O que são cálculos personalizados?
Os cálculos personalizados permitem definir métricas e transformações dinâmicas sem modificar as consultas dataset . Esta página explica como usar cálculos personalizados em painéis de AI/BI .
Por que usar cálculos personalizados?
Os cálculos personalizados permitem criar e visualizar novos campos a partir de um conjunto de dados de painel existente, sem alterar o SQL de origem. Você pode definir até 200 cálculos personalizados por dataset.
Os cálculos personalizados são de um dos seguintes tipos:
- Medidas calculadas : Valores agregados, como o total de vendas ou o custo médio. As medidas calculadas podem usar o comando
AGGREGATE OVERpara compute valores em intervalos de tempo. - Dimensões calculadas : Valores não agregados ou transformações, como categorização de faixas etárias ou formatação de strings.
Os cálculos personalizados comportam-se de forma semelhante à visualização de métricas, mas estão limitados ao dataset e ao painel onde são definidos. Para definir métricas personalizadas que podem ser usadas com outros dados ativos, consulte a visualização de métricasUnity Catalog.
Crie métricas dinâmicas com medidas calculadas.
Suponha que você tenha o seguinte dataset:
Item | Região | Preço | Custo | Data |
|---|---|---|---|---|
Maçãs | EUA | 30 | 15 | 2024-01-01 |
Maçãs | Canadá | 20 | 10 | 2024-01-01 |
Laranjas | EUA | 20 | 15 | 2024-01-02 |
Laranjas | Canadá | 15 | 10 | 2024-01-02 |
Você deseja visualizar a margem de lucro por região. Sem cálculos personalizados, você precisaria criar um novo dataset com uma coluna margin :
Região | Margem |
|---|---|
EUA | 0,40 |
Canadá | 0,43 |
Embora essa abordagem funcione, o novo dataset é estático e pode suportar apenas uma única visualização. Os filtros aplicados ao dataset original não afetam o novo dataset sem ajustes manuais adicionais.
Com cálculos personalizados, você pode expressar a margem de lucro como uma agregação usando a seguinte fórmula:
(SUM(Price) - SUM(Cost)) / SUM(Price)
Essa medida é dinâmica. Quando usado em uma visualização, ele se atualiza automaticamente para refletir os agrupamentos da visualização. Por exemplo, a mesma medida acima pode ser usada para visualizar a margem de lucro por Region ou por Item, dependendo do que for selecionado na visualização.
Defina valores não agregados com dimensões calculadas.
As dimensões calculadas permitem definir valores não agregados ou transformações leves sem alterar o dataset de origem. Isso é útil quando você deseja organizar ou reformatar dados para visualização.
Por exemplo, para analisar tendências etárias por faixa etária em vez de idades individuais, você pode definir uma dimensão personalizada age_group usando a seguinte expressão:
CASE
WHEN age < 18 THEN '<18'
WHEN age >= 18 AND age < 25 THEN '18–24'
WHEN age >= 25 AND age < 35 THEN '25–34'
WHEN age >= 35 AND age < 45 THEN '35–44'
WHEN age >= 45 AND age < 55 THEN '45–54'
WHEN age >= 55 AND age < 65 THEN '55–64'
WHEN age >= 65 THEN '65+'
END
Defina cálculos em uma janela.
Uma tarefa comum em visualizações de dashboards é compute uma agregação em um intervalo, como a soma acumulada das vendas nos últimos sete dias. Os cálculos personalizados suportam essa funcionalidade por meio de funções de janela, que permitem realizar cálculos em um conjunto de linhas (uma "janela") relacionadas à linha atual.
Os painéis de AI/BI suportam dois tipos de funções de janela:
- Funções de janela escalares, que agregam dados em agrupamentos fixos e se comportam como funções escalares. Quando usados isoladamente, eles formam dimensões calculadas.
- Funções de janela agregadas, que agregam agrupamentos dinâmicos e se comportam como funções agregadas. Quando utilizados, eles formam medidas calculadas.
As funções de janela também são a base para expressões de nível de detalhe, que permitem controlar a granularidade da agregação independentemente dos agrupamentos da sua visualização.
Funções de janela escalar
As funções de janela escalar usam o operador OVER com cláusulas opcionais PARTITION BY e ORDER BY para compute agregações entre linhas relacionadas antes que qualquer agrupamento de visualização tenha ocorrido. Eles se agregam em um conjunto estático de partições definidas na própria função de janela, antes de serem reunidos à tabela subjacente não transformada como uma dimensão.
