ベクトル検索エンドポイントとインデックスを作成する
この記事では、地下鉄検索を使用して、地下鉄検索のエンドポイントとインデックスを作成する方法について説明します。
ベクトル検索UI、Python SDK 、またはREST API を使用して、ベクトル検索エンドポイントやベクトル検索インデックスなどの コンポーネントを作成および管理できます。
たとえば、ベクトル検索エンドポイントを作成してクエリする方法を説明するノートブックについては、ベクトル検索の例を参照してください。 リファレンス情報については、 Python SDK リファレンスを参照してください。
要件
- Unity Catalog対応ワークスペースであること。
- サーバレス コンピュートが有効化されていること。手順については、 サーバレス コンピュートへの接続を参照してください。
- 標準エンドポイントの場合、ソース テーブルでチェンジデータフィードが有効になっている必要があります。DatabricksでのDelta Lake チェンジデータフィードの使用 を参照してください。
- ベクトル検索インデックスを作成するには、インデックスが作成されるカタログ スキーマに対する CREATE TABLE 権限が必要です。
- 別のユーザーが所有するインデックスをクエリするには、追加の権限が必要です。「ベクトル検索インデックスをクエリする方法」を参照してください。
ベクトル検索エンドポイントを作成および管理するためのアクセス許可は、アクセス制御リストを使用して構成されます。 ベクトル検索エンドポイント ACLを参照してください。
インストール
ベクトル検索SDK使用するには、ノートブックにインストールする必要があります。 パッケージをインストールするには、次のコードを使用します。
%pip install databricks-vectorsearch
dbutils.library.restartPython()
次に、次のコマンドを使用してVectorSearchClientをインポートします。
from databricks.vector_search.client import VectorSearchClient
認証に関する情報については、 「データ保護と認証」を参照してください。
ベクトル検索エンドポイントを作成する
Databricks UI、 Python SDK 、またはAPIを使用して、ベクトル検索エンドポイントを作成できます。
UIを使用してベクトル検索エンドポイントを作成する
これらのステップに従って、UI を使用してベクトル検索エンドポイントを作成します。
-
左側のサイドバーで 「コンピュート」 をクリックします。
-
[検索] タブをクリックし、 [エンドポイントの作成] をクリックします。
-
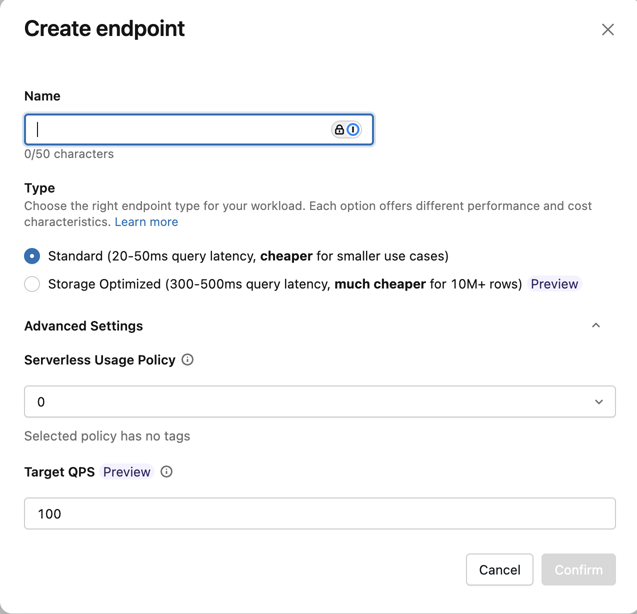
エンドポイントの作成フォーム が開きます。このエンドポイントの名前を入力します。
-
タイプ フィールドで、 標準 または ストレージ最適化 を選択します。エンドポイントのオプションを参照してください。
-
(オプション) 詳細設定 で、予算ポリシーを選択します。「節約検索」を参照してください。
-
確認 をクリックします。
Python SDKを使用して、ベクトル検索エンドポイントを作成する
次の例では、 create_endpoint() SDK 関数を使用して ベクトル検索 エンドポイントを作成します。
# The following line automatically generates a PAT Token for authentication
client = VectorSearchClient()
# The following line uses the service principal token for authentication
# client = VectorSearchClient(service_principal_client_id=<CLIENT_ID>,service_principal_client_secret=<CLIENT_SECRET>)
client.create_endpoint(
