ベクトル検索の取得品質を評価する
ベータ版
この機能はベータ版です。ワークスペース管理者は、 プレビュー ページからこの機能へのアクセスを制御できます。「Databricks プレビューの管理」を参照してください。
一連検索は、データに対するさまざまな検索戦略の関連性を測定および比較する組み込みの検索品質評価を提供します。 ドキュメントから評価クエリを自動的に生成したり、複数の検索戦略を実行したり、詳細なレポートを生成したりできます。
要件
管理されたDelta Sync 検索インデックス。 ベクトル検索のエンドポイントとインデックスの作成を参照してください。
権限
評価ジョブと結果ダッシュボードは、一斉検索インデックスからUnity Catalog権限を継承します。 インデックスへのクエリアクセス権を持つユーザーであれば、誰でも評価実行を開始し、結果ダッシュボードを表示できます。評価実行を開始するユーザーは、ジョブの所有者であり、インデックスの所有者ではありません。
ベクトル検索における検索結果品質評価の仕組み
この評価では、お客様のデータに対して4段階のパイプラインを実行します。
- クエリの生成 :システムはソーステーブルからドキュメントをサンプリングし、LLMを使用して現実的な検索クエリを生成します。自然言語クエリとキーワードクエリを組み合わせたクエリを生成します。
- 複数の 検索戦略を横断的に実行 :生成された各クエリは、ANN、ハイブリッド、全文検索など、複数の検索戦略を使用してインデックスに対して実行されます。各戦略は、リランカーを使用した場合と使用しない場合の両方で評価されます。このアプローチでは、同じクエリセットに対して複数の戦略を並べて比較します。各検索戦略の詳細については、 「検索アルゴリズム」を参照してください。
- スコアの関連性 :LLM審査員が、すべてのクエリと取得された文書のペアを4段階の関連性スケールで評価します。
- コンピュート メトリクスと分析 : システム コンピュートは、信頼区間を使用して品質メトリクスを取得します。 結果は保存されるため、後で確認したり、複数の評価実行結果を比較したりできます。
検索品質評価の実行を開始します
プロセスを開始するには、「検索インデックス」ページで 「検索品質の評価」を クリックします。 インデックスのメタデータに基づいてデフォルト値が事前に設定されているため、設定は不要です。
実行が完了したら、 「結果を表示」 をクリックして結果ダッシュボードを表示します。ダッシュボードの概要については、 「結果ダッシュボード」を参照してください。
いつでも新しい評価を開始するには、 「新しい評価を開始」 をクリックしてください。
結果ダッシュボード
ダッシュボードには、評価実行の結果が表示されます。 [実行の選択] ドロップダウン メニューを使用して、表示する実行を選択します。
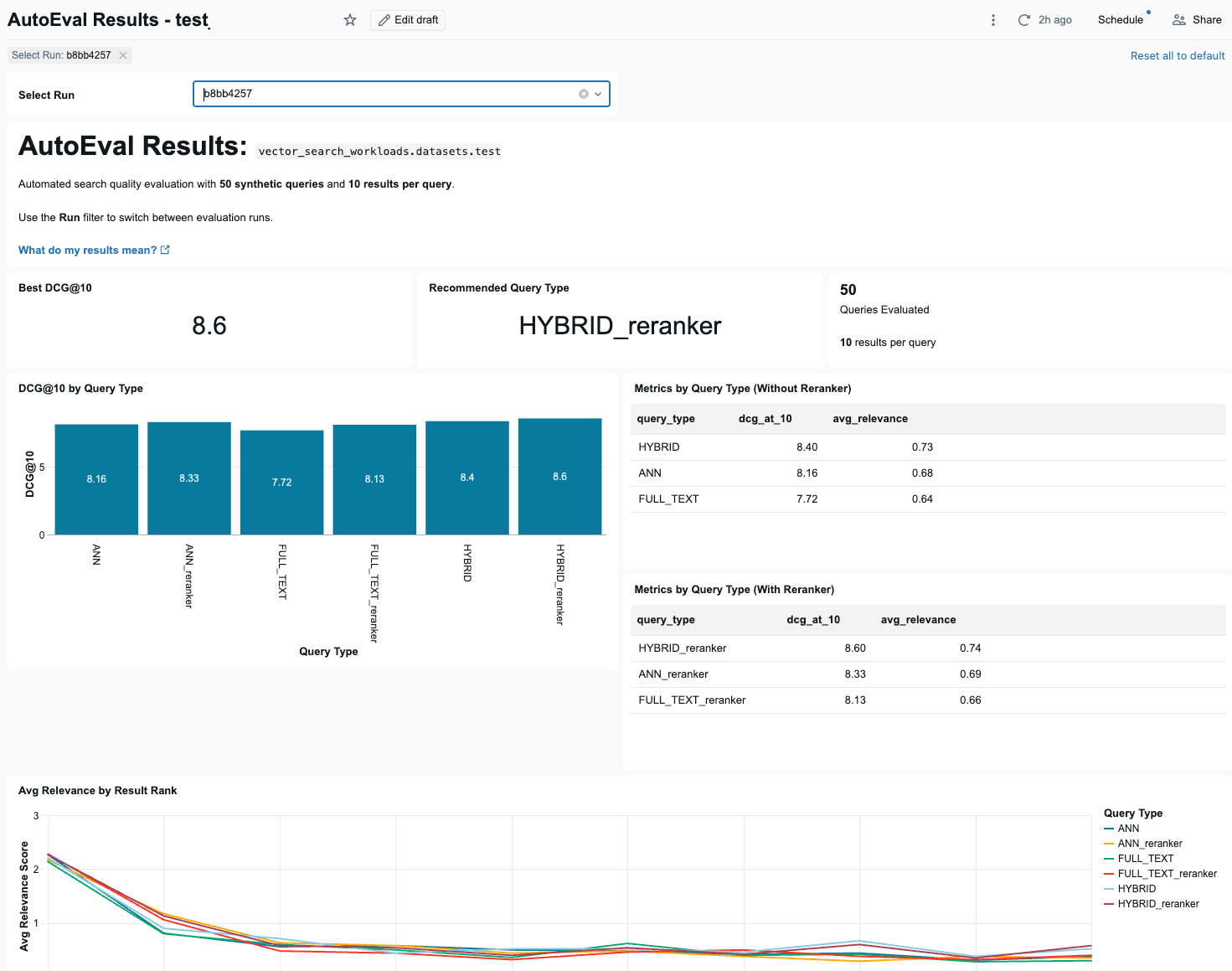