Exemplo de cálculo do total de vendas por região:
SUM(sales) OVER (PARTITION BY Region)
Exemplo de cálculo de vendas cumulativas por região:
SUM(sales) OVER (PARTITION BY Region ORDER BY Date RANGE BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW)
sintaxeOVER
<AGGREGATE_FUNCTION>(<column>) OVER (
[PARTITION BY <dimensions>]
[ORDER BY <column>]
[ROWS|RANGE frame_specification]
)
Consulte a seção "Funções de janela" na referência da linguagem SQL para obter mais detalhes.
Funções de janela agregadas
As funções de janela agregada usam o operador AGGREGATE OVER para compute agregações em janelas após a aplicação do agrupamento de visualização. Os grupos a serem agregados são herdados automaticamente da visualização na qual a expressão é usada. Você pode opcionalmente usar uma cláusula PARTITION BY com * para representar todas as partições herdadas e excluir dimensões específicas usando a cláusula EXCEPT . A cláusula ORDER BY permite agregar parcialmente as partições resultantes em linhas adjacentes, fornecendo funcionalidade de "janelas".
Usando o mesmo dataset do exemplo anterior, a seguinte expressão calcula a margem de lucro média dos últimos sete dias usando o operador AGGREGATE OVER .
(
(SUM(Price) - SUM(Cost)) / SUM(Price)
) AGGREGATE OVER (
ORDER BY Date TRAILING 7 DAY
)
Após a criação, essa medida pode ser aplicada em qualquer visualização.
sintaxeAGGREGATE OVER
<AGGREGATE_EXPRESSION> AGGREGATE OVER (
[PARTITION BY * [EXCEPT (<field> [, ...])]]
[ORDER BY <field> <frame_specification>]
)
Nessa sintaxe:
PARTITION BY *representa todas as partições herdadas do agrupamento de visualizaçãoEXCEPT (<field> [, ...])Especifica as dimensões a serem excluídas do conjunto de partições.- As cláusulas
PARTITION BYeORDER BYsão opcionais, mas uma cláusulaAGGREGATE OVER ()vazia não é válida.
A especificação do quadro pode ser uma das seguintes:
CURRENTCUMULATIVEALL(TRAILING|LEADING) <number> <unit> [INCLUSIVE|EXCLUSIVE]<number>é um número inteiro positivo<unit>éDAY,MONTHouYEAR- A palavra-chave opcional
INCLUSIVEinclui a linha atual no intervalo.EXCLUSIVEo exclui. O default seráEXCLUSIVE. - Por exemplo:
TRAILING 7 DAY INCLUSIVEouLEADING 1 MONTH
É possível anexar opcionalmente uma cláusula OFFSET para deslocar todo o intervalo por um intervalo especificado:
OFFSET <number> <unit>- Aceita as mesmas especificações de intervalo que
TRAILINGeLEADING - Exemplo:
TRAILING 7 DAY OFFSET -1 YEAR
- Aceita as mesmas especificações de intervalo que
A tabela a seguir identifica como a especificação de quadro para agregação sobre se compara à cláusula de quadro de janela SQL equivalente.
Especificações do quadro | Cláusula equivalente de janela SQL |
|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Se o campo ORDER BY não estiver agrupado na visualização, AGGREGATE OVER assume o valor agregado da última linha como o valor a ser exibido para cada grupo. Isso é equivalente ao comportamento semi-aditivo "final".
OVER versus AGGREGATE OVER
A principal diferença entre OVER e AGGREGATE OVER é que OVER é uma função escalar e AGGREGATE OVER é uma função agregada. OVER requer uma cláusula PARTITION BY para definir grupos, enquanto AGGREGATE OVER herda seus grupos da visualização circundante e pode incorporar dados fora do grupo atual.
Use a sintaxe OVER para :
- Cálculos de janela que precisam ser usados em contextos não agregados, como tabelas.
- Cálculos de janela que devem ignorar todos os agrupamentos e filtros de visualização.
- Agregação em um nível fixo de detalhes: Computar agregações em uma granularidade específica usando
PARTITION BY. - Utilizando funções de classificação e analíticas como
ROW_NUMBER,RANK,LAG.
Use a sintaxe AGGREGATE OVER para :
- Cálculos de janela que podem ser usados em diversos contextos de agrupamento ou que precisam incorporar dados externos ao grupo atual.
- Cálculos de janela que respeitam os filtros de visualização.
