Databricks でホストされている RStudio サーバーに接続する
Databricks がホストする RStudio Server は非推奨であり、Databricks Runtime バージョン 15.4 以下でのみ使用できます。その他のオプションについては、 「ホストされた RStudio Server の代替手段」を参照してください。
Webブラウザーを使用して Databricks ワークスペースにサインインし、そのワークスペース内でRStudio Server がインストールされているDatabricksコンピュートに接続します。
ホストされたRStudio Server の場合は、 Databricksのオープンソース (OS) エディションまたはRStudio Workbench (以前のRStudio Server Pro) エディションを使用できます。 RStudio Workbench (RStudio Server Pro) を使用する場合は、既存の RStudio Workbench (RStudio Server Pro) ライセンスを Databricks に転送する必要があります。RStudio Workbench (旧称 RStudio Server Pro)を参照してください。
Databricksでは、コンピュートの開始時間を短縮するために、RStudio Server とDatabricksコンピュートでDatabricks機械学習ランタイムを使用することをお勧めします。Databricks Runtime ML には、 RStudio Server オープンソース エディション パッケージの未変更バージョンが含まれています。 このパッケージのソースコードは GitHub にあります。 次の表は、Databricks機械学習ランタイムバージョンにプリインストールされているRStudio Serverオープンソースエディション のバージョンの一覧です。
Databricks機械学習ランタイムバージョン | RStudio サーバーのバージョン |
|---|---|
Databricks Runtime 9.1 LTS ML および 10.4 LTS ML | 1.4 |
RStudio サーバー オープンソース (OS)
RStudio Server オープンソースは、 Databricks Runtime for Machine Learning ( Databricks Runtime ML ) を使用するDatabricksクラスターにプレインストールされています。
要件
-
クラスターは汎用クラスターである必要があります。
-
そのクラスターに対する Can Attach To 権限が必要です。 クラスター管理者は、この権限を付与できます。 「コンピュートの権限」を参照してください。
-
クラスターでは、 テーブルアクセスコントロール 、自動終了 、または資格情報のパススルーを有効にし ないでください 。
-
クラスターでは 、標準 アクセス・モード を使用しないでください 。
-
クラスターでは、Spark構成 に設定し ないでください
spark.databricks.pyspark.enableProcessIsolationtrue。 -
Pro エディションを使用するには、RStudio Server フローティング Pro ライセンスが必要です。
クラスターでは をサポートするアクセス モード Unity CatalogRStudioを使用できますが、そのクラスターの Server を使用してUnity Catalog のデータにアクセスすることはできません。
RStudioサーバーを開く
Databricks クラスターで RStudio Server OS を開くには、次の手順を実行します。
-
クラスターの詳細ページを開きます。
-
クラスターを開始し、[ Apps ] タブをクリックします。
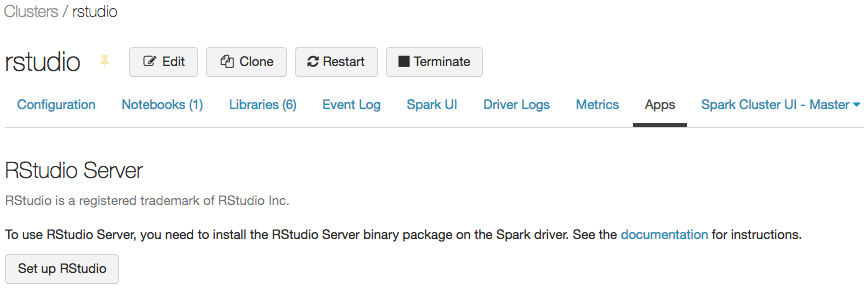
-
[ アプリ] タブで、 [RStudio のセットアップ] ボタンをクリックします。これにより、ワンタイムパスワードが生成されます。 表示 リンクをクリックして表示し、パスワードをコピーします。
-
「Open RStudio」 リンクをクリックすると、新しいタブで UI が開きます。ログインフォームにユーザー名とパスワードを入力してサインインします。
-
RStudio UI から、
SparkRパッケージをインポートし、クラスターで Spark ジョブを起動するためのSparkRセッションを設定できます。Rlibrary(SparkR)
sparkR.session()
