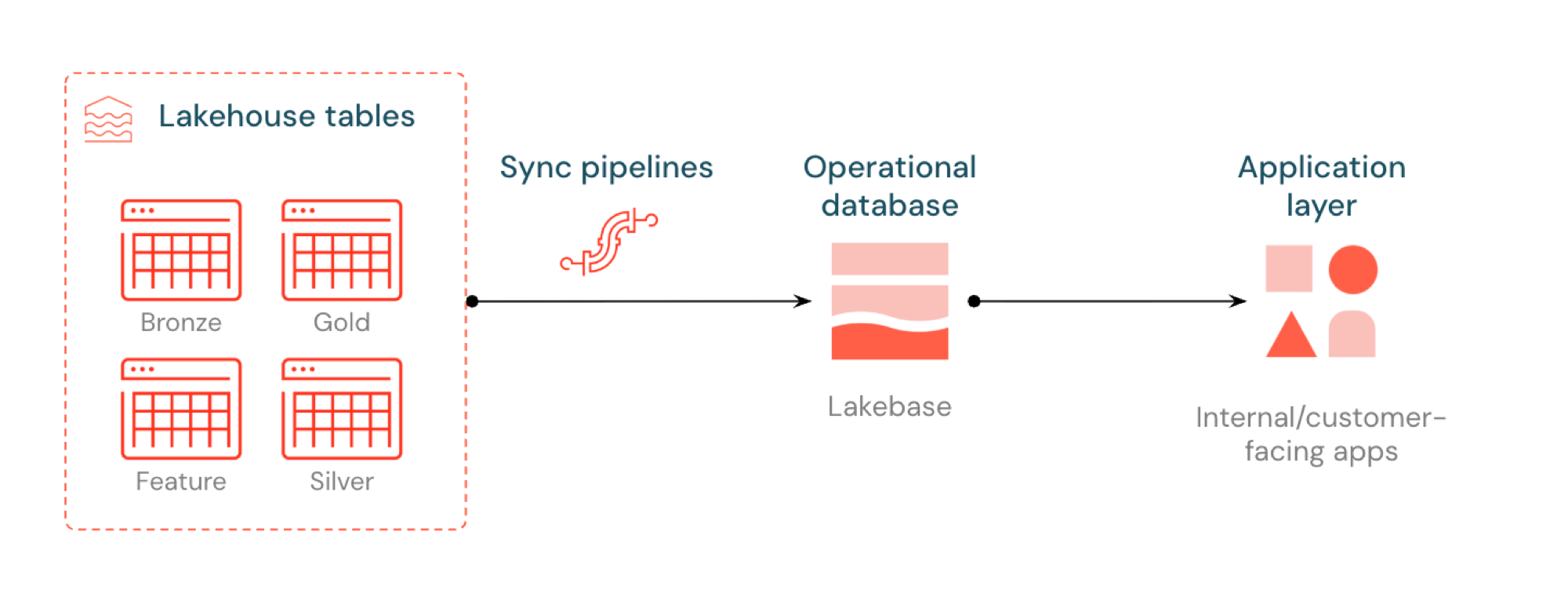
リバース ETL とは何ですか?
