ストレージアーキテクチャ
Lakebaseはストレージとコンピュートを分けています。お客様のデータベースデータは、お客様のクエリを実行するコンピュートインスタンスとは独立して、Databricksが管理する分散ストレージレイヤーに格納されています。ストレージは、コンピュートが実行中、停止する中、スケーリング中のいずれの状態であっても、永続的に保持され、高い可用性を維持します。
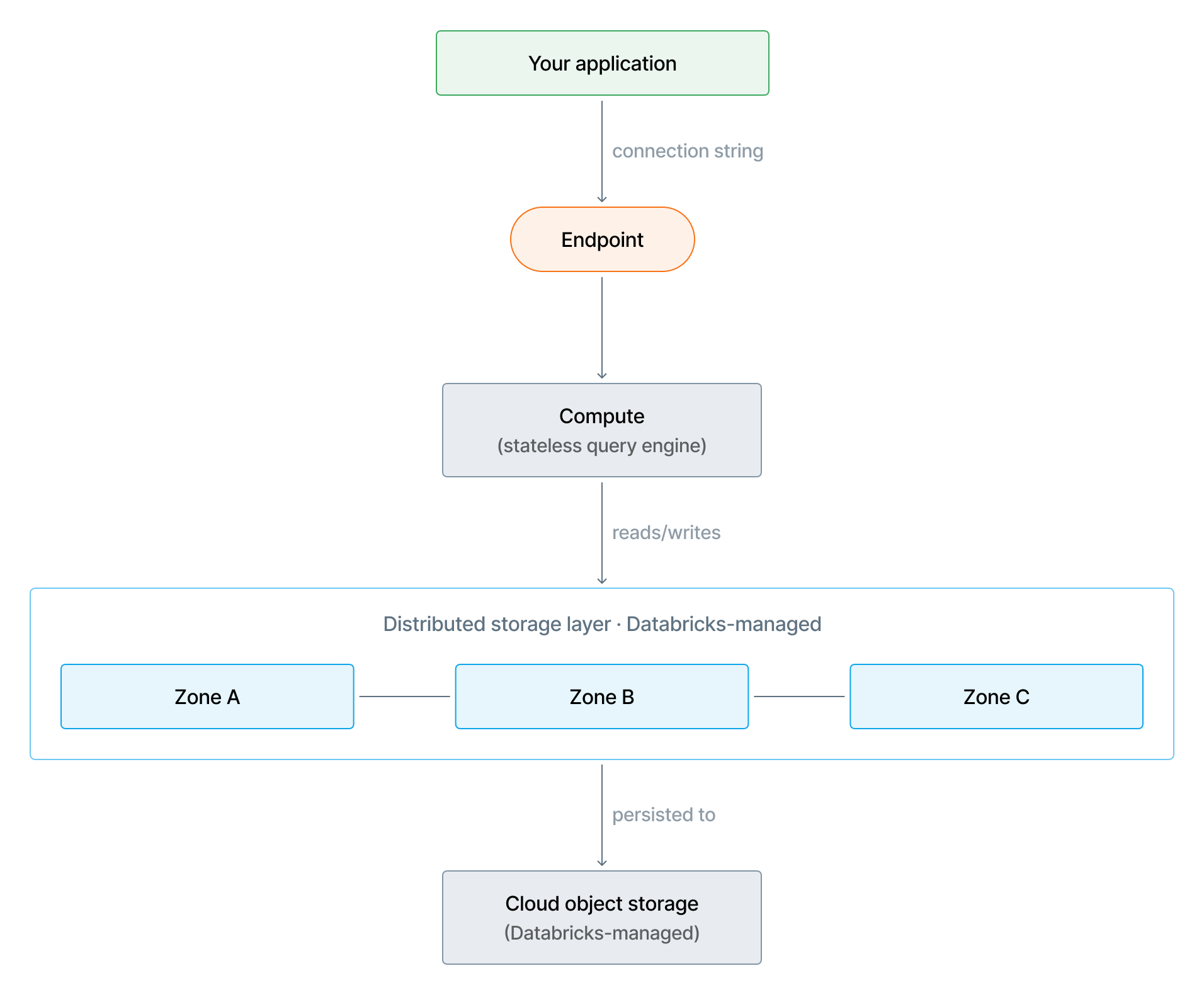
ストレージ レイヤー
Lakebaseは分散ストレージアーキテクチャを採用しています。単一のマシンでは、データベースの信頼性のある状態を保持しません。データは、ストレージ層全体の永続性の基盤となるDatabricksが管理するクラウドオブジェクトストレージにも永続化されます。クラウドオブジェクトストレージは、極めて高い耐久性を実現するように設計されており、非同期レプリケーションには依存しないため、耐久性がレプリケーションラグの影響を受けることはありません。Databricks はストレージ冗長性の構成を管理します。
AWS上では、Lakebaseはクラウドオブジェクトストレージ層としてAmazon S3にデータを永続化します。
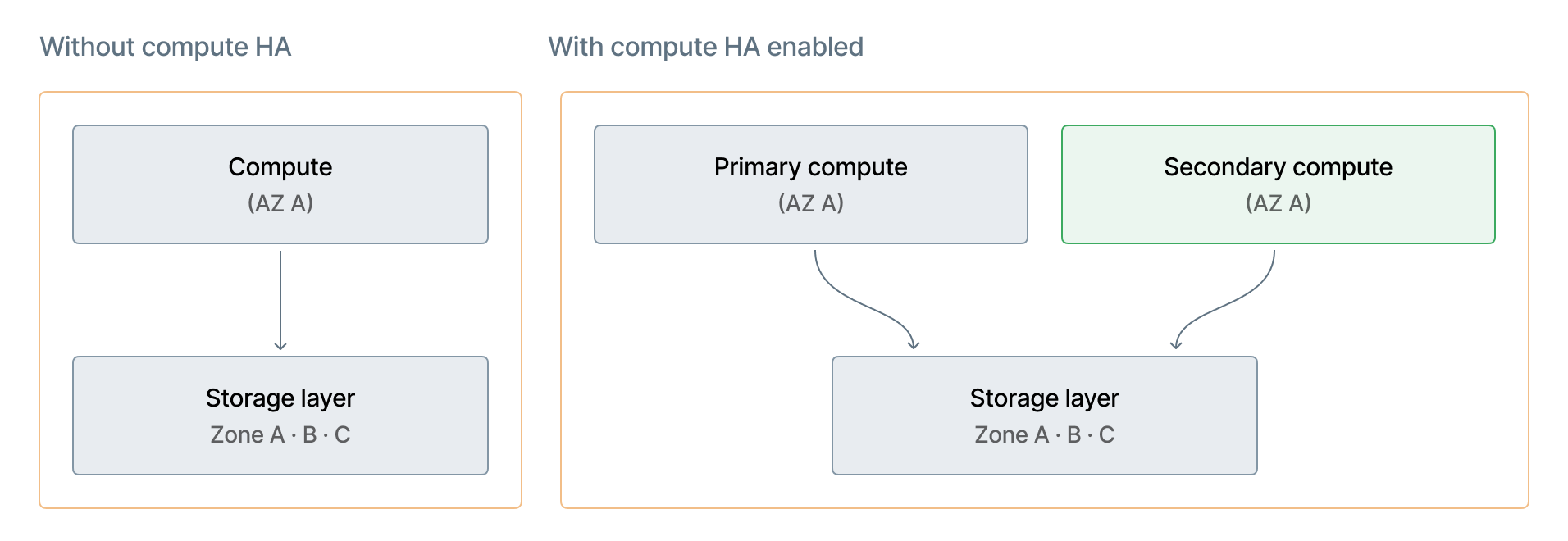
ストレージの冗長性はコンピュートの高可用性とは独立しています。
Lakebase のストレージの冗長性と可用性は Databricks によって管理されており、高可用性 (HA) コンピュート設定とは独立しています。HA を有効化または無効化しても、ストレージの冗長性には影響しません。