# Query the first two rows of a table named "diamonds" in a
# schema (database) named "default" and display the query result.
df <- SparkR::sql("SELECT * FROM default.diamonds LIMIT 2")
showDF(df)
-
Sparklyrパッケージを添付してSpark接続を設定することもできます。
Rlibrary(sparklyr)
sc <- spark_connect(method = "databricks")
# Query a table named "diamonds" and display the first two rows.
df <- spark_read_table(sc = sc, name = "diamonds")
print(x = df, n = 2)
RStudio Server統合
で RStudioServerDatabricks を使用すると、RStudio クラスターのドライバノードで Server Daemon が実行されます。DatabricksRStudio Web UI は Databricks Web アプリを介してプロキシされるため、クラスター ネットワーク構成を変更する必要はありません。この図は、RStudio 統合コンポーネントのアーキテクチャを示しています。
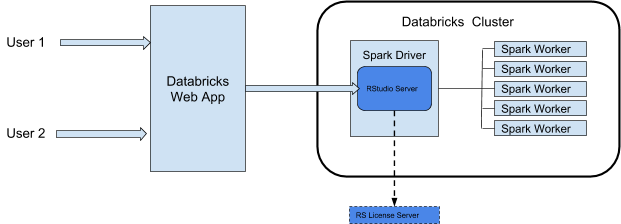
Databricks は、クラスターの Spark ドライバーのポート 8787 から RStudio Web サービスをプロキシします。この Web プロキシは RStudio でのみ使用することを目的としています。ポート 8787 で他の Web サービスを起動すると、ユーザーが潜在的なセキュリティ上の脆弱性にさらされる可能性があります。Databricks は、クラスターにサポートされていないソフトウェアをインストールしたことにより発生する問題については責任を負いません。
RStudio Workbench(旧RStudio Server Pro)
このセクションでは、Databricks クラスターでRStudio Workbench (旧称 RStudio Server Pro) をセットアップして使用を開始する方法について説明します。ライセンスによっては、RStudio Workbench に RStudio Server Pro が含まれる場合があります。
RStudioライセンスサーバーをセットアップする
Databricks で RStudio Workbench を使用するには、Pro ライセンスをフローティング ライセンスに変換する必要があります。サポートが必要な場合は、 help@rstudio.comまでお問い合わせください。ライセンスを変換する場合は、RStudio Workbench のライセンス サーバーを設定する必要があります。
ライセンス サーバーをセットアップするには:
- クラウド プロバイダー ネットワーク上で小さなインスタンスを起動します。ライセンス サーバー デーモンは軽量です。
- インスタンスに適切なバージョンの RStudio License Server をダウンロードしてインストールし、サービスを開始します。詳細な手順については、 RStudio Workbench 管理者ガイドを参照してください。
- ライセンス サーバー ポートが Databricks インスタンスに対して開いていることを確認します。
RStudio Workbenchをインストールする
RStudioDatabricksクラスターで Workbenchを設定するには、initスクリプトを作成してRStudio Workbenchバイナリパッケージをインストールし、ライセンスサーバーをライセンスリースに使用するように構成する必要があります。
RStudio Server オープンソース エディション パッケージが既に含まれているDatabricks RuntimeバージョンにRStudio Workbench をインストールする場合は、インストールを成功させるために、まずそのパッケージをアンインストールする必要があります。
以下は、ワークスペースファイルとしてホームディレクトリ、 Unity Catalog ボリューム、オブジェクトストレージなどの場所にinitスクリプトとして保存できる.shファイルの例です。 詳細については、 クラスター-scoped initスクリプトを参照してください。 このスクリプトは、Databricks との統合を効率化する追加の認証構成も実行します。
クラスタースコープinitスクリプトはサポート終了 DBFS 。 initスクリプトを DBFS に保存することは、レガシーワークロードをサポートするために一部のワークスペースに存在するため、推奨されません。 DBFSに保存されているすべてのinitスクリプトを移行する必要があります。移行手順については、 DBFSからの initスクリプトの移行を参照してください。
#!/bin/bash
set -euxo pipefail
if [[ $DB_IS_DRIVER = "TRUE" ]]; then
sudo apt-get update
sudo dpkg --purge rstudio-server # in case open source version is installed.
