Materialização para views de métricas
A materialização para views de métricas acelera as queries usando views materializadas para pré-calcular agregações. Lakeflow pipelines orquestram views materializadas definidas pelo usuário para uma determinada view de métricas. No momento da query, o otimizador de query roteia as queries para a melhor view materializada usando a correspondência automática de query com reconhecimento de agregação (re escrita de query). Você query a view de métricas como de costume, sem esforço manual adicional. A Databricks faz refresh das materializações para mantê-las atualizadas. Também escolhe qual materialização consultar para query mais rápidas com menor custo.
Como a materialização funciona
A materialização para visualizações de métricas envolve duas fases: a definição da materialização e a execução de consultas nela.
Fase de definição
Quando você define uma view de métrica com materialização, especifica seus campos, medidas e schedule de refresh no YAML da view de métrica. A partir dessa definição, o Databricks cria um LakeFlow pipeline gerenciado que constrói e mantém as views materializadas.
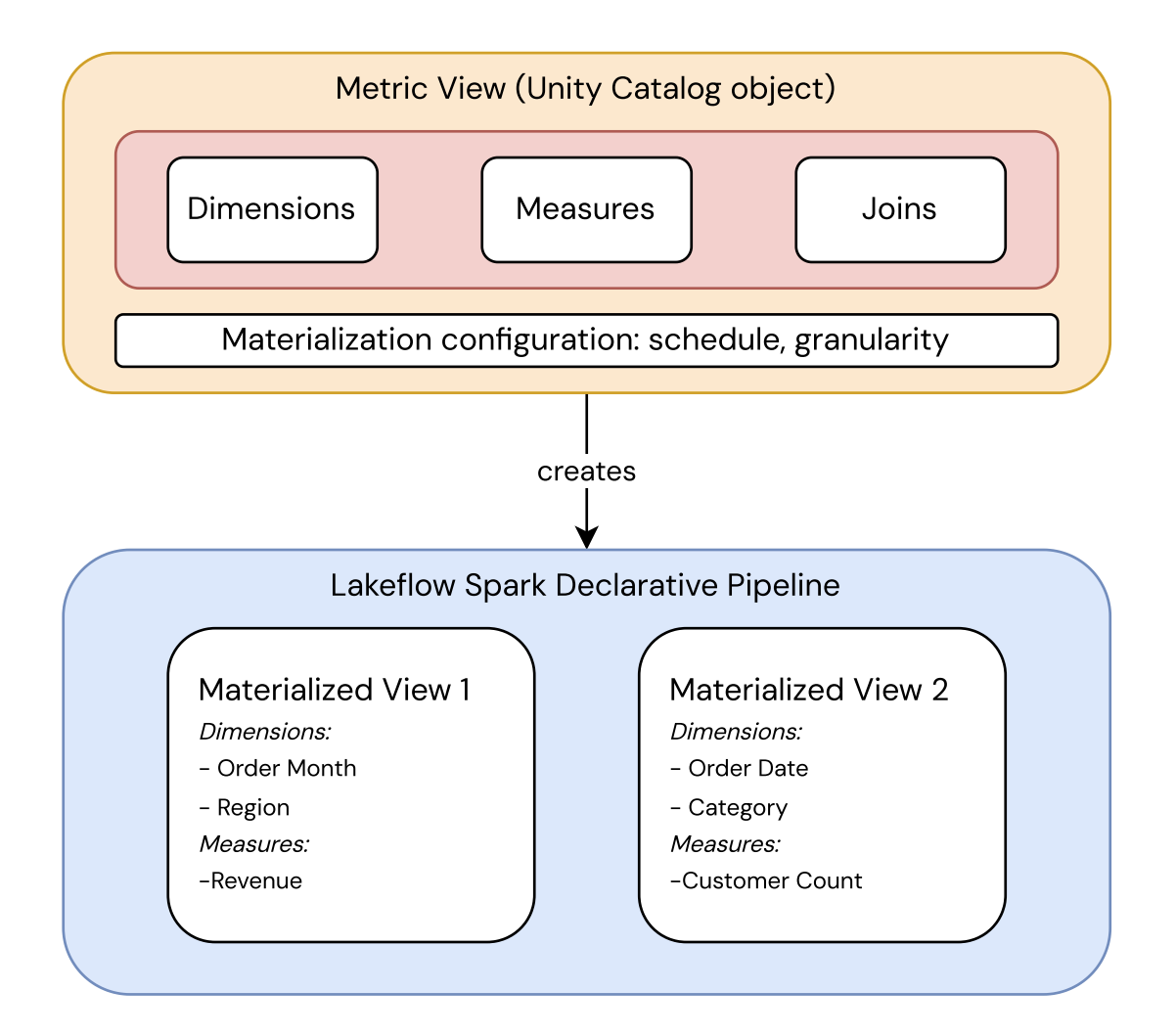
Isso mantém a definição da métrica separada de como ela é armazenada:
- A view de métricas é um objeto do Unity Catalog que define os campos, medidas e joins da métrica, junto com a configuração de materialização (programação e granularidade). É a única fonte de verdade para o que a métrica significa.
