tipos de visualizaçãoAI/BI dashboard
Esta página descreve os tipos de visualizações disponíveis para uso em painéis de AI/BI e mostra como criar um exemplo de cada tipo de visualização. Para obter instruções sobre como criar um painel de controle, consulte Criar um painel de controle. Você pode usar linguagem natural para dar comandos Genie Code e criar gráficos de barras, linhas, pontos, dispersão, pie e contadores. Consulte Usar o código Genie para criação de dashboards.
Esta página aborda visualizações para painéis deAI/BI . Para visualizações no Databricks Notebook e no editor SQL , consulte Tipos de visualizaçãoNotebook e do editor SQL.
Para obter informações sobre os limites de renderização da visualização, consulte Limites do painel.
Visualização de área
As visualizações de área combinam as visualizações de linha e de barra para mostrar como os valores numéricos de um ou mais grupos mudam ao longo da progressão de uma segunda variável, normalmente o tempo. Eles são frequentemente usados para mostrar as mudanças funnel ventilação ao longo do tempo.
Para ajustar o:
- Clique no
 Menu de kebab na seção do eixo Y do painel de edição de visualização.
Menu de kebab na seção do eixo Y do painel de edição de visualização. - Na seção Disposição , escolha Empilhar ou Empilhar 100% .
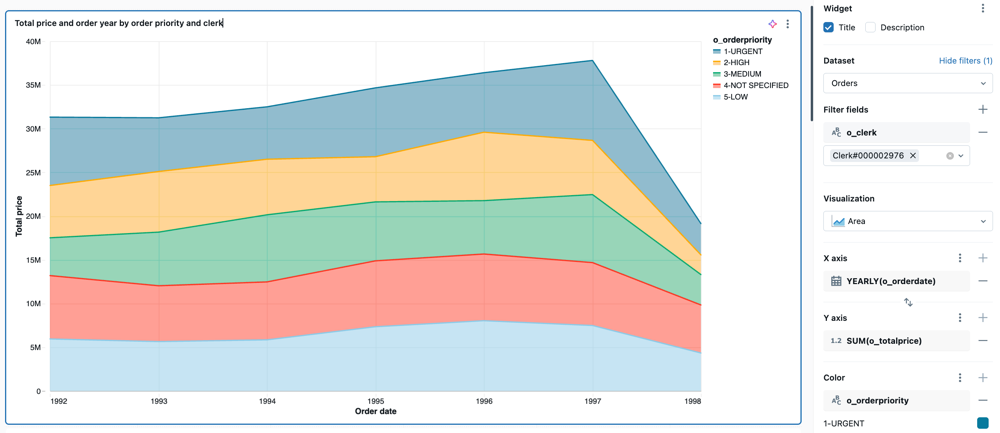
Valores de configuração : Para o exemplo de visualização de área fornecido, os seguintes valores foram definidos:
-
conjunto de dados: samples.tpch.orders
-
Visualização: Área
-
Título:
Total price and order year by order priority and clerk -
Eixo X:
- Campo:
o_orderdate - Transformar:
Yearly - Tipo de escala:
Continuous - Nome de exibição:
Order year
- Campo:
-
Eixo Y
- Campo:
o_totalprice - Nome de exibição:
Total price - Tipo de escala:
Continuous - Transformar:
Sum
- Campo:
-
Cor:
- Campo:
o_orderpriority - Título da legenda:
Order priority
- Campo:
-
Filtrar
- Campo:
TPCH orders.o_clerk
- Campo:
Consulta SQL: Para esta visualização de área, a seguinte consulta SQL foi usada para gerar o dataset TPCH orders nomeado.
SELECT * FROM samples.tpch.orders;
Gráfico de barras
Os gráficos de barras representam a variação de ao longo do tempo ou entre categorias e mostram proporcionalidade, de forma semelhante a uma visualização em gráfico pie .
