Crie os endpoints de Pesquisa de AI e os Índices de Pesquisa de AI
Os índices da Pesquisa de IA fornecem busca de similaridade em tempo real em uma tabela Delta, e os endpoints da Pesquisa de IA servem esses índices para consulta. Este artigo descreve como criar ambos. Para uma introdução à Pesquisa de IA, consulte Databricks AI Search.
Você pode criar e gerenciar componentes do AI Search, como um endpoint do AI Search e índices do AI Search, usando a interface do usuário, o Python SDK ou a API REST.
Para Notebooks de exemplo que ilustram como criar e consultar endpoints do AI Search, consulte Notebooks de exemplo do AI Search. Para obter informações de referência, consulte a referência do SDK do Python.
Databricks AI Search era anteriormente conhecida como Databricks Vector Search.
Requisitos
- Workspace habilitado para o Unity Catalog.
- Compute serverless ativado. Para obter instruções, consulte Conecte-se ao compute serverless.
- Para endpoints padrão, a tabela de origem deve ter o Change Data Feed habilitado. Consulte Usar o feed de dados de alteração no Databricks.
- Para criar um Índice de Pesquisa de AI, é necessário ter privilégios CREATE TABLE no esquema do catálogo onde o índice será criado.
- Para consultar um índice que pertence a outro usuário, o usuário deve ter privilégios adicionais. Consulte Como Consultar um Índice de Pesquisa de IA.
Permissão para criar e gerenciar endpoints de Pesquisa de AI é configurada usando listas de controle de acesso. Consulte as Listas de Controle de Acesso do endpoint de Pesquisa de AI.
Instalação
Para usar o SDK de AI Search, você deve instalá-lo em seu notebook. Use o seguinte código para instalar o pacote:
%pip install databricks-ai-search
dbutils.library.restartPython()
Em seguida, execute o seguinte comando para importar AISearchClient:
from databricks.ai_search.client import AISearchClient
Para obter informações sobre autenticação, consulte Proteção de dados e autenticação.
Criar um endpoint de Pesquisa de IA
Você pode criar um endpoint de pesquisa de IA usando a interface do usuário do Databricks, o Python SDK ou a API.
Crie um endpoint de Pesquisa de IA usando a interface do usuário
Siga os passos para criar um endpoint de Pesquisa de AI usando a interface do usuário.
-
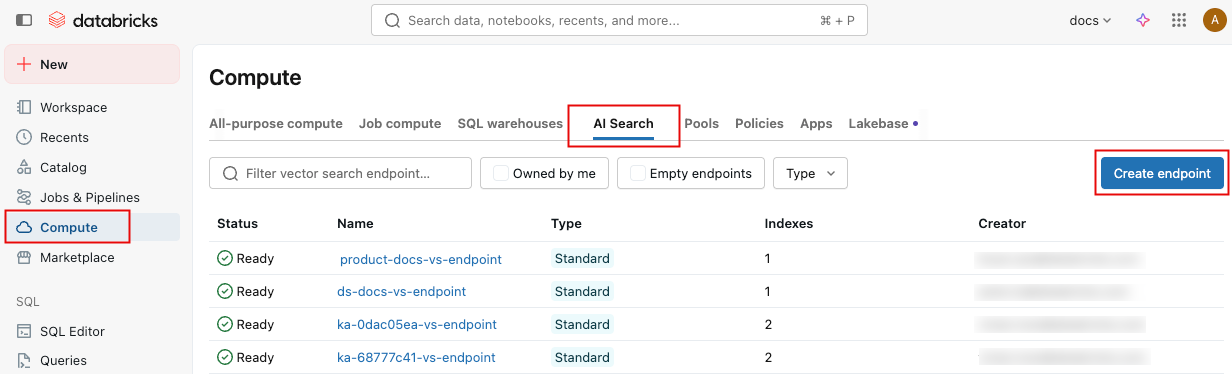
Na barra lateral esquerda, clique em Compute .
-
Clique na tab Pesquisa de IA e clique em Criar endpoint .