name="vector_search_endpoint_name",
endpoint_type="STANDARD" # or "STORAGE_OPTIMIZED"
)
REST APIを使用してベクトル検索エンドポイントを作成する
REST API リファレンスドキュメント: POST /api/2.0/vector-search/endpointsを参照してください。
高スループットワークロード向けに、目標QPSを設定したエンドポイントを作成します。
プレビュー
この機能は パブリック プレビュー段階です。
高スループットのワークロードの場合、目標QPSを指定したエンドポイントを作成できます。この機能は標準エンドポイントでのみ利用可能です。
ターゲット QPS を設定するには、 target_qpsを使用します。 エンドポイントのスループットを高QPSで拡張する方法を参照してください。
target_qpsプロビジョニングの追加容量を設定すると、エンドポイントのコストが増加します。 実際のクエリトラフィック量に関わらず、この追加容量に対して料金が発生します。これらの料金の発生を停止するには、 target_qps=-1を使用してエンドポイントをリセットしてください。パブリックプレビュー期間中は、スループットのスケーリングはベストエフォート型であり、保証されるものではありません。
client.create_endpoint(
name="vector_search_endpoint_name",
endpoint_type="STANDARD",
target_qps=500, # target QPS for high-throughput workloads
)
既存のエンドポイントの目標 QPS を変更するには、 update_endpoint()を使用します。
from databricks.vector_search.client import VectorSearchClient, TARGET_QPS_RESET_TO_DEFAULT
client = VectorSearchClient()
# Set or update target QPS
response = client.update_endpoint(name="vector_search_endpoint_name", target_qps=500)
# Check scaling status
scaling_info = response.get("endpoint", {}).get("scaling_info", {})
print(f"State: {scaling_info.get('state')}") # SCALING_CHANGE_IN_PROGRESS or SCALING_CHANGE_APPLIED
# Remove high QPS configuration and return to default
client.update_endpoint(name="vector_search_endpoint_name", target_qps=TARGET_QPS_RESET_TO_DEFAULT)
目標QPSを更新した後、インデックスを同期して新しい設定を適用してください。
(オプション)埋め込みモデルを提供するエンドポイントを作成して構成する
Databricksで埋め込みをコンピュートすることを選択した場合は、事前構成された基盤モデルAPIエンドポイントを使用するか、選択した埋め込みモデルを提供するモデルサービング エンドポイントを作成できます。 手順については、トークン単位の従量課金 基盤モデルAPIまたは基盤モデル サービング エンドポイントの作成を参照してください。 たとえば、ノートブックについては、 ベクトル検索サンプルノートブックを参照してください。
