Referência da tabela do sistema de trabalhos
O esquema lakeflow era conhecido anteriormente como workflow. O conteúdo de ambos os esquemas é idêntico.
Este artigo é uma referência para as tabelas do sistema lakeflow, que registram a atividade do trabalho no seu account. Essas tabelas incluem registros de todos os espaços de trabalho do seu account implantados na mesma região de nuvem. Para ver os registros de outra região, é necessário acessar view as tabelas de um workspace implantado nessa região.
Requisitos
- Para acessar essas tabelas do sistema, os usuários devem:
- Ser um administrador de metastore e um administrador de account, ou
- Tenha as permissões
USEeSELECTnos esquemas do sistema. Consulte Conceder acesso às tabelas do sistema.
Tabelas de empregos disponíveis
Todas as tabelas de sistema relacionadas a trabalhos residem no esquema system.lakeflow . Atualmente, o esquema contém seis tabelas:
Tabela | Descrição | Suporta transmissão | Período de retenção gratuito | Inclui dados globais ou regionais |
|---|---|---|---|---|
Rastreia todos os trabalhos criados no account | Sim | 365 dias | Regional | |
Rastreia todas as tarefas de trabalho que são executadas no account | Sim | 365 dias | Regional | |
Rastreia a execução do trabalho e os metadados relacionados | Sim | 365 dias | Regional | |
Rastreia a execução da tarefa do trabalho e os metadados relacionados | Sim | 365 dias | Regional | |
pipeline (visualização pública) | Rastreia todos os pipelines criados no account | Sim | 365 dias | Regional |
pipeline_update_timeline (visualização pública) | Rastreia as atualizações do pipeline e metadados relacionados | Sim | 365 dias | Regional |
Além da janela de retenção de 365 dias, a Databricks retém o registro mais recente para cada entidade nas tabelas de dimensões que mudam lentamente (SCD) (SCD2) (jobs, job_tasks e pipelines). Isso significa que a entrada histórica mais recente para cada job_id, job_task ou pipeline_id está sempre disponível, mesmo que tenha mais de 365 dias. Os registros que excedem o período de 365 dias, exceto a entrada mais recente por entidade, são removidos.
Referência detalhada do esquema
As seções a seguir fornecem referências de esquema para cada uma das tabelas de sistema relacionadas ao Job.
Esquema da tabela de trabalhos
A tabela jobs é uma tabela de dimensões que mudam lentamente (SCD) (SCD2). Quando uma linha muda, uma nova linha é emitida, substituindo logicamente a anterior.
Caminho da tabela : system.lakeflow.jobs
Nome da coluna | Tipo de dados | Descrição | Notas |
|---|---|---|---|
| string | O ID do site account ao qual esse trabalho pertence | |
| string | O ID do site workspace ao qual esse trabalho pertence | |
| string | A ID do trabalho | Somente exclusivo em um único workspace |
| string | O nome do trabalho fornecido pelo usuário | |
| string | A descrição do trabalho fornecida pelo usuário | Esse campo estará vazio se o senhor tiver configurado a chave do gerenciador de clientes. |
| string | O ID do diretor que criou o trabalho | |
| map | As tags personalizadas fornecidas pelo usuário associadas a esse trabalho | |
| carimbo de data/hora | A hora em que o trabalho foi modificado pela última vez | Fuso horário registrado como + 00:00 (UTC) |
| carimbo de data/hora | A hora em que o trabalho foi excluído pelo usuário | Fuso horário registrado como + 00:00 (UTC) |
| string | O ID do usuário ou da entidade de serviço cujas permissões são usadas para a atualização do pipeline. | |
| struct | A configuração do gatilho para a tarefa | Não preenchido para linhas emitidas antes do início de dezembro de 2025. |
| string | O tipo de gatilho para o trabalho | Não preenchido para linhas emitidas antes do início de dezembro de 2025. |
| string | O email do usuário, o ID da entidade de serviço ou o nome do grupo cujas permissões são utilizadas para a execução do Job. | Não preenchido para linhas emitidas antes do início de dezembro de 2025. |
| string | O email do usuário, o ID da entidade de serviço ou o nome do grupo que criou a tarefa. | Não preenchido para linhas emitidas antes do início de dezembro de 2025. |
| boolean | Indica se o trabalho está em pausa. | Não preenchido para linhas emitidas antes do início de dezembro de 2025. |
| long | O tempo limite para a tarefa em segundos | Não preenchido para linhas emitidas antes do início de dezembro de 2025. |
| matriz | Conjunto de regras de saúde definidas para este trabalho. | Não preenchido para linhas emitidas antes do início de dezembro de 2025. |
| struct | Informações de implantação para gerenciamento de tarefas por fontes externas | Não preenchido para linhas emitidas antes do início de dezembro de 2025. |
| carimbo de data/hora | A época em que este trabalho foi criado. O fuso horário registrado é +00:00 (UTC). | Não preenchido para linhas emitidas antes do início de dezembro de 2025. |
Exemplo de consulta
-- Get the most recent version of a job
SELECT
*,
ROW_NUMBER() OVER(PARTITION BY workspace_id, job_id ORDER BY change_time DESC) as rn
FROM
system.lakeflow.jobs QUALIFY rn=1
Job esquema da tabela de tarefas
A tabela de tarefas de trabalho é uma tabela de dimensões que mudam lentamente (SCD) (SCD2). Quando uma linha muda, uma nova linha é emitida, substituindo logicamente a anterior.
Caminho da tabela : system.lakeflow.job_tasks
Nome da coluna | Tipo de dados | Descrição | Notas |
|---|---|---|---|
| string | O ID do site account ao qual esse trabalho pertence | |
| string | O ID do site workspace ao qual esse trabalho pertence | |
| string | A ID do trabalho | Somente exclusivo em um único workspace |
| string | A referência key para uma tarefa em um trabalho | Somente exclusivo em um único trabalho |
| matriz | A chave da tarefa de todas as dependências upstream dessa tarefa | |
| carimbo de data/hora | A hora em que a tarefa foi modificada pela última vez | Fuso horário registrado como + 00:00 (UTC) |
| carimbo de data/hora | A hora em que uma tarefa foi excluída pelo usuário | Fuso horário registrado como + 00:00 (UTC) |
| long | A duração do tempo limite para a tarefa em segundos | Não preenchido para linhas emitidas antes do início de dezembro de 2025. |
| matriz | Conjunto de regras de saúde definidas para esta tarefa de trabalho. | Não preenchido para linhas emitidas antes do início de dezembro de 2025. |
Exemplo de consulta
-- Get the most recent version of a job task
SELECT
*,
ROW_NUMBER() OVER(PARTITION BY workspace_id, job_id ORDER BY change_time DESC) as rn
FROM
system.lakeflow.job_tasks QUALIFY rn=1
Job esquema de tabela da linha do tempo de execução
A tabela de cronograma de execução do trabalho é imutável e completa no momento em que é produzida.