-
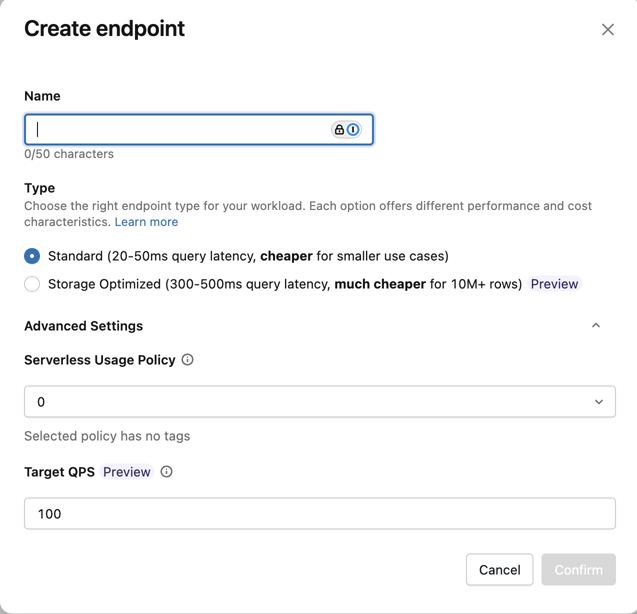
O Formulário Criar endpoint abre-se. Insira um nome para este endpoint.
-
No campo Tipo , selecione Padrão ou Otimizado para Armazenamento . Consulte Opções de endpoint.
-
(Opcional) Em **Configurações avançadas**, selecione uma política de uso. Consulte políticas de uso da Pesquisa de AI.
-
Clique em Confirmar .
Crie um endpoint de Pesquisa de IA usando o Python SDK
O seguinte exemplo utiliza a função SDK create_endpoint() para criar um endpoint de Pesquisa de AI.
# The following line automatically generates a PAT Token for authentication
client = AISearchClient()
# The following line uses the service principal token for authentication
# client = AISearchClient(service_principal_client_id=<CLIENT_ID>,service_principal_client_secret=<CLIENT_SECRET>)
client.create_endpoint(
name="vector_search_endpoint_name",
endpoint_type="STANDARD" # or "STORAGE_OPTIMIZED"
)
Crie um endpoint de Pesquisa de IA usando a API REST
Consulte a documentação de referência da API REST: POST /api/2.0/vector-search/endpoints.
Criar um endpoint de busca vetorial usando Pacotes de Automação Declarativa
É possível definir um endpoint de pesquisa vetorial como um recurso em Pacotes de Automação Declarativa para gerenciá-lo como código juntamente com seus Jobs, pipelines e outros ativos do workspace. Para saber mais sobre pacotes, consulte O que são Pacotes de Automação Declarativa?.
A definição de endpoints de pesquisa vetorial em um pacote é compatível apenas com o mecanismo de implantação direta e requer a CLI do Databricks versão 1.1.0 ou posterior.
O exemplo a seguir define um endpoint de pesquisa vetorial padrão:
resources:
vector_search_endpoints:
my_vector_search_endpoint:
name: my_vector_search_endpoint
endpoint_type: STANDARD
Para a lista completa de campos compatíveis, incluindo endpoint_type, budget_policy_id, min_qps e permissions, consulte vector_search_endpoint.
Crie um endpoint com um QPS alvo para cargas de trabalho de alta taxa de transferência
Para cargas de trabalho de alta taxa de transferência, você pode criar um endpoint com um QPS alvo. Este recurso está disponível somente para endpoints padrão.
Para configurar um QPS alvo, utilize o parâmetro target_qps. Veja Dimensionar taxa de transferência do endpoint com QPS alto.
A definição de target_qps provisiona capacidade adicional, o que aumenta o custo do endpoint. É cobrado por essa capacidade adicional independentemente do tráfego real de query. O escalonamento de throughput é de melhor esforço e não é garantido.
client.create_endpoint(
name="vector_search_endpoint_name",
endpoint_type="STANDARD",
target_qps=500, # target QPS for high-throughput workloads
)
Para alterar o QPS alvo em um endpoint existente, use update_endpoint().
from databricks.ai_search.client import AISearchClient
client = AISearchClient()
# Set or update target QPS
response = client.update_endpoint(name="vector_search_endpoint_name", target_qps=500)
# Check scaling status
scaling_info = response.get("endpoint", {}).get("scaling_info", {})
print(f"State: {scaling_info.get('state')}") # SCALING_CHANGE_IN_PROGRESS or SCALING_CHANGE_APPLIED
Após atualizar o QPS alvo, sincronize seus índices para aplicar a nova configuração.
