Conectar-se ao pool dedicado do Azure Synapse Analytics
Experimental
A documentação antiga da federação de consultas foi retirada e pode não ser atualizada. As configurações mencionadas neste conteúdo não são oficialmente endossadas ou testadas pela Databricks. Se a Lakehouse Federation for compatível com seu banco de dados de origem, o site Databricks recomenda que o senhor a utilize.
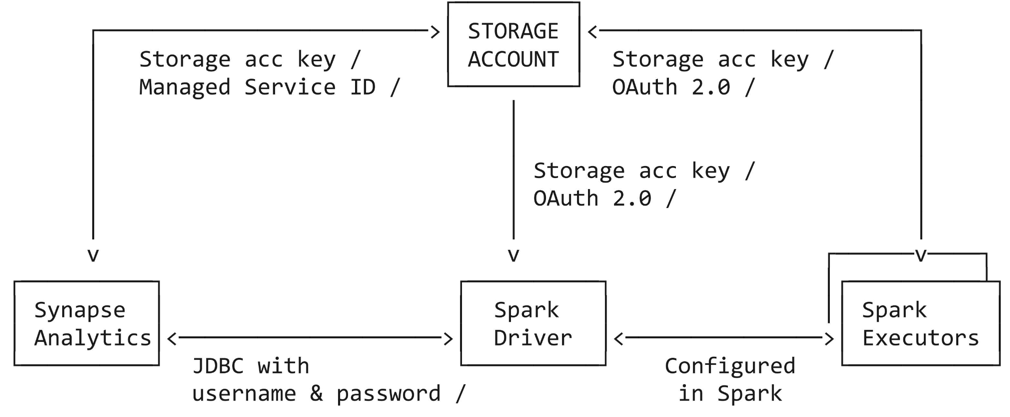
Este tutorial guia o senhor por todas as etapas necessárias para se conectar de Azure Databricks a Azure Synapse Analytics dedicado pool usando entidade de serviço, Azure serviço gerenciado Identity (MSI) e SQL Authentication. O conector do Azure Synapse usa três tipos de conexões de rede:
- Driver Spark para o Azure Synapse
- Spark driver e executor para Azure storage account
- Azure Synapse para Azure storage account
Requisitos
Conclua essa tarefa antes de iniciar o tutorial:
- Crie um workspace Azure Databricks . Consulte Criar um workspaceclássico
- Crie um Azure Synapse Analytics workspace. Consulte Início rápido: Criar um Synapse workspace
- Criar um pool de SQL dedicado. Consulte Início rápido: Criar um pool de SQL dedicado usando o portal do Azure
- Crie um data lake de teste Azure Armazenamento para a conexão entre Azure Databricks e Azure Synapse Analytics.
Conecte-se ao Azure Synapse Analytics usando uma entidade de serviço
As etapas a seguir neste tutorial mostram ao senhor como se conectar ao Azure Synapse Analytics usando uma entidade de serviço.
Etapa 1: Criar uma entidade de serviço Microsoft Entra ID para o armazenamento do data lake Azure
Para usar a entidade de serviço para se conectar ao Azure data lake Gen2, um usuário administrador deve criar um novo aplicativo Microsoft Entra ID (anteriormente conhecido como Azure Active Directory). Se o senhor já tiver uma entidade de serviço Microsoft Entra ID disponível, pule para a Etapa 3 . Para criar uma entidade de serviço Microsoft Entra ID, siga estas instruções:
- Faça login no portal do Azure.
- Se o senhor tiver acesso a vários locatários, inscrições ou diretórios, clique no ícone Diretórios + inscrição (diretório com filtro) no menu superior para alternar para o diretório no qual deseja provisionar a entidade de serviço.
- Pesquise e selecione Microsoft Entra ID .
- Em gerenciar , clique em App registrations (Registros de aplicativos) > New registration (Novo registro ).
- Em Nome , insira o nome do aplicativo.
- Na seção Supported account types (Tipos de suportados ), selecione account in this organizational directory only (Single tenant ).
- Clique em Registrar .