- **O pipeline** materializa essa definição em uma ou mais visualizações materializadas, cada uma pré-computada em uma granularidade específica. O Databricks escolhe qual ler no momento da query.
Execução de query
Quando você executa SELECT ... FROM <metric_view>, o otimizador de query usa a reescrita de query com reconhecimento de agregação para otimizar o desempenho:
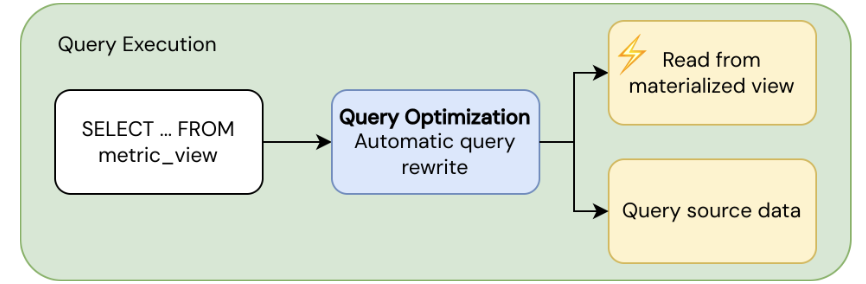
- Fast path : Lê de views materializadas pré-computadas quando existe uma materialização adequada.
- Fallback path : Lê dados de origem diretamente quando nenhuma materialização adequada está disponível.
O otimizador de query equilibra automaticamente o desempenho e a atualização ao escolher entre dados materializados e de origem. Os resultados são apresentados de forma transparente, independentemente do caminho que o otimizador utiliza. Para saber mais sobre como executar query em views de métricas, consulte Consultar views de métricas.
Requisitos
Para usar a materialização para visualizações de métricas:
- Seu workspace deve ter o compute serverless habilitado. Isso é necessário para executar Lakeflow pipelines.
- Um SQL Warehouse ou recurso de compute executando o Databricks Runtime 17.3 ou acima.
A materialização requer o Databricks Runtime 17,3 ou acima. A criação de uma view de métricas sem materialização é compatível com o Databricks Runtime 16,4 e acima. Para o Runtime mínimo para cada recurso, consulte Disponibilidade do recurso de view de métricas.
Referência de configuração
A configuração da materialização é feita em um campo materialization de nível superior na definição YAML da view de métricas. Este campo define a reescrita de query mode (sempre relaxed), um refresh opcional schedule e uma lista de materialized_views para manter. Cada view materializada é aggregated, que pré-calcula dimensões e medidas específicas, ou unaggregated, que materializa o modelo de dados completo.
Para a especificação completa campo a campo, incluindo campos obrigatórios e opcionais, valores permitidos e as restrições da cláusula schedule, consulte Materialização.
Exemplo de definição
O exemplo a seguir define uma view de métricas com uma materialização não agregada e duas agregadas:
version: 1.1
source: prod.operations.orders_enriched_view
filter: revenue > 0
fields:
- name: category
expr: substring(category, 5)
- name: color
expr: color
measures:
- name: total_revenue
expr: SUM(revenue)
- name: number_of_suppliers
expr: COUNT(DISTINCT supplier_id)
materialization:
schedule: every 6 hours
mode: relaxed
materialized_views:
- name: baseline
type: unaggregated
- name: revenue_breakdown
type: aggregated
dimensions:
- category
- color
measures:
- total_revenue
cluster_by:
cols:
- category
- color
partition_by:
- category
- name: suppliers_by_category
type: aggregated
dimensions:
- category
measures:
- number_of_suppliers
O bloco materialization usa a palavra-chave dimensions: para listar campos a serem materializados, embora a definição de nível superior use fields:. As duas palavras-chave são equivalentes. Consulte Campos.
