同期されたテーブルでレイクハウスデータを提供する
同期されたテーブルを使用すると、Lakebase Postgres を通じてレイクハウス データを提供できます。Unity Catalog テーブルは Postgres に同期されるため、アプリケーションは低レイテンシでレイクハウス データを直接クエリできます。このプロセスは一般にリバース ETL と呼ばれます。レイクハウスは分析と強化のために最適化されており、Lakebase は高速なルックアップ スタイルのクエリとトランザクションの一貫性を必要とする運用ワークロード向けに設計されています。
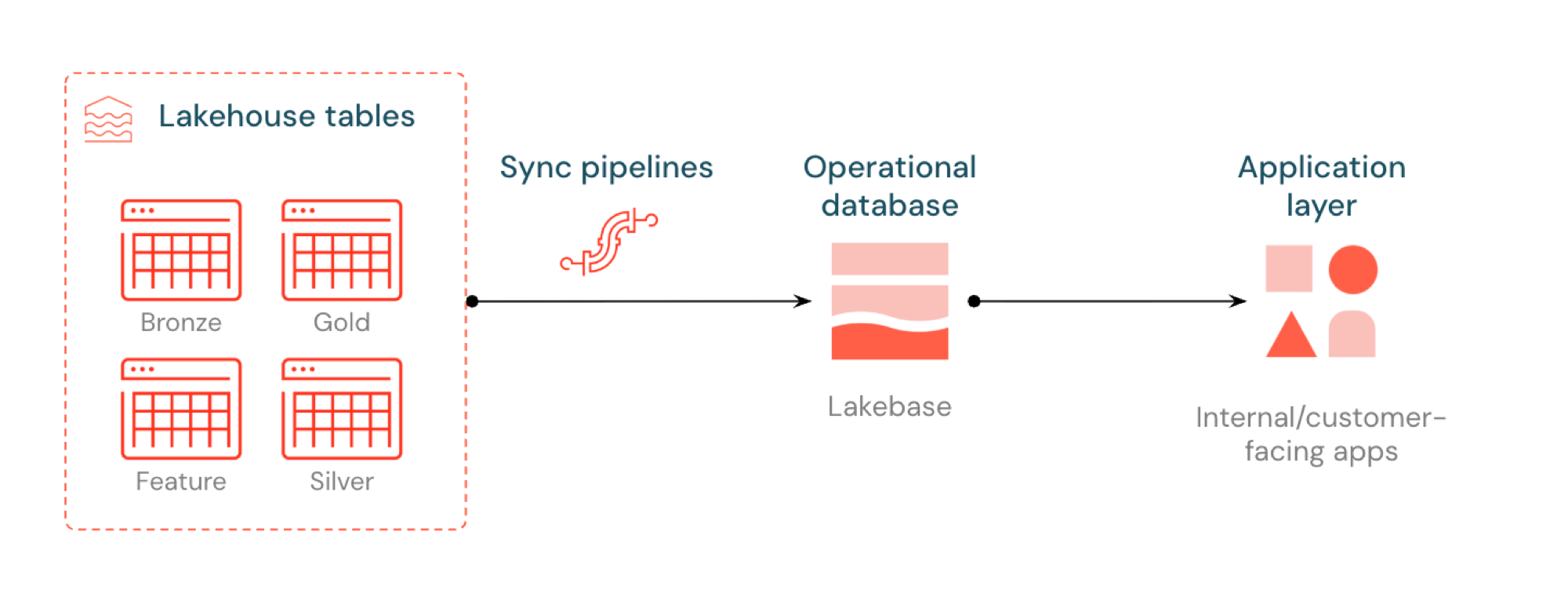
同期テーブルとは何ですか?