sudo apt-get install -y gdebi-core alien
## Installing RStudio Workbench
cd /tmp
# You can find new releases at https://rstudio.com/products/rstudio/download-commercial/debian-ubuntu/.
wget https://download2.rstudio.org/server/bionic/amd64/rstudio-workbench-2022.02.1-461.pro1-amd64.deb -O rstudio-workbench.deb
sudo gdebi -n rstudio-workbench.deb
## Configuring authentication
sudo echo 'auth-proxy=1' >> /etc/rstudio/rserver.conf
sudo echo 'auth-proxy-user-header-rewrite=^(.*)$ $1' >> /etc/rstudio/rserver.conf
sudo echo 'auth-proxy-sign-in-url=<domain>/login.html' >> /etc/rstudio/rserver.conf
sudo echo 'admin-enabled=1' >> /etc/rstudio/rserver.conf
sudo echo 'export PATH=/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin' >> /etc/rstudio/rsession-profile
# Enabling floating license
sudo echo 'server-license-type=remote' >> /etc/rstudio/rserver.conf
# Session configurations
sudo echo 'session-rprofile-on-resume-default=1' >> /etc/rstudio/rsession.conf
sudo echo 'allow-terminal-websockets=0' >> /etc/rstudio/rsession.conf
sudo rstudio-server license-manager license-server <license-server-url>
sudo rstudio-server restart || true
fi
<domain>Databricks URL に置き換え、<license-server-url>フローティング ライセンス サーバーの URL に置き換えます。- この
.shファイルをinitスクリプトとして、ホームディレクトリなどの場所にワークスペースファイルとして保存したり、 Unity Catalog ボリュームやオブジェクトストレージに保存したりします。 詳細については、 クラスター-scoped initスクリプトを参照してください。 - クラスターを起動する前に、この
.shファイルを関連付けられた場所からinitスクリプトとして追加します。 手順については、 クラスター-scoped initスクリプトを参照してください。 - クラスターを起動します。
RStudioワークベンチを開く
-
クラスターの詳細ページを開きます。
-
クラスターを開始し、[ Apps ] タブをクリックします。
-
[ アプリ] タブで、 [RStudio のセットアップ] ボタンをクリックします。
-
ワンタイムパスワードは必要ありません。 「Open RStudio UI」 リンクをクリックすると、認証された RStudio Pro セッションが開きます。
-
RStudio UI から、
SparkRパッケージをアタッチし、クラスターでジョブを起動するためのSparkRセッションSpark設定できます。Rlibrary(SparkR)
sparkR.session()
# Query the first two rows of a table named "diamonds" in a
# schema (database) named "default" and display the query result.
df <- SparkR::sql("SELECT * FROM default.diamonds LIMIT 2")
showDF(df)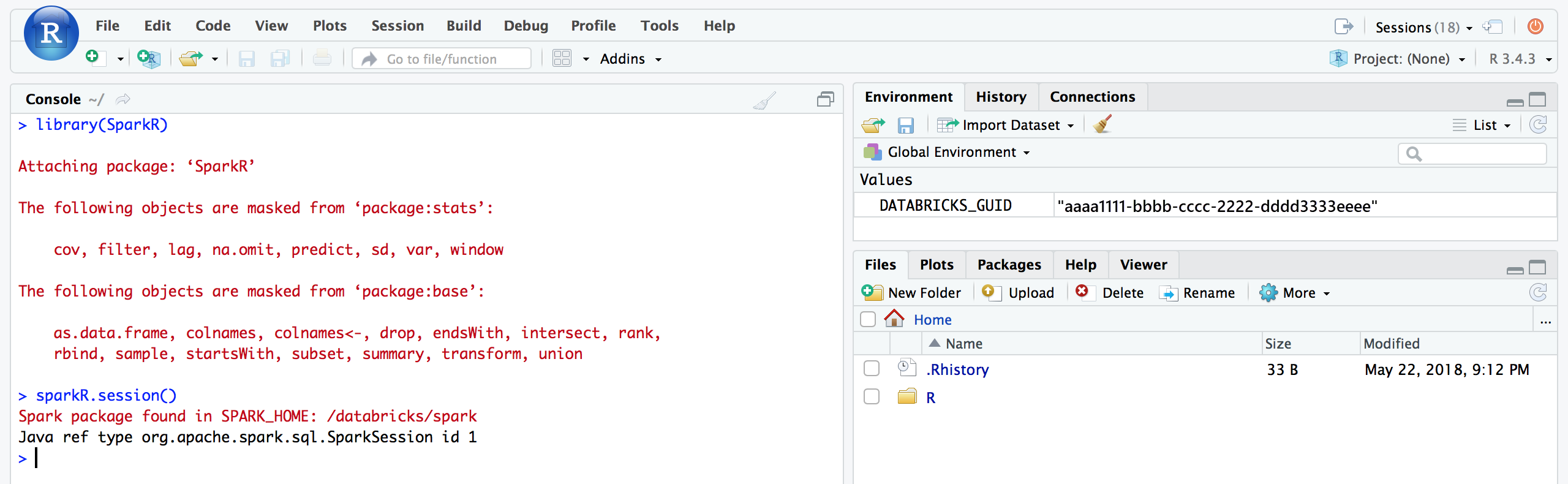
-
Sparklyrパッケージを添付してSpark接続を設定することもできます。
Rlibrary(sparklyr)
sc <- spark_connect(method = "databricks")