A materialização revenue_breakdown usa cluster_by e partition_by para controlar como os dados materializados são dispostos fisicamente, da mesma forma que as cláusulas CLUSTER BY e PARTITION BY em uma view materializada. Para a especificação completa do campo, consulte Materialização.
Crie a view de métrica usando SQL
Para criar esta view de métricas fora do Catalog Explorer, envolva o YAML em CREATE OR REPLACE VIEW ... WITH METRICS LANGUAGE YAML AS e coloque a definição entre os delimitadores $$:
CREATE OR REPLACE VIEW catalog.schema.orders_materialized WITH METRICS LANGUAGE YAML AS
$$
version: 1.1
source: prod.operations.orders_enriched_view
filter: revenue > 0
dimensions:
- name: category
expr: substring(category, 5)
- name: color
expr: color
measures:
- name: total_revenue
expr: SUM(revenue)
- name: number_of_suppliers
expr: COUNT(DISTINCT supplier_id)
materialization:
schedule: every 6 hours
mode: relaxed
materialized_views:
- name: baseline
type: unaggregated
- name: revenue_breakdown
type: aggregated
dimensions:
- category
- color
measures:
- total_revenue
- name: suppliers_by_category
type: aggregated
dimensions:
- category
measures:
- number_of_suppliers
$$
Modo de reescrita de query
No modo relaxed, a reescrita automática de query só verifica se as visualizações materializadas candidatas têm os campos e medidas necessários para atender à query.
As seguintes verificações são ignoradas:
- Atualização : Não verifica se a materialização está atualizada.
- Configurações de SQL : Não verifica se configurações como
TIMEZONEouANSI_MODEcorrespondem. - Determinismo : Não verifica se os resultados materializados são totalmente determinísticos.
As queries que correspondem a uma materialização usam o último refresh. As queries que não correspondem retornam à origem e mostram dados em tempo real. Como resultado, a atualização dos dados pode variar dependendo se uma query se qualifica para reescrita. Para verificar a consistência, alinhe seu programar de refresh da materialização com seu pipeline de origem. Por exemplo, se sua origem for atualizada diariamente com um pipeline de lotes, programe os refresh da materialização para execução após a conclusão desse pipeline. Como alternativa, use uma materialização não agregada para garantir que todas as queries leiam do mesmo Snapshot.
Não é possível criar uma materialização quando a view de métricas ou qualquer uma de suas tabelas de origem usa:
- Segurança em nível de linha (RLS), mascaramento em nível de coluna (CLM) ou políticas ABAC. Os resultados pré-computados podem ignorar os controles de acesso por usuário que se destinam a ser aplicados no momento da query.
- Expressões dependentes do invocador, cujo resultado muda com base em quem executa a query (por exemplo,
current_user()ouis_member()). Uma materialização é pré-calculada uma vez e compartilhada, então fornecê-la para um usuário diferente retornaria resultados incorretos ou inseguros.
A Databricks valida esta restrição ao criar, alterar ou fazer refresh de uma materialização. Estas operações falham com a condição de erro METRIC_VIEW_MATERIALIZATION_WITH_INVOKER_DEPENDENT_EXPRESSIONS_NOT_SUPPORTED (SQLSTATE 42K0E). Consulte METRIC_VIEW_MATERIALIZATION_WITH_INVOKER_DEPENDENT_EXPRESSIONS_NOT_SUPPORTED.
Tipos de materializações para views de métricas
As seções a seguir explicam os tipos de views materializadas disponíveis para views de métricas e fornecem orientação sobre a seleção da configuração apropriada para suas fontes de dados e padrões de query.
Tipo agregado
Este tipo pré-calcula agregações para combinações especificadas de medidas e campos para cobertura direcionada.
Utilize um tipo agregado quando houver combinações específicas de dimensão e medida que são frequentemente consultadas. Com materializações agregadas, tanto as estratégias de correspondência exata quanto de correspondência de rollup se aplicam, proporcionando o melhor desempenho de query para esses padrões.
Para agregações ótimas :
-
Inclua as dimensões mais usadas nas cláusulas
GROUP BY. -
Inclua quaisquer colunas de filtro potenciais (colunas usadas em
WHEREno momento da query). -
Materialize no nível mais detalhado de que suas queries precisam. Por exemplo, uma materialização em
(region, sku, event_day)pode servir a tudo o que segue:GROUP BY regionGROUP BY region, event_monthGROUP BY skucomWHERE region = 'US'
-
Evite dimensões tão granulares que produzam principalmente grupos de linha única (por exemplo, um timestamp bruto com precisão de milissegundos). Isso não traz nenhum benefício e infla o armazenamento.