- Agregando em um nível de detalhe mais grosseiro do que a visualização: Excluindo dimensões usando
PARTITION BY * EXCEPT (...). - Intervalos baseados em tempo que são robustos a linhas ausentes: Janelas móveis com
TRAILINGouLEADING.
Benefícios de desempenho
Os cálculos personalizados são otimizados para melhor desempenho. Para conjuntos de dados pequenos (≤100.000 linhas e ≤100 MB), os cálculos são executados no navegador para uma resposta mais rápida. Conjuntos de dados maiores são processados pelo SQL warehouse. Consulte a seção sobre otimização e armazenamento em cache de conjuntos de dados para obter mais detalhes.
Criar um cálculo personalizado
Este exemplo cria uma medida calculada com base no dataset samples.nyctaxi.trips . Pressupõe-se conhecimento geral sobre como trabalhar com dashboards AI/BI . Se você não estiver familiarizado com a criação de dashboards AI/BI , consulte Criar um dashboard para começar.
-
Abra um dataset existente ou crie um novo.
-
Clique em + Adicionar cálculo personalizado .
-
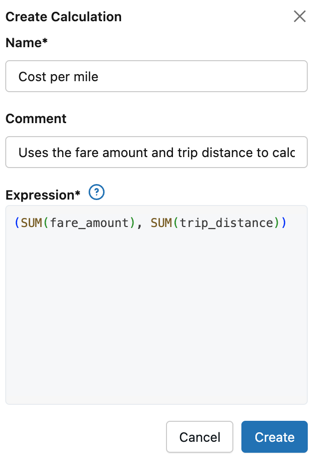
Um painel "Criar Cálculo" é aberto no lado direito da tela. No campo Nome , digite Custo por milha .
-
(Opcional) No campo de texto Comentário , digite "Utiliza o valor da tarifa e a distância da viagem para calcular o custo por milha."
-
No campo Expressão , insira o seguinte:
SQLtry_divide(SUM(fare_amount), SUM(trip_distance)) -
Clique em Criar .
Referenciando outros cálculos
Os cálculos personalizados podem fazer referência a outros cálculos personalizados definidos no mesmo dataset. Isso permite criar métricas complexas a partir de cálculos mais simples, promovendo a reutilização e a facilidade de manutenção.
Ao fazer referência a outro cálculo personalizado, use o nome dele diretamente na sua expressão, como se fosse uma coluna no dataset.
Por exemplo, suponha que você tenha criado estas medidas calculadas:
- receita_total :
SUM(sale_amount) - custo_total :
SUM(cost_amount)
Você pode criar uma terceira medida calculada que faça referência a ambas:
- margem_de_lucro :
(MEASURE(total_revenue) - MEASURE(total_cost)) / MEASURE(total_revenue)
- Você só pode referenciar cálculos no mesmo dataset.
- Referências circulares não são permitidas (o cálculo A não pode referenciar o cálculo B se B referenciar A).
- Os cálculos referenciados devem ser criados antes de poderem ser usados em outras expressões.
Adicione cálculos personalizados a uma viewmétrica
Visualização
Este recurso está em Pré-visualização Pública.
Você pode definir cálculos personalizados com base em um dataset criado por uma view de métricas. Ao abrir o dataset, apenas a tabela de resultados e o esquema são exibidos. Clique em Cálculo personalizado para definir um novo cálculo personalizado. Para definir métricas personalizadas adicionais que outros dados ativos possam usar, faça alterações na definição view . Veja a visualização de métricasUnity Catalog.
Para definir uma nova view de métricas a partir do editor dataset do painel, consulte Exportar como uma viewde métricas.
veja o esquema
Clique na tab Esquema no painel de resultados para view o cálculo personalizado e o comentário associado.
As medidas calculadas estão listadas na seção Medidas e marcadas com um asterisco.![]() fx. O valor associado a uma medida calculada é calculado dinamicamente quando você define o
fx. O valor associado a uma medida calculada é calculado dinamicamente quando você define o GROUP BY em uma visualização. Você não consegue visualizar o valor na tabela de resultados. As dimensões calculadas aparecem na seção Dimensões .

Utilize um cálculo personalizado em uma visualização.
Você pode usar a métrica calculada de Custo por milha criada anteriormente em uma visualização.
As medidas calculadas são agregadas automaticamente em relação às dimensões configuradas no seu gráfico. Esse comportamento é semelhante ao funcionamento das dimensões e medidas na visualização de métricas, onde a agregação se adapta dinamicamente aos agrupamentos definidos na visualização.
- Clique em Página sem título . Em seguida, insira um novo widget de visualização na página.
