ワークスペースデータをエクスポートする
このページでは、Databricks ワークスペースからデータと構成をエクスポートするためのツールとアプローチの概要を説明します。コンプライアンス要件、データの移植性、バックアップ目的、またはワークスペースの移行のために、ワークスペース アセットをエクスポートできます。
概要
Databricksワークスペースには、ワークスペース構成、マネージドテーブル、 AIおよびMLオブジェクト、クラウドストレージに保存されたデータなど、さまざまな資産が含まれています。 ワークスペース データをエクスポートする必要がある場合、組み込みツールとAPIs組み合わせて使用して、これらの資産を体系的に抽出できます。
ワークスペース データをエクスポートする一般的な理由は次のとおりです。
- コンプライアンス要件 : GDPR や CCPA などの規制に基づくデータ移植義務を満たす。
- バックアップとディザスタリカバリ : ビジネス継続のために重要なワークスペース資産のコピーを作成します。
- ワークスペース移行 : ワークスペースまたはクラウドプロバイダー間で資産を移動すること。
- 監査とアーカイブ : ワークスペースの構成とデータの履歴レコードを保存します。
エクスポートを計画する
ワークスペース データのエクスポートを開始する前に、エクスポートする必要があるアセットのインベントリを作成し、それらの間の依存関係を理解しておきます。
ワークスペースの資産を理解する
Databricks ワークスペースには、エクスポートできる資産のカテゴリがいくつか含まれています。
- ワークスペース構成 : ノートブック、フォルダー、リポジトリ、シークレット、ユーザー、グループ、アクセス制御リスト (ACL)、クラスター構成、およびジョブ定義。
- データ資産 : マネージドテーブル、データベース、 Databricks File System ファイル、およびクラウド ストレージに保存されたデータ。
- コンピュート リソース : クラスター構成、ポリシー、およびインスタンス プールの定義。
- AI と機械学習アセット :MLflow エクスペリメント、実行、モデル、Feature Store のテーブル、AI Search のインデックス、Unity Catalog のモデル
- Unity Catalogオブジェクト : メタストア構成、カタログ、スキーマ、テーブル、ボリューム、および権限。
エクスポートの範囲を定める
要件に基づいてエクスポートする資産のチェックリストを作成します。次の質問について考えてみましょう。
- すべてのアセットをエクスポートする必要がありますか、それとも特定のカテゴリのみをエクスポートする必要がありますか?
- どの資産をエクスポートする必要があるかを規定するコンプライアンス要件またはセキュリティ要件はありますか?
- アセット間の関係 (たとえば、ノートブックを参照するジョブ) を保持する必要がありますか?
- 別の環境でワークスペース構成を再作成する必要がありますか?
エクスポート範囲を計画すると、適切なツールを選択し、重要な依存関係の見落としを回避するのに役立ちます。
ワークスペース構成をエクスポートする
Terraform エクスポーターは、ワークスペース構成をエクスポートするための主要なツールです。ワークスペース アセットをコードとして表す Terraform 構成ファイルを生成します。
Terraformエクスポーターを使用する
Terraform エクスポーターは、Databricks Terraform プロバイダーに組み込まれており、ノートブック、ジョブ、クラスター、ユーザー、グループ、シークレット、アクセス制御リストなどのワークスペース リソースの Terraform 構成ファイルを生成します。エクスポーターはワークスペースごとに個別に実行する必要があります。Databricks Terraform プロバイダーを参照してください。
前提条件:
- マシンにTerraformがインストールされている
- Databricks認証が設定されている
- エクスポートするワークスペースの管理者権限
ワークスペース リソースをエクスポートするには:
-
エクスポーターのチュートリアルについては、使用例のビデオを確認してください。
-
エクスポータ ツールを使用して Terraform プロバイダーをダウンロードしてインストールします。
Bashwget -q -O terraform-provider-databricks.zip $(curl -s https://api.github.com/repos/databricks/terraform-provider-databricks/releases/latest|grep browser_download_url|grep linux_amd64|sed -e 's|.*: "\([^"]*\)".*$|\1|')
unzip -d terraform-provider-databricks terraform-provider-databricks.zip -
ワークスペースの認証環境変数を設定します。
Bashexport DATABRICKS_HOST=https://your-workspace-url
export DATABRICKS_TOKEN=your-token -
エクスポーターを実行して、Terraform 構成ファイルを生成します。
Bashterraform-provider-databricks exporter \
-directory ./exported-workspace \
-listing notebooks,jobs,clusters,users,groups,secrets一般的なエクスポーターのオプション:
-listing: エクスポートするリソースの種類を指定します(カンマ区切り)-services: リソースをフィルタリングするためのリストの代替-directory: 生成された.tfファイルの出力ディレクトリ-incremental: 段階的な移行では増分モードで実行します
-
出力ディレクトリに生成された
.tfファイルを確認します。エクスポータは、リソース タイプごとに 1 つのファイルを作成します。
Terraform エクスポーターは、ワークスペースの構成とメタデータに重点を置いています。テーブルまたは Databricks ファイル システムに保存されている実際のデータはエクスポートされません。次のセクションで説明する方法を使用して、データを個別にエクスポートする必要があります。
特定の資産タイプをエクスポートする
Terraform エクスポーターで完全にカバーされていないアセットの場合は、次の方法を使用します。
- ノートブック : ワークスペース UI からノートブックを個別にダウンロードするか、ワークスペースAPIを使用してプログラム的にノートブックをエクスポートします。 「ワークスペース オブジェクトの管理」を参照してください。
- シークレット : セキュリティ上の理由から、シークレットを直接エクスポートすることはできません。ターゲット環境でシークレットを手動で再作成する必要があります。参照用に秘密の名前とスコープを文書化します。
- MLflowオブジェクト : mlflow-export-import ツールを使用して、体験、実行、およびモデルをエクスポートします。 以下のML アセットのセクションを参照してください。
データをエクスポートする
通常、顧客データは Databricks ではなく、クラウド アカウント ストレージに保存されます。クラウド ストレージにすでに存在するデータをエクスポートする必要はありません。ただし、Databricks が管理する場所に保存されているデータはエクスポートする必要があります。
マネージドテーブルのエクスポート
マネージドテーブルはクラウド ストレージ内に存在しますが、解析が難しい UUID ベースの階層に保存されています。 DEEP CLONEコマンドを使用すると、指定した場所にあるマネージドテーブルを外部テーブルとして書き換えることができ、操作が容易になります。
例: DEEP CLONEコマンド:
CREATE TABLE delta.`s3://path/to/storage/`
DEEP CLONE my_catalog.my_schema.my_table
カタログのリスト内のすべてのテーブルを複製する完全なスクリプトについては、以下のサンプル スクリプトを参照してください。
Databricksのデフォルトストレージをエクスポートする
サーバーレス ワークスペースの場合、 Databricks Databricksアカウント内のフルマネージド ストレージ ソリューションであるデフォルトストレージを提供します。 ワークスペースを削除または廃止する前に、デフォルト ストレージ内のデータを顧客所有のストレージ コンテナーにエクスポートする必要があります。サーバレス ワークスペースの詳細については、 「サーバレス ワークスペースの作成」を参照してください。
デフォルト ストレージ内のテーブルの場合、 DEEP CLONEを使用して、顧客所有のストレージ コンテナーにデータを書き込みます。ボリュームおよび任意のファイルについては、以下のDBFSルート エクスポート セクションで説明されているのと同じパターンに従います。
Databricks ファイル システムのルートをエクスポートする
新しいワークフローでは、Databricks File Systemではなく、Unity Catalogボリュームまたはワークスペース ファイル システムにデータを格納することをお勧めします。このページでは、既存のDatabricks ファイルシステムデータをお持ちのユーザー向けのDatabricks ファイルシステムエクスポートについて説明します。
Databricksファイル システムのルートは、顧客が所有する資産、ユーザーのアップロード、init スクリプト、ライブラリ、およびテーブルが含まれる可能性があるワークスペース ストレージ バケット内のレガシー ストレージの場所です。 Databricks ファイル システム ルートは非推奨のストレージ パターンですが、従来のワークスペースでは、エクスポートする必要があるデータがこの場所にまだ保存されている可能性があります。ワークスペース ストレージ アーキテクチャの詳細については、 「ワークスペース ストレージ」を参照してください。
Databricks ファイル システムのルート バケットをエクスポートします 。
AWS CLI を使用して、Databricks ワークスペース ストレージ バケットの場所からエクスポート バケットにデータを同期します。
# Export from DBFS root bucket to export bucket
aws s3 sync s3://databricks-workspace-bucket/dbfs/ s3://export-bucket/dbfs-export/
Databricks ファイル システムのルート バケットが AWS KMS によるサーバー側暗号化を使用している場合は、エクスポート バケットに適切な暗号化構成と KMS キーにアクセスするためのアクセス許可があることを確認してください。
クラウド ストレージから大量のデータをエクスポートすると、データ転送とストレージに多大なコストが発生する可能性があります。大規模なエクスポートを開始する前に、クラウド プロバイダーの価格を確認してください。