# Query a table named "diamonds" and display the first two rows.
df <- spark_read_table(sc = sc, name = "diamonds")
print(x = df, n = 2)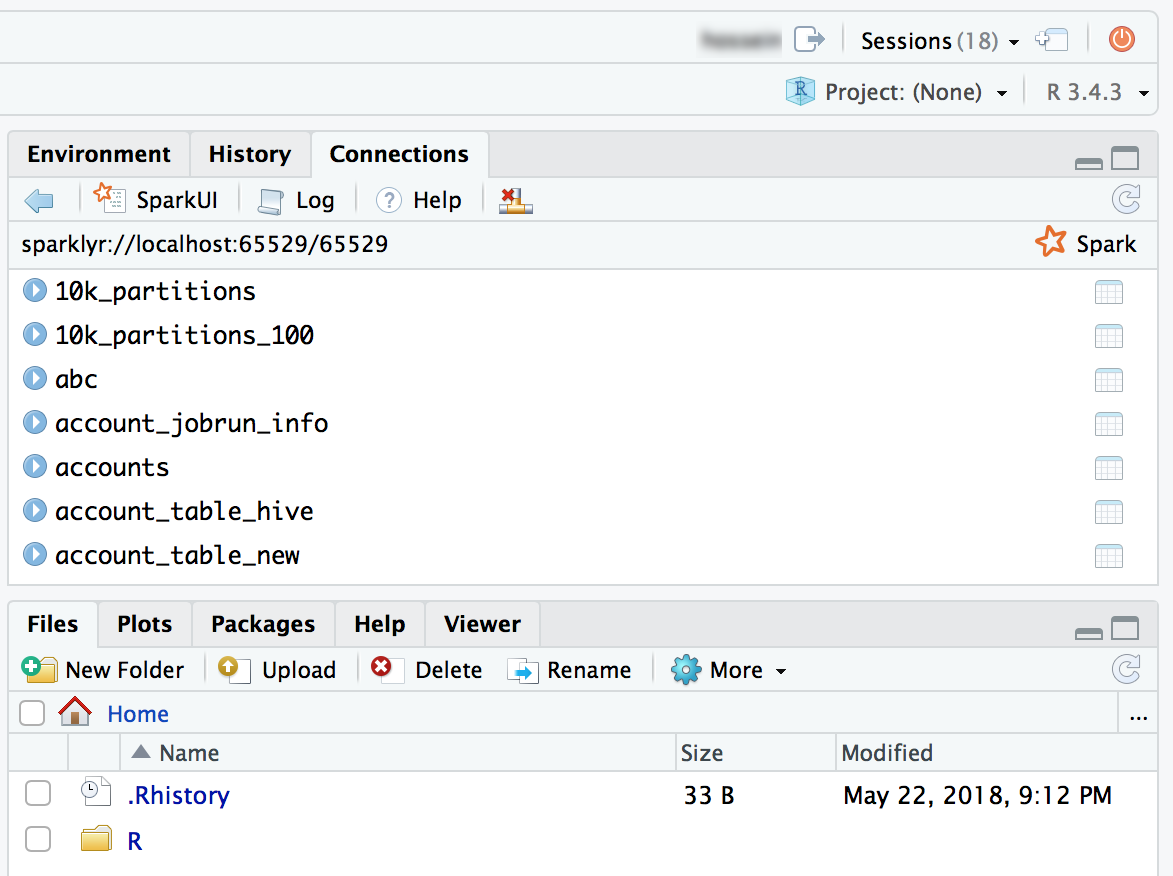
RStudio サーバーに関するよくある質問
RStudio Server オープンソース Edition とRStudio Workbench の違いは何ですか?