リバースETL使用すると、アナリティクス グレードのデータをUnity Catalogから Lakebase Postgres に移動でき、低レイテンシー クエリ (10 ミリ秒未満) と完全なACID必要とするアプリケーションでデータを利用できるようになります。 キュレーションされたデータをリアルタイム アプリケーションで使用できるようにすることで、分析ストレージと運用システム間のギャップを埋めます。
仕組み
Databricks 同期テーブルは、 Lakebase にUnity Catalogデータの管理されたコピーを作成します。 同期されたテーブルを作成すると、次のものが得られます。
- 新しいUnity Catalogテーブル (読み取り専用、同期パイプラインによって管理)
- Lakebase の Postgres テーブル (アプリケーションからクエリ可能)
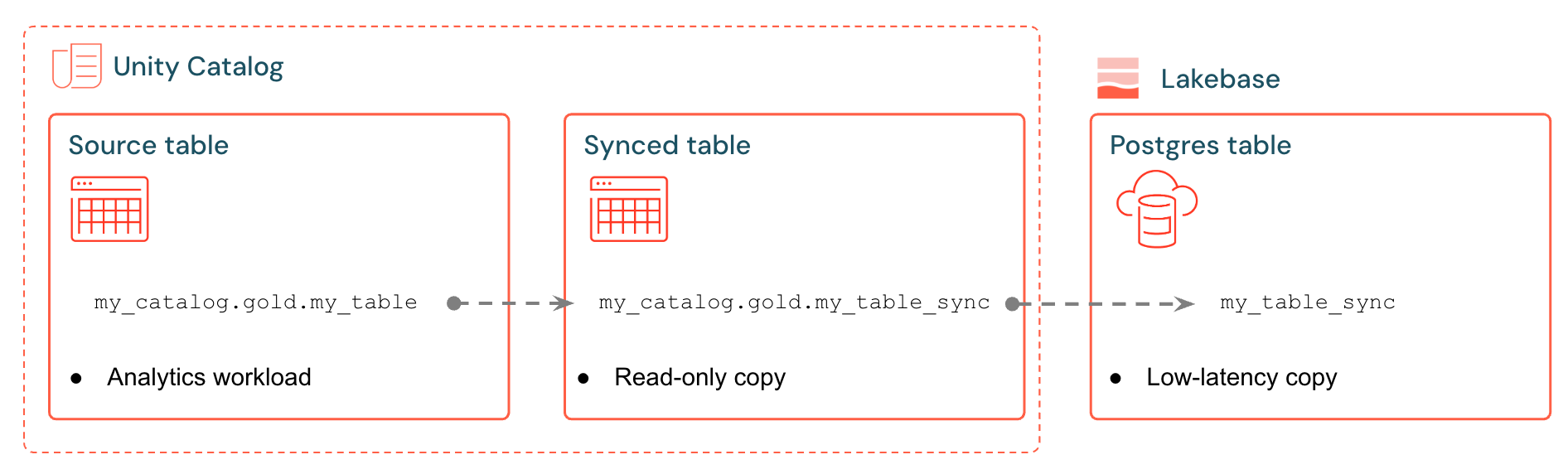
たとえば、ゴールド テーブル、エンジニアリングされた特徴、または ML 出力をanalytics.gold.user_profilesから新しい同期テーブルanalytics.gold.user_profiles_syncedに同期できます。Postgres では、Unity Catalog スキーマ名は Postgres スキーマ名になるため、 "gold"."user_profiles_synced"のように表示されます。
SELECT * FROM "gold"."user_profiles_synced" WHERE "user_id" = 12345;
アプリケーションは標準の Postgres ドライバーに接続し、同期されたデータと自身の動作状態を照会します。
Postgres で同期テーブルを直接変更することは可能ですが、 Databricksソースによるデータ完全性を保護するために読み取りクエリのみを実行することを強くお勧めします。 同期されたテーブルでサポートされている操作については、 「サポートされている操作」を参照してください。
同期パイプラインは、マネージドLakeFlow Spark宣言型パイプラインを使用して、ソース テーブルからの変更でUnity Catalog同期テーブルと Postgres テーブルの両方を継続的に更新します。 各同期では、Lakebase データベースへの接続を最大 16 個使用できます。
Lakebase Postgres は、トランザクション保証付きで最大 1,000 のライナー接続をサポートするため、アプリケーションはエンリッチデータを読み取りながら、同じデータベース内で挿入、更新、削除を処理できます。
同期モード
アプリケーションのニーズに応じて適切な同期モードを選択します。
モード | 説明 | どのようなタスクにベストなのか | パフォーマンス |
|---|---|---|---|
スナップショット | すべてのデータの1回限りのコピー | 初期設定または履歴分析 | ソースデータの10%以上を変更する場合、10倍の効率化 |
トリガー | オンデマンドまたは一定間隔で実行されるスケジュール更新 | ダッシュボード(1時間ごと/毎日更新) | コストとラグのバランスが良い。5分間隔で実行すると高価になります |
連続 | 数秒の遅延でリアルタイムストリーミング | ライブ アプリケーション (専用のコンピュートによりコストが高くなります) | 遅延は最低、コストは最高。最小15秒間隔 |
トリガー モードと連続モードでは、ソース テーブルで変更データフィード (CDF) を有効にする必要があります。 CDF が有効になっていない場合、実行する正確なALTER TABLEコマンドを含む警告が UI に表示されます。変更データフィードの詳細については、 「 DatabricksでDelta Lake変更データフィードを使用する」を参照してください。
使用例
Lakebase を使用したリバース ETL は、一般的な運用シナリオをサポートします。
- Databricks アプリに同期された最新のユーザー プロファイルを必要とするパーソナライゼーション エンジン
- モデル予測や特徴量を提供するアプリケーション レイクハウスのコンピュート
- KPIをリアルタイムで表示する顧客向けダッシュボード
- 即時対応のためにリスクスコアを必要とする不正検出サービス