同期テーブルを使用するとUnity CatalogからLakebase Postgres を介してアナリティクス グレードのデータを提供できるため、低レイテンシのクエリと完全なACID必要とするアプリケーションでデータを利用できるようになります。 これらは、データをリアルタイムアプリケーションで利用できる状態に保つことで、分析用ストレージと運用システム間のギャップを埋めます。
サポートされているソース
同期されたテーブルは、次のUnity Catalogソース タイプをサポートします。
- 管理対象および外部Deltaテーブル
- 管理対象および外部の Iceberg テーブル
- ビューとマテリアライズドビュー
仕組み
Databricks 同期テーブルは、 Lakebase にUnity Catalogデータの管理されたコピーを作成します。 同期されたテーブルを作成すると、次のものが得られます。
- 同期パイプラインを参照する Unity Catalog 内の同期テーブル
- Lakebase の Postgres テーブル (読み取り専用、アプリケーションからクエリ可能)
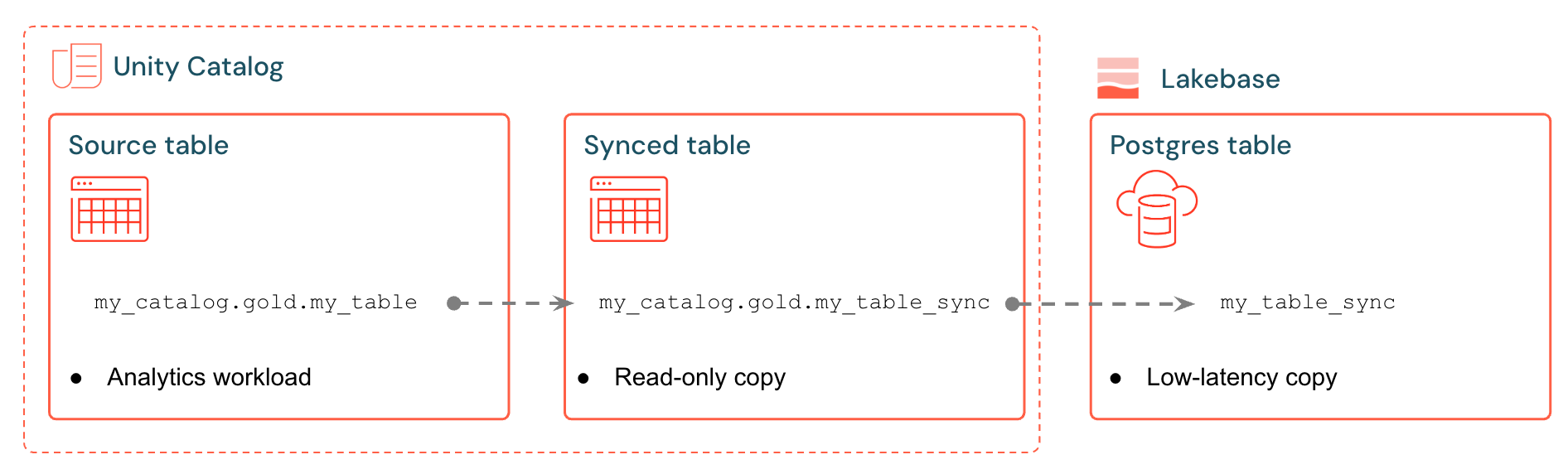
たとえば、ゴールド テーブル、エンジニアリングされた特徴、または ML 出力をanalytics.gold.user_profilesから新しい同期テーブルanalytics.gold.user_profiles_syncedに同期できます。Postgres では、Unity Catalog スキーマ名は Postgres スキーマ名になるため、 gold.user_profiles_syncedのように表示されます。
SELECT * FROM gold.user_profiles_synced WHERE user_id = 12345;
アプリケーションは標準の Postgres ドライバーに接続し、同期されたデータと自身の動作状態を照会します。
Postgres で同期テーブルを直接変更することは可能ですが、 Databricksソースによるデータ完全性を保護するために読み取りクエリのみを実行することを強くお勧めします。 同期テーブルでサポートされている操作については、 「Postgres の同期テーブルで許可されている操作」を参照してください。
同期パイプラインは、マネージドLakeFlow Pipelinesを使用して、Unity Catalog同期テーブルとPostgresテーブルの両方をソーステーブルからの変更で継続的に更新します。各同期は、Lakebaseデータベースへの最大16の接続を使用できます。
Lakebase Postgres は、トランザクション保証付きで最大 1,000 のライナー接続をサポートするため、アプリケーションはエンリッチデータを読み取りながら、同じデータベース内で挿入、更新、削除を処理できます。
同期モード
アプリケーションのニーズに応じて適切な同期モードを選択します。
モード | 説明 | いつ使うか | パフォーマンス |
|---|---|---|---|
スナップショット | すべてのデータの1回限りのコピー | ソースがサイクルごとに 10% を超える行を変更するか、ソースが CDF (ビュー、 Icebergテーブル) をサポートしていない | ソースデータの10%以上を変更する場合、10倍の効率化 |
トリガー | オンデマンドまたは一定間隔で実行されるスケジュール更新 | ソース行は既知の周期で変更されます。挿入、更新、削除は更新ごとに伝播されます。 | コストとラグのバランスが良い。5分間隔で実行すると高価になります |
連続 | 数秒の遅延でリアルタイムストリーミング | 変更はLakebaseにほぼリアルタイムで反映される必要がある | 遅延は最低、コストは最高。最小15秒間隔 |
トリガー モードと連続モードでは、ソース テーブルで変更データフィード (CDF) を有効にする必要があります。 CDF が有効になっていない場合、実行する正確なALTER TABLEコマンドを含む警告が UI に表示されます。変更データフィードの詳細については、 DatabricksでDelta Lake変更データフィードを使用するを参照してください。
CDF をサポートしていないソース (ビュー、マテリアライズドビュー、 Icebergテーブルなど) はスナップショット モードでのみ同期できます。 スナップショットモードの場合、ソースはSELECT *をサポートしている必要があります。
使用例
同期されたテーブルは、次のようなデータ提供のユースケースに使用できます。
- Databricks Appsに最新のユーザー プロファイルを提供するパーソナライゼーション エンジン
- モデル予測や特徴量を提供するアプリケーション レイクハウスのコンピュート
- KPIをリアルタイムで表示する顧客向けダッシュボード
- リスクスコアを提供し、即時の対応を可能にする不正行為検出サービス
- レイクハウスデータから強化された顧客レコードを提供するサポートツール
同期テーブルを作成する
前提条件
必要なもの:
- Lakebase が有効になっている Databricks ワークスペース。
- Lakebase プロジェクト (プロジェクトの作成を参照)。
- 同期するUnity Catalogテーブル。
- 同期テーブルを作成するための権限。使用するスキーマには、 USE_SCHEMA と CREATE_TABLE が必要です。