エンべディングエンドポイントを構成する場合、Databricks では、デフォルトの選択である Scale to zero を削除することをお勧めします。 エンドポイントの提供にはウォームアップに数分かかる場合があり、スケールダウンされたエンドポイントを持つインデックスに対する最初のクエリがタイムアウトする可能性があります。
埋め込みエンドポイントがデータセットに対して適切に構成されていない場合、トラフィック検索インデックスの初期化がタイムアウトになる可能性があります。 小さなデータセットとテストには CPU エンドポイントのみを使用する必要があります。大規模なデータセットの場合は、最適なパフォーマンスを得るために GPU エンドポイントを使用します。
ベクトル検索インデックスを作成する
UI、 Python SDK 、またはREST APIを使用して、ベクトル検索インデックスを作成できます。 UI は最もシンプルなアプローチです。
インデックスには 2 つの種類があります。
- Delta Sync Index は ソース Delta Table と自動的に同期し、Delta Table の基礎となるデータが変更されると、インデックスを自動的かつ増分的に更新します。
- Direct Vector Access Index は、 ベクトルとメタデータの直接読み取りと書き込みをサポートします。ユーザーは、REST API または Python SDK を使用してこのテーブルを更新する責任があります。このタイプのインデックスは、UI を使用して作成することはできません。REST API または SDK を使用する必要があります。
Delta Sync Indexesは、以下の検索モードをサポートしています。
- ベクトル検索 (ANNまたはハイブリッド):埋め込み列が必要です。標準エンドポイントとストレージ最適化エンドポイントの両方をサポートします。これらのインデックスでは、
query_type="FULL_TEXT"を使用してキーワード検索を行うこともできます。 - 専用の全文検索インデックス (ベータ版):キーワードのみの検索用に、埋め込み列を使用せずに作成されたDelta Sync Index。トリガー同期モードを使用するストレージ最適化エンドポイントでのみ利用可能です。全文検索インデックスの作成を参照してください。
列名_idは予約されています。ソース テーブルに_idという名前の列がある場合は、ベクトル検索インデックスを作成する前に名前を変更してください。
UIを使用してインデックスを作成する
-
左のサイドバーで[ カタログ ] をクリックして、カタログエクスプローラーUIを開きます。
-
使用する Delta テーブルに移動します。
-
右上の 作成 ボタンをクリックし、ドロップダウンメニューから ベクトル検索インデックス を選択します。
-
ダイアログ内のセレクターを使用してインデックスを構成します。
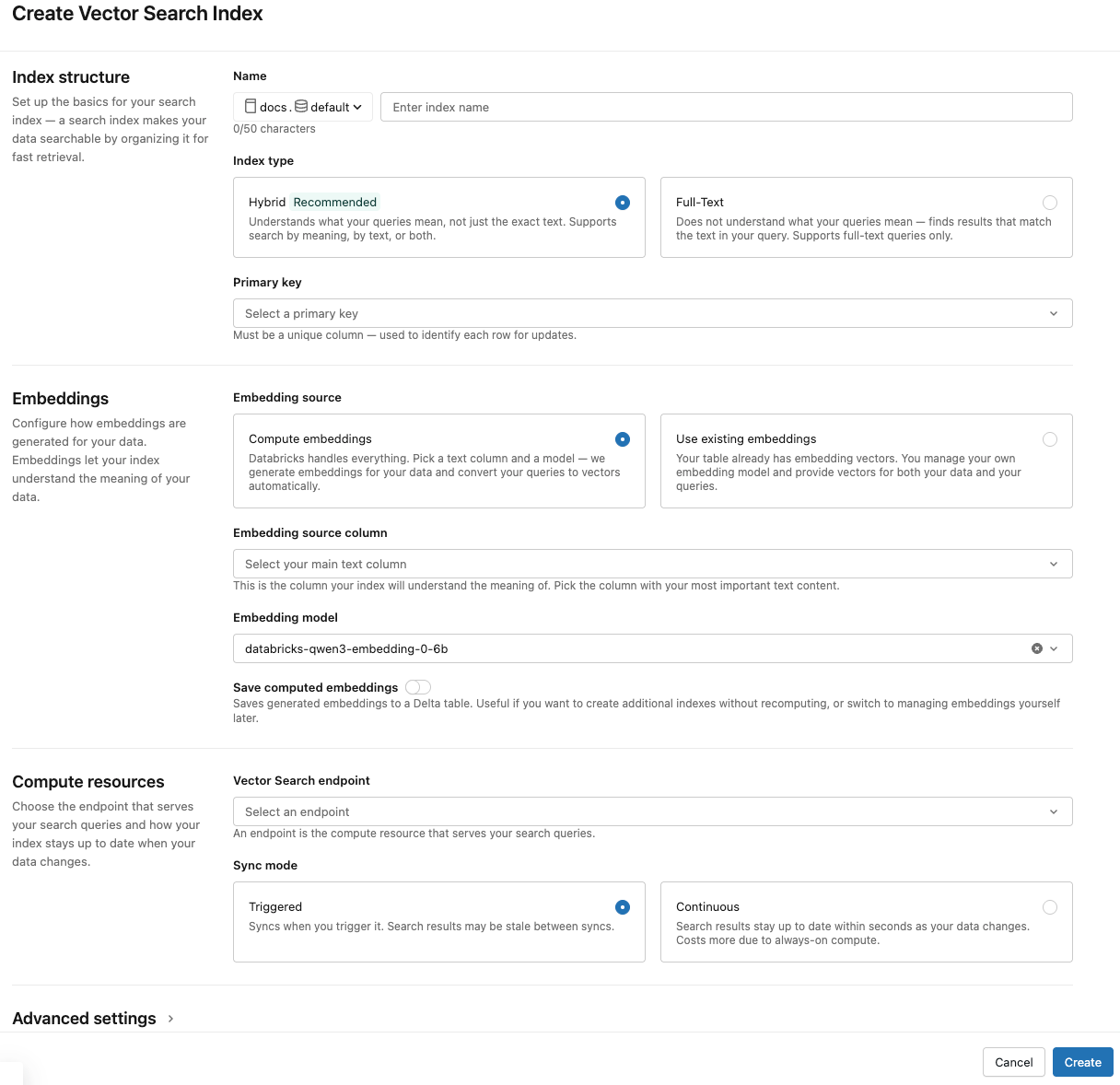
インデックス構造
名前 : Unity Catalog のオンライン テーブルに使用する名前。 名前には3階層の名前空間、
<catalog>.<schema>.<name>が必要です。英数字とアンダースコアのみ使用できます。インデックスの種類 : ハイブリッド を選択すると、同じインデックス上で意味検索(ベクトル検索)とキーワード検索の両方がサポートされます。埋め込みコンテンツを含まないキーワードのみの検索を行うには、 「全文検索」 を選択してください。全文検索インデックスの要件については、「全文検索インデックスの作成(ベータ版)」を参照してください。
主キー : 主キーとして使用する列。
エンベディング
Embedding ソース : DatabricksでDeltaテーブル内のテキスト列の埋め込みをコンピュートするか ( コンピュート embeddings )、 Deltaテーブルに事前計算された埋め込みが含まれるかどうか ( [ 既存の埋め込みを使用 ] ) を示します。
-