Caminho da tabela : system.lakeflow.job_run_timeline
Nome da coluna | Tipo de dados | Descrição | Notas |
|---|---|---|---|
| string | O ID do site account ao qual esse trabalho pertence | |
| string | O ID do site workspace ao qual esse trabalho pertence | |
| string | A ID do trabalho | Este key é exclusivo apenas em um único workspace |
| string | O ID da execução do trabalho | |
| carimbo de data/hora | A hora de início da execução ou do período de tempo | As informações de fuso horário são registradas no final do valor com |
| carimbo de data/hora | A hora de término da execução ou do período de tempo | As informações de fuso horário são registradas no final do valor com |
| string | O tipo de gatilho que pode disparar uma execução | Para valores possíveis, consulte Valores do tipo de gatilho |
| string | O tipo de execução do trabalho | Para ver os valores possíveis, consulte Valores de tipo de execução |
| string | O nome da execução fornecido pelo usuário associado a essa execução do Job | |
| matriz | Matriz contendo os IDs do trabalho compute para a execução do trabalho pai | Use para identificar o agrupamento de trabalhos usado pelos tipos de execução do |
| string | O resultado da execução do trabalho | Para execuções com mais de uma hora que são divididas em várias linhas, essa coluna é preenchida somente na linha que representa o fim da execução. Para valores possíveis, consulte Valores do estado do resultado. |
| string | O código de encerramento da execução do trabalho | Para execuções com mais de uma hora que são divididas em várias linhas, essa coluna é preenchida somente na linha que representa o fim da execução. Para valores possíveis, consulte Valores do código de terminação. |
| map | Os parâmetros de nível de trabalho usados na execução do trabalho | Contém apenas os valores de job_parameters. Os campos de parâmetros obsoletos ( |
| string | O ID da execução da tarefa de origem. Use esta coluna para identificar qual execução de tarefa acionou esta execução de trabalho. | Não preenchido para linhas emitidas antes do início de dezembro de 2025. |
| string | O ID da execução da tarefa raiz. Use esta coluna para identificar qual execução de tarefa acionou esta execução de trabalho. | Não preenchido para linhas emitidas antes do início de dezembro de 2025. |
| matriz | Detalhes sobre o recurso compute utilizado na execução da tarefa. | Não preenchido para linhas emitidas antes do início de dezembro de 2025. |
| string | O tipo de rescisão para a execução do trabalho | Não preenchido para linhas emitidas antes do início de dezembro de 2025. |
| long | A duração da fase de configuração para execução do Job em segundos | Não preenchido para linhas emitidas antes do início de dezembro de 2025. |
| long | A duração gasta na fila para execução do Job em segundos | Não preenchido para linhas emitidas antes do início de dezembro de 2025. |
| long | A duração total da execução do Job em segundos | Não preenchido para linhas emitidas antes do início de dezembro de 2025. |
| long | A duração da fase de limpeza para execução do Job em segundos | Não preenchido para linhas emitidas antes do início de dezembro de 2025. |
| long | A duração da fase de execução para a execução do Job em segundos | Não preenchido para linhas emitidas antes do início de dezembro de 2025. |
Exemplo de consulta
-- This query gets the daily job count for a workspace for the last 7 days:
SELECT
workspace_id,
COUNT(DISTINCT run_id) as job_count,
to_date(period_start_time) as date
FROM system.lakeflow.job_run_timeline
WHERE
period_start_time > CURRENT_TIMESTAMP() - INTERVAL 7 DAYS
GROUP BY ALL
-- This query returns the daily job count for a workspace for the last 7 days, distributed by the outcome of the job run.
SELECT
workspace_id,
COUNT(DISTINCT run_id) as job_count,
result_state,
to_date(period_start_time) as date
FROM system.lakeflow.job_run_timeline
WHERE
period_start_time > CURRENT_TIMESTAMP() - INTERVAL 7 DAYS
AND result_state IS NOT NULL
GROUP BY ALL
-- This query returns the average time of job runs, measured in seconds. The records are organized by job. A top 90 and a 95 percentile column show the average lengths of the job's longest runs.
with job_run_duration as (
SELECT
workspace_id,
job_id,
run_id,
CAST(SUM(period_end_time - period_start_time) AS LONG) as duration
FROM
system.lakeflow.job_run_timeline
WHERE
period_start_time > CURRENT_TIMESTAMP() - INTERVAL 7 DAYS
GROUP BY ALL
)
SELECT
t1.workspace_id,
t1.job_id,
COUNT(DISTINCT t1.run_id) as runs,
MEAN(t1.duration) as mean_seconds,
AVG(t1.duration) as avg_seconds,
PERCENTILE(t1.duration, 0.9) as p90_seconds,
PERCENTILE(t1.duration, 0.95) as p95_seconds
FROM
job_run_duration t1
GROUP BY ALL
ORDER BY mean_seconds DESC
LIMIT 100
-- This query provides a historical runtime for a specific job based on the `run_name` parameter. For the query to work, you must set the `run_name`.
SELECT
workspace_id,
run_id,
SUM(period_end_time - period_start_time) as run_time
FROM system.lakeflow.job_run_timeline
WHERE
run_type="SUBMIT_RUN"
AND run_name = :run_name
AND period_start_time > CURRENT_TIMESTAMP() - INTERVAL 60 DAYS
GROUP BY ALL
-- This query collects a list of retried job runs with the number of retries for each run.
with repaired_runs as (
SELECT
workspace_id, job_id, run_id, COUNT(*) - 1 as retries_count
FROM system.lakeflow.job_run_timeline
WHERE result_state IS NOT NULL
GROUP BY ALL
HAVING retries_count > 0
)
SELECT
*
FROM repaired_runs
ORDER BY retries_count DESC
LIMIT 10;
Job tarefa execução esquema de tabela de linha do tempo
A tabela de cronograma de execução da tarefa de trabalho é imutável e completa no momento em que é produzida.