RStudio Workbench は、オープンソース版では利用できない幅広いエンタープライズ機能をサポートします。 機能の比較はRStudio の Web サイトで確認できます。
さらに、 RStudio Server オープンソース版はGNU Affero General Public License (AGPL)に基づいて配布されていますが、Pro バージョンには AGPL ソフトウェアを使用できない組織向けの商用ライセンスが付属しています。
最後に、 RStudio Workbench にはRStudio 、PBC によるプロフェッショナルおよびエンタープライズ サポートが付属していますが、 RStudio Server オープンソース Edition にはサポートが付属していません。
RStudio Workbench (RStudio Server Pro) ライセンスを Databricks で使用できますか?
はい、RStudio Server の Pro または Enterprise ライセンスをすでにお持ちの場合は、そのライセンスを Databricks で使用できます。Databricks で RStudio Workbench を設定する方法については、 RStudio Workbench (旧称 RStudio Server Pro)を参照してください。
RStudio Server はどこで実行されますか?追加のサービスやサーバーを管理する必要がありますか?
RStudio Server 統合の図に示されているように、RStudio Server デーモンは Databricks クラスターのドライバー (マスター) ノードで実行されます。RStudio Server オープンソース Edition を使用すると、追加のサーバーやサービスを実行する必要はありません。 ただし、RStudio Workbench の場合は、RStudio License Server を実行する別のインスタンスを管理する必要があります。
RStudio Serverを標準クラスターで使用できますか?
このページでは、レガシー クラスターの UI について説明します。クラスター アクセス モードの用語の変更を含む、新しいクラスター UI に関する情報については、 「コンピュート構成リファレンス」を参照してください。 新しいクラスター タイプと従来のクラスター タイプの比較については、 「クラスター UI の変更とクラスター アクセス モード」を参照してください。
はい、できます。
RStudio Serverを自動終了のクラスターで使用できますか?
いいえ、自動終了が有効になっている場合は RStudio を使用できません。自動終了により、RStudio セッション内の保存されていないユーザー スクリプトとデータが消去される可能性があります。このような意図しないデータ損失のシナリオからユーザーを保護するために、このようなクラスターでは RStudio はデフォルトで無効になっています。
クラスター リソースを使用しないときにクリーンアップする必要があるお客様には、DatabricksクラスターAPI リソース を使用して、スケジュールに基づいてRStudio クラスターをクリーンアップすることをお勧めします。
RStudio で作業をどのように永続化すればよいですか?
Databricks では、RStudio のバージョン管理システムを使用して作業を保存することを推奨しています。RStudio はさまざまなバージョン管理システムをサポートしており、プロジェクトのチェックインと管理が可能です。次のいずれかのオプションを使用してコードを永続化しないと、ワークスペース管理者がクラスターを再起動または終了した場合に作業が失われるリスクがあります。
1 つのオプションは、ファイル (コードまたはデータ) をワークスペースまたはボリュームに保存することです。たとえば、 /Workspace/の下にファイルを保存すると、クラスターが終了または再起動されてもファイルは削除されません。
もう 1 つのオプションは、R ノートブックをRmarkdownとしてエクスポートしてローカル ファイル システムに保存し、後でそのファイルを RStudio インスタンスにインポートすることです。rmarkdownを使用した BlogSharing R ノートブックでは、ステップについて詳しく説明しています。
もう 1 つのオプションは、クラスターがシャットダウンされても作業が失われないように、Amazon Elastic File System (Amazon EFS) ボリュームをクラスターにマウントすることです。クラスターが再起動すると、Databricks によって Amazon EFS ボリュームが再マウントされ、中断したところから作業を続行できます。既存のAmazon EFS ボリュームをクラスターにマウントするには、クラスターAPI 2.0 でcreate Cluster ( POST /api/2.0/clusters/create ) またはedit クラスター( POST /api/2.0/clusters/edit ) オペレーションを呼び出し、オペレーションのcluster_mount_infos配列でAmazon EFS ボリュームのマウント情報を指定します。
作成または使用するクラスターでUnity Catalog 、自動終了、または自動スケーリングが有効になっていないことを確認してください。 また、クラスターでコマンドchmod a+w </path/to/volume>を実行するなどして、マウントされたボリュームへの書き込みアクセス権がクラスターにあることを確認します。このコマンドは、クラスターのWeb ターミナルを介して既存のクラスター上で実行することも、前の操作のinit_scripts配列で指定したinit スクリプトを使用して新しいクラスター上で実行することもできます。
既存の Amazon EFS ボリュームがない場合は、作成できます。まず、Databricks 管理者に連絡して、Databricks ワークスペースの VPC ID、パブリック サブネット ID、セキュリティ グループ ID を取得します。次に、この情報と AWS マネジメントコンソールを使用して、 Amazon EFS コンソールでカスタム設定のファイルシステムを作成します。この手順の最後のステップで、 [Attach] をクリックし、前述のcluster_mount_infos配列で指定した DNS 名とマウント オプションをコピーします。
SparkRセッションを開始するにはどうすればよいですか?