(Opcional) Etapa 2: Crie uma entidade de serviço Microsoft Entra ID para o Azure Synapse Analytics
Opcionalmente, o senhor pode criar uma entidade de serviço dedicada ao Azure Synapse Analytics repetindo as instruções da Etapa 1. Se o senhor não criar um conjunto separado de credenciais de entidade de serviço, a conexão usará a mesma entidade de serviço para se conectar ao data lake Gen2 do Azure e ao Azure Synapse Analytics.
Etapa 3: Crie um segredo de cliente para sua entidade de serviço Azure data lake Gen2 (e Azure Synapse Analytics)
- Em Gerenciar , clique em Certificados & secrets
- Em Client secrets (Segredos do cliente ) tab, clique em New client secret (Novo segredo do cliente ).
- No painel Adicionar um segredo do cliente , em Descrição , insira uma descrição para o segredo do cliente.
- Em Expira, selecione um período de expiração para o segredo do cliente e clique em Adicionar.
- Copie e armazene o valor do segredo do cliente em um local seguro, pois esse segredo do cliente é a senha do seu aplicativo.
- Na página Visão geral da página do aplicativo, na seção Essentials , copie os seguintes valores:
- ID da aplicação (cliente)
- ID do diretório (tenant)
Se o senhor criou um conjunto de credenciais de entidade de serviço para o Azure Synapse Analytics, siga as etapas novamente para criar um segredo de cliente.
Etapa 4: Conceder à entidade de serviço acesso ao Azure data lake Storage
O senhor concede acesso ao recurso de armazenamento atribuindo funções à sua entidade de serviço. Neste tutorial, o senhor atribui o Storage Blob Data Contributor à(s) entidade(s) de serviço(s) em seu data lake Azure Storage account. Talvez seja necessário atribuir outras funções, dependendo dos requisitos específicos.
- No portal Azure, acesse o serviço Storage account (Conta de armazenamento ).
- Selecione um armazenamento Azure account para usar.
- Clique em Controle de acesso (IAM) .
- Clique em + Add (Adicionar ) e selecione Add role assignment (Adicionar atribuição de função ) no menu dropdown.
- Defina o campo Select como o nome do aplicativo Microsoft Entra ID que o senhor criou na etapa 1 e defina Role como Storage Blob Data Contributor .
- Clique em Salvar .
Se o senhor criou um conjunto de credenciais de entidade de serviço para Azure Synapse Analytics, siga as etapas novamente para conceder acesso à entidade de serviço no data lake Storage Azure.
Etapa 5: Criar um key mestre em Azure Synapse Analytics dedicado pool
Conecte-se ao site Azure Synapse Analytics dedicado pool e crie um site mestre key, caso o senhor não o tenha feito antes.
CREATE MASTER KEY ENCRYPTION BY PASSWORD = '<Password>'
Etapa 6: Conceder permissões à entidade de serviço no pool dedicado do Azure Synapse Analytics
Conecte-se ao pool dedicado do Azure Synapse Analytics e crie um usuário externo para a entidade de serviço que se conectará ao Azure Synapse Analytics:
CREATE USER <serviceprincipal> FROM EXTERNAL PROVIDER
O nome da entidade de serviço deve corresponder àquele criado na Etapa 2 (ou na Etapa 1, se o senhor tiver pulado a criação de uma entidade de serviço dedicada para o Azure Synapse Analytics).
Conceda permissões à entidade de serviço para ser um db_owner executando o comando abaixo:
sp_addrolemember 'db_owner', '<serviceprincipal>'
Conceda as permissões necessárias para poder inserir em uma tabela existente:
GRANT ADMINISTER DATABASE BULK OPERATIONS TO <serviceprincipal>
GRANT INSERT TO <serviceprincipal>
(Opcional) Conceda as permissões necessárias para poder inserir em uma nova tabela:
GRANT CREATE TABLE TO <serviceprincipal>
GRANT ALTER ON SCHEMA ::dbo TO <serviceprincipal>
Etapa 7: Exemplo de sintaxe: consultar e gravar dados no Azure Synapse Analytics
O senhor pode consultar Synapse em Scala, Python, SQL, e R. Os exemplos de código a seguir usam a chave de armazenamento account e encaminham as credenciais de armazenamento de Azure Databricks para Synapse.