(Opcional) Criar e configurar um endpoint para disponibilizar o modelo de incorporação
Se você optar por fazer com que o Databricks compute os embeddings, poderá usar um endpoint pré-configurado das APIs do Foundation Model ou criar um endpoint de servindo modelo para servir o modelo de embedding de sua escolha. Consulte APIs de Foundation Model Pay-per-tokens ou Crie endpoints de servindo modelo de fundação para instruções. Para notebooks de exemplo, consulte Notebooks de exemplo da Pesquisa de AI
Ao configurar um endpoint de embedding, o Databricks recomenda que você remova a seleção default de Escala para zero . Endpoints de serviço podem levar alguns minutos para aquecer, e a consulta inicial em um índice com um endpoint reduzido pode expirar.
A inicialização do Índice de Pesquisa de AI pode exceder o tempo limite se o endpoint de incorporação não estiver configurado adequadamente para o dataset. Só se deve usar endpoints de CPU para datasets pequenos e testes. Para datasets maiores, use um endpoint de GPU para desempenho ideal.
Criar Índice de Pesquisa de AI
Você pode criar um índice do AI Search usando a IU, o Python SDK ou a API REST. A interface do usuário é a abordagem mais simples.
Existem dois tipos de índice:
- O Delta Sync Index é sincronizado automaticamente com uma tabela Delta de origem e é atualizado de forma automática e incremental à medida que os dados subjacentes na tabela Delta são alterados.
- O Direct Vector Access Index é compatível com a leitura e gravação direta de vetores e metadados. O usuário é responsável por atualizar esta tabela usando a API REST ou o Python SDK. Este tipo de índice não pode ser criado utilizando a IU. Você deve usar a API REST ou o SDK.
Delta Sync Indexes oferecem suporte aos seguintes modos de pesquisa:
- Pesquisa vetorial (rede neurais artificiais (ANN) ou híbrida): requer colunas de incorporação. Suporta tanto endpoints padrão quanto otimizados para armazenamento. Você também pode usar
query_type="FULL_TEXT"para pesquisa de palavras-chave nesses índices. - Índice de pesquisa de texto completo dedicado (Beta): um índice de sincronização Delta criado sem nenhuma coluna de incorporação, para pesquisa somente por palavra-chave. Disponível apenas em endpoints otimizados para armazenamento usando o modo de sincronização acionado. Consulte Criar um índice de pesquisa de texto completo.
O nome da coluna _id está reservado. Se a sua tabela de origem tiver uma coluna chamada _id, renomeie-a antes de criar um Índice de Pesquisa de IA.
Criar índice utilizando a interface do usuário
-
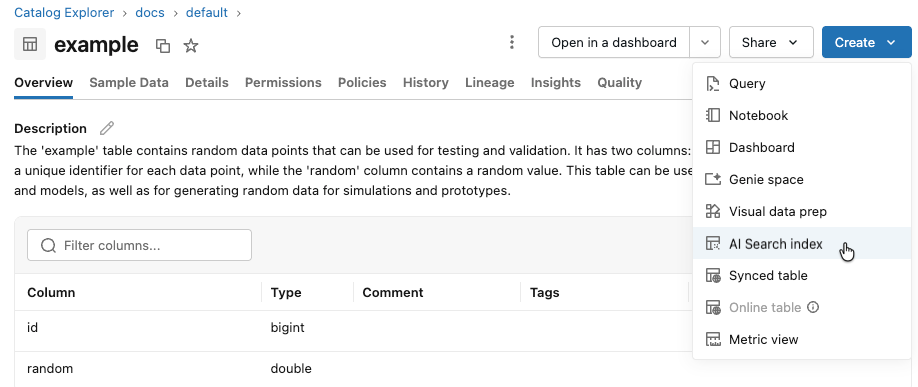
Na barra lateral esquerda, clique em Catálogo para abrir a interface do usuário do Catalog Explorer.
-
Acesse a tabela Delta que deseja usar.
-
Clique no botão **Criar** no canto superior direito e selecione **índice de pesquisa vetorial** no menu suspenso.
-
Utilize os seletores na caixa de diálogo para configurar o índice.