-
Observe as medidas não aditivas. Medidas não aditivas não podem ser reagregadas a partir de resultados parciais (por exemplo,
COUNT(DISTINCT),MEDIANe percentis) e exigem uma correspondência exata com uma materialização.
Uma única agregação pode atender apenas a queries que correspondem às suas dimensões específicas (correspondência exata) ou a um subconjunto de suas dimensões (correspondência de rollup). A Databricks recomenda criar múltiplas materializações agregadas para diferentes formatos de query.
Tipo não agregado
Este tipo materializa o modelo de dados desagregados inteiro (os campos source, joins, filter e fields) para uma cobertura mais ampla com menos ganho de desempenho em comparação com o tipo agregado.
Use um tipo não agregado quando uma das seguintes condições for verdadeira:
- Sua visualização de métricas envolve transformações de origem ou joins onerosos.
- Padrões de query são imprevisíveis ou variados.
- Todos os usuários que consultam a view de métricas devem ver consistência nos dados.
Com materializações não agregadas, views de origem e joins caros são computados uma vez na refresh, em vez de em cada consulta. Quando existem materializações agregadas e não agregadas, o Databricks computa as materializações agregadas a partir da não agregada. Isso fornece um snapshot consistente e evita a recomputação redundante da origem. Uma correspondência não agregada é sempre elegível, independentemente do formato da consulta, sujeita às restrições descritas em Modo de reescrita de consulta.
Uma materialização não agregada não ajuda quando a origem é uma referência direta a uma tabela sem um filtro seletivo. Nesse caso, não há benefício em relação a consultar a origem diretamente.
Para obter orientação adicional sobre como e quando usar esses tipos de materialização, consulte Escolher um tipo de materialização para views de métricas.
Reescrita automática de query
Quando você consulta uma view de métricas, a regravação de query roteia automaticamente sua query para a melhor materialização disponível. Ele usa três estratégias de regravação de query: correspondência exata, correspondência de rollup e correspondência não agregada.
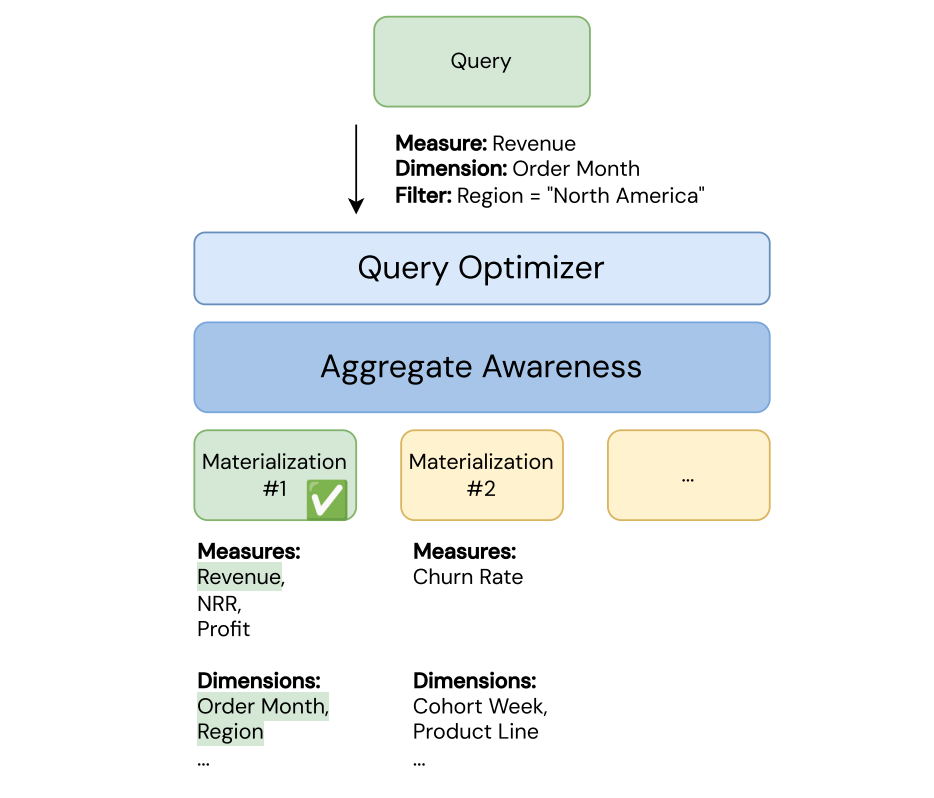
A query é executada automaticamente na melhor materialização em vez das tabelas base usando este algoritmo:
- Primeiro, o otimizador de query tenta uma correspondência exata.