高可用性はコンピュート層の機能です。自動フェールオーバーのため、別の**アベイラビリティゾーン**にセカンダリ**コンピュート**インスタンスを**事前プロビジョニング**します。ストレージの冗長性とコンピュート HA は独立したレイヤーです。
characteristic | ストレージの冗長性 | コンピュート高可用性(HA) |
|---|---|---|
必須 | はい | No |
顧客設定可能 | No | はい |
保護されるもの | データの耐久性と可用性 | クエリー実行機能 |
ストレージ分離によって他の機能がどのように有効になるか
ストレージとコンピュートの分離により、いくつかのLakebase機能が可能になります。
- ゼロデータ損失 (RPO = 0): コミットされたすべてのトランザクションは、承認される前にクラウドオブジェクトストレージに永続的に保持されるため、コンピュートが失敗、再起動、ゼロにスケール、またはフェイルオーバーしても、コミットされたデータが失われることはありません。
- インスタントブランチ: Lakebase は共有ストレージに対してコピーオンライト方式でブランチを作成します。このプロセスではデータは重複しません。
- リードレプリカ: 複数のコンピュート インスタンスが同じ共有ストレージレイヤーから読み取ります。この方法では、データのレプリケーションは必要ありません。
- ゼロにスケーリング:コンピュートは停止しますが、ストレージは維持されます。コンピュートが再開されたとき、データはすぐに利用可能です。
- 高速フェールオーバー:ストレージはコンピュートとは分離されているため、フェールオーバーにはデータの移動が伴いません。 Lakebaseは、既存のストレージに接続するセカンダリコンピュートインスタンスを提供します。