非同期進捗状況追跡
非同期的な進捗状況追跡により、クエリがチェックポイントの進捗状況を非同期的に更新し、各マイクロバッチでデータを処理できるようになるため、構造化ストリーミングパイプラインのレイテンシが削減されます。
クエリ処理中、構造化ストリーミングはオフセットを保持および管理し、各マイクロバッチのoffsetLogとcommitLogでクエリの進行状況を測定します。非同期的な進捗状況追跡がない場合、オフセット管理操作は処理遅延に直接影響します。なぜなら、オフセット管理操作が完了するまでデータ処理を続行できないからです。
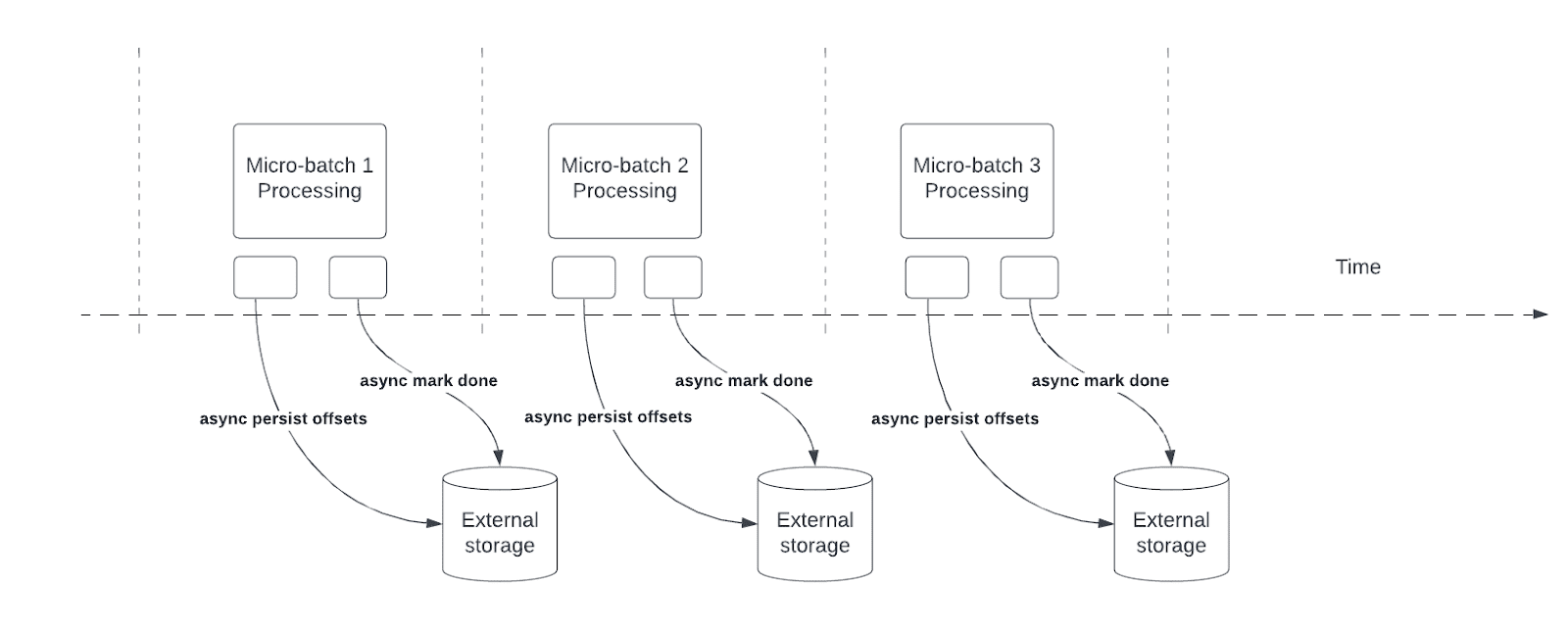
非同期の進捗状況追跡は、 Trigger.onceまたはTrigger.availableNowトリガーとは互換性がありません。有効になっている場合、 Trigger.onceまたはTrigger.availableNowを含む構造化ストリーミングクエリは失敗します。
設定オプション
オプション | デフォルト | 説明 |
|---|---|---|
|
| 非同期の進捗状況追跡を有効にするかどうか。 |
|
| オフセットへの書き込みと完了コミットの間隔(ミリ秒)。 |
非同期の進捗状況追跡を有効にする
非同期の進捗状況追跡を有効にするには、 asyncProgressTrackingEnabled trueに設定してください。
- Python
- Scala
stream = (spark.readStream
.format("kafka")
.option("kafka.bootstrap.servers", "host1:port1,host2:port2")
.option("subscribe", "in")
.load()
)
query = (stream.writeStream
.format("kafka")
.option("topic", "out")
.option("checkpointLocation", "/tmp/checkpoint")
.option("asyncProgressTrackingEnabled", "true")
.start()
)
val stream = spark.readStream
.format("kafka")
.option("kafka.bootstrap.servers", "host1:port1,host2:port2")
.option("subscribe", "in")
.load()
val query = stream.writeStream
.format("kafka")
.option("topic", "out")
.option("checkpointLocation", "/tmp/checkpoint")
.option("asyncProgressTrackingEnabled", "true")
.start()
チェックポイントの頻度でスループットを向上させる
デフォルトのチェックポイント頻度である1000ミリ秒は、ほとんどのクエリに対して十分なスループットを提供します。オフセット管理操作が非同期進捗状況追跡の処理速度よりも速く発生すると、オフセット管理操作のバックログが蓄積されます。バックログがさらに増大するのを防ぐため、非同期の進捗状況追跡はデータ処理をブロックしたり遅延させたりすることがあり、期待されるレイテンシのメリットを損なう可能性があります。
このシナリオでは、Databricksはチェックポイントの間隔を長くすることを推奨します。
- Python
- Scala
query = (stream.writeStream
.format("kafka")
.option("topic", "out")
.option("checkpointLocation", "/tmp/checkpoint")
.option("asyncProgressTrackingEnabled", "true")
.option("asyncProgressTrackingCheckpointIntervalMs", "5000")
.start()
)
val query = stream.writeStream
.format("kafka")
.option("topic", "out")
.option("checkpointLocation", "/tmp/checkpoint")
.option("asyncProgressTrackingEnabled", "true")
.option("asyncProgressTrackingCheckpointIntervalMs", "5000")