- Se não houver correspondência exata, o otimizador de query tenta uma correspondência agregada.
- Se não houver correspondência de rollup e uma materialização não agregada existir, o otimizador de query tentará uma correspondência não agregada.
- Se não houver correspondência não agregada, a query lê diretamente das tabelas de origem.
As seções a seguir explicam como cada estratégia funciona.
As materializações devem terminar de materializar antes que a reescrita da query possa entrar em vigor.
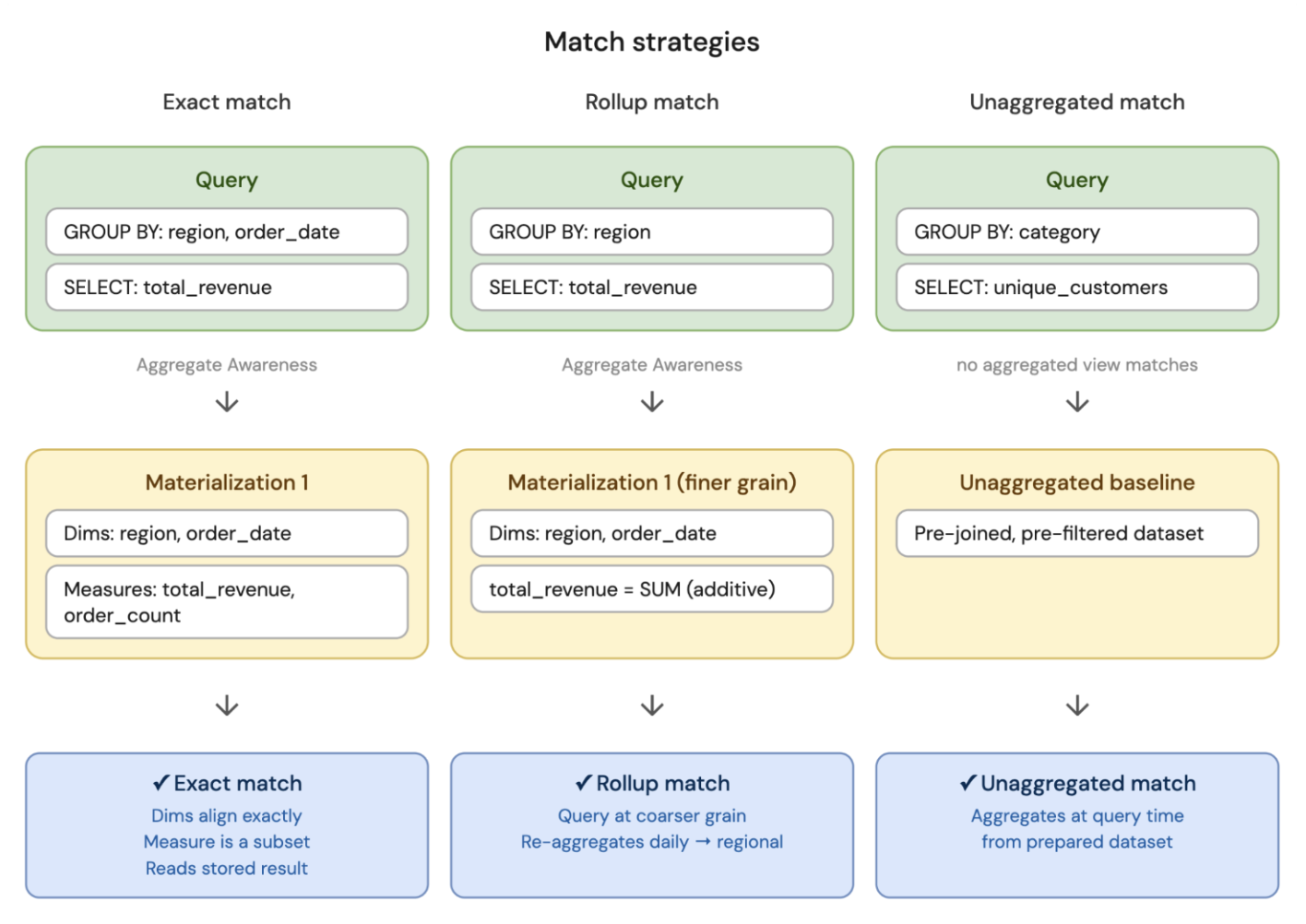
Correspondência exata
A query pede exatamente o que foi pré-computado na materialização. A reescrita de query lê o resultado armazenado sem trabalho extra, permitindo resultados rápidos.