トリガー モード または 連続 モードの場合、ソース テーブルで変更データフィードを有効にする必要があります。
ALTER TABLE your_catalog.your_schema.your_table
SET TBLPROPERTIES (delta.enableChangeDataFeed = true)
容量計画とデータ型の互換性については、 「データ型と互換性」および「容量計画」を参照してください。
- UI
- CLI
- Python SDK
- Java SDK
- curl
-
ワークスペース サイドバーの [カタログ] に移動し、同期するUnity Catalogテーブルを選択します。
-
テーブルの詳細ビューから、 [作成] > [同期されたテーブル] をクリックします。
-
同期テーブルの作成 ダイアログで次の操作を行います。
カタログとスキーマのリストには、現在のユーザーが USE_SCHEMA および CREATE_TABLE 権限を持つ Unity Catalog スキーマのみが含まれます。期待するスキーマが表示されない場合は、カタログ管理者に権限を確認してください。
-
テーブル名 : 同期されたテーブルの名前を入力します (ソース テーブルと同じカタログとスキーマに作成されます)。これにより、Unity Catalog 同期テーブルとクエリ可能な Postgres テーブルの両方が作成されます。
-
データベースの種類 : Lakebase サーバレス (オートスケール) を選択します。
-
同期モード : ニーズに応じて、 スナップショット 、 トリガー 、または 連続を 選択します (上記の同期モードを参照)。
-
プロジェクト、ブランチ、データベースの選択を構成します。
-
主キーが 正しいことを確認します (通常は自動検出されます)。
-
同期されたテーブルでは、主キーの列はNULL値を許容しません。主キー列にNULL値を持つ行は 同期から除外されます 。
- (オプション)ソーステーブルで2つの行が同じ主キーを共有できる場合は、重複排除を設定するために 時系列キー を選択します。時系列キーが指定されている場合、同期されたテーブルには、各主キーに対して最新の時系列キー値を持つ行のみが含まれます。時系列キーがない障害モードについては、 「重複キー」を参照してください。
Triggered または Continuous モードを選択し、変更データフィードをまだ有効にしていない場合は、実行するための正確なコマンドを含む警告が表示されます。 データ型の互換性に関する質問については、 「データ型と互換性」を参照してください。
同期されたテーブルを作成するには、 [作成] をクリックします。 4. カタログ 内の同期済みテーブルを監視します。 概要 タブには、同期ステータス、構成、パイプラインステータス、および最終同期タイムスタンプが表示されます。手動で更新するには、 今すぐ同期 してください。
databricks postgres create-synced-table my-catalog.sales.orders \
--json '{
"spec": {
"source_table_full_name": "main.sales.orders",
"branch": "projects/my-project/branches/production",
"primary_key_columns": ["order_id"],
"scheduling_policy": "SNAPSHOT",
"postgres_database": "mydb",
"create_database_objects_if_missing": true
}
}'
SYNCED_TABLE_ID の位置引数は catalog.schema.table の形式を使用します。Postgresでは、テーブル {table} は、postgres_database (ここでは mydb) で設定したデータベース内のスキーマ {schema} で作成されます。コマンドは、デフォルトで操作が完了するのを待機します。利用可能なすべてのオプションについては、databricks postgres create-synced-tableを参照してください。
from databricks.sdk import WorkspaceClient
from databricks.sdk.service.postgres import (
SyncedTable,
SyncedTableSyncedTableSpec,
SyncedTableSyncedTableSpecSyncedTableSchedulingPolicy,
)
w = WorkspaceClient()
synced_table = w.postgres.create_synced_table(
synced_table=SyncedTable(spec=SyncedTableSyncedTableSpec(
source_table_full_name="main.sales.orders",
branch="projects/my-project/branches/production",
primary_key_columns=["order_id"],
scheduling_policy=SyncedTableSyncedTableSpecSyncedTableSchedulingPolicy.SNAPSHOT,
postgres_database="mydb",