Caminho da tabela : system.lakeflow.job_task_run_timeline
Nome da coluna | Tipo de dados | Descrição | Notas |
|---|---|---|---|
| string | O ID do site account ao qual esse trabalho pertence | |
| string | O ID do site workspace ao qual esse trabalho pertence | |
| string | A ID do trabalho | Somente exclusivo em um único workspace |
| string | A ID da execução da tarefa | |
| string | O ID da execução do trabalho | |
| string | A ID da execução principal | |
| carimbo de data/hora | O tempo de início da tarefa ou do período de tempo | As informações de fuso horário são registradas no final do valor com |
| carimbo de data/hora | A hora de término da tarefa ou do período de tempo | As informações de fuso horário são registradas no final do valor com |
| string | A referência key para uma tarefa em um trabalho | Este endereço key é exclusivo apenas em um único trabalho |
| matriz | A matriz de computação contém IDs de clustering de trabalho, clustering interativo e armazém SQL usados pela tarefa de trabalho. | |
| string | O resultado da execução do Job tarefa | Para tarefas de execução com mais de uma hora que são divididas em várias linhas, essa coluna é preenchida somente na linha que representa o fim da execução. Para valores possíveis, consulte Valores do estado do resultado. |
| string | O código de encerramento da execução da tarefa | Para tarefas de execução com mais de uma hora que são divididas em várias linhas, essa coluna é preenchida somente na linha que representa o fim da execução. Para valores possíveis, consulte Valores do código de terminação. |
| matriz | Detalhes sobre o recurso compute utilizado na execução da tarefa do Job | Não preenchido para linhas emitidas antes do início de dezembro de 2025. |
| string | O tipo de rescisão para execução da tarefa do trabalho | Não preenchido para linhas emitidas antes do início de dezembro de 2025. |
| map | Os parâmetros de nível de tarefa usados na execução da tarefa do trabalho | Contém apenas os valores de job_parameters. Os campos de parâmetros obsoletos ( |
| long | A duração da fase de configuração para a execução da tarefa, em segundos. | Não preenchido para linhas emitidas antes do início de dezembro de 2025. |
| long | A duração da fase de limpeza para a execução da tarefa, em segundos. | Não preenchido para linhas emitidas antes do início de dezembro de 2025. |
| long | A duração da fase de execução da tarefa é medida em segundos. | Não preenchido para linhas emitidas antes do início de dezembro de 2025. |
esquema da tabela de pipeline
A tabela pipeline é uma tabela de dimensões que mudam lentamente (SCD) (SCD2). Quando uma linha muda, uma nova linha é emitida, substituindo logicamente a anterior.
Caminho da tabela : system.lakeflow.pipelines
Nome da coluna | Tipo de dados | Descrição | Notas |
|---|---|---|---|
| string | O ID do site account ao qual este pipeline pertence | |
| string | O ID do site workspace ao qual este pipeline pertence | |
| string | A ID do pipeline | Somente exclusivo em um único workspace |
| string | O tipo do pipeline | Para ver os valores possíveis, consulte Valores do tipo de pipeline |
| string | O nome do pipeline fornecido pelo usuário | |
| string | O email do usuário, o ID da entidade de serviço ou o nome do grupo que criou o pipeline | |
| string | O email do usuário, o ID da entidade de serviço ou o nome do grupo cujas permissões são utilizadas para a execução pipeline . | |
| map | As tags personalizadas fornecidas pelo usuário associadas a esse trabalho | |
| struct | As configurações do pipeline | Consulte Configurações do pipeline |
| map | A configuração do pipeline fornecida pelo usuário | |
| carimbo de data/hora | A hora em que o pipeline foi modificado pela última vez | Fuso horário registrado como + 00:00 (UTC) |
| carimbo de data/hora | A hora em que o pipeline foi excluído pelo usuário | Fuso horário registrado como + 00:00 (UTC) |
| carimbo de data/hora | O momento em que um pipeline foi criado pelo usuário. O fuso horário registrado é +00:00 (UTC). | Não preenchido para linhas emitidas antes do início de dezembro de 2025. |
Exemplo de consulta
-- Get the most recent version of a pipeline
SELECT
*,
ROW_NUMBER() OVER(PARTITION BY workspace_id, pipeline_id ORDER BY change_time DESC) as rn
FROM
system.lakeflow.pipelines QUALIFY rn=1
-- Enrich billing logs with pipeline metadata
with latest_pipelines AS (
SELECT
*,
ROW_NUMBER() OVER(PARTITION BY workspace_id, pipeline_id ORDER BY change_time DESC) as rn
FROM
system.lakeflow.pipelines QUALIFY rn=1
)
SELECT
usage.*,
pipelines.*
FROM system.billing.usage
LEFT JOIN latest_pipelines
ON (usage.workspace_id = pipelines.workspace_id
AND usage.usage_metadata.dlt_pipeline_id = pipelines.pipeline_id)
WHERE
usage.usage_metadata.dlt_pipeline_id IS NOT NULL
Esquema da tabela de cronograma de atualização do pipeline
A tabela de cronograma de atualização do pipeline é imutável e completa no momento em que é produzida.
Caminho da tabela : system.lakeflow.pipeline_update_timeline
Nome da coluna | Tipo de dados | Descrição | Notas |
|---|---|---|---|
| string | O ID do site account ao qual este pipeline pertence | |
| string | O ID do site workspace ao qual este pipeline pertence | |
| string | A ID do pipeline | Somente exclusivo em um único workspace |
| string | O ID da atualização do pipeline | Somente exclusivo em um único workspace |
| string | O tipo de atualização do pipeline | Para valores possíveis, consulte Valores do tipo de atualização do pipeline |
| string | O ID da solicitação. Ajuda a entender quantas vezes uma atualização teve que ser repetida/reiniciada | |
| string | O email do usuário, o ID da entidade de serviço ou o nome do grupo cujas permissões são usadas para a atualização pipeline . | |
| string | O que desencadeou esta atualização | Para valores possíveis, consulte Valores do tipo de gatilho do pipeline |
| struct | Os detalhes do gatilho do pipeline | Para valores possíveis, consulte Detalhes do tipo de gatilho do pipeline |
| string | O resultado da atualização do pipeline | Para atualizações com duração superior a 1 hora divididas em várias linhas, esta coluna é preenchida apenas na linha que representa o fim da atualização. Para valores possíveis, consulte Referência de resultados do pipeline. |
| struct | Detalhes sobre o recurso compute usado na atualização pipeline | |
| carimbo de data/hora | O tempo de início da atualização do pipeline ou da hora. O valor é armazenado como um registro de data e hora UTC. | As informações de fuso horário são registradas no final do valor com |
| carimbo de data/hora | O horário de término da atualização do pipeline ou da hora. O valor é armazenado como um registro de data e hora UTC. | As informações de fuso horário são registradas no final do valor com |
| matriz | Uma lista de tabelas para atualizar sem fullRefresh | |
| matriz | Uma lista de tabelas para atualizar com fullRefresh | |
| matriz | Uma lista de fluxos de transmissão para limpar os pontos de verificação para |
Exemplo de consulta
-- This query gets the daily pipeline update count for a workspace for the last 7 days:
SELECT
workspace_id,
COUNT(DISTINCT update_id) as update_count,
to_date(period_start_time) as date
FROM system.lakeflow.pipeline_update_timeline
WHERE
period_start_time > CURRENT_TIMESTAMP() - INTERVAL 7 DAYS
GROUP BY ALL
-- This query returns the daily pipeline update count for a workspace for the last 7 days, distributed by the outcome of the pipeline update.