Para se qualificar para correspondência exata:
- As
GROUP BYexpressões da query devem corresponder exatamente às dimensões da materialização. - As medidas da query devem ser um subconjunto das medidas de materialização.
Por exemplo, uma materialização tem dimensões [region, order_date] e medidas [total_revenue, order_count]. Uma query que agrupa por region e order_date e pede total_revenue é uma correspondência exata, porque as dimensões são as mesmas e a medida foi pré-calculada.
Correspondência de rollup
A query pede por um resumo em um nível mais grosseiro do que o que foi pré-computado. O otimizador lê o resultado pré-computado e o reagrega até o nível que a query precisa.
Para se qualificar para a correspondência de rollup:
- Grão mais grosseiro : A query agrupa por menos dimensões ou por uma granularidade de tempo mais ampla do que a materialização.
- Todas as medidas são aditivas : Cada medida que sua query solicita deve ser uma que possa ser recomputada corretamente combinando resultados parciais (por exemplo,
SUMdeSUMs ouMAXdeMAXes).MEDIANnão pode ser acumulado porque depende da distribuição do grupo. - Quaisquer filtros participantes devem ser expressões determinísticas : se sua query tiver uma cláusula
WHERE, o filtro deve sempre produzir o mesmo resultado para a mesma entrada. Por exemplo,WHERE region = 'US'é determinístico, mas expressões comorand()ouuuid()não são.
A correspondência de rollup não é elegível para medidas não aditivas, pois elas não podem ser re-agregadas corretamente a partir de resultados parciais. Veja Medidas aditivas.
Por exemplo, usando a mesma materialização com dimensões [region, order_date] e medidas [total_revenue, order_count], uma query que agrupa apenas por region e solicita total_revenue é uma correspondência de rollup. A query precisa de menos dimensões do que foi materializado, então o mecanismo agrega os totais diários em totais no nível da região.
A correspondência de rollup não está disponível quando a view de métricas usa uma join one_to_many. Nesse caso, toda materialização reverte apenas para correspondência exata. Para detalhes sobre joins um-para-muitos, consulte joins um-para-muitos.
Medidas aditivas
Uma medida é *aditiva* se seu resultado agregado puder ser corretamente recalculado re-agregando a partir de materializações agregadas existentes. Este é o requisito principal para a correspondência de rollup.
Qualquer agregado usando DISTINCT (por exemplo, COUNT(DISTINCT), SUM(DISTINCT)) não é aditivo e não pode ser agrupado.
As seguintes funções são aditivas:
SUMCOUNTMINMAXBIT_ANDBIT_ORBIT_XORBOOL_ANDBOOL_OR
Restrições adicionais aplicam-se a medidas aditivas:
- A definição da medida deve conter exatamente uma função agregada. Uma medida cuja definição combina vários agregados (por exemplo,
sum(cost) + min(revenue)) não é elegível para correspondência de rollup. - Se a definição da medida incluir uma cláusula
FILTER, ela deverá ser determinística. - A medida não pode ser uma medida de janela (por exemplo, um total móvel de 7 dias ou comparação ano a ano definida com um bloco de janela).
A tabela a seguir resume como os padrões de medidas comuns se mapeiam para os tipos de correspondência:
Medir padrão | Tipo correspondente | Motivo |
|---|---|---|
Agregado aditivo único ( | Acúmulo elegível | Pode ser reagregado a partir de resultados parciais |
| Somente correspondência exata | Não pode ser reagregado |
Múltiplos agregados em uma expressão ( | Somente correspondência exata | Não é possível isolar agregações individuais para consolidação. |
Agregado aditivo com determinístico | Acúmulo elegível | O filtro é determinístico e o agregado é aditivo |
Medida da janela | Somente correspondência exata | O quadro da janela depende da granularidade exata |
Correspondência não agregada
A query não corresponde a nenhuma agregação pré-computada, mas o trabalho de preparação caro (joins e filtros) já está feito. A reescrita de query começa a partir do dataset preparado da materialização não agregada, em vez de voltar para as tabelas de origem.
Se existir uma materialização não agregada, esta estratégia é sempre elegível como fallback antes de ir para a fonte. Qualquer formato de query pode usá-lo, sujeito às restrições descritas em Modo de reescrita de query.