[埋め込みをコンピュート] を選択した場合は、埋め込みをコンピュートする列と、計算に使用する埋め込みモデルを選択します。 テキスト列のみがサポートされます。
-
標準エンドポイントを使用する本番運用アプリケーションの場合、 Databricksプロビジョニング スループット サービング エンドポイントを備えた基盤モデル
databricks-qwen3-embedding-0-6bを使用することを推奨します。 -
Databricksでホストされるモデルでストレージ最適化エンドポイントを使用する本番運用アプリケーションの場合は、埋め込みモデル エンドポイントとしてモデル名を直接使用します (たとえば、
databricks-qwen3-embedding-0-6b)。 ストレージ最適化エンドポイントは、取り込み時にバッチ推論でai_queryを使用し、埋め込みジョブに高いスループットを提供します。クエリにプロビジョニングされたスループット エンドポイントを使用する場合は、インデックスを作成するときにmodel_endpoint_name_for_queryフィールドに指定します。
-
-
「既存の埋め込みを使用する」 を選択した場合は、事前に計算された埋め込みと埋め込みの次元を含む列を選択してください。事前計算された埋め込み列の形式は
array[float]ある必要があります。ストレージ最適化エンドポイントの場合、埋め込み次元は16で割り切れる必要があります。
コンピュート埋め込みを保存 : この設定を切り替えると、生成された埋め込みがUnity Catalogテーブルに保存されます。 詳細については、 「生成された埋め込みテーブルの保存」を参照してください。
コンピュートリソース
ベクトル検索エンドポイント : インデックスを保存するためのベクトル検索エンドポイントを選択します。
同期モード : 連続 は、インデックスを数秒の待機時間と同期させます。ただし、継続的な同期ストリーミングパイプラインを実行するためにコンピュートクラスターをプロビジョニングするため、コストが高くなります。
- 標準エンドポイントの場合、 連続 と トリガー の両方が増分更新を実行するため、最後の同期以降に変更されたデータのみが処理されます。
- ストレージ最適化エンドポイントの場合、同期ごとにインデックスが部分的に再構築されます。後続の同期の管理インデックスの場合、ソース行が変更されていない生成された埋め込みは再利用されるため、再計算する必要はありません。ストレージ最適化エンドポイントの制限事項を参照してください。
トリガー モードでは、Python SDK または REST API を使用して同期を開始します。Delta Sync インデックスの更新を参照してください。
ストレージ最適化エンドポイントの場合、 トリガー 同期モードのみがサポートされます。
詳細設定
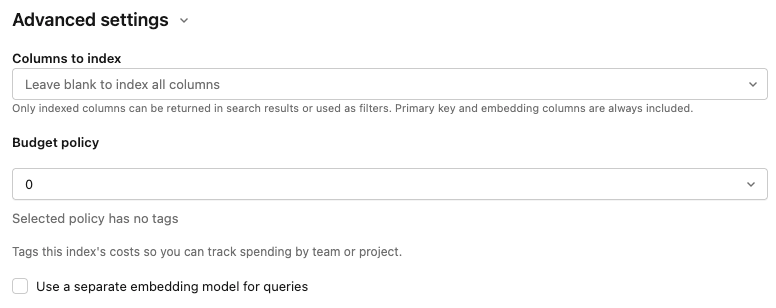
インデックスを作成する列 :インデックスに含める列を選択します。このフィールドを空白のままにすると、ソーステーブルのすべての列にインデックスが作成されます。主キーと埋め込み列は常に含まれます。検索結果に表示できるのは、インデックスが付けられた列のみであり、フィルターとしても使用できます。
予算ポリシー : 予算ポリシーを適用して、チームまたはプロジェクトごとに追跡するためにインデックスのコストをタグ付けします。 「節約検索」を参照してください。
クエリに別の埋め込みモデルを使用する : [コンピュート embeddings] を選択した場合は、このオプションを選択して、インデックスのクエリに別の埋め込みモデルサービング エンドポイントを指定します。 これは、データ取り込みには高スループットのエンドポイントが必要だが、クエリには低遅延のエンドポイントが必要な場合に役立ちます。 埋め込みモデル フィールドで指定されたモデルは、ここで別のモデルを指定しない限り、常にデータ取り込みに使用され、クエリにも使用されます。
-
-
インデックスの設定が完了したら、 「作成」 をクリックします。