ダッシュボードの上部には、3つの要約指標が表示されます。すべてのクエリタイプの中で最も高いDCG@10スコア、そのスコアを達成した推奨クエリタイプ、および評価されたクエリの数です。
DatabricksがDCG@10を推奨する理由をご覧ください。
要約指標の下には、リランカーを使用した場合と使用しない場合で、クエリの種類ごとにDCG@10スコアを比較した棒グラフがダッシュボードに表示されます。棒グラフの隣には、リランカーを使用した場合と使用しない場合の両方について、各クエリタイプにおけるDCG@10と平均関連性を示す2つの表があります。
続いて、クエリの種類ごとに、検索結果の順位に応じて平均関連性がどのように変化するかを示す折れ線グラフを示します。
ダッシュボードには、平均関連性スコアによる最高および最低のパフォーマンスのクエリ、クエリの種類ごとにベースとリランカーのパフォーマンスを比較した表、失敗したクエリ(トップ1の結果が0(無関係)と評価されたクエリ)の表、およびクエリごとに選択されたメトリクスを評価実行にわたって時間経過とともに示す折れ線グラフも表示されます。
関連性スコアリング
検索品質評価では、LLM(論理言語モデル)を評価者として用い、各クエリと取得された文書のペアを4段階の関連性評価尺度で採点します。
スコア | ラベル | 説明 | 例 |
|---|---|---|---|
3 | 非常に関連性が高い | 文書は、問い合わせに直接回答するか、求められている情報を正確に提供する。 | 質問:「長方形の面積を計算するにはどうすればよいですか?」文書では、長さ×幅の計算式について説明しています。 |
2 | 関連性 | この文書は関連しており、有用な情報を提供していますが、質問に完全に答えるものではない可能性があります。 | 質問:「小切手に記載されているルーティング番号はどこにありますか?」 文書には「小切手の下部に印刷されている」と記載されている(一部未完成) |
1 | 部分的に関連性あり | 文書にはそのトピックについて言及されているが、クエリに役立つ情報は提供されていない。 | 質問:「長方形の面積を計算する方法」 この文書では、長方形の面積について一般的な説明のみを行っています。 |
0 | 関係ない | 文書がクエリと関連していないか、文書の言語がクエリの言語と一致しません。 | 英語での問い合わせ 文書の回答は正しいが、フランス語で書かれている |
関連性/非関連性という二値尺度と比較して、段階尺度は重要な違いを捉えている。例えば、質問に直接答えている文書(スコア3)は、単にその話題に触れているだけの文書(スコア1)とは、意味的に異なる。このきめ細かさはメトリクス、特にDCGにも反映され、より質の高い結果をより重視するようになっている。
すべてのメトリクスには、クエリごとの値にわたる 95% 信頼区間コンピュートが含まれているため、戦略間の差異が統計的に意味があるかどうかを評価できます。