Por exemplo, sua query agrupa por category e solicita unique_customers, mas nenhuma materialização agregada inclui esses campos e métricas. No entanto, uma materialização não agregada existe com o dataset unido e filtrado pronto. O otimizador de query lê esse dataset preparado e executa GROUP BY category, COUNT(DISTINCT customer_id) no momento da query, em vez de reunir as tabelas brutas do zero.
Verificar se uma query está usando views materializadas
Existem duas maneiras de verificar se uma query está usando uma view materializada:
- Execute
EXPLAIN EXTENDEDem sua query para ver o plano de query. Se a materialização foi usada, o nó folha inclui__materialization_mat_<pipeline ID>___metric_view_mat_e o nome da materialização do arquivo YAML. - Veja o perfil da consulta, conforme mostrado abaixo.
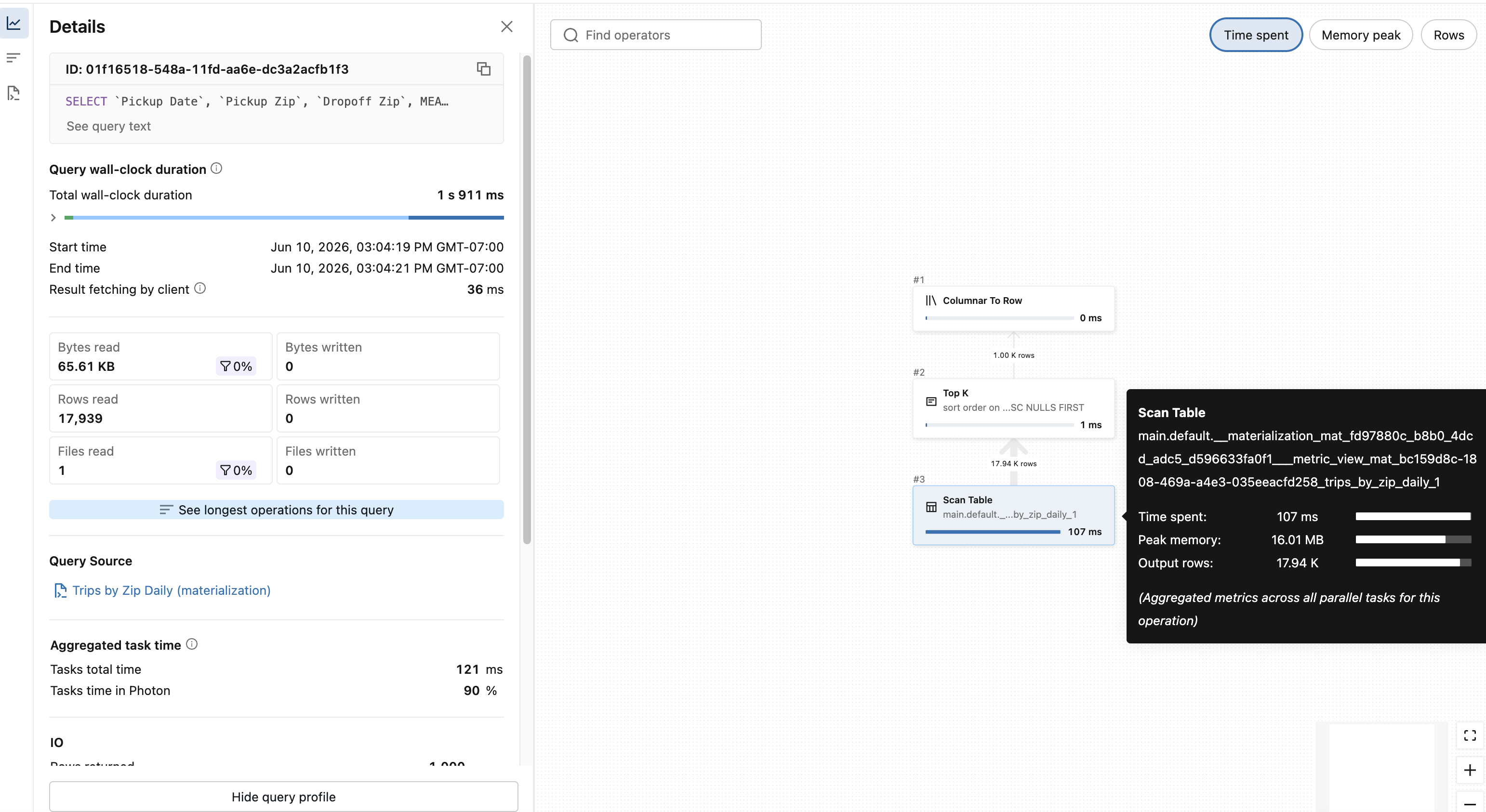
Ciclo de vida da materialização
Esta seção explica como as materializações são criadas, gerenciadas e recebem refresh ao longo de seu ciclo de vida.