Python SDKを使用してインデックスを作成する
次の例では、Databricksによって計算されるエンべディングを用いたDelta Sync Indexを作成します。詳細については、 Python SDK リファレンスを参照してください。
この例では、オプションのパラメーターmodel_endpoint_name_for_queryも示しています。これは、インデックスのクエリに使用される別の埋め込みモデルサービング エンドポイントを指定します。
client = VectorSearchClient()
index = client.create_delta_sync_index(
endpoint_name="vector_search_demo_endpoint",
source_table_name="vector_search_demo.vector_search.en_wiki",
index_name="vector_search_demo.vector_search.en_wiki_index",
pipeline_type="TRIGGERED",
primary_key="id",
embedding_source_column="text",
embedding_model_endpoint_name="e5-small-v2", # This model is used for ingestion, and is also used for querying unless model_endpoint_name_for_query is specified.
model_endpoint_name_for_query="e5-mini-v2" # Optional. If specified, used only for querying the index.
)
次の例では、自己管理型のエンベディングを使用して Delta Sync Index を作成します。
client = VectorSearchClient()
index = client.create_delta_sync_index(
endpoint_name="vector_search_demo_endpoint",
source_table_name="vector_search_demo.vector_search.en_wiki",
index_name="vector_search_demo.vector_search.en_wiki_index",
pipeline_type="TRIGGERED",
primary_key="id",
embedding_dimension=1024,
embedding_vector_column="text_vector"
)
デフォルトでは、ソース テーブルのすべての列がインデックスと同期されます。同期する列のサブセットを選択するには、 columns_to_syncを使用します。主キーと埋め込み列は常にインデックスに含まれます。
プライマリキーとエンベディングカラム のみを 同期するには、次のように columns_to_sync で指定する必要があります。
index = client.create_delta_sync_index(
...
columns_to_sync=["id", "text_vector"] # to sync only the primary key and the embedding column
)
追加の列を同期するには、次のように指定します。 プライマリ・キーとエンベディングカラムは、常に同期されるため、含める必要はありません。
index = client.create_delta_sync_index(
...
columns_to_sync=["revisionId", "text"] # to sync the `revisionId` and `text` columns in addition to the primary key and embedding column.