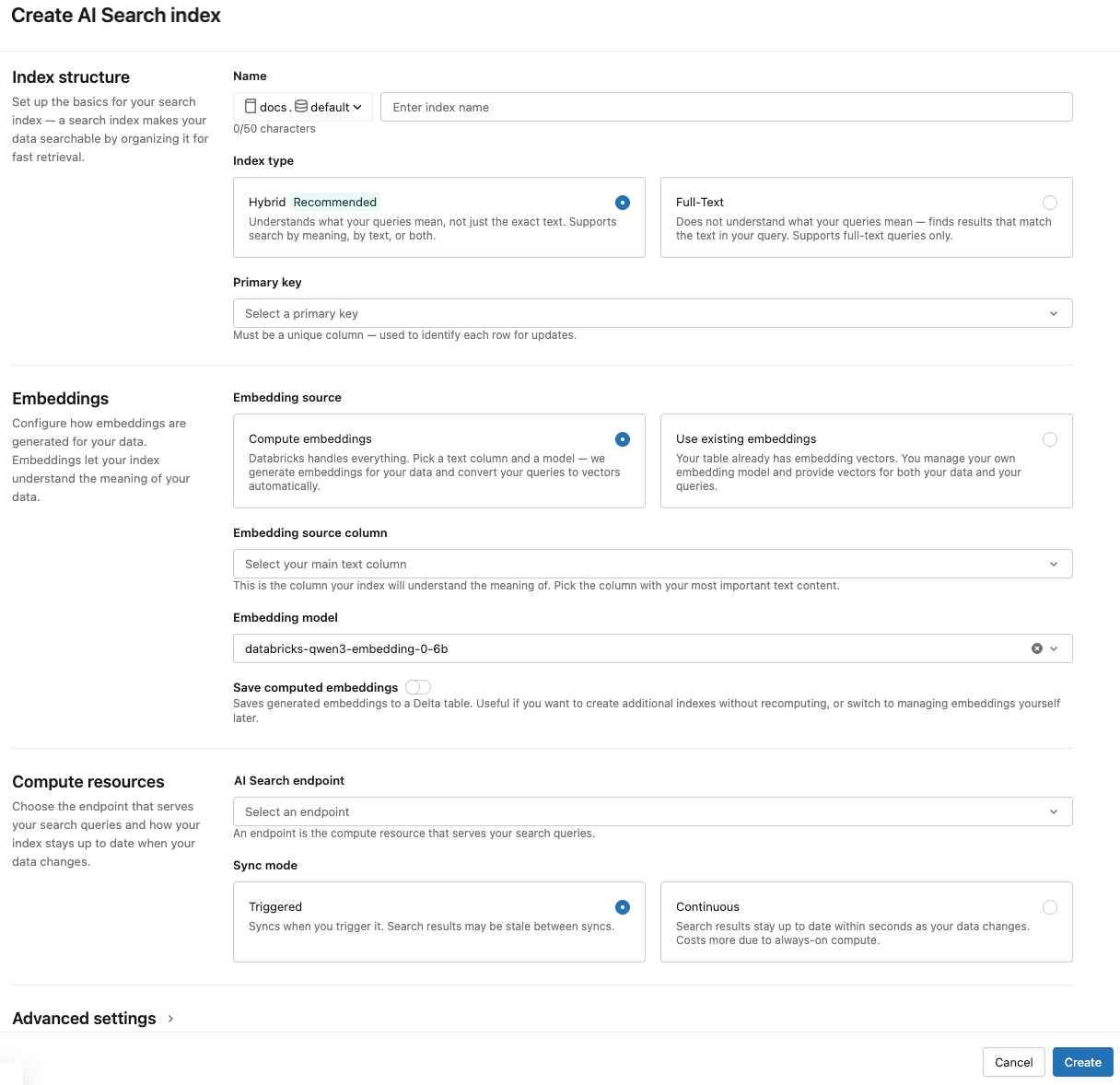
Estrutura do índice
Nome : Nome a ser usado para a tabela online no Unity Catalog. O nome exige um namespace de três níveis,
<catalog>.<schema>.<name>. Os nomes não podem conter espaços, pontos, barras ou caracteres de controle.Tipo de índice : Selecione Híbrido para dar suporte tanto à pesquisa semântica (vetorial) quanto à pesquisa por palavras-chave no mesmo índice. Selecione **Texto Completo** para pesquisa somente por palavra-chave sem incorporações. Ver Criar um índice de pesquisa de texto completo (Beta) para os requisitos de índice de texto completo.