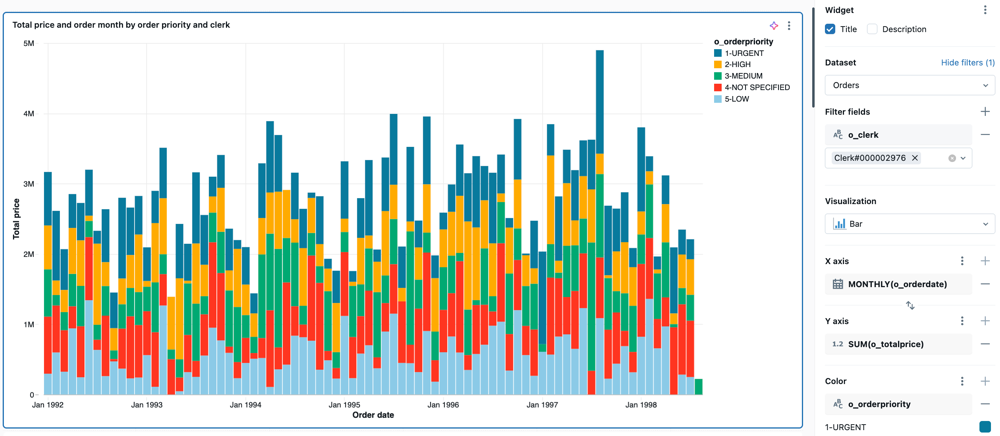
Para ajustar o:
- Clique no Menu de kebab na seção do eixo Y do painel de edição de visualização.
- Na seção Disposição , escolha Pilha ou Pilha 100% ou Grupo .
Valores de configuração : Para o exemplo de gráfico de barras fornecido, os seguintes valores foram definidos:
-
conjunto de dados: samples.tpch.orders
-
Visualização: Barra
-
Título:
Total price and order month by order priority and clerk -
Eixo X:
- Campo:
o_orderdate - Transformar:
Monthly - Tipo de escala:
Continuous - Nome de exibição:
Order month
- Campo:
-
Eixo Y
- Campo:
o_totalprice - Tipo de escala:
Continuous - Transformar:
Sum - Nome de exibição:
Total price
- Campo:
-
Cor:
- Campo:
o_orderpriority - Título da legenda:
Order priority
- Campo:
-
Filtrar
- Campo:
TPCH orders.o_clerk
- Campo:
Consulta SQL : a seguinte consulta SQL gerou o dataset TPCH orders para esta visualização de barras.
SELECT * FROM samples.tpch.orders;
Diagrama de caixa
O gráfico de caixa (ou diagrama de caixa) mostra o resumo da distribuição de dados numéricos, opcionalmente agrupados por categoria. Utilizando um gráfico de caixa (box chart), você pode comparar rapidamente os intervalos de valores entre as categorias e visualizar a localidade, a dispersão e a assimetria dos valores por meio de seus quartis. Em cada caixa, a linha mais escura mostra o intervalo interquartil. Para obter mais informações sobre a interpretação de visualizações de gráficos de caixa, consulte os artigos do gráfico de caixa na Wikipedia.