- Scala
- Python
- SQL
- R
Os exemplos de código a seguir mostram que você precisa:
- Configure o armazenamento account acesse key na sessão do Notebook
- Definir as credenciais da entidade de serviço para o armazenamento Azure account
- Defina um conjunto separado de credenciais de entidade de serviço para Azure Synapse Analytics (se não for definido, o conector usará as credenciais Azure storage account )
- Obter alguns dados de uma tabela do Azure Synapse
- Carregar dados de uma consulta do Azure Synapse
- Aplique algumas transformações aos dados e, em seguida, use a fonte de dados API para gravar os dados de volta em outra tabela no Azure Synapse
import org.apache.spark.sql.DataFrame
// Set up the storage account access key in the notebook session
conf.spark.conf.set(
"fs.azure.account.key.<your-storage-account-name>.dfs.core.windows.net",
"<your-storage-account-access-key>")
// Define the service principal credentials for the Azure storage account
spark.conf.set("fs.azure.account.auth.type", "OAuth")
spark.conf.set("fs.azure.account.oauth.provider.type", "org.apache.hadoop.fs.azurebfs.oauth2.ClientCredsTokenProvider")
spark.conf.set("fs.azure.account.oauth2.client.id", "<ApplicationId>")
spark.conf.set("fs.azure.account.oauth2.client.secret", "<SecretValue>")
spark.conf.set("fs.azure.account.oauth2.client.endpoint", "https://login.microsoftonline.com/<DirectoryId>/oauth2/token")
// Define a separate set of service principal credentials for Azure Synapse Analytics (If not defined, the connector will use the Azure storage account credentials)
spark.conf.set("spark.databricks.sqldw.jdbc.service.principal.client.id", "<ApplicationId>")
spark.conf.set("spark.databricks.sqldw.jdbc.service.principal.client.secret", "<SecretValue>")
// Get some data from an Azure Synapse table
val df: DataFrame = spark.read
.format("com.databricks.spark.sqldw")
.option("url", "jdbc:sqlserver://<the-rest-of-the-connection-string>")
.option("tempDir", "abfss://<your-container-name>@<your-storage-account-name>.dfs.core.windows.net/<your-directory-name>")
.option("enableServicePrincipalAuth", "true")
.option("dbTable", "dbo.<your-table-name>")
.load()
// Load data from an Azure Synapse query
val df1: DataFrame = spark.read
.format("com.databricks.spark.sqldw")
.option("url", "jdbc:sqlserver://<the-rest-of-the-connection-string>")
.option("tempDir", "abfss://<your-container-name>@<your-storage-account-name>.dfs.core.windows.net/<your-directory-name>")
.option("enableServicePrincipalAuth", "true")
.option("query", "select * from dbo.<your-table-name>")
.load()
// Apply some transformations to the data, then use the
// Data Source API to write the data back to another table in Azure Synapse
df1.write
.format("com.databricks.spark.sqldw")
.option("url", "jdbc:sqlserver://<the-rest-of-the-connection-string>")
.option("tempDir", "abfss://<your-container-name>@<your-storage-account-name>.dfs.core.windows.net/<your-directory-name>")
.option("enableServicePrincipalAuth", "true")
.option("dbTable", "dbo.<new-table-name>")
.save()
Os exemplos de código a seguir mostram que você precisa:
- Configure o armazenamento account acesse key na sessão do Notebook
- Definir as credenciais da entidade de serviço para o armazenamento Azure account
- Definir um conjunto separado de credenciais de entidade de serviço para Azure Synapse Analytics
- Obter alguns dados de uma tabela do Azure Synapse
- Carregar dados de uma consulta do Azure Synapse
- Aplique algumas transformações aos dados e, em seguida, use a fonte de dados API para gravar os dados de volta em outra tabela no Azure Synapse
Os exemplos de código a seguir mostram que você precisa:
- Definir as credenciais da entidade de serviço para o armazenamento Azure account
- Definir um conjunto separado de credenciais de entidade de serviço para Azure Synapse Analytics
- Configure o armazenamento account acesse key na sessão do Notebook
- Ler uso de dados SQL
- Escrever uso de dados SQL