create_database_objects_if_missing=True,
)),
synced_table_id="my-catalog.sales.orders",
).wait()
print(f"Synced table created: {synced_table.name}")
synced_table_idはcatalog.schema.table形式を使用し、 Unity Catalog同期テーブル名になります。 Postgresでは、 {table}テーブルは、 {schema}スキーマ内に作成され、 postgres_databaseで設定したデータベース(ここではmydb )内に配置されます。
import com.databricks.sdk.WorkspaceClient;
import com.databricks.sdk.service.postgres.*;
import java.util.List;
WorkspaceClient w = new WorkspaceClient();
SyncedTable syncedTable = w.postgres().createSyncedTable(
new CreateSyncedTableRequest()
.setSyncedTableId("my-catalog.sales.orders")
.setSyncedTable(new SyncedTable()
.setSpec(new SyncedTableSyncedTableSpec()
.setSourceTableFullName("main.sales.orders")
.setBranch("projects/my-project/branches/production")
.setPrimaryKeyColumns(List.of("order_id"))
.setSchedulingPolicy(SyncedTableSyncedTableSpecSyncedTableSchedulingPolicy.SNAPSHOT)
.setPostgresDatabase("mydb")
.setCreateDatabaseObjectsIfMissing(true))))
.waitForCompletion();
System.out.println("Synced table created: " + syncedTable.getName());
curl -X POST "https://your-workspace.cloud.databricks.com/api/2.0/postgres/synced_tables?synced_table_id=my-catalog.sales.orders" \
-H "Authorization: Bearer ${DATABRICKS_TOKEN}" \
-H "Content-Type: application/json" \
-d '{
"spec": {
"source_table_full_name": "main.sales.orders",
"branch": "projects/my-project/branches/production",
"primary_key_columns": ["order_id"],
"scheduling_policy": "SNAPSHOT",
"postgres_database": "mydb",
"create_database_objects_if_missing": true
}
}'
これは、実行時間の長い操作を返します。返されたnameフィールドをdone: trueになるまでポーリングします。長時間実行される操作を参照してください。認証設定については、 「認証」を参照してください。
後続の同期をスケジュールまたはトリガーする
初期スナップショットは作成時に自動的に実行されます。 スナップショット モード と トリガー モードの場合、後続の同期は明示的にトリガーする必要があります。 連続 モードは自己管理されます。
データベーステーブル同期パイプラインタスク
LakeFlow Jobs の Database Table Sync パイプライン タスクは、同期されたテーブルのパイプラインをワークフロー ステップとして実行します。 テーブル更新トリガーまたはスケジュールを使用してジョブを構成します。
ソーステーブルの更新時にトリガーする
ソースUnity Catalogテーブルが更新されたときにジョブを起動します。 トリガー モードでは、新しい変更のみが段階的に適用されるため、継続モードのような常時オンのコストをかけずに、ほぼリアルタイムの最新状態が提供されます。
- サイドバーで、 ワークフロー をクリックします。
- [ジョブの作成] をクリックするか、既存のジョブを開きます。
- [タスク] タブで、 [+ 別のタスク タイプを追加] をクリックします。
- [取り込みと変換] の下で、 [データベース テーブル同期パイプライン] を選択します。
- [パイプライン] フィールドで、同期テーブルに関連付けられたパイプラインを選択します。
- [スケジュールとトリガー] の下で、 [トリガーの追加] をクリックします。
- トリガー タイプとして テーブル更新を 選択します。
- [テーブル] の下で、監視するソースUnity Catalogテーブルを選択します。
- 保存 をクリックします。
スケジュールに従ってトリガーする