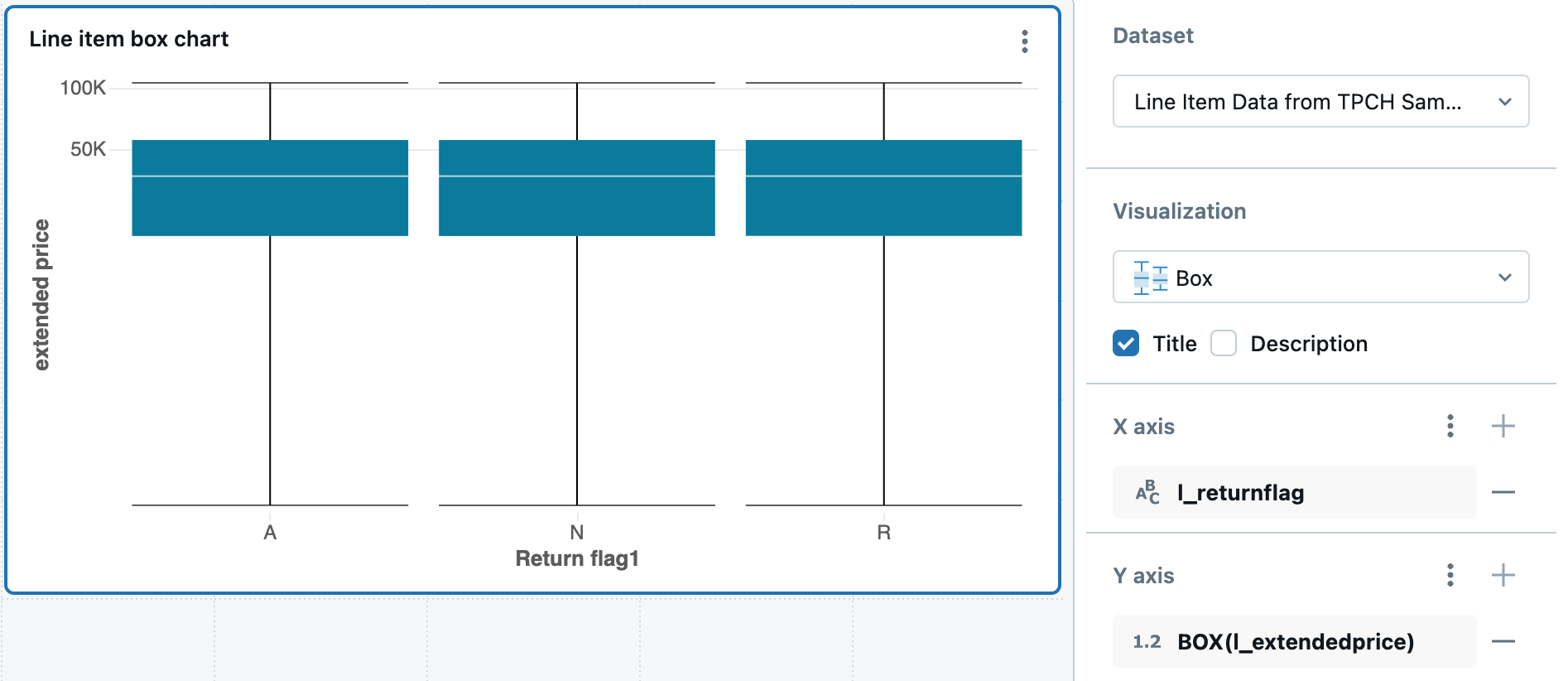
Para o exemplo de gráfico de caixa fornecido, foram definidos os seguintes valores:
- Coluna X (coluna dataset ):
l-returnflag - Colunas Y (coluna dataset ):
l_extendedprice - Nome de exibição X:
Return flag1 - Nome de exibição Y:
Extended price
Consulta SQL : Para esta visualização de gráfico de caixa, a seguinte consulta SQL foi usada para gerar o dataset.
SELECT * FROM samples.tpch.lineitem;
gráfico de bolhas
Os gráficos de bolhas são gráficos de dispersão onde o tamanho de cada marcador de ponto reflete uma métrica relevante. Para criar um gráfico de bolhas, selecione Dispersão como tipo de visualização. Na configuração Tamanho , selecione as medidas que deseja representar pelo tamanho dos marcadores.
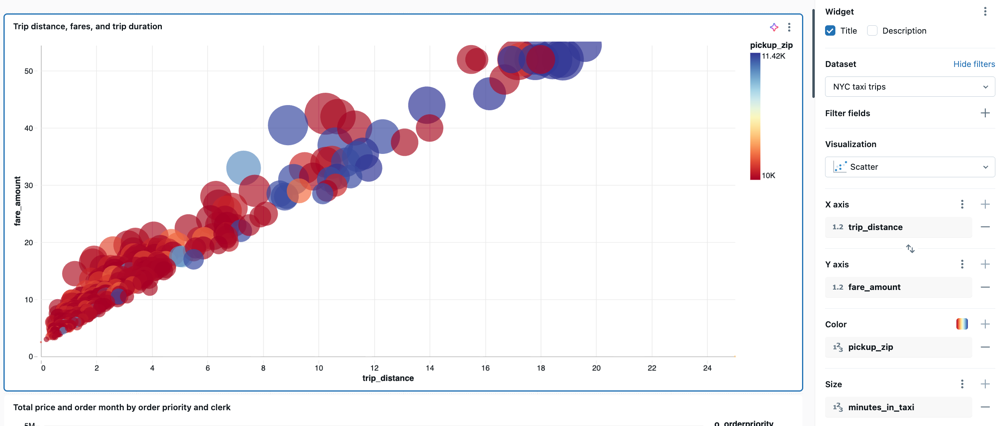
Valores de configuração : Para o exemplo de gráfico de bolhas fornecido, os seguintes valores foram definidos:
-
Conjunto de dados: viagens de táxi em Nova Iorque
-
Visualização: Dispersão
-
Título:
Trip distance, fares, and trip duration -
Eixo X:
- Campo:
trip_distance - Tipo de escala:
Continuous - Transformar:
None
- Campo:
-
Eixo Y
- Campo:
fare_amount - Tipo de escala:
Continuous - Transformar:
None
- Campo:
-
Colorir por:
- Campo:
pickup_zip
- Campo:
-
Tamanho:
- Campo:
minutes_in_taxi - Transformar:
None
- Campo:
Consulta SQL : Para esta visualização de gráfico de bolhas, a seguinte consulta SQL foi usada para gerar o dataset.