- レイクハウスからキュレーションされたデータを使用して顧客レコードを充実させるサポートツール
同期されたテーブルを作成する(UI)
UI ワークフローの概要は次のとおりです。
前提条件
必要なもの:
- Lakebase が有効になっている Databricks ワークスペース。
- Lakebase プロジェクト (プロジェクトの作成を参照)。
- 厳選されたデータを含むUnity Catalogテーブル。
- 同期されたテーブルを作成する権限。
容量計画とデータ型の互換性については、 「データ型と互換性」および「容量計画」を参照してください。
ステップ 1: ソーステーブルを選択します
ワークスペース サイドバーの [カタログ] に移動し、同期するUnity Catalogテーブルを選択します。
ステップ 2: 変更データフィードを有効にする (必要な場合)
トリガー 同期モードまたは 連続 同期モードを使用する場合は、ソース テーブルで変更データフィードを有効にする必要があります。 テーブルですでに CDF が有効になっているかどうかを確認するか、SQL エディターまたはノートブックで次のコマンドを実行します。
ALTER TABLE your_catalog.your_schema.your_table
SET TBLPROPERTIES (delta.enableChangeDataFeed = true)
your_catalog.your_schema.your_table実際のテーブル名に置き換えます。
ステップ 3: 同期テーブルを作成する
テーブルの詳細ビューから、 [作成] > [同期されたテーブル] をクリックします。
ステップ 4: 設定する
同期テーブルの作成 ダイアログで次の操作を行います。
- テーブル名 : 同期されたテーブルの名前を入力します (ソース テーブルと同じカタログとスキーマに作成されます)。これにより、Unity Catalog 同期テーブルとクエリ可能な Postgres テーブルの両方が作成されます。
- データベースの種類 : Lakebase サーバレス (オートスケール) を選択します。
- 同期モード : ニーズに応じて、 スナップショット 、 トリガー 、または 連続 を選択します (上記の同期モードを参照)。
- プロジェクト、ブランチ、データベースの選択を構成します。
- 主キー が正しいことを確認します (通常は自動検出されます)。
Triggered または Continuous モードを選択し、変更データフィードをまだ有効にしていない場合は、実行するための正確なコマンドを含む警告が表示されます。 データ型の互換性に関する質問については、 「データ型と互換性」を参照してください。
同期されたテーブルを作成するには、 [作成] をクリックします。
ステップ 5: モニター
作成後、 カタログ 内の同期されたテーブルを監視します。 [概要] タブには、同期ステータス、構成、パイプライン ステータス、および最後の同期タイムスタンプが表示されます。手動で更新するには 、今すぐ同期 を使用してください。
データ型と互換性
同期されたテーブルを作成するときに、Unity Catalog データ型は Postgres 型にマッピングされます。複合型 (ARRAY、MAP、STRUCT) は、Postgres では JSONB として保存されます。
ソース列タイプ | Postgresの列型 |
|---|---|
BIGINT | BIGINT |
バイナリ | バイト |
ブール値 | ブール値 |
DATE | DATE |
10進数(p,s) | 数値 |
DOUBLE | 倍精度 |
Float | real |
INT | Integer |
間隔 | 間隔 |
smallint | smallint |
STRING | TEXT |
TIMESTAMP | タイムゾーン付きタイムスタンプ |
タイムスタンプ_NTZ | タイムゾーンなしのタイムスタンプ |
tinyint | smallint |
ARRAY<elementType> | JSONB |
MAP\ | JSONB |
STRUCT<フィールド名:フィールドタイプ[, ...]> | JSONB |
GEOGRAPHY、GEOMETRY、VARIANT、および OBJECT タイプはサポートされていません。
無効な文字を処理する