# Define the Service Principal credentials for the Azure storage account
fs.azure.account.auth.type OAuth
fs.azure.account.oauth.provider.type org.apache.hadoop.fs.azurebfs.oauth2.ClientCredsTokenProvider
fs.azure.account.oauth2.client.id <application-id>
fs.azure.account.oauth2.client.secret <service-credential>
fs.azure.account.oauth2.client.endpoint https://login.microsoftonline.com/<directory-id>/oauth2/token
## Define a separate set of service principal credentials for Azure Synapse Analytics (If not defined, the connector will use the Azure storage account credentials)
spark.databricks.sqldw.jdbc.service.principal.client.id <application-id>
spark.databricks.sqldw.jdbc.service.principal.client.secret <service-credential>
# Set up the storage account access key in the notebook session
conf.SET fs.azure.account.key.<your-storage-account-name>.dfs.core.windows.net=<your-storage-account-access-key>
-- Read data using SQL
CREATE TABLE df
USING com.databricks.spark.sqldw
OPTIONS (
url 'jdbc:sqlserver://<the-rest-of-the-connection-string>',
'enableServicePrincipalAuth' 'true',
dbtable 'dbo.<your-table-name>',
tempDir 'abfss://<your-container-name>@<your-storage-account-name>.dfs.core.windows.net/<your-directory-name>'
);
-- Write data using SQL
-- Create a new table, throwing an error if a table with the same name already exists:
CREATE TABLE df1
USING com.databricks.spark.sqldw
OPTIONS (
url 'jdbc:sqlserver://<the-rest-of-the-connection-string>',
'enableServicePrincipalAuth' 'true',
dbTable 'dbo.<new-table-name>',
tempDir 'abfss://<your-container-name>@<your-storage-account-name>.dfs.core.windows.net/<your-directory-name>'
)
AS SELECT * FROM df1
Os exemplos de código a seguir mostram que você precisa:
- Configure o armazenamento account acesse key no conf. de sessão do Notebook
- Definir as credenciais da entidade de serviço para o armazenamento Azure account
- Defina um conjunto separado de credenciais de entidade de serviço para Azure Synapse Analytics (se não for definido, o conector usará as credenciais Azure storage account )
- Obter alguns dados de uma tabela do Azure Synapse
- Aplique algumas transformações aos dados e, em seguida, use a fonte de dados API para gravar os dados de volta em outra tabela no Azure Synapse
# Load SparkR
library(SparkR)
# Set up the storage account access key in the notebook session conf
conf <- sparkR.callJMethod(sparkR.session(), "conf")
sparkR.callJMethod(conf, "set", "fs.azure.account.key.<your-storage-account-name>.dfs.core.windows.net", "<your-storage-account-access-key>")
# Load SparkR
library(SparkR)
conf <- sparkR.callJMethod(sparkR.session(), "conf")
# Define the service principal credentials for the Azure storage account
sparkR.callJMethod(conf, "set", "fs.azure.account.auth.type", "OAuth")
sparkR.callJMethod(conf, "set", "fs.azure.account.oauth.provider.type", "org.apache.hadoop.fs.azurebfs.oauth2.ClientCredsTokenProvider")
sparkR.callJMethod(conf, "set", "fs.azure.account.oauth2.client.id", "<ApplicationId>")
sparkR.callJMethod(conf, "set", "fs.azure.account.oauth2.client.secret", "<SecretValue>")
sparkR.callJMethod(conf, "set", "fs.azure.account.oauth2.client.endpoint", "https://login.microsoftonline.com/<DirectoryId>/oauth2/token")
# Define a separate set of service principal credentials for Azure Synapse Analytics (If not defined, the connector will use the Azure storage account credentials)
sparkR.callJMethod(conf, "set", "spark.databricks.sqldw.jdbc.service.principal.client.id", "<ApplicationId>")
sparkR.callJMethod(conf, "set", "spark.databricks.sqldw.jdbc.service.principal.client.secret", "SecretValue>")
# Get some data from an Azure Synapse table
df <- read.df(
source = "com.databricks.spark.sqldw",
url = "jdbc:sqlserver://<the-rest-of-the-connection-string>",
tempDir = "abfss://<your-container-name>@<your-storage-account-name>.dfs.core.windows.net/<your-directory-name>",
enableServicePrincipalAuth = "true",
dbTable = "dbo.<your-table-name>")