SELECT
*,
TIMESTAMPDIFF(MINUTE, tpep_pickup_datetime, tpep_dropoff_datetime) AS minutes_in_taxi
FROM samples.nyctaxi.trips
LIMIT 500;
Mapa coroplético
Em visualizações coropléticas, localidades geográficas, como países ou estados, são coloridas de acordo com os valores agregados de cada coluna key . A consulta deve retornar localizações geográficas por nome. Os usuários podem criar mapas que exibem as divisões administrativas em nível de país, estado ou província, e condado ou distrito.
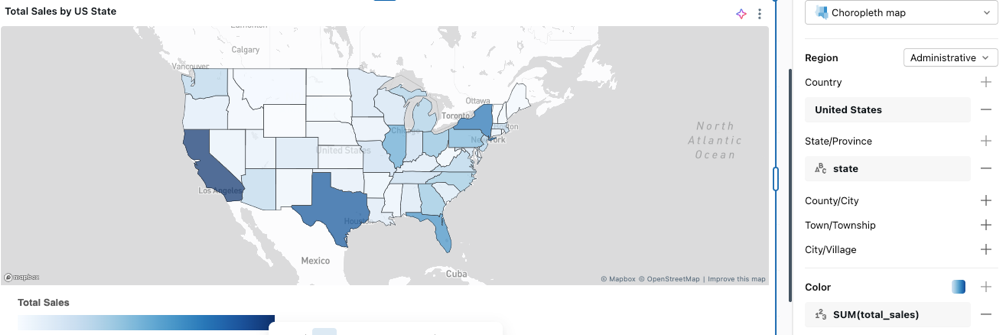
Para um exemplo de configuração e opções de mapa coroplético, consulte Opções de mapa coroplético.
Gráfico de coorte
Os gráficos de coorte visualizam a retenção de usuários e os padrões de comportamento ao longo do tempo, agrupando usuários com base em uma característica compartilhada (como a data de inscrição) e acompanhando sua atividade em períodos subsequentes. Essa visualização ajuda você a entender como diferentes grupos de usuários interagem com seu produto ou serviço ao longo do tempo.