Chave primária : Coluna a ser usada como uma chave primária.
Incorporações
Origem da incorporação : Indique se deseja que o Databricks compute incorporações para uma coluna de texto na tabela Delta ( Computar incorporações ), ou se sua tabela Delta contém incorporações pré-computadas ( Usar incorporações existentes ).
-
Se você selecionou Incorporações de compute , selecione a coluna para a qual você deseja que as incorporações sejam computadas. Um modelo de incorporação gerenciado pelo Databricks é selecionado por default. Para usar um modelo diferente, expanda Configurações avançadas e escolha no dropdown Modelo de incorporação . Somente colunas de texto são aceitas.
-
Para aplicativos de produção que usam endpoints padrão, a Databricks recomenda usar o modelo de fundação
databricks-qwen3-embedding-0-6bcom um endpoint de serviço de taxa de transferência provisionada. -
Para aplicativos de produção que usam endpoints otimizados para armazenamento com modelos hospedados no Databricks, use o nome do modelo diretamente (por exemplo,
databricks-qwen3-embedding-0-6b) como o endpoint do modelo de incorporação. Endpoints otimizados para armazenamento usamai_querycom inferência em lote no momento da ingestão, oferecendo alta taxa de transferência para o Job de embedding. Se preferir usar um endpoint de Taxa de transferência provisionado para consulta, especifique-o no campomodel_endpoint_name_for_queryao criar o índice.
-
-
Se você selecionou Usar incorporações existentes , selecione a coluna que contém as incorporações pré-computadas e a dimensão da incorporação. O formato da coluna de incorporação pré-computada deve ser
array[float]. Para endpoints otimizados para armazenamento, a dimensão de incorporação deve ser divisível por 16.
Salvar incorporações computadas : Ative esta configuração para salvar as incorporações geradas em uma tabela do Unity Catalog. Para obter mais informações, consulte Salvar tabela de incorporação gerada.
Recursos de compute
Endpoint de pesquisa vetorial : Selecione o endpoint de pesquisa vetorial para armazenar o índice.
Modo de sincronização : Contínuo mantém o índice em sincronia com segundos de latência. No entanto, ele tem um custo maior associado, pois um cluster de compute é provisionado para a execução do pipeline de transmissão de sincronização contínua.
- Para endpoints padrão, tanto Continuous quanto Triggered realizam atualizações incrementais, de modo que apenas os dados que foram alterados desde a última sincronização são processados.
- Para endpoints otimizados para armazenamento, cada sincronização reconstrói parcialmente o índice. Para índices gerenciados em sincronizações subsequentes, quaisquer incorporações geradas em que a linha de origem não foi alterada são reutilizadas e não precisam ser recalculadas. Consulte Limitações de endpoints otimizados para armazenamento.
Com o modo de sincronização **acionado**, usa-se o SDK Python ou a API REST para iniciar a sincronização. Consulte Atualizar um Índice Delta Sync.
Para endpoints otimizados para armazenamento, somente o modo de sincronização Acionado é compatível.
Configurações avançadas
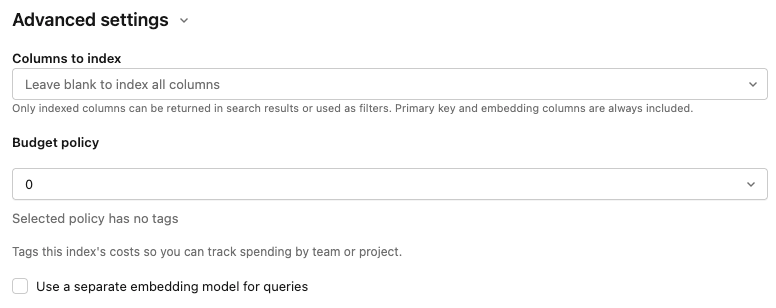
A seção Configurações avançadas está recolhida por padrão. A maioria dos usuários pode aceitar os padrões. Amplie para ajustar qualquer um dos seguintes:
Modelo de incorporação : substitua o modelo de incorporação default. O modelo default hospedado pelo Databricks funciona para a maioria dos workspaces. Altere aqui caso necessite de um diferente ou se você não tiver acesso ao default.