一定のリズムで同期を実行します。夜間または毎週の完全更新が最も効率的なパターンとなる スナップショット モードに適しています。
- 上記のステップ 1 ~ 5 に従って、 Database Table Sync パイプライン タスクをジョブに追加します。
- [スケジュールとトリガー] の下で、 [トリガーの追加] をクリックします。
- トリガー タイプとして [スケジュール済み] を選択します。
- cron スケジュールとタイムゾーンを設定し、 「保存」 をクリックします。
同期ステータスを確認する
同期済みテーブルの現在の状態と最終同期時刻を確認するには:
- UI
- Python SDK
- Java SDK
- curl
カタログ で、同期済みのテーブルに移動し、 「概要」 タブを選択します。現在の同期状態、パイプラインの状態、および最終同期のタイムスタンプが表示されます。
from databricks.sdk import WorkspaceClient
w = WorkspaceClient()
table = w.postgres.get_synced_table("synced_tables/my-catalog.sales.orders")
print(f"State: {table.status.detailed_state}")
print(f"Last sync: {table.status.last_sync_time}")
print(f"Message: {table.status.message}")
import com.databricks.sdk.WorkspaceClient;
import com.databricks.sdk.service.postgres.SyncedTable;
WorkspaceClient w = new WorkspaceClient();
SyncedTable table = w.postgres().getSyncedTable("synced_tables/my-catalog.sales.orders");
System.out.println("State: " + table.getStatus().getDetailedState());
System.out.println("Last sync: " + table.getStatus().getLastSyncTime());
System.out.println("Message: " + table.getStatus().getMessage());
curl "https://your-workspace.cloud.databricks.com/api/2.0/postgres/synced_tables/my-catalog.sales.orders" \
-H "Authorization: Bearer ${DATABRICKS_TOKEN}"
データ型と互換性
同期されたテーブルを作成するときに、Unity Catalog データ型は Postgres 型にマッピングされます。複合型 (ARRAY、MAP、STRUCT) は、Postgres では JSONB として保存されます。
ソース列タイプ | Postgresの列タイプ |
|---|---|
BIGINT | BIGINT |
バイナリ | バイト |
ブール値 | ブール値 |
DATE | DATE |
DECIMAL(p,s) | NUMERIC |
DOUBLE | DOUBLE PRECISION |
FLOAT | REAL |
INT | INTEGER |
INTERVAL | INTERVAL |
SMALLINT | SMALLINT |
STRING | TEXT |
TIMESTAMP | TIMESTAMP WITH TIME ZONE |
TIMESTAMP_NTZ | TIMESTAMP WITHOUT TIME ZONE |
TINYINT | SMALLINT |
ARRAY<elementType> | JSONB |
MAP<keyType,valueType> | JSONB |
STRUCT<fieldName:fieldType[, ...]> | JSONB |
GEOGRAPHY、GEOMETRY、VARIANT、および OBJECT タイプはサポートされていません。
無効な文字を処理する
ヌル バイト (0x00) などの特定の文字は、 Unity Catalog文字列、ARRAY、MAP、または STRUCT 列では許可されますが、Postgres のTEXTまたは JSONB 列ではサポートされません。 これにより、次のようなエラーが発生し、同期が失敗する可能性があります。
ERROR: invalid byte sequence for encoding "UTF8": 0x00
ERROR: unsupported Unicode escape sequence DETAIL: \u0000 cannot be converted to text
- 最初のエラーは、トップレベルの文字列列にヌルバイトが現れた場合に発生します。これは、Postgres
TEXTに直接マッピングされます。 - 2 番目のエラーは、
STRUCT、ARRAY、またはMAPの複合型の中にネストされた文字列にヌルバイトが現れた場合に発生し、JSONBとしてシリアル化されます。シリアライズ中、すべての文字列はPostgresTEXTにキャストされますが、\u0000は許可されていません。
ソリューション:
-