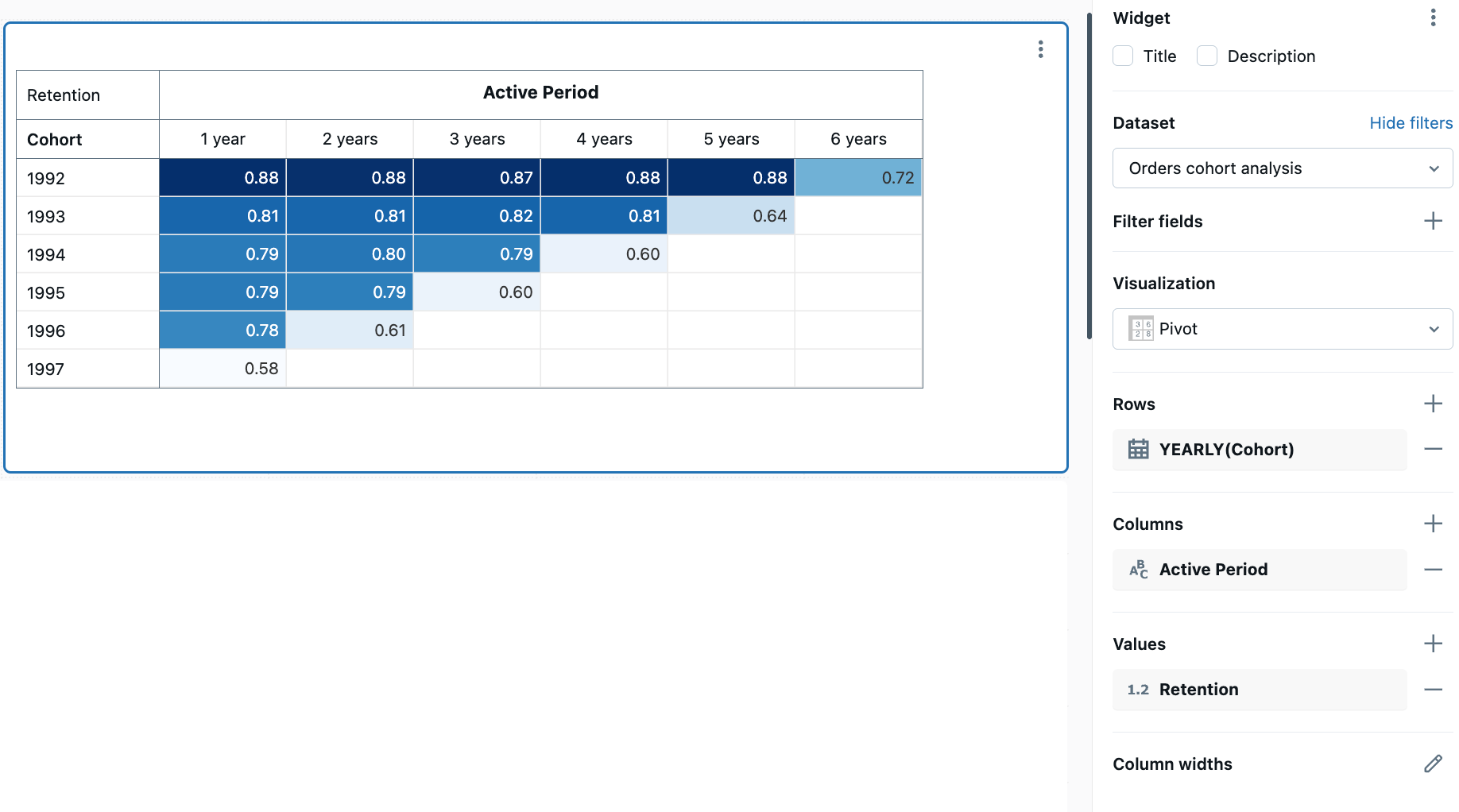
Para criar um gráfico de coorte, utilize uma visualização de tabela dinâmica com dados de retenção. O exemplo a seguir rastreia a retenção de clientes calculando quando os clientes fizeram o primeiro pedido (a data da coorte) e medindo quantos clientes de cada coorte permanecem ativos nos anos subsequentes. A escala de cores indica as taxas de retenção, sendo que cores mais escuras indicam maior retenção.