# Load data from an Azure Synapse query.
df <- read.df(
source = "com.databricks.spark.sqldw",
url = "jdbc:sqlserver://<the-rest-of-the-connection-string>",
tempDir = "abfss://<your-container-name>@<your-storage-account-name>.dfs.core.windows.net/<your-directory-name>",
enableServicePrincipalAuth = "true",
query = "Select * from dbo.<your-table-name>")
# Apply some transformations to the data, then use the
# Data Source API to write the data back to another table in Azure Synapse
write.df(
df,
source = "com.databricks.spark.sqldw",
url = "jdbc:sqlserver://<the-rest-of-the-connection-string>",
tempDir = "abfss://<your-container-name>@<your-storage-account-name>.dfs.core.windows.net/<your-directory-name>",
enableServicePrincipalAuth = "true",
dbTable = "dbo.<new-table-name>")
Solução de problemas
As seções a seguir discutem as mensagens de erro que você pode encontrar e seus possíveis significados.
a credencial da entidade de serviço não existe como um usuário
com.microsoft.sqlserver.jdbc.SQLServerException: Login failed for user '<token-identified principal>'
O erro anterior provavelmente significa que a credencial da entidade de serviço não existe como um usuário no site Synapse analítica workspace.
Execute o seguinte comando no site Azure Synapse Analytics dedicado pool para criar um usuário externo:
CREATE USER <serviceprincipal> FROM EXTERNAL PROVIDER
A credencial da entidade de serviço tem permissões insuficientes SELECT
com.microsoft.sqlserver.jdbc.SQLServerException: The SELECT permission was denied on the object 'TableName', database 'PoolName', schema 'SchemaName'. [ErrorCode = 229] [SQLState = S0005]
O erro anterior provavelmente significa que a credencial da entidade de serviço não tem permissões SELECT suficientes no pool dedicado do Azure Synapse Analytics.
Execute o seguinte comando no site Azure Synapse Analytics dedicado pool para conceder permissões SELECT:
GRANT SELECT TO <serviceprincipal>
A credencial da entidade de serviço não tem permissão para usar COPY
com.microsoft.sqlserver.jdbc.SQLServerException: User does not have permission to perform this action. [ErrorCode = 15247] [SQLState = S0001]
O erro anterior provavelmente significa que a credencial da entidade de serviço não tem permissões suficientes no pool dedicado do Azure Synapse Analytics para usar COPY. A entidade de serviço requer permissões diferentes, dependendo das operações (inserir em uma tabela existente ou inserir em uma nova tabela). Certifique-se de que a entidade de serviço tenha as permissões necessárias do Azure Synapse.
A entidade de serviço não é um db_owner do pool dedicado do Azure Synapse Analytics.
Execute o seguinte comando no site Azure Synapse Analytics dedicado pool para conceder permissões db_owner :
sp_addrolemember 'db_owner', 'serviceprincipal'
Nenhum mestre key no dedicado pool
com.microsoft.sqlserver.jdbc.SQLServerException: Please create a master key in the database or open the master key in the session before performing this operation. [ErrorCode = 15581] [SQLState = S0006]
O erro anterior provavelmente significa que não há um key mestre no Azure Synapse Analytics dedicado pool.
Crie um mestre key em Azure Synapse Analytics para corrigir esse problema.
A credencial da entidade de serviço não tem permissões de gravação suficientes
com.microsoft.sqlserver.jdbc.SQLServerException: CREATE EXTERNAL TABLE AS SELECT statement failed as the path name '' could not be used for export. Please ensure that the specified path is a directory which exists or can be created, and that files can be created in that directory. [ErrorCode = 105005] [SQLState = S0001]
O erro anterior provavelmente significa que:
-
A credencial da entidade de serviço não tem permissões suficientes para as operações de gravação do PolyBase
Certifique-se de que a entidade de serviço tenha as permissões Azure Synapse necessárias para o PolyBase com a opção de fonte externa de dados.
-
O armazenamento de preparação account não tem recursos de armazenamento de data lake Azure.
O senhor pode fazer upgrade do Azure Blob Storage com os recursos de armazenamento do data lake do Azure.
-
A identidade da entidade de serviço/serviço gerenciado não tem a função "Storage Blob Data Contributor" no armazenamento do data lake Azure.
-
Consulte Error 105005 when you do CETAS operações to Azure blob storage para obter mais soluções de problemas.