文字列フィールドをサニタイズ : 同期する前にサポートされていない文字を削除します。文字列列の null バイトの場合:
SQLSELECT REPLACE(column_name, CAST(CHAR(0) AS STRING), '') AS cleaned_column FROM your_table -
BINARY に変換 : 生のバイトを保持する必要がある文字列列の場合は、BINARY 型に変換します。
キャパシティプランニング
同期されたテーブルの実装を計画するときは、次のリソース要件を考慮してください。
- 接続使用量 : 同期された各テーブルは、Lakebase データベースへの接続を最大 16 個使用します。これはインスタンスの接続制限にカウントされます。
- サイズクォータ :同期されているすべてのテーブルの論理データ合計は16TBのクォータです。より大きなクォータが必要な場合は、Databricks サポートにお問い合わせください。個々のテーブルにクォータはありませんが、Databricks は、更新が必要なテーブルでは 1TB を超えないことを推奨しています。
- フル更新サイズ : フル更新をトリガーしても、新しい同期が完了するまでPostgresの古いバージョンは削除されません。更新中、両方のバージョンが一時的に論理データベース サイズのクォータに計上されます。
- ソースごとのテーブル数 :1つのソーステーブルには、最大20個の同期テーブルを含めることができます。
- 命名要件 : データベース、スキーマ、およびテーブル名には、英数字とアンダースコア (
[A-Za-z0-9_]+) のみを含めることができます。 - コレクション識別子に関するガイダンス :コレクションUnity Catalogテーブルの列名またはテーブル名には、大文字や特殊文字を使用しないでください。 それらの識別子を保持する場合は、Postgresで参照する際に引用符で囲む必要があります。
- スキーマ進化 : トリガー モードと連続モードでは、追加的なスキーマ変更 (列の追加など) のみがサポートされています。
- 重複キー : ソース テーブルで 2 つの行が同じ主キーを持っている場合、時系列キーを使用して重複排除を構成しない限り、同期パイプラインは失敗します。
- API冪等性 :同期テーブルAPIs冪等性を持つため、一時的なエラーが発生した場合は再試行して、タイムリーな操作を保証します。
- 更新レート : Lakebaseオートスケールの場合、同期パイプラインは、キャパシティー ユニット (CU) あたり 1 秒あたり約 150 行の連続書き込みとトリガー書き込み、および CU あたり 1 秒あたり最大 2,000 行のスナップショット書き込みをサポートします。
Postgres の同期テーブルで許可される操作
Databricks では、誤って上書きしたりデータの不整合が生じたりしないように、同期されたテーブルに対して Postgres で次の操作のみを実行することを推奨しています。
- 読み取り専用クエリ
- インデックスの作成
- テーブルを削除する( Unity Catalogから同期されたテーブルを削除した後、スペースを解放するため)
Postgres で同期されたテーブルを他の方法で変更することは可能ですが、同期パイプラインに干渉します。
所有権と許可
同期されたテーブルは、内部の databricks_writer_<dbid> ロールによって所有され、作成したユーザーによっては所有されません。これは同期パイプラインが管理しているためです(Postgres ロールを参照してください)。行レベルセキュリティの構成のような所有者のみのコマンドは、同期されたテーブルで直接実行することはできません。
これは一般的なPostgresのルールに対する例外で、作成したオブジェクトは、そのログインがPostgresにロールとして存在する場合、Databricks IDが所有します。パイプラインはユーザーに代わって同期されたテーブルを作成します。
同期テーブルを作成するユーザーのアクセス
同期されたテーブルを作成すると、お客様の Databricks ID は自動的に使用するためのアクセス権が付与されます。databricks_superuser の対応は必要ありません。同期されたテーブルに対して、お客様のIDに次の特権が付与されます。
オブジェクト | 権限 | 目的 |
|---|---|---|
同期テーブル |
| テーブルの読み取りまたはクリア |
スキーマ |
| スキーマを使用し、インデックスなどのオブジェクトを作成します |
INSERT または UPDATE は付与されていません。パイプラインがテーブルのデータを所有しているため、直接書き込みは次回の更新時に上書きされます。DELETE と TRUNCATE はテーブルのみをクリアします。次回の更新で、ソースからテーブルにデータが再投入されます。
このアクセスは、同期されたテーブルに対する Unity Catalog の権限に由来し、Unity Catalog で管理されます。変更するには、ユーザーの Unity Catalog 権限を更新します。Postgres で Databricks ID から直接 REVOKEすることはできません。
このアクセスは、同期テーブルを作成したIDに結び付けられています。パイプラインの 実行ユーザー の変更では、再割り当ては行われません。別の所有者IDを使用するには、そのIDで同期テーブルを再作成します。
同期テーブルへのアクセスを管理する