一般的なエクスポートの課題
バケットの暗号化:
ワークスペース ストレージ バケットでサーバー側の暗号化が使用されている場合は、いくつかの方法があります。
- 安心S3暗号化 : S3すべてのデータを安全に暗号化します。 これはユーザーには透過的であるため、追加のステップは必要ありません。
- AWS 管理キーによる KMS 暗号化 : AWS がキー、暗号化、復号化を管理します。追加のステップは必要ありません。
- カスタム KMS キーを使用した KMS 暗号化 : 暗号化は S3 によって処理されますが、バケット内のデータを読み取るには、キーにアクセスする権限が必要です。ターゲット バケット内の同じキーにアクセスできること、およびエクスポート バケットに適切な暗号化構成があることを確認します。
秘密:
セキュリティ上の理由から、シークレットを直接エクスポートすることはできません。-export-secretsオプションを指定した Terraform エクスポーターを使用すると、エクスポーターはシークレットと同じ名前の変数をvars.tfに生成します。このファイルを実際のシークレット値で手動で更新するか、 -export-secretsオプション (Databricks 管理のシークレットの場合のみ) を使用して Terraform エクスポーターを実行する必要があります。
AIおよびMLアセットのエクスポート
一部の AI および ML アセットでは、エクスポートに異なるツールとアプローチが必要です。Unity Catalogモデルは、 Terraformエクスポーターの一部としてエクスポートされます。
MLflowオブジェクト
MLflow は、API のギャップとシリアル化の難しさのため、Terraform エクスポーターではカバーされていません。MLflowエクスペリメント、実行、モデル、およびアーティファクトをエクスポートするには、 mlflow-export-importツールを使用します。 このオープンソース ツールは、MLflow 移行のほぼ完全なカバレッジを提供します。
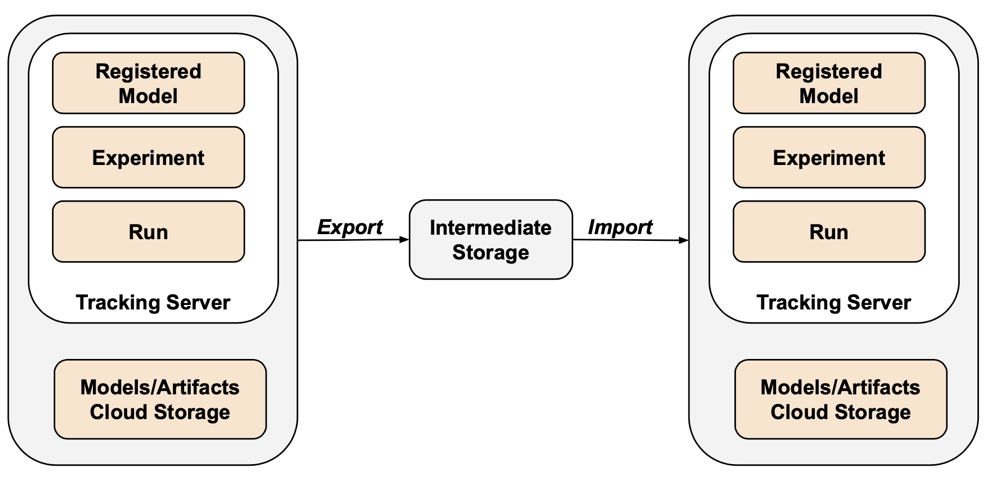
エクスポートのみのシナリオの場合、インポート ステップを実行する必要なく、カスタマー所有のバケット内にすべてのMLflowアセットを保存できます。 MLflow管理の詳細については、 Unity Catalogでモデルのライフサイクルを管理する」を参照してください。
Feature Store と AI 検索
AI検索インデックス : AI検索インデックスはEUデータエクスポート手続きの範囲には含まれていません。それでもエクスポートしたい場合は、標準テーブルに書き込んでから、DEEP CLONEを使用してエクスポートする必要があります。
Feature Store テーブル : Feature Store は AI 検索インデックスと同様に扱う必要があります。SQL を使用して、関連データを選択し、標準テーブルに書き込み、その後に DEEP CLONE を使用してエクスポートします。
エクスポートされたデータを検証する
ワークスペース データをエクスポートした後、古い環境を廃止する前に、ジョブ、ユーザー、ノートブック、その他のリソースが正しくエクスポートされたことを確認します。スコープ設定および計画フェーズで作成したチェックリストを使用して、エクスポートする予定のものがすべて正常にエクスポートされたことを確認します。
検証チェックリスト
次のチェックリストを使用してエクスポートを検証します。
- 生成される構成ファイル : 必要なすべてのワークスペース リソースに対して Terraform 構成ファイルが作成されます。
- ノートブックのエクスポート : すべてのノートブックは、コンテンツとメタデータをそのままの状態でエクスポートされます。
- 複製されたテーブル : マネージドテーブルはエクスポート場所に正常に複製されました。
- コピーされたデータ ファイル : クラウド ストレージのデータはエラーなく完全にコピーされます。
- エクスポートされるMLflowオブジェクト : 体験、実行、モデルはアーティファクトとともにエクスポートされます。
- 文書化された権限 : アクセス制御リストと権限は、Terraform 構成でキャプチャされます。
- 識別された依存関係 : アセット間の関係 (たとえば、ノートブックを参照するジョブ) はエクスポートで保持されます。
エクスポート後のベストプラクティス
検証および受け入れテストは主に要件によって決まり、大きく異なる可能性があります。ただし、次の一般的なベスト プラクティスが適用されます。
- テストベッドを定義する : エクスポートされた環境でシークレット、データ、マウント、コネクタ、およびその他の依存関係が正しく動作していることを検証するジョブまたはノートブックのテストベッドを作成します。
- 開発環境から開始する : 段階的に移行する場合は、開発環境から開始し、本番運用まで作業を進めます。 これにより、重大な問題が早期に表面化し、本番運用への影響が回避されます。
- Git フォルダーを活用する : 可能な場合は、Git フォルダーを使用します。これは、Git フォルダーが外部の Git リポジトリに存在するためです。これにより、手動によるエクスポートが回避され、環境間でコードが同一であることが保証されます。
- エクスポート プロセスを文書化します 。使用したツール、実行したコマンド、発生した問題を記録します。
- エクスポートされたデータのセキュリティ保護 : 特に機密情報や個人を特定できる情報が含まれている場合は、エクスポートされたデータが適切なアクセス制御を使用して安全に保存されていることを確認します。