Colunas a serem indexadas : Selecione as colunas a serem incluídas no índice. Se deixar esse campo em branco, todas as colunas da tabela de origem serão indexadas. A chave primária e as colunas de incorporação estão sempre incluídas. Somente colunas indexadas podem ser retornadas nos resultados da pesquisa ou usadas como filtros.
Política de uso : Aplique uma política de uso para marcar os custos do índice para acompanhamento por equipe ou projeto. Consulte políticas de uso da Pesquisa de AI.
Use um modelo de incorporação separado para consultas: Se você selecionou **Compute embeddings**, selecione esta opção para especificar um endpoint separado de disponibilização de modelos de incorporação para consultar o índice. Isso pode ser útil se você precisar de um endpoint de alta taxa de transferência para ingestão, mas de um endpoint de menor latência para consultas. O modelo especificado no campo Modelo de incorporação é sempre usado para ingestão e também é usado para queries, a menos que especifique um modelo diferente aqui.
-
-
Quando terminar de configurar o índice, clique em Criar .
Criar índice usando o SDK para Python
O exemplo a seguir cria um índice de sincronização Delta com incorporações computadas pelo Databricks. Para obter detalhes, consulte a referência do Python SDK.
Este exemplo também mostra o parâmetro opcional model_endpoint_name_for_query, que especifica um endpoint de servindo modelo de incorporação separado a ser usado para consultar o índice.
client = AISearchClient()
index = client.create_delta_sync_index(
endpoint_name="vector_search_demo_endpoint",
source_table_name="vector_search_demo.vector_search.en_wiki",
index_name="vector_search_demo.vector_search.en_wiki_index",
pipeline_type="TRIGGERED",
primary_key="id",
embedding_source_column="text",
embedding_model_endpoint_name="e5-small-v2", # This model is used for ingestion, and is also used for querying unless model_endpoint_name_for_query is specified.
model_endpoint_name_for_query="e5-mini-v2" # Optional. If specified, used only for querying the index.
)
O exemplo a seguir cria um Índice de Sincronização Delta com incorporações autogerenciadas.
client = AISearchClient()
index = client.create_delta_sync_index(
endpoint_name="vector_search_demo_endpoint",
source_table_name="vector_search_demo.vector_search.en_wiki",
index_name="vector_search_demo.vector_search.en_wiki_index",
pipeline_type="TRIGGERED",
primary_key="id",
embedding_dimension=1024,
embedding_vector_column="text_vector"
)
Por default, todas as colunas da tabela de origem são sincronizadas com o índice. Para selecionar um subconjunto de colunas para sincronizar, use columns_to_sync. A chave primária e as colunas de incorporação estão sempre incluídas no índice.
Para sincronizar *somente* a chave primária e a coluna de incorporação, você deve especificá-las em,columns_to_sync conforme mostrado.
index = client.create_delta_sync_index(
...
columns_to_sync=["id", "text_vector"] # to sync only the primary key and the embedding column
)
Para sincronizar colunas adicionais, especifique-as conforme mostrado. Não é necessário incluir a chave primária e a coluna de incorporação, pois elas são sempre sincronizadas.
index = client.create_delta_sync_index(
...
columns_to_sync=["revisionId", "text"] # to sync the `revisionId` and `text` columns in addition to the primary key and embedding column.
)
Criar um índice de pesquisa de texto completo (Beta)
Beta
A criação de índice de pesquisa de texto completo está disponível como parte do beta Vector Search: Pesquisa de Texto Completo apenas em endpoints otimizados para armazenamento. Para usá-lo, habilite o **Pré-lançamento público do Vector Search: Full-Text Search**. Entre em contato com a equipe da sua conta ou consulte Gerenciar pré-visualizações do Databricks para ativar as pré-visualizações.
Um índice de pesquisa de texto completo permite a pesquisa baseada em palavras-chave em colunas de texto sem exigir incorporações de vetores. Isso é útil para pesquisar termos exatos, identificadores ou palavras-chave, em vez de similaridade semântica.
Durante a sincronização, o Databricks detecta o idioma dominante para cada coluna de texto e usa um analisador específico do idioma. Os idiomas suportados são inglês, chinês, japonês, coreano, alemão, francês, espanhol, italiano, português e russo.