)
全文検索インデックスを作成する(ベータ版)
ベータ版
全文検索インデックスの作成機能は、ストレージ最適化エンドポイントでのみベータ版機能として利用可能です。これを使用するには、 vs_full_textワークスペースプレビューを有効にする必要があります。プレビューを有効にするには、アカウントチームにお問い合わせいただくか、 「Databricksプレビューの管理」をご覧ください。
全文検索インデックスを使用すると、ベクトル埋め込みを必要とせずに、テキスト列に対してキーワードベースの検索が可能になります。これは、意味的な類似性ではなく、正確な用語、識別子、またはキーワードを検索したい場合に便利です。
全文検索インデックスには、以下の要件があります。
- ストレージ最適化された エンドポイントを使用する必要があります。標準エンドポイントはサポートされていません。
- トリガー 同期モードを使用する必要があります。継続的な同期はサポートされていません。
- パラメーター
embedding_source_column、embedding_vector_column、およびembedding_dimensionはサポートされていません。
以下の例は、Python SDK を使用して全文検索インデックスを作成するものです。
client = VectorSearchClient()
index = client.create_delta_sync_index(
endpoint_name="storage_optimized_endpoint",
source_table_name="catalog.schema.source_table",
index_name="catalog.schema.full_text_index",
pipeline_type="TRIGGERED",
primary_key="id",
columns_to_sync=["id", "text", "metadata_column"],
index_subtype="FULL_TEXT"
)
インデックスを作成したら、同期を実行してデータを投入します。
index.sync()
全文インデックスを照会するには、 query_type="FULL_TEXT"を使用します。詳細については、 「ベクトル検索インデックスのクエリ」を参照してください。
results = index.similarity_search(
query_text="search terms",
columns=["id", "text"],
num_results=10,
query_type="FULL_TEXT"
)
次の例では、直接ベクトル アクセス インデックスを作成します。
client = VectorSearchClient()
index = client.create_direct_access_index(
endpoint_name="storage_endpoint",
index_name=f"{catalog_name}.{schema_name}.{index_name}",
primary_key="id",
embedding_dimension=1024,
embedding_vector_column="text_vector",
schema={
"id": "int",
"field2": "string",
"field3": "float",
"text_vector": "array<float>"}
)
REST APIを使用してインデックスを作成する
REST API リファレンス ドキュメントを参照してください: POST /api/2.0/vector-search/indexes 。
生成されたエンベディングテーブルを保存
Databricks がエンべディングを生成する場合、生成されたエンべディングを Unity Catalog のテーブルに保存できます。 このテーブルは、ベクトル索引と同じスキーマで作成され、ベクトル索引ページからリンクされます。
テーブルの名前は、ベクトル検索インデックスの名前に_writeback_tableが追加されたものです。名前は編集できません。
Unity Catalog 内の他のテーブルと同様に、テーブルにアクセスしてクエリを実行できます。ただし、テーブルは手動で更新されることを意図していないため、削除したり変更したりしないでください。インデックスが削除されると、テーブルも自動的に削除されます。
ベクトル検索インデックスを更新する
Delta同期インデックスを更新する
継続 同期モードで作成されたインデックスは、ソース Delta テーブルが変更されると自動的に更新されます。 トリガー 同期モードを使用している場合は、UI、Python SDK、または REST API を使用して同期を開始できます。
- Databricks UI
- Python SDK
- REST API
-
Catalog Explorer で、「ベクトル検索インデックス」に移動します。
-
概要 タブの データ取り込み セクションで、 今すぐ同期 をクリックします。
![[今すぐ同期] ボタンを使用して、カタログ エクスプローラーからの検索インデックスを同期します。](/aws/ja/assets/images/sync-now-f4e56831766a63ef6f7dcf6351bea12e.png) 。
。
詳細については、 Python SDK リファレンスを参照してください。
client = VectorSearchClient()
index = client.get_index(index_name="vector_search_demo.vector_search.en_wiki_index")
index.sync()
REST API リファレンスドキュメント: POST /api/2.0/vector-search/indexes/{index_name}/syncを参照してください。
直接ベクトルアクセスインデックスを更新する
Python SDK または REST API を使用して、Direct Vector Access Index にデータを挿入、更新、または削除できます。
- Python SDK
- REST API
詳細については、 Python SDK リファレンスを参照してください。
index.upsert([
{
"id": 1,
"field2": "value2",
"field3": 3.0,
"text_vector": [1.0] * 1024
},
{
"id": 2,
"field2": "value2",
"field3": 3.0,
"text_vector": [1.1] * 1024
}
])
REST API リファレンス ドキュメントを参照してください: POST /api/2.0/vector-search/indexes 。
本番運用アプリケーションの場合、 Databricks は パーソナルアクセストークン の代わりに サービスプリンシパル を使用することをお勧めします。 パフォーマンスは、クエリごとに最大 100 ミリ秒向上できます。
次のコード例は、サービスプリンシパルを使用してインデックスを更新する方法を示しています。
export SP_CLIENT_ID=...