検索メトリクス
ダッシュボードの下部では、選択したメトリクスを経時的に表示できます。 [メトリクス の 選択] ドロップダウン メニューから、表示するメトリクスを選択します。
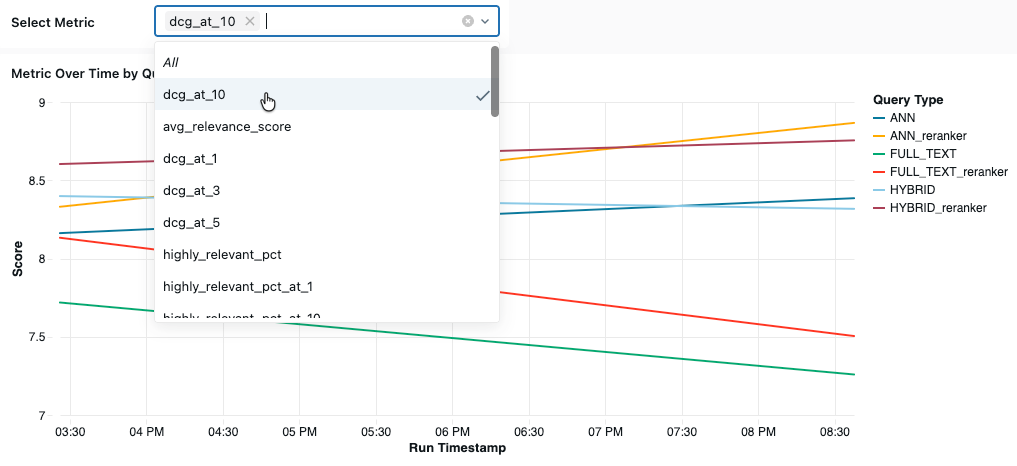
このセクションでは、利用可能なメトリクスについて説明します。
DCG@k — 割引累積利益
DCG@10は、関連性の度合いとランキングにおける表示位置の両方を、0~3の完全な関連性スケールを用いて捉えます。Databricks 、全体的な取得品質を評価するためのプライマリ メトリクスとして DCG@10 を使用することをお勧めします。
- 測定内容 : 上位 10 位までの結果のユーティリティの合計 (位置別に重み付け)。 上位の結果は下位の結果よりも貢献度が高い。
- 仕組み :各結果は、その順位に基づく対数割引によって重み付けされた
2^relevance - 1の利益をもたらします。2^relevance - 1を使用することで(生の関連性スコアではなく)、関連性の高い結果が強調されます。スコア 3 の結果は 7 に貢献し、スコア 1 の結果は 1 に貢献します。最初の結果は最大の効果をもたらし、それより下位の結果は徐々に効果が低くなる。 - 範囲 :0から以下の表に示す理論上の最大値まで。数値が高いほど良い。
すべての結果が3点だった場合の理論上の最大DCG値:
K | 理論上の最大DCG |
|---|---|
1 | 7.00 |
3 | 14.92 |
5 | 20.64 |
10 | 31.80 |
20 | 49.28 |
これらの数値を分かりやすく説明すると、10個の結果すべてが関連性2(0~3のスケール)である場合、DCG@10は13.63になります。このシナリオでは、DCG@10が1ポイント向上することは、意味のある(相対的に+7%の)改善となる。これは、ページ上の検索結果のうち1つが明らかに改善され、上位に表示されるようになる、と考えてよいでしょう。
NDCG@k — 正規化割引累積利益
- 測定対象 :結果が可能な限り最適な順序付けと比較して、どの程度適切に順序付けられているか。NDCGは、DCGを理想的なDCG(関連性の降順で結果を並べ替えた場合のDCG)で割ることによって、DCGを正規化します。
- 範囲 :0~1。スコアが1.0ということは、結果が完全に整っていることを意味します。
- 使用タイミング :関連文書の総数に関係なく、システムが検索結果を正しくランク付けしているかどうかを知りたい場合。詳細な比較については、 「DCG@10 が推奨されるプライマリ メトリクスである理由」を参照してください。
リコール@k
- 測定対象 :上位k件の結果に表示される、既知の関連文書の割合。
- 範囲 :0~1。スコアが1.0ということは、既知の関連文書がすべて取得されたことを意味します。