Índices de texto completo têm os seguintes requisitos:
- Deve-se usar um endpoint otimizado para armazenamento . Endpoints padrão não são suportados.
- Deve usar o Modo de sincronização acionado . A sincronização contínua não é compatível.
- Os parâmetros
embedding_source_column,embedding_vector_columneembedding_dimensionnão são compatíveis.
O exemplo a seguir cria um índice de pesquisa de texto completo usando o SDK do Python.
client = AISearchClient()
index = client.create_delta_sync_index(
endpoint_name="storage_optimized_endpoint",
source_table_name="catalog.schema.source_table",
index_name="catalog.schema.full_text_index",
pipeline_type="TRIGGERED",
primary_key="id",
columns_to_sync=["id", "text", "metadata_column"],
index_subtype="FULL_TEXT"
)
Após a criação do índice, é necessário acionar uma sincronização para preenchê-lo:
index.sync()
Para consultar o índice de texto completo, use query_type="FULL_TEXT". Consulte Consultar um Índice de Pesquisa de IA para detalhes.
results = index.similarity_search(
query_text="search terms",
columns=["id", "text"],
num_results=10,
query_type="FULL_TEXT"
)
O exemplo a seguir cria um Índice de acesso vetorial direto.
client = AISearchClient()
index = client.create_direct_access_index(
endpoint_name="storage_endpoint",
index_name=f"{catalog_name}.{schema_name}.{index_name}",
primary_key="id",
embedding_dimension=1024,
embedding_vector_column="text_vector",
schema={
"id": "int",
"field2": "string",
"field3": "float",
"text_vector": "array<float>"}
)
Criar índice usando a API REST
Consulte a documentação de referência da API REST: POST /api/2.0/vector-search/indexes.
Salvar tabela de incorporações geradas
Se o Databricks gerar as incorporações, você poderá salvar as incorporações geradas em uma tabela no Unity Catalog. Esta tabela é criada no mesmo esquema que o índice de pesquisa vetorial e está vinculada à página do índice de pesquisa vetorial.
O nome da tabela é o nome do Índice de Pesquisa de IA, anexado por _writeback_table. O nome não é editável.
Você pode acessar e consultar a tabela como qualquer outra tabela no Unity Catalog. No entanto, a tabela não deve ser descartada ou modificada, pois não se destina a ser atualizada manualmente. A tabela é excluída automaticamente se o índice for excluído.
Atualizar um Índice de Pesquisa de IA
Atualizar o Delta Sync Index
Índices criados com o modo de sincronização Contínuo são atualizados automaticamente quando a tabela Delta de origem é alterada. Se você estiver usando o modo de sincronização **Acionado**, você pode começar a sincronização usando a interface do usuário, o Python SDK ou a API REST.
- Databricks UI
- Python SDK
- REST API
-
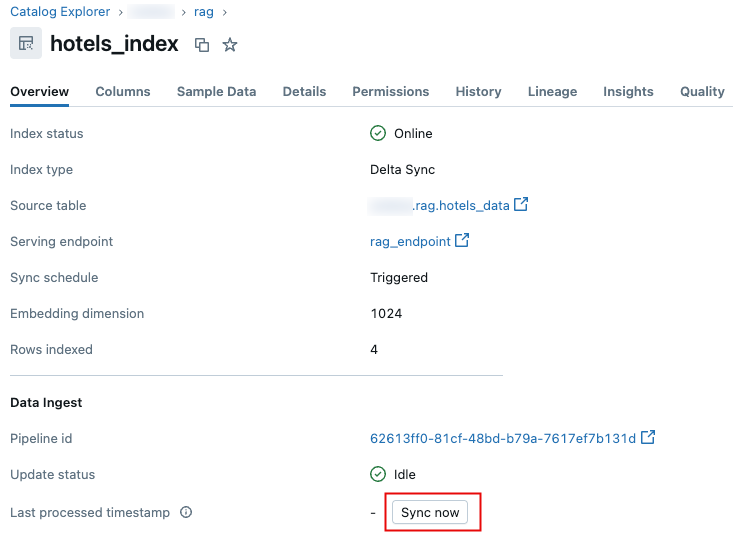
No Catálogo do Explorer, navegue até o Índice de Pesquisa de IA.