- Utilize o painel de configuração de visualização para editar as configurações da seguinte forma:
-
Conjunto de dados : Dados de táxi
-
Visualização : Barra
-
Eixo X :
- Campo : dropoff_zip
- Tipo de escala : Categórica
- Transformar : Nenhuma
-
Eixo Y :
- Custo por milha
-
As visualizações em tabela suportam dimensões calculadas, mas não suportam medidas calculadas.
A imagem a seguir mostra o gráfico.
As visualizações com cálculos personalizados são atualizadas automaticamente quando os filtros são aplicados. Por exemplo, adicionar um filtro pickup_zip atualizará a visualização para mostrar apenas os dados que correspondem aos valores selecionados.
Editar um cálculo personalizado
Para editar um cálculo:
- Clique na tab Dados e, em seguida, clique no dataset associado ao cálculo que deseja editar.
- Clique na tab Esquema no painel de resultados.
- As medidas e dimensões aparecem abaixo da lista de campos dataset . Clique no
 Menu de kebabs à direita do cálculo que você deseja editar. Em seguida, clique em Editar .
Menu de kebabs à direita do cálculo que você deseja editar. Em seguida, clique em Editar . - No painel Editar cálculo personalizado , atualize os campos de texto que deseja editar. Em seguida, clique em Atualizar .
Excluir um cálculo personalizado
Para excluir um cálculo:
- Clique na tab Dados e, em seguida, clique no dataset associado à métrica que deseja editar.
- Clique na tab Esquema no painel de resultados.
- A seção Medidas aparece abaixo da lista de campos. Clique no O menu de kebabs está à direita do cálculo que você deseja editar. Em seguida, clique em Excluir .
- Clique em Excluir na caixa de diálogo Excluir que aparece.
Utilizar parâmetros em cálculos personalizados
Você pode referenciar parâmetros diretamente em cálculos personalizados usando a sintaxe :keyword . Os parâmetros permitem alterar dinamicamente as medidas e dimensões.
Por exemplo, considere um dataset com uma coluna contendo as idades dos usuários. Para criar uma definição dinâmica de "adulto", você pode criar um cálculo personalizado usando um parâmetro chamado adult_age_threshold:
CASE
WHEN age > :adult_age_threshold THEN "adult"
END
Onde :adult_age_threshold é um parâmetro com um tipo de dados numérico. No painel de controle, os usuários podem definir o parâmetro :adult_age_threshold dinamicamente, o que atualiza a dimensão.
Um cálculo personalizado que faz referência a um parâmetro herda o tipo de dados do parâmetro, de modo que os widgets subsequentes o interpretem corretamente sem configuração adicional.
Cálculos personalizados que utilizam parâmetros funcionam com widgets de filtro. Quando um usuário seleciona um valor, o cálculo personalizado é atualizado automaticamente. O parâmetro selecionado também é salvo no URL, de modo que os links favoritos ou compartilhados mantenham as mesmas configurações de filtro quando o painel for aberto.
Limitações
Para usar cálculos personalizados, as seguintes condições devem ser atendidas:
- As colunas utilizadas na expressão devem pertencer ao mesmo dataset.
- Expressões que fazem referência a tabelas externas ou fontes de dados não são suportadas e podem falhar ou retornar resultados inesperados.
Funções suportadas
Para obter uma referência completa de todas as funções suportadas para cálculos personalizados, consulte a Referência de funções de cálculo personalizadas. A tentativa de usar uma função não suportada resulta em um erro.
Exemplos
Os exemplos a seguir demonstram usos comuns para cálculos personalizados. Cada cálculo personalizado aparece no esquema do conjunto de dataset, na tab de dados. Na tela, você pode escolher o cálculo personalizado como um campo.
Filtrar e agregar dados condicionalmente
Use uma instrução CASE para agregar dados condicionalmente. O exemplo a seguir usa o dataset samples.nyctaxi.trips e calcula a soma das tarifas para todas as viagens que começam no código postal 10103.
SUM(CASE
WHEN pickup_zip=10103 THEN fare_amount
WHEN pickup_zip!=10103 THEN 0
END)
Construir strings
Use a função CONCAT para construir um novo valor de string. Veja a funçãoconcat e a funçãoconcat_ws.
CONCAT(first_name, ' ', last_name)
Formatar datas
Use DATE_FORMAT para formatar strings de data que aparecem nas visualizações.
DATE_FORMAT(tpep_pickup_datetime, 'YYYY-MM-dd')