SELECT
workspace_id,
COUNT(DISTINCT update_id) as update_count,
result_state,
to_date(period_start_time) as date
FROM system.lakeflow.pipeline_update_timeline
WHERE
period_start_time > CURRENT_TIMESTAMP() - INTERVAL 7 DAYS
AND result_state IS NOT NULL
GROUP BY ALL
-- This query returns the average time of pipeline updates, measured in seconds. The records are organized by pipeline. A top 90 and a 95 percentile column show the average lengths of the pipeline's longest updates.
with pipeline_update_duration as (
SELECT
workspace_id,
pipeline_id,
update_id,
CAST(SUM(period_end_time - period_start_time) AS LONG) as duration
FROM
system.lakeflow.pipeline_update_timeline
WHERE
period_start_time > CURRENT_TIMESTAMP() - INTERVAL 7 DAYS
GROUP BY ALL
)
SELECT
t1.workspace_id,
t1.pipeline_id,
COUNT(DISTINCT t1.update_id) as update_count,
MEAN(t1.duration) as mean_seconds,
AVG(t1.duration) as avg_seconds,
PERCENTILE(t1.duration, 0.9) as p90_seconds,
PERCENTILE(t1.duration, 0.95) as p95_seconds
FROM
pipeline_update_duration t1
GROUP BY ALL
ORDER BY mean_seconds DESC
LIMIT 100
Padrões comuns do site join
As seções a seguir fornecem exemplos de consultas que destacam os padrões join comumente usados para as tabelas do sistema Job.
unir as tabelas de linha do tempo do Job e da execução do Job
Enriquecer a execução do trabalho com um nome de trabalho
with jobs as (
SELECT
*,
ROW_NUMBER() OVER (PARTITION BY workspace_id, job_id ORDER BY change_time DESC) as rn
FROM system.lakeflow.jobs QUALIFY rn=1
)
SELECT
job_run_timeline.*
jobs.name
FROM system.lakeflow.job_run_timeline
LEFT JOIN jobs USING (workspace_id, job_id)
unir as tabelas de linha do tempo e de uso da execução do trabalho
Enriquecer cada faturamento log com metadados de execução de trabalho
A consulta a seguir enriquece logs de faturamento com metadados de execução de trabalhos, tanto clássicos quanto serverless :
with aggregated_job_runs AS (
SELECT
j.workspace_id,
COALESCE(t.job_id, j.job_id) as origin_job_id,
COALESCE(t.job_run_id, j.run_id) AS origin_job_run_id,
j.job_id as billing_job_id,
j.run_id as billing_run_id,
CASE WHEN j.root_task_run_id IS NOT NULL THEN true ELSE false END AS is_workflow_run
FROM
system.lakeflow.job_run_timeline j
LEFT JOIN
system.lakeflow.job_task_run_timeline t
ON
j.workspace_id = t.workspace_id
AND j.root_task_run_id = t.run_id
WHERE j.period_start_time >= CURRENT_DATE() - INTERVAL 7 DAYS
GROUP BY ALL
),
billing_logs_enriched AS (
SELECT
t2.origin_job_id,
t2.origin_job_run_id,
t1.*
FROM system.billing.usage t1
INNER JOIN aggregated_job_runs t2
ON t1.workspace_id = t2.workspace_id
AND t1.usage_metadata.job_id = t2.billing_job_id
AND t1.usage_metadata.job_run_id = t2.billing_run_id
WHERE
billing_origin_product="JOBS" AND usage_date >= CURRENT_DATE() - INTERVAL 7 DAYS
)
SELECT
workspace_id,
origin_job_id AS job_id,
origin_job_run_id AS run_id,
sku_name,
SUM(usage_quantity) as total_usage_quantity,
SUM(CASE WHEN usage_metadata.job_run_id != origin_job_run_id THEN usage_quantity ELSE 0 END) AS workflow_run_usage_quantity,
COUNT(DISTINCT usage_metadata.job_run_id) - 1 AS workflow_runs
FROM billing_logs_enriched
GROUP BY ALL
Calcular o custo por execução do trabalho
Essa consulta se junta à tabela do sistema billing.usage para calcular um custo por execução de trabalho.
with jobs_usage AS (
SELECT
*,
usage_metadata.job_id,
usage_metadata.job_run_id as run_id,
identity_metadata.run_as as run_as
FROM system.billing.usage
WHERE billing_origin_product="JOBS"
),
jobs_usage_with_usd AS (
SELECT
jobs_usage.*,
usage_quantity * pricing.default as usage_usd
FROM jobs_usage
LEFT JOIN system.billing.list_prices pricing ON
jobs_usage.sku_name = pricing.sku_name
AND pricing.price_start_time <= jobs_usage.usage_start_time
AND (pricing.price_end_time >= jobs_usage.usage_start_time OR pricing.price_end_time IS NULL)
AND pricing.currency_code="USD"
),
jobs_usage_aggregated AS (
SELECT
workspace_id,
job_id,
run_id,
FIRST(run_as, TRUE) as run_as,
sku_name,
SUM(usage_usd) as usage_usd,
SUM(usage_quantity) as usage_quantity
FROM jobs_usage_with_usd
GROUP BY ALL
)
SELECT
t1.*,
MIN(period_start_time) as run_start_time,
MAX(period_end_time) as run_end_time,
FIRST(result_state, TRUE) as result_state
FROM jobs_usage_aggregated t1
LEFT JOIN system.lakeflow.job_run_timeline t2 USING (workspace_id, job_id, run_id)
GROUP BY ALL
ORDER BY usage_usd DESC
LIMIT 100
Obter uso logs para um trabalho SUBMIT_RUN
SELECT
*
FROM system.billing.usage
WHERE
EXISTS (
SELECT 1
FROM system.lakeflow.job_run_timeline
WHERE
job_run_timeline.job_id = usage_metadata.job_id
AND run_name = :run_name
AND workspace_id = :workspace_id
)
juntar as tabelas de cronograma e clustering do Job tarefa execução
Enriquecer a execução da tarefa do trabalho com metadados de clustering
with clusters as (
SELECT
*,
ROW_NUMBER() OVER (PARTITION BY workspace_id, cluster_id ORDER BY change_time DESC) as rn
FROM system.compute.clusters QUALIFY rn=1
),
exploded_task_runs AS (
SELECT
*,
EXPLODE(compute_ids) as cluster_id
FROM system.lakeflow.job_task_run_timeline
WHERE array_size(compute_ids) > 0
)
SELECT
*
FROM exploded_task_runs t1
LEFT JOIN clusters t2
USING (workspace_id, cluster_id)
Encontrar trabalho em execução em todas as finalidades compute
Essa consulta se une à tabela do sistema compute.clusters para retornar jobs recentes que estejam em execução em compute para múltiplas finalidades em vez de compute de jobs.