Valores de configuração : Para este exemplo de gráfico de coorte, os seguintes valores foram definidos:
-
conjunto de dados: samples.tpch.orders
-
Visualização: Pivô
-
Título:
Customer retention by cohort year -
Linhas:
- Campo:
Cohort - Transformar:
Yearly
- Campo:
-
Colunas:
- Campo:
Active Period
- Campo:
-
Célula:
- Campo:
Retention - Estilo:
Color Scale
- Campo:
Consulta SQL: Para esta visualização de gráfico de coorte, a seguinte consulta SQL foi usada para gerar o dataset.Orders cohort analysis
-- get the list of customers and when they were active
WITH history AS (
SELECT o_orderdate, o_custkey -- replace with the right columns representing date and id
FROM samples.tpch.orders -- replace with desired table
GROUP BY ALL
),
-- find the date of the first order for each customer
cohort AS (
SELECT o_custkey, MIN(o_orderdate) AS first_date
FROM history
GROUP BY 1
),
-- combine the customer activity table with the date of first activity, and choose a granularity (e.g. YEAR)
joined AS (
SELECT
DATE_TRUNC("YEAR", first_date) AS cohort,
CAST(DATE_DIFF(YEAR, cohort, o_orderdate) AS STRING) AS active,
o_custkey
FROM history LEFT JOIN cohort USING(o_custkey)
),
-- calculate the number of distinct customers by cohort and date active
grouped AS (
SELECT cohort, active, COUNT(DISTINCT o_custkey) AS customers
FROM joined
GROUP BY 1, 2
),
-- calculate the number of initial customers for each cohort
initial_customers AS (
SELECT cohort, customers AS t0_customers
FROM grouped
WHERE active = 0
)
-- calculate the retention by cohort and date active
SELECT
cohort AS Cohort,
active AS Active,
CASE WHEN active = 1 THEN CONCAT(active, " year")
ELSE CONCAT(active, " years") END AS `Active Period`,
customers AS Customers,
t0_customers AS `Initial Customers`,
TRY_DIVIDE(customers, t0_customers) AS Retention
FROM grouped LEFT JOIN initial_customers USING (cohort)