export SP_CLIENT_SECRET=...
export INDEX_NAME=...
export WORKSPACE_URL=https://...
export WORKSPACE_ID=...
# Set authorization details to generate OAuth token
export AUTHORIZATION_DETAILS='{"type":"unity_catalog_permission","securable_type":"table","securable_object_name":"'"$INDEX_NAME"'","operation": "WriteVectorIndex"}'
# Generate OAuth token
export TOKEN=$(curl -X POST --url $WORKSPACE_URL/oidc/v1/token -u "$SP_CLIENT_ID:$SP_CLIENT_SECRET" --data 'grant_type=client_credentials' --data 'scope=all-apis' --data-urlencode 'authorization_details=['"$AUTHORIZATION_DETAILS"']' | jq .access_token | tr -d '"')
# Get index URL
export INDEX_URL=$(curl -X GET -H 'Content-Type: application/json' -H "Authorization: Bearer $TOKEN" --url $WORKSPACE_URL/api/2.0/vector-search/indexes/$INDEX_NAME | jq -r '.status.index_url' | tr -d '"')
# Upsert data into vector search index.
curl -X POST -H 'Content-Type: application/json' -H "Authorization: Bearer $TOKEN" --url https://$INDEX_URL/upsert-data --data '{"inputs_json": "[...]"}'
# Delete data from vector search index
curl -X DELETE -H 'Content-Type: application/json' -H "Authorization: Bearer $TOKEN" --url https://$INDEX_URL/delete-data --data '{"primary_keys": [...]}'
次のコード例は、パーソナルアクセストークン (PAT) を使用してインデックスを更新する方法を示しています。
export TOKEN=...
export INDEX_NAME=...
export WORKSPACE_URL=https://...
# Upsert data into vector search index.
curl -X POST -H 'Content-Type: application/json' -H "Authorization: Bearer $TOKEN" --url $WORKSPACE_URL/api/2.0/vector-search/indexes/$INDEX_NAME/upsert-data --data '{"inputs_json": "..."}'
# Delete data from vector search index
curl -X DELETE -H 'Content-Type: application/json' -H "Authorization: Bearer $TOKEN" --url $WORKSPACE_URL/api/2.0/vector-search/indexes/$INDEX_NAME/delete-data --data '{"primary_keys": [...]}'
ダウンタイムなしでスキーマを変更する方法
インデックスを再構築しない限り、ソース テーブルへのスキーマ変更はサポートされません。これには、既存の列の変更と新しい列の追加が含まれます。インデックス スキーマは作成時に固定されるため、スキーマの変更を有効にするには新しいインデックスを作成する必要があります。
次のステップに従って、ダウンタイムなしでインデックスを再構築してデプロイします。
- ソース テーブルでスキーマの変更を実行します。
- 更新されたスキーマを使用して新しいインデックスを作成します。
- 新しいインデックスの準備ができたら、トラフィックを新しいインデックスに切り替えます。
- 元のインデックスを削除します。