with clusters AS (
SELECT
*,
ROW_NUMBER() OVER(PARTITION BY workspace_id, cluster_id ORDER BY change_time DESC) as rn
FROM system.compute.clusters
WHERE cluster_source="UI" OR cluster_source="API"
QUALIFY rn=1
),
job_tasks_exploded AS (
SELECT
workspace_id,
job_id,
EXPLODE(compute_ids) as cluster_id
FROM system.lakeflow.job_task_run_timeline
WHERE period_start_time >= CURRENT_DATE() - INTERVAL 30 DAY
GROUP BY ALL
),
all_purpose_cluster_jobs AS (
SELECT
t1.*,
t2.cluster_name,
t2.owned_by,
t2.dbr_version
FROM job_tasks_exploded t1
INNER JOIN clusters t2 USING (workspace_id, cluster_id)
)
SELECT * FROM all_purpose_cluster_jobs LIMIT 10;
Encontrar trabalhos que não foram executados nos últimos 30 dias
Essa consulta une as tabelas de sistema lakeflow.jobs e lakeflow.job_run_timeline para retornar o trabalho que não foi executado nos últimos 30 dias.
with latest_jobs AS (
SELECT
*,
ROW_NUMBER() OVER (PARTITION BY workspace_id, job_id ORDER BY change_time DESC) as rn
FROM system.lakeflow.jobs QUALIFY rn=1
),
latest_not_deleted_jobs AS (
SELECT
workspace_id,
job_id,
name,
change_time,
tags
FROM latest_jobs WHERE delete_time IS NULL
),
last_seen_job_timestamp AS (
SELECT
workspace_id,
job_id,
MAX(period_start_time) as last_executed_at
FROM system.lakeflow.job_run_timeline
WHERE
run_type="JOB_RUN"
GROUP BY ALL
)
SELECT
t1.workspace_id,
t1.job_id,
t1.name,
t1.change_time as last_modified_at,
t2.last_executed_at,
t1.tags
FROM latest_not_deleted_jobs t1
LEFT JOIN last_seen_job_timestamp t2
USING (workspace_id, job_id)
WHERE
(t2.last_executed_at <= CURRENT_DATE() - INTERVAL 30 DAYS) OR (t2.last_executed_at IS NULL)
ORDER BY last_executed_at ASC
Painel de monitoramento de trabalhos
O painel a seguir usa tabelas do sistema para ajudar o senhor a começar a monitorar o trabalho e a integridade operacional. Ele inclui casos de uso comuns, como acompanhamento do desempenho do trabalho, monitoramento de falhas e utilização de recursos.
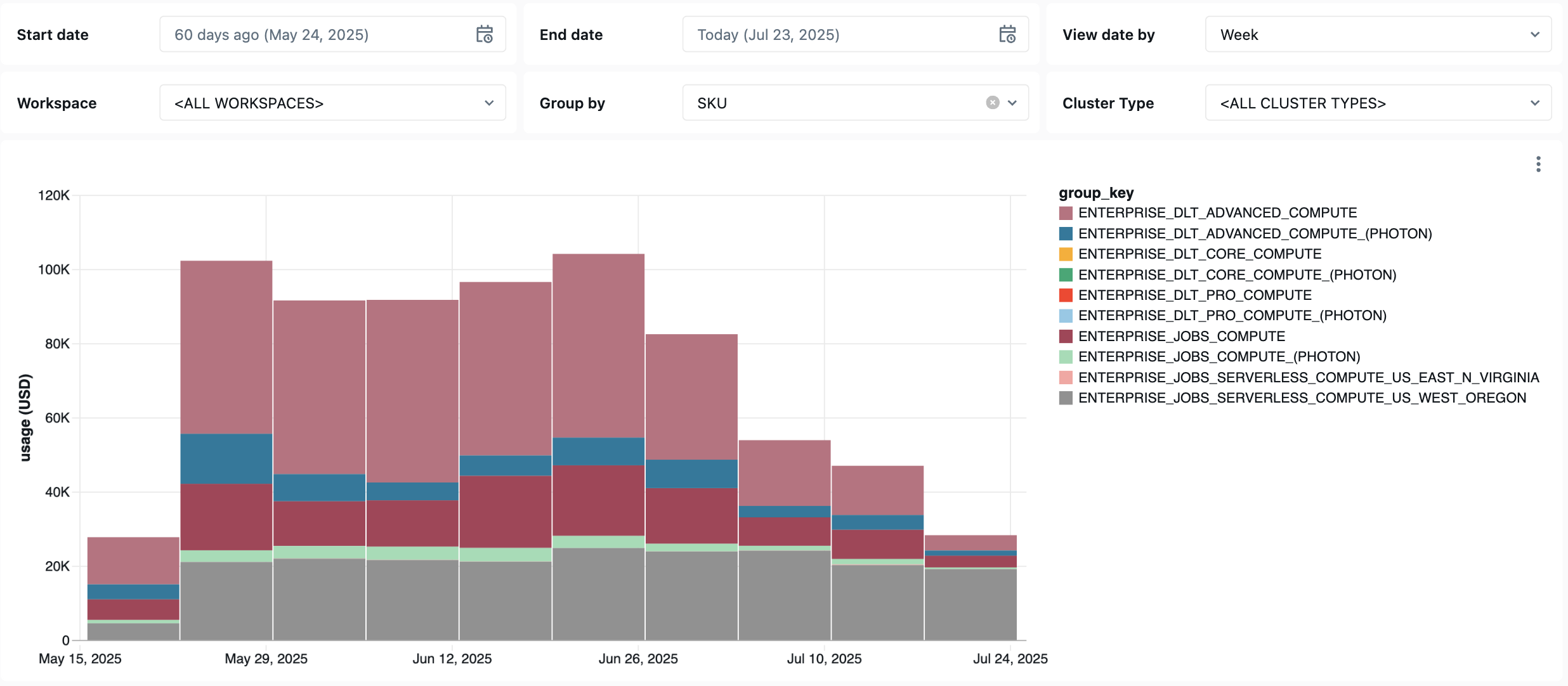
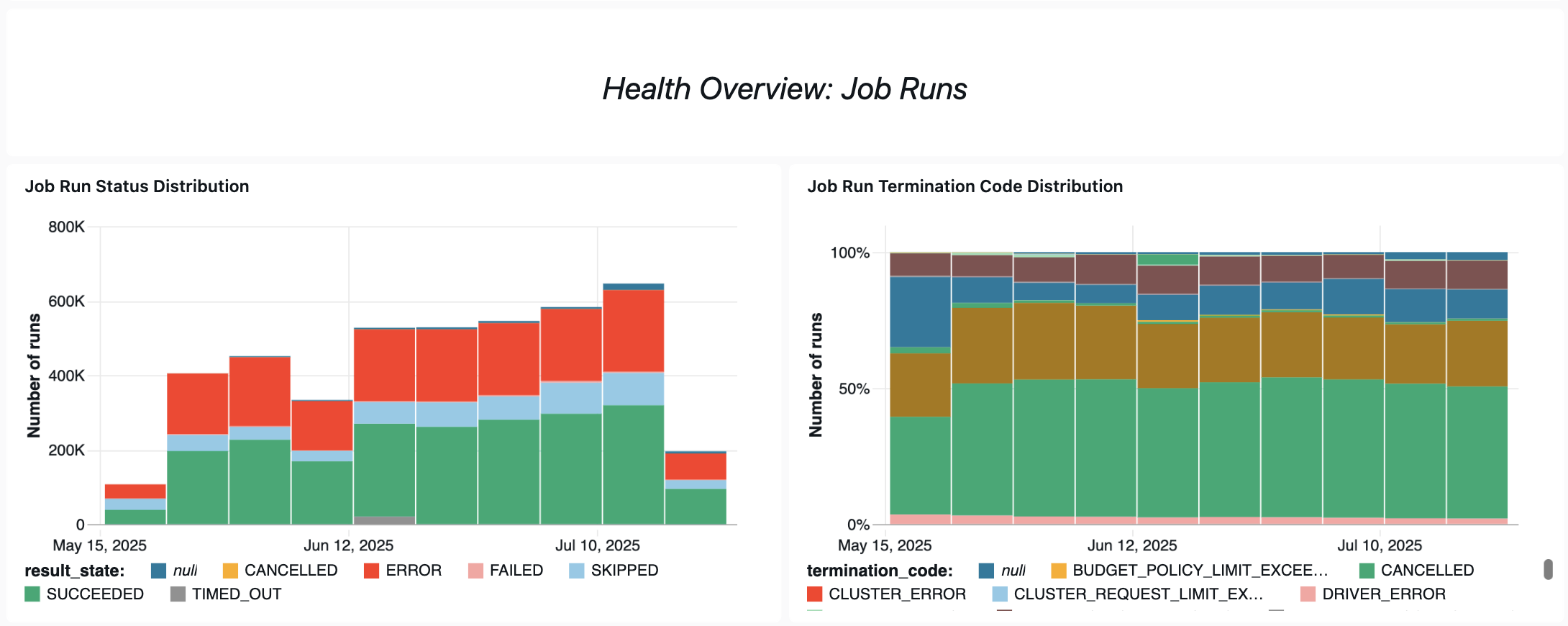
Para obter informações sobre downloads do painel, consulte Monitorar custos do trabalho & desempenho com tabelas do sistema
Solução de problemas
Job não está registrado na tabela lakeflow.jobs
Se um trabalho não estiver visível nas tabelas do sistema:
- O trabalho foi criado em uma região diferente
- Criação recente de empregos (defasagem da tabela)
- Embora o registro mais recente para cada
job_idseja sempre retido, registros históricos mais antigos além da janela de retenção de 365 dias são removidos. Se você precisar de um novo registro, modifique qualquer um dos campos do trabalho presentes no esquema para emitir uma nova linha.
Não é possível encontrar um trabalho visto na tabela job_run_timeline
Nem todos os trabalhos executados são visíveis em todos os lugares. Enquanto as entradas JOB_RUN aparecem em todas as tabelas relacionadas ao trabalho, WORKFLOW_RUN (Notebook fluxo de trabalho execução) são registradas apenas em job_run_timeline e SUBMIT_RUN (one-time submitted execução) são registradas apenas em ambas as tabelas de cronograma. Essas execuções não são preenchidas em outras tabelas do sistema de trabalho, como jobs ou job_tasks.
Consulte a tabela de tipos de execução abaixo para obter uma análise detalhada de onde cada tipo de execução é visível e acessível.
Job execução não visível na tabela billing.usage
Em system.billing.usage, o usage_metadata.job_id só é preenchido para o trabalho que é executado no Job compute ou serverless compute.
Além disso, o WORKFLOW_RUN Job não tem sua própria atribuição usage_metadata.job_id ou usage_metadata.job_run_id em system.billing.usage.
Em vez disso, o uso do compute é atribuído ao Notebook pai que o acionou.
Isso significa que quando um Notebook inicia a execução de um fluxo de trabalho, todos os custos do compute aparecem sob o uso do Notebook pai, e não como um fluxo de trabalho Job separado.
Consulte a referência de metadados de uso para obter mais informações.
Calcule o custo de um trabalho executado em uma máquina multifuncional compute
Não é possível calcular com precisão o custo exato do trabalho executado no site compute com 100% de precisão. Quando um trabalho é executado em um site interativo (all-purpose) compute, várias cargas de trabalho, como Notebook, consultas SQL ou outro trabalho, são executadas simultaneamente no mesmo recurso compute. Como os recursos de clustering são compartilhados, não há um mapeamento direto 1:1 entre os custos de computação e a execução de um trabalho individual.