.start()
障害復旧時間は、チェックポイント間隔時間とともに増加します。障害が発生した場合、パイプラインは前回の正常なチェックポイント以降のすべてのデータを再処理する必要があります。本番運用でこの変更を行う前に、通常処理時のレイテンシの低減と、障害発生時の復旧時間とのトレードオフを考慮してください。
非同期進捗状況追跡をオフにする
非同期進捗状況追跡が有効になっている場合、ストリームはすべてのバッチのチェックポイント進捗状況を保証するものではありません。この機能をオフにするには、まず進行状況をチェックポイントに保存する必要があります。
オフにするには、次のステップに従います。
asyncProgressTrackingEnabledをtrueに、asyncProgressTrackingCheckpointIntervalMs0に設定した状態で、少なくとも2つのマイクロバッチを処理します。
- Python
- Scala
query = (stream.writeStream
.format("kafka")
.option("topic", "out")
.option("checkpointLocation", "/tmp/checkpoint")
.option("asyncProgressTrackingEnabled", "true")
.option("asyncProgressTrackingCheckpointIntervalMs", "0")
.start()
)
val query = stream.writeStream
.format("kafka")
.option("topic", "out")
.option("checkpointLocation", "/tmp/checkpoint")
.option("asyncProgressTrackingEnabled", "true")
.option("asyncProgressTrackingCheckpointIntervalMs", "0")
.start()
- クエリを停止します。
- Python
- Scala
query.stop()
query.stop()
- 非同期進捗状況追跡を無効にして、クエリを再起動してください。
- Python
- Scala
query = (stream.writeStream
.format("kafka")
.option("topic", "out")
.option("checkpointLocation", "/tmp/checkpoint")
.option("asyncProgressTrackingEnabled", "false")
.start()
)
val query = stream.writeStream
.format("kafka")
.option("topic", "out")
.option("checkpointLocation", "/tmp/checkpoint")
.option("asyncProgressTrackingEnabled", "false")
.start()
上記の手順に従わずに非同期進捗状況の追跡を無効にすると、次のエラーが発生する可能性があります。
java.lang.IllegalStateException: batch x doesn't exist
ドライバー ログに、次のエラーが表示される場合があります。
The offset log for batch x doesn't exist, which is required to restart the query from the latest batch x from the offset log. Please ensure there are two subsequent offset logs available for the latest batch via manually deleting the offset file(s). Please also ensure the latest batch for commit log is equal or one batch earlier than the latest batch for offset log.
制限事項
- Kafkaシンクの場合、非同期進捗状況追跡はステートレスパイプラインのみをサポートします。
- 非同期的な進捗状況追跡では、バッチのオフセット範囲が障害発生時に変更される可能性があるため、エンドツーエンドの処理が正確に一度だけ行われることが保証されません。Kafkaのような一部のシンクは、厳密に1回だけデータを送信するという保証を一切提供しません。