ヌル バイト (0x00) などの特定の文字は、 Unity Catalog文字列、ARRAY、MAP、または STRUCT 列では許可されますが、Postgres のTEXTまたは JSONB 列ではサポートされません。 これにより、次のようなエラーが発生し、同期が失敗する可能性があります。
ERROR: invalid byte sequence for encoding "UTF8": 0x00
ERROR: unsupported Unicode escape sequence DETAIL: \u0000 cannot be converted to text
ソリューション:
-
文字列フィールドをサニタイズ : 同期する前にサポートされていない文字を削除します。文字列列の null バイトの場合:
SQLSELECT REPLACE(column_name, CAST(CHAR(0) AS STRING), '') AS cleaned_column FROM your_table -
BINARY に変換 : 生のバイトを保持する必要がある文字列列の場合は、BINARY 型に変換します。
キャパシティプランニング
リバース ETL 実装を計画するときは、次のリソース要件を考慮してください。
- 接続使用量 : 同期された各テーブルは、Lakebase データベースへの接続を最大 16 個使用します。これはインスタンスの接続制限にカウントされます。
- サイズ制限 : 同期されたすべてのテーブル全体の論理データ サイズ制限は 8 TB です。個々のテーブルには制限はありませんが、Databricks では更新が必要なテーブルについては 1 TB を超えないようにすることを推奨しています。
- 命名要件 : データベース、スキーマ、およびテーブル名には、英数字とアンダースコア (
[A-Za-z0-9_]+) のみを含めることができます。 - スキーマ進化 : トリガー モードと連続モードでは、追加的なスキーマ変更 (列の追加など) のみがサポートされています。
- 更新レート: : Lakebase オートスケールの場合、同期パイプラインは、キャパシティー ユニット (CU) あたり 1 秒あたり約 150 行の連続書き込みとトリガー書き込み、および CU あたり 1 秒あたり最大 2,000 行のスナップショット書き込みをサポートします。
Postgres の同期テーブルで許可される操作
Databricks では、誤って上書きしたりデータの不整合が生じたりしないように、同期されたテーブルに対して Postgres で次の操作のみを実行することを推奨しています。
- 読み取り専用クエリ
- インデックスの作成
- テーブルを削除する( Unity Catalogから同期されたテーブルを削除した後、スペースを解放するため)
Postgres で同期されたテーブルを他の方法で変更することは可能ですが、同期パイプラインに干渉します。
同期されたテーブルを削除する
同期されたテーブルを削除するには、Unity Catalog と Postgres の両方から削除する必要があります。
-
Unity Catalogから削除 : カタログ で同期したテーブルを見つけて、
 メニューをクリックし、 [削除] を選択します。 これにより、データの更新は停止しますが、テーブルは Postgres に残ります。
メニューをクリックし、 [削除] を選択します。 これにより、データの更新は停止しますが、テーブルは Postgres に残ります。 -
Postgres から削除 : Lakebase データベースに接続し、テーブルを削除してスペースを解放します。
SQLDROP TABLE your_database.your_schema.your_table;
SQL エディターまたは外部ツールを使用して Postgres に接続できます。
もっと詳しく知る
タスク | 説明 |
|---|---|
Lakebaseプロジェクトを設定する | |
Lakebaseの接続オプションについて | |
Lakebase データを Unity Catalog で表示して、統合ガバナンスとクロスソースクエリを実現します。 | |
ガバナンスと権限を理解する |
その他のオプション
Databricks 以外のシステムにデータを同期する場合は、Census や Hightouch などのPartner Connect リバース ETL ソリューションを参照してください。