Para um acompanhamento preciso dos custos do trabalho, o site Databricks recomenda a execução do trabalho em um site dedicado compute ou serverless compute, onde usage_metadata.job_id e usage_metadata.job_run_id permitem uma atribuição precisa dos custos.
Se o senhor precisar usar o site compute para todos os fins, é possível:
- Monitorar o uso e os custos gerais de clustering em
system.billing.usagecom base emusage_metadata.cluster_id. - Acompanhe as métricas de tempo de execução do trabalho separadamente.
- Considere que qualquer estimativa de custo será aproximada devido ao recurso compartilhado.
Consulte a referência de metadados de uso para obter mais informações sobre a atribuição de custos.
Valores de referência
A seção a seguir inclui referências para colunas selecionadas em tabelas relacionadas ao trabalho.
Lógica de divisão nas tabelas da linha do tempo
As colunas period_start_time e period_end_time nas tabelas job_run_timeline e job_task_run_timeline registram o período ativo de uma execução de trabalho ou execução de tarefa.
:::aviso Mudança importante
A partir de 19 de janeiro de 2026, as novas linhas emitidas para as tabelas da linha do tempo usarão uma lógica de fatiamento alinhada à hora do relógio. As linhas existentes permanecerão inalteradas.
As fatias são criadas em intervalos de uma hora, com base no horário de início da execução. Por exemplo, uma tarefa iniciada às 16h47 cria intervalos de tempo das 16h47 às 17h47, das 17h47 às 18h47 e assim por diante.
As fatias serão alinhadas aos limites das horas do relógio. Por exemplo, uma tarefa iniciada às 16h47 criará intervalos de tempo das 16h47 às 17h, das 17h às 18h, das 18h às 19h e assim por diante. Consulte a lógica de fatiamento alinhada ao horário do relógio para obter detalhes.
:::
Cada linha registra até uma hora de tempo de execução. As execuções que duram mais de 1 hora são registradas em várias linhas. Esse fatiamento garante granularidade horária para o monitoramento de trabalhos de longa duração.
Se uma execução nunca começou, ela é representada por uma linha em que period_start_time é igual a period_end_time. Isso indica que não há tempo de execução ativo. Para entender por que a execução não começou, consulte a coluna termination_code.
Trabalho de curta duração
Para execuções inferiores a 1 hora, uma única linha é emitida, com period_start_time definido como o horário de início da execução e period_end_time definido como o horário de término da execução.
Por exemplo, um trabalho iniciado às 12:13 UTC e encerrado às 12:45 UTC é representado por uma única linha:
ID do espaço de trabalho | ID do trabalho | run_id | horário_de_início do período | horário_de_fim do período |
|---|---|---|---|---|
6051921418418893 | 280090038844882 | 174832649710507 | 2025-06-08T 12:13:01.605 | 2025-06-08T 12:45:06.09 |
Trabalho de longa duração
Para execuções que duram mais de 1 hora, várias linhas são emitidas com o mesmo run_id, cada uma representando até uma hora da duração da execução:
- A primeira linha começa no horário real de início da execução e termina no final da primeira hora de execução.
- As linhas intermediárias (se houver) abrangem janelas horárias completas, alinhadas à fatia anterior
period_end_time. - A última linha começa no início da fatia anterior e termina no horário de término real da execução.
Por exemplo, um trabalho que é executado das 4:47 PM UTC às 8:28 PM UTC é dividido em várias linhas. Cada linha representa uma hora de atividade, exceto a última linha, que pode ser mais curta:
ID do espaço de trabalho | ID do trabalho | run_id | horário_de_início do período | horário_de_fim do período |
|---|---|---|---|---|
6051921418418893 | 280090038844882 | 55408597258956 | 2025-07-01 T 16:47:55.992 | 2025-07-01 T 17:47:56.434 |
6051921418418893 | 280090038844882 | 55408597258956 | 2025-07-01 T 17:47:56.434 | 2025-07-01T 18:47:58.876 |
6051921418418893 | 280090038844882 | 55408597258956 | 2025-07-01T 18:47:58.876 | 2025-07-01T 19:47:59.682 |
6051921418418893 | 280090038844882 | 55408597258956 | 2025-07-01T 19:47:59.682 | 2025-07-01T 20:28:29.743 |
Lógica de fatiamento alinhada ao horário do relógio
Essa lógica de segmentação se aplica a novas linhas nas tabelas de cronograma de tarefas a partir de 19 de janeiro de 2026 .
A partir de 19 de janeiro de 2026, as tabelas da linha do tempo usarão fatiamento alinhado com a hora do relógio. Todos os intervalos de tempo estão alinhados aos limites de horas padrão do relógio.
Para tarefas com duração inferior a 1 hora que começam e terminam dentro da mesma hora, é emitida uma única linha:
ID do espaço de trabalho | ID do trabalho | run_id | horário_de_início do período | horário_de_fim do período |
|---|---|---|---|---|
6051921418418893 | 280090038844882 | 174832649710507 | 2025-12-08T12:13:01.605 | 2025-12-08T12:45:06.009 |
Para a execução de tarefas que ultrapassam os limites de horas do relógio, são emitidas várias linhas com fatias alinhadas às horas do relógio:
- A primeira linha começa no horário de início real da execução e termina no limite da próxima hora do relógio.
- As linhas intermediárias (se houver) abrangem horas completas do relógio. Por exemplo: das 14h às 15h e das 15h às 16h.
- A última linha começa no limite de uma hora do relógio e termina na hora final real da execução.
Por exemplo, a execução de uma tarefa que ocorre das 1h25 UTC às 3h40 UTC é dividida em três linhas:
ID do espaço de trabalho | ID do trabalho | run_id | horário_de_início do período | horário_de_fim do período |
|---|---|---|---|---|
6051921418418893 | 280090038844882 | 55408597258956 | 2025-12-01T01:25:00.000 | 2025-12-01T02:00:00.000 |
6051921418418893 | 280090038844882 | 55408597258956 | 2025-12-01T02:00:00.000 | 2025-12-01T03:00:00.000 |
6051921418418893 | 280090038844882 | 55408597258956 | 2025-12-01T03:00:00.000 | 2025-12-01T03:40:00.000 |
Valores do tipo de gatilho
Para obter mais informações sobre os tipos de acionadores de Job, consulte Automatizar Jobs com programações e acionadores.