Databricks の SparkR は、Databricks Runtime 16.0 以降では非推奨です。
SparkR Databricks Runtime に含まれていますが、RStudio に読み込む必要があります。RStudio 内で次のコードを実行して、 SparkRセッションを初期化します。
library(SparkR)
sparkR.session()
SparkRパッケージのインポート中にエラーが発生した場合は、 .libPaths()を実行し、結果に/home/ubuntu/databricks/spark/R/libが含まれていることを確認します。
含まれていない場合は、 /usr/lib/R/etc/Rprofile.siteの内容を確認してください。ドライバーの/home/ubuntu/databricks/spark/R/lib/SparkRをリストして、 SparkRパッケージがインストールされていることを確認します。
sparklyrセッションを開始するにはどうすればよいですか?
sparklyrパッケージは、クラスターにインストールする必要があります。次のいずれかの方法を使用して、 sparklyr パッケージをインストールします。
- Databricksライブラリとして
install.packages()command- RStudio パッケージ管理 UI
library(sparklyr)
sc <- spark_connect(method = “databricks”)
RStudio は Databricks R ノートブックとどのように統合されますか?
バージョン管理を通じて、ノートブックと RStudio 間で作業を移動できます。
作業ディレクトリとは何ですか?
RStudio でプロジェクトを開始するときは、作業ディレクトリを選択します。デフォルトでは、これは RStudio Server が実行されているドライバー (マスター) コンテナー上のホーム ディレクトリです。必要に応じてこのディレクトリを変更できます。
Databricks 上で実行されている RStudio から Shiny アプリを起動できますか?
はい、 Databricks 上の RStudio Server 内で Shiny アプリケーションを開発および表示できます。
Databricks 上の RStudio 内でターミナルや git を使用できません。どうすれば修正できますか?
Websocket が無効になっていることを確認してください。RStudio Server オープンソース Edition では、これを UI から実行できます。
RStudio Server Pro では、 allow-terminal-websockets=0 /etc/rstudio/rsession.confに追加して、すべてのユーザーの Websocket を無効にすることができます。
クラスターの詳細の下に「アプリ」タブが表示されません。
この機能はすべてのお客様が利用できるわけではありません。 プレミアムプラン以上をご利用いただく必要があります。
ホスト型RStudio Serverの代替
Databricks は、 Databricks ランタイム 15.4 以前でホストされている RStudio Server を、サポート終了まで引き続きサポートします。 たとえば、Databricks Runtime 15.4 LTS は、2027 年 8 月 19 日まで、ホストされた RStudio サーバーを引き続きサポートします。
移行にさらに時間が必要な場合は、ランタイムのサポート終了日まで、ホストされている RStudio サーバーを引き続き使用できます。15.4 などの新しい LTS ランタイムにアップグレードすると、サポート期間が延長されます。
代替案1:Posit Workbench
Posit PBC は Databricks と提携して、 Databricks の Posit Workbench ネイティブ統合を提供します。
この統合により、RStudio ProからDatabricksコンピュートに接続でき、Unity Catalog やマネージドDatabricks OAuth の資格情報のサポートなどの機能が含まれます。
代替案2:RStudioデスクトップ
RStudio Desktop をローカルの開発マシンから Databricks コンピュート リソースまたは SQLウェアハウスに接続します。
Sparklyrを通じてDatabricks Connect を使用するか、odbc Rパッケージを通じてDatabricks ODBCドライバーを使用できます。このメソッドは、Unity Catalog もサポートしています。
代替案 3: Databricks ノートブック
Databricks ノートブックで R を使用して、Databricks プラットフォームの他の部分と統合されたインタラクティブな開発エクスペリエンスを実現します。