- コンプライアンスの維持 : コンプライアンス目的でエクスポートする場合は、エクスポートが規制要件と保持ポリシーを満たしていることを確認します。
サンプルスクリプトと自動化
スクリプトとスケジュールされたジョブを使用してワークスペースのエクスポートを自動化できます。
ディープクローンエクスポートスクリプト
次のスクリプトは、 DEEP CLONEを使用してUnity Catalogマネージドテーブルをエクスポートします。 特定のカタログを中間バケットにエクスポートするには、このコードをソース ワークスペースで実行する必要があります。catalogs_to_copyおよびdest_bucket変数を更新します。
import pandas as pd
# define catalogs and destination bucket
catalogs_to_copy = ["my_catalog_name"]
dest_bucket = "<cloud-storage-path>://my-intermediate-bucket"
manifest_name = "manifest"
# initialize vars
system_info = sql("SELECT * FROM system.information_schema.tables")
copied_table_names = []
copied_table_types = []
copied_table_schemas = []
copied_table_catalogs = []
copied_table_locations = []
# loop through all catalogs to copy, then copy all non-system tables
# note: this would likely be parallelized using thread pooling in prod
for catalog in catalogs_to_copy:
filtered_tables = system_info.filter((system_info.table_catalog == catalog) & (system_info.table_schema != "information_schema"))
for table in filtered_tables.collect():
schema = table['table_schema']
table_name = table['table_name']
table_type = table['table_type']
print(f"Copying table {schema}.{table_name}...")
target_location = f"{dest_bucket}/{catalog}_{schema}_{table_name}"
sqlstring = f"CREATE TABLE delta.`{target_location}` DEEP CLONE {catalog}.{schema}.{table_name}"
sql(sqlstring)
# lists used to create manifest table DF
copied_table_names.append(table_name)
copied_table_types.append(table_type)
copied_table_schemas.append(schema)
copied_table_catalogs.append(catalog)
copied_table_locations.append(target_location)
# create the manifest as a df and write to a table in dr target
# this contains catalog, schema, table and location
manifest_df = pd.DataFrame({"catalog": copied_table_catalogs,
"schema": copied_table_schemas,
"table": copied_table_names,
"location": copied_table_locations,
"type": copied_table_types})
spark.createDataFrame(manifest_df).write.mode("overwrite").format("delta").save(f"{dest_bucket}/{manifest_name}")
display(manifest_df)
自動化に関する考慮事項
エクスポートを自動化する場合:
- スケジュールされたジョブを使用する : 定期的なスケジュールでエクスポート スクリプトを実行する Databricks ジョブを作成します。
- エクスポート ジョブを監視する : エクスポートが失敗したり、予想よりも時間がかかったりした場合に通知するアラートを構成します。
- 資格情報の管理 : Databricks シークレットを使用して、クラウド ストレージの資格情報と API トークンを安全に保存します。「秘密管理」を参照してください。
- バージョン エクスポート : エクスポート パスでタイムスタンプまたはバージョン番号を使用して、履歴エクスポートを維持します。
- 古いエクスポートをクリーンアップする : 保持ポリシーを実装して、古いエクスポートを削除し、ストレージ コストを管理します。
- 増分エクスポート : 大規模なワークスペースの場合は、前回のエクスポート以降に変更されたデータのみをエクスポートする増分エクスポートの実装を検討してください。