Nas tabelas job_run_timeline e jobs, os valores possíveis para a coluna trigger_type são:
Tipo de trigger | Descrição | Tabelas aplicáveis |
|---|---|---|
| A tarefa ou execução é acionada por um gatilho contínuo que mantém a tarefa em execução. |
|
| A tarefa ou execução é acionada por um programador recorrente usando a sintaxe cron. |
|
| A tarefa ou execução é acionada quando novos arquivos chegam a um local de armazenamento configurado. |
|
| A tarefa ou execução é acionada por um evento de disponibilização de versão do modelo. |
|
| A execução da tarefa foi acionada por um gatilho manual único ou API . |
|
| A tarefa ou execução foi acionada como uma nova tentativa de uma execução anterior que havia falhado. |
|
| A tarefa ou execução é acionada por um programa periódico com base em um intervalo de tempo (por exemplo, a cada hora). |
|
| A execução do Job foi acionada como parte de uma tarefa de execução de outro Job. |
|
| A tarefa ou execução é acionada por uma atualização de tabela usando uma configuração de gatilho de tabela. |
|
| O tipo de gatilho não está definido. Isso pode ocorrer em registros de tarefas mais antigos ou em tarefas onde o tipo de gatilho não foi configurado. |
|
Valores de tipo de execução
Na tabela job_run_timeline, os valores possíveis para a coluna run_type são:
Tipo | Descrição | Localização da interface do usuário | API ponto final | Tabelas do sistema |
|---|---|---|---|---|
| Execução de trabalho padrão | Jobs & Job execução UI | Endpoint /Job e /Job/execução | Trabalho, trabalho, trabalho, trabalho, trabalho |
| Execução única via POST /Job/execução/submit | Job execução somente UI | Somente o endpoint /Job/execução | Trabalho, trabalho |
| execução iniciada a partir do Notebook fluxo de trabalho | Não visível | Não acessível | Trabalho |
Valores do estado do resultado
Nas tabelas job_task_run_timeline e job_run_timeline, os valores possíveis para a coluna result_state são:
Status | Descrição |
|---|---|
| A execução foi concluída com êxito. |
| A execução foi concluída com um erro. |
| A execução nunca foi executada porque uma condição não foi atendida. |
| A execução foi cancelada por solicitação do usuário. |
| A execução foi interrompida após atingir o tempo limite. |
| A execução foi concluída com um erro. |
| A execução foi bloqueada em uma dependência upstream. |
| A linha representa uma fatia intermediária de um trabalho de longa duração. O endereço |
Valores do código de terminação
Nas tabelas job_task_run_timeline e job_run_timeline, os valores possíveis para a coluna termination_code são:
Código de encerramento | Descrição |
|---|---|
| A execução foi concluída com êxito. |
| A execução foi cancelada durante a execução pela plataforma Databricks; por exemplo, se a duração máxima da execução foi excedida. |
| A execução nunca foi executada, por exemplo, se a execução da tarefa upstream falhou, a condição do tipo de dependência não foi atendida ou não havia tarefa material para executar. |
| A execução encontrou um erro ao se comunicar com o Spark Driver. |
| A execução falhou devido a um erro de clustering. |
| Não foi possível concluir o checkout devido a um erro na comunicação com o serviço de terceiros. |
| A execução falhou porque foi emitida uma solicitação inválida para iniciar o clustering. |
| O site workspace atingiu a cota para o número máximo de concorrente ativos em execução. Considere programar a execução em um período de tempo maior. |
| A execução falhou porque tentou acessar um recurso indisponível para o site workspace. |
| O número de solicitações de criação de cluster, início e aumento de tamanho excedeu o limite da taxa alocada. Considere a possibilidade de distribuir a execução em um período de tempo maior. |
| A execução falhou devido a um erro ao acessar o armazenamento de blob do cliente. |
| A execução foi concluída com falhas na tarefa. |
| A execução falhou devido a um problema de permissão ao acessar um recurso. |
| A execução falhou ao instalar a biblioteca solicitada pelo usuário. As causas podem incluir, mas não estão limitadas a: a biblioteca fornecida é inválida ou as permissões para instalar a biblioteca são insuficientes. |
| A execução programada excede o limite de execução máxima concorrente definido para o Job. |
| A execução está programada em um clustering que já atingiu o número máximo de contextos que está configurado para criar. |
| Um recurso necessário para executar a execução não existe. |
| A execução falhou devido a uma configuração inválida. |
| A execução falhou devido a um problema do provedor de nuvem. |
| A execução foi ignorada por ter atingido o limite de tamanho da fila no nível do trabalho. |
Valores do tipo de pipeline
Na tabela pipelines, os valores possíveis para a coluna pipeline_type são:
tipo de tubulação | Descrição |
|---|---|
| Padrão pipeline |
| |
| |
| |
|
Referência de resultado do pipeline
Na tabela pipeline_update_timeline, os valores possíveis para a coluna result_state são:
COMPLETEDFAILEDCANCELED
Referência de configurações do pipeline
Na tabela pipelines, os valores possíveis para a coluna settings são:
Valor | Descrição |
|---|---|
| Um sinalizador que indica se deve ser usado Photon para executar o pipeline |
| Um sinalizador que indica se o site pipeline deve ser executado no modo de desenvolvimento ou produção |
| Um sinalizador que indica se o site pipeline deve ser executado continuamente. |
| Um sinalizador que indica se o senhor deve executar o pipeline em um clustering serverless |
| A edição do produto para execução do pipeline |
| A versão do tempo de execução do pipeline a ser usada |
Valores do tipo de atualização do pipeline
Na tabela pipeline_update_timeline, os valores possíveis para a coluna update_type são:
FULL_REFRESHREFRESHVALIDATE
Valores do tipo de gatilho do pipeline
Na tabela pipeline_update_timeline, os valores possíveis para a coluna trigger_type são:
API_CALLRETRY_ON_FAILURESERVICE_UPGRADESCHEMA_CHANGEJOB_TASKUSER_ACTIONDBSQL_REQUESTSETTINGS_CHANGESCHEMA_EXPLORATIONINFRASTRUCTURE_MAINTENANCESTART_RESOURCES
Detalhes do tipo de gatilho do pipeline
Quando o tipo de gatilho do pipeline for JOB_TASK, o trigger_type.details será preenchido com os seguintes valores:
Valor | Descrição | Notas |
|---|---|---|
| O ID do trabalho que acionou a atualização do pipeline | O valor |
| O ID da tarefa de execução do Job que acionou a atualização do pipeline | O valor |
| Preenchido apenas para atualizações pipeline serverless | Ou |