-
Na tab Overview , na seção Data Ingest , clique em Sincronizar agora .
 .
.
Para obter detalhes, consulte a referência do Python SDK.
client = AISearchClient()
index = client.get_index(index_name="vector_search_demo.vector_search.en_wiki_index")
index.sync()
Consulte a documentação de referência da API REST: POST /api/2.0/vector-search/indexes/{index_name}/sync.
Atualizar um Índice de acesso vetorial direto
É possível usar o Python SDK ou a API REST para inserir, atualizar ou excluir dados de um Índice de Acesso Vetorial Direto.
- Python SDK
- REST API
Para obter detalhes, consulte a referência do Python SDK.
index.upsert([
{
"id": 1,
"field2": "value2",
"field3": 3.0,
"text_vector": [1.0] * 1024
},
{
"id": 2,
"field2": "value2",
"field3": 3.0,
"text_vector": [1.1] * 1024
}
])
Consulte a documentação de referência da API REST: POST /api/2.0/vector-search/indexes.
Para aplicações de produção, o Databricks recomenda usar entidades de serviço em vez de tokens de acesso pessoal. O desempenho pode ser melhorado em até 100 ms por consulta.
O exemplo de código a seguir ilustra como atualizar um índice usando uma entidade de serviço.
export SP_CLIENT_ID=...
export SP_CLIENT_SECRET=...
export INDEX_NAME=...
export WORKSPACE_URL=https://...
export WORKSPACE_ID=...
# Set authorization details to generate OAuth token
export AUTHORIZATION_DETAILS='{"type":"unity_catalog_permission","securable_type":"table","securable_object_name":"'"$INDEX_NAME"'","operation": "WriteVectorIndex"}'
# Generate OAuth token
export TOKEN=$(curl -X POST --url $WORKSPACE_URL/oidc/v1/token -u "$SP_CLIENT_ID:$SP_CLIENT_SECRET" --data 'grant_type=client_credentials' --data 'scope=all-apis' --data-urlencode 'authorization_details=['"$AUTHORIZATION_DETAILS"']' | jq .access_token | tr -d '"')
# Get index URL
export INDEX_URL=$(curl -X GET -H 'Content-Type: application/json' -H "Authorization: Bearer $TOKEN" --url $WORKSPACE_URL/api/2.0/vector-search/indexes/$INDEX_NAME | jq -r '.status.index_url' | tr -d '"')
# Upsert data into AI Search index.
curl -X POST -H 'Content-Type: application/json' -H "Authorization: Bearer $TOKEN" --url https://$INDEX_URL/upsert-data --data '{"inputs_json": "[...]"}'
# Delete data from AI Search index
curl -X DELETE -H 'Content-Type: application/json' -H "Authorization: Bearer $TOKEN" --url https://$INDEX_URL/delete-data --data '{"primary_keys": [...]}'
O exemplo de código a seguir ilustra como atualizar um índice usando um token de acesso pessoal (PAT).
export TOKEN=...
export INDEX_NAME=...
export WORKSPACE_URL=https://...
# Upsert data into AI Search index.
curl -X POST -H 'Content-Type: application/json' -H "Authorization: Bearer $TOKEN" --url $WORKSPACE_URL/api/2.0/vector-search/indexes/$INDEX_NAME/upsert-data --data '{"inputs_json": "..."}'
# Delete data from AI Search index
curl -X DELETE -H 'Content-Type: application/json' -H "Authorization: Bearer $TOKEN" --url $WORKSPACE_URL/api/2.0/vector-search/indexes/$INDEX_NAME/delete-data --data '{"primary_keys": [...]}'
Como fazer alterações de esquema sem interrupção
Alterações de esquema na tabela de origem não são suportadas a menos que o índice seja reconstruído. Isso inclui modificar colunas existentes e adicionar novas colunas. O esquema do índice é fixado no momento da criação, portanto, quaisquer alterações de esquema exigem a criação de um novo índice para que tenham efeito.
Siga estes os passos para reconstruir e implantar o índice sem tempo de inatividade.
- A alteração do esquema deve ser realizada na tabela de origem.
- Crie um novo índice usando o esquema atualizado.
- Assim que o novo índice estiver pronto, direcione o tráfego para o novo índice.
- Excluir o índice original.