同期テーブルが作成されると、 databricks_superuserは Postgres から同期テーブルを読み取ることができます。databricks_superuserにはpg_read_all_dataがあり、これによりこのロールはすべてのテーブルから読み取ることができます。また、このロールにはpg_write_all_data権限があり、これによりこのロールはすべてのテーブルに書き込むことができます。これは、 databricks_superuserが Postgres の同期テーブルにも書き込むことができることを意味します。Lakebaseは、対象テーブルに緊急の変更を加える必要がある場合に備えて、このような書き込み動作をサポートしています。しかし、Databricksはソーステーブルを修正することを推奨しています。
-
databricks_superuserは、他のユーザーに以下の権限を付与することもできます。SQLGRANT USAGE ON SCHEMA synced_table_schema TO user;SQLGRANT SELECT ON synced_table_name TO user; -
databricks_superuserはこれらの権限を取り消すことができます。SQLREVOKE USAGE ON SCHEMA synced_table_schema FROM user;SQLREVOKE {SELECT | INSERT | UPDATE | DELETE} ON synced_table_name FROM user;
同期テーブル操作を管理する
databricks_superuserは、同期テーブルに対して特定の操作を実行する権限を持つユーザーを管理できます。同期テーブルでサポートされている操作は次のとおりです。
CREATE INDEXALTER INDEXDROP INDEXDROP TABLE
同期テーブルに対しては、その他のすべてのDDL操作は拒否されます。
これらの権限を他のユーザーに付与するには、 databricks_superuserはまずdatabricks_auth上に拡張機能を作成する必要があります。
CREATE EXTENSION IF NOT EXISTS databricks_auth;
次に、 databricks_superuserは同期テーブルを管理するユーザーを追加できます。
SELECT databricks_synced_table_add_manager('"synced_table_schema"."synced_table"'::regclass, '[user]');
databricks_superuserは、同期テーブルの管理からユーザーを削除できます。
SELECT databricks_synced_table_remove_manager('[table]', '[user]');
databricks_superuserはすべてのマネージャーを表示できます:
SELECT * FROM databricks_synced_table_managers;
同期されたテーブルを削除する
Unity Catalogから同期済みのテーブルを削除すると、対応するPostgresテーブルも削除されます。
- UI
- Python SDK
- Java SDK
- curl
カタログ で、同期されたテーブルを見つけて、![]() メニューを開き、 「削除」 を選択します。
メニューを開き、 「削除」 を選択します。
from databricks.sdk import WorkspaceClient
w = WorkspaceClient()
w.postgres.delete_synced_table("synced_tables/my-catalog.sales.orders").wait()
import com.databricks.sdk.WorkspaceClient;
WorkspaceClient w = new WorkspaceClient();
w.postgres().deleteSyncedTable("synced_tables/my-catalog.sales.orders").waitForCompletion();
curl -X DELETE "https://your-workspace.cloud.databricks.com/api/2.0/postgres/synced_tables/my-catalog.sales.orders" \
-H "Authorization: Bearer ${DATABRICKS_TOKEN}"
もっと詳しく知る
タスク | 説明 |
|---|---|
Lakebaseプロジェクトを設定する | |
Lakebaseの接続オプションについて | |
Lakebase データを Unity Catalog で表示して、統合ガバナンスとクロスソースクエリを実現します。 | |
ガバナンスと権限を理解する |
カタログ統合
- カタログの複製: 標準カタログで、別のデータベースカタログとしても登録されているPostgresデータベースを対象とした同期テーブルを作成すると、その同期テーブルはUnity Catalog標準カタログとデータベースカタログの両方に表示されます。
その他のオプション
Databricks 以外のシステムにデータを同期する場合は、Census や Hightouch などのPartner Connect リバース ETL ソリューションを参照してください。