- 使用時期 :完全性が重要な場合。例えば、関連文書が欠落している場合、LLMが不完全な回答を生成することになるRAGアプリケーションなど。
Precision@k
- 測定対象 :上位k件の結果のうち、関連性のある結果(関連性スコア≧2)の割合。
- 範囲 :0~1。スコアが1.0ということは、上位k件の結果はすべて関連性があることを意味します。
- 使用すべき場面 :検索結果の網羅性よりも結果の質が重要な場合。例えば、無関係な結果がユーザーの信頼を損なう可能性がある検索インターフェースなど。
平均関連性スコア
- 測定対象 :すべてのクエリと結果のペアにおける、LLMによって判定された関連性スコアの平均値。
- 範囲 :0~3。数値が高いほど良い。
- 使用する場合 : 簡単な高品質のスナップショットとして。
関連性分布
-
測定対象 :各関連性カテゴリにおける結果の割合:
- 非常に関連性の高い割合 :スコア3(直接的な回答)の結果。
- 関連度+ % : スコアが2以上(有用)の結果。
- 関連性なし % : スコアが 0 または 1 の結果 (役に立たない)。
-
使用時期 :品質分布の形状を理解するため。2つの戦略は平均スコアが同じでも、その分布は大きく異なる可能性がある。例えば、二峰性分布(3が多く、0が多い)は、クエリパターンがうまく取得されていないことを示唆しており、注意が必要である。
MRR — 平均逆順位
- 測定対象 :ユーザーが最初の関連結果をどれだけ早く見つけられるか。MRRは、クエリ全体における1/rankの平均値であり、rankは最初の関連結果(スコア≧2)の位置を表します。
- 範囲 :0~1。スコアが1.0ということは、最初の結果が常に適切であることを意味します。
- 使用場面 :質問応答システムなど、最上位の結果が最も重要な場合。
MAP@k — 平均精度
- 測定対象 :上位検索結果だけでなく、関連するすべての検索結果におけるランキングの質。MAP コンピュートの精度を各関連結果の位置で計算し、平均します。
- 範囲 :0~1。値が大きいほど、関連文書が常に上位にランク付けされていることを示します。
- 使用タイミング :関連するすべての文書における総合的なランキング品質を捉える単一の数値が必要な場合。
DCG@10 がプライマリ メトリクスとして推奨される理由
DCG@10は、ほとんどのアプリケーションにおいて、検索品質に関する最も包括的な情報を提供します。
- 段階的な関連性はニュアンスを捉えます : バイナリ メトリクスのような精度は、すべての関連ドキュメントを同等に扱います。 質問に完全に答えている文書(スコア3)は、そのトピックに漠然と触れている文書(スコア1)と同じ評価となる。DCGは0~3の関連性スケール全体を使用するため、スコア3の結果はスコア1の結果よりもはるかに大きな貢献度を持つことになります。