Criar e modificar
Ao criar ou modificar uma view de métricas (usando CREATE, ALTER ou Catalog Explorer), a definição da view de métricas é atualizada imediatamente. Visualizações materializadas refresh assincronamente em segundo plano usando um pipeline gerenciado.
Para definir uma nova materialização no editor do Explorador de Catálogos:
- Clique em Materializações .
- Clique em programar para definir um agendamento. Você pode selecionar um período de intervalo ou definir a materialização para ser executada em um horário específico.
- Selecione um Tipo . Somente uma materialização não agregada é permitida por view de métricas. Para mais informações, consulte Tipos de materializações para views de métricas.
- Use o menu suspenso Fields para selecionar os campos a serem incluídos na materialização.
- Use o menu suspenso de **Medidas** para selecionar as medidas a serem incluídas.
Ao criar uma view de métricas, o Databricks cria um pipeline do LakeFlow e programa uma atualização inicial imediatamente se houver views materializadas especificadas. A view de métricas permanece consultável sem materializações, recorrendo à consulta dos dados de origem.
Quando você modifica uma view de métricas, o Databricks não programa novas atualizações, a menos que você esteja habilitando a materialização pela primeira vez. As views materializadas não são usadas para reescrita automática de query até que a próxima atualização programada seja concluída.
Alterar o agendamento da materialização não Trigger um refresh.
Sem um agendamento, o pipeline executa uma atualização inicial na criação, mas os refresh subsequentes devem ser Trigger manualmente ou os dados ficam desatualizados. A Databricks recomenda sempre definir um agendamento para que os dados permaneçam atualizados, a menos que você esteja testando ou prototipando.
Veja refresh manual para um controle mais preciso sobre o comportamento de refresh.
Inspecionar o pipeline subjacente
A materialização para views de métricas é implementada usando LakeFlow Pipelines. É possível acessar o pipeline de duas maneiras:
- No Catalog Explorer : A tab Visão geral para a view de métricas inclui um Link direto sob o cabeçalho Refresh Schedule . Para saber como acessar o Catalog Explorer, consulte O que é o Catalog Explorer?.
- Usando SQL : Execute
DESCRIBE EXTENDED. A seção Informações de refresh contém o link do pipeline e o status de refresh atual.
DESCRIBE EXTENDED my_metric_view;
Exemplo de saída:
-- Returns additional metadata such as parent schema, owner, access time etc.
> DESCRIBE EXTENDED my_metric_view;
col_name data_type comment
------------------------------- ------------------------------ ----------
... ... ...
# Detailed Table Information
... ...
Language YAML
Table properties ...
# Refresh Information
Latest Refresh Status Succeeded
Latest Refresh https://...
Refresh Schedule EVERY 6 HOURS
Refresh manual
A partir do link para a página do pipeline do Lakeflow, você pode começar manualmente uma atualização do pipeline para atualizar as materializações. Você também pode trigger um refresh manual usando o seguinte comando SQL:
REFRESH MATERIALIZED VIEW <metric-view-name>
refresh incremental
As views materializadas usam refresh incremental sempre que possível e têm as mesmas limitações que as views materializadas padrão em relação às fontes de dados e à estrutura do plano.
Para detalhes sobre pré-requisitos e restrições, consulte refresh incremental para views materializadas.
Cobrança
Refreshes de visualizações materializadas incorrem em custos de uso de LakeFlow Pipelines. Para encontrar o consumo de DBU do pipeline, consulte Qual é o consumo de DBU de um pipeline serverless?.
Restrições conhecidas
As seguintes restrições se aplicam à materialização para views de métricas:
- Não é possível materializar uma view de métricas que defina parâmetros.
- Depois que uma materialização é criada para uma view de métricas, não é possível alterar o proprietário.
- A Databricks não oferece suporte à propriedade de grupo de views de métricas materializadas.
- Apenas a estratégia de correspondência exata é elegível para views de métricas com joins um-para-muitos.
- A materialização
schedulenão oferece suporte à cláusulaTRIGGER ON UPDATE.