- 掲載順位は重要です 。ユーザーはまず上位の結果を見ます。DCGは対数割引を適用するため、1位の結果は10位の結果よりもはるかに高く評価されます。最初の結果は関連性スコアを完全に反映し、10番目の結果はlog₂(11) ≈ 3.46で割った値になります。
- Absolute ユーティリティは、正規化されたメトリクスのミスを明らかにします 。次の表に示す例を考えてみましょう。 どちらの結果セットも、理想的な降順で結果が並んでいるため、NDCG値は1.00という完璧な値を達成しています。しかし、結果セットBは、すべての結果が有用であるため、総価値がほぼ2倍になります(DCG 8.02対4.26)。NDCGは、「無関係な結果3件のうち、良い結果2件が完璧な順位付けになっている場合」と「良い結果5件が完璧な順位付けになっている場合」を区別することができません。DCGは、「ユーザーは実際にどれだけの有用な情報を得られたのか?」という問いに答えます。
DCGとNDCGに関する詳細については、 「割引累積利益」を参照してください。
結果 | ポジション1 | ポジション2 | ポジション3 | ポジション4 | ポジション5 | NDCG@5 | DCG@5 |
|---|---|---|---|---|---|---|---|
結果セットA | 3 | 2 | 0 | 0 | 0 | 1.00 | 4.26 |
結果セットB | 3 | 3 | 3 | 2 | 2 | 1.00 | 8.02 |
単一のメトリクスがすべてのストーリーを語ることはありません。 全体像を把握するには完全なメトリクス スイートを使用し、アプリケーションの品質要件に最も適合するメトリクスを選択してください。
よくあるシナリオ
以下の表は、一般的な評価結果のパターン、その意味、および対処方法について説明しています。
パターン | 意味 | 推奨される行動 |
|---|---|---|
ハイブリッドはANNよりも大幅に優れている | キーワードマッチングによって検索クエリの精度が向上します。 | 本番運用ではハイブリッド検索を使用します。 |
ANNはハイブリッドとほぼ等しい | キーワードはデータに付加価値を与えていません。 | どちらの戦略も有効です。ANNの方がシンプルだ。 |
全文はANNよりはるかに優れている | 埋め込みコンテンツでは、ドメインが適切に反映されない場合があります。 | 埋め込みモデルを微調整するか、全文検索を使用することを検討してください。 |
Reranker はメトリクスを大幅に改善します | クロスエンコーダーは、画質を大幅に向上させる。 | レイテンシの許容範囲に余裕がある場合は、リランカーを有効にしてください。 |
広い信頼区間 | 信頼できる比較を行うにはクエリ数が不足しています。 | 評価クエリの数を増やしてください。 |
すべての戦略のスコアが低い | データ品質または関連性の問題。 | 検索品質を向上させるための手順については、 「ベクトル検索検索品質ガイド」を参照してください。 |