WHERE active > 0;
Tabela combinada
Os gráficos combinados unem gráficos de linhas e de barras para apresentar as mudanças ao longo do tempo de forma proporcional.
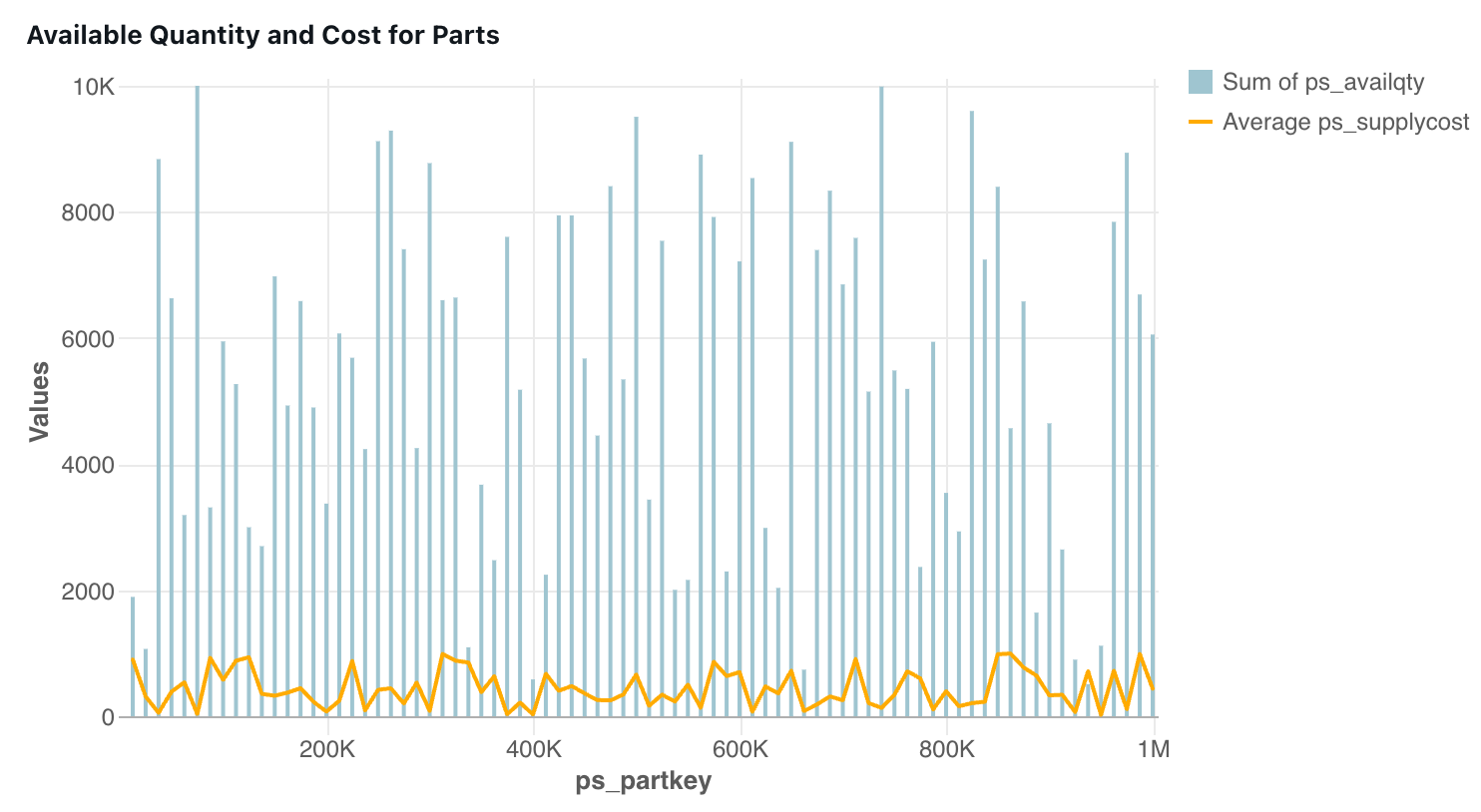
Valores de configuração : Para esta visualização de gráfico combinado, os seguintes valores foram definidos:
-
conjunto de dados: samples.tpch.partsupp
-
Visualização: Combinação
-
Eixo X:
ps_partkey- Tipo de escala:
Continuous
- Tipo de escala:
-
Eixo Y
- Bar:
ps_availqty - Tipo de agregação:
SUM - Linha:
ps_supplycost - Tipo de agregação:
AVG
- Bar:
-
Cor por Série Y:
Sum of ps_availqtyAverage ps_supplycost
Consulta SQL: Para esta visualização de gráfico combinado, a seguinte consulta SQL foi usada para gerar o dataset.
SELECT * FROM samples.tpch.partsupp;
Gráfico combinado de eixo duplo
Você pode usar gráficos combinados para exibir dois eixos y diferentes. Com o widget de gráfico combinado selecionado, clique em ![]() Menu kebab nas configurações do eixo Y no painel de configuração do gráfico. Ative a opção " Habilitar eixo duplo" .
Menu kebab nas configurações do eixo Y no painel de configuração do gráfico. Ative a opção " Habilitar eixo duplo" .
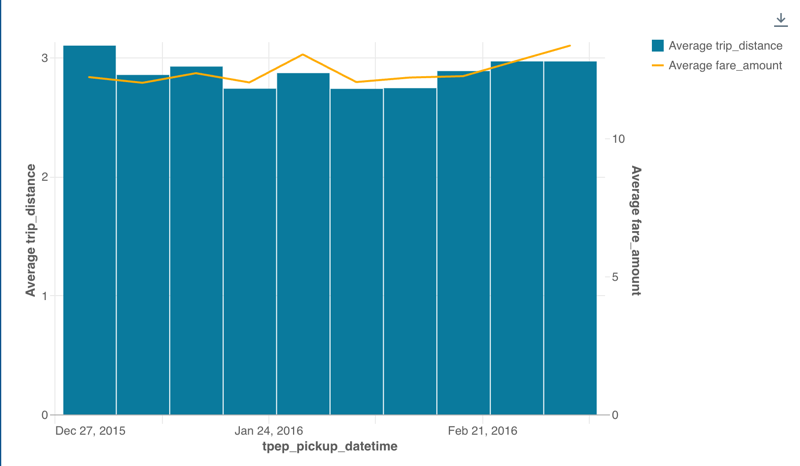
Valores de configuração : Para este gráfico combinado, a opção Ativar eixo duplo está ativada. As demais configurações são definidas da seguinte forma:
-
conjunto de dados: samples.nyctaxi.trips
-
Visualização: Combinação
-
Eixo X:
tpep_pickup_datetime- Transformar:
Weekly - Tipo de escala:
Continuous
- Transformar:
-
Eixo Y
-
Eixo Y esquerdo (Barra):
trip_distance- Transformar:
AVG
- Transformar:
-
Eixo Y direito (Linha):
fare_amount- Transformar:
AVG
- Transformar:
-
Colorir por série Y:
Average trip_distanceAverage fare_amount
Query SQL : A seguinte query SQL foi usada para gerar o dataset:
SELECT * FROM samples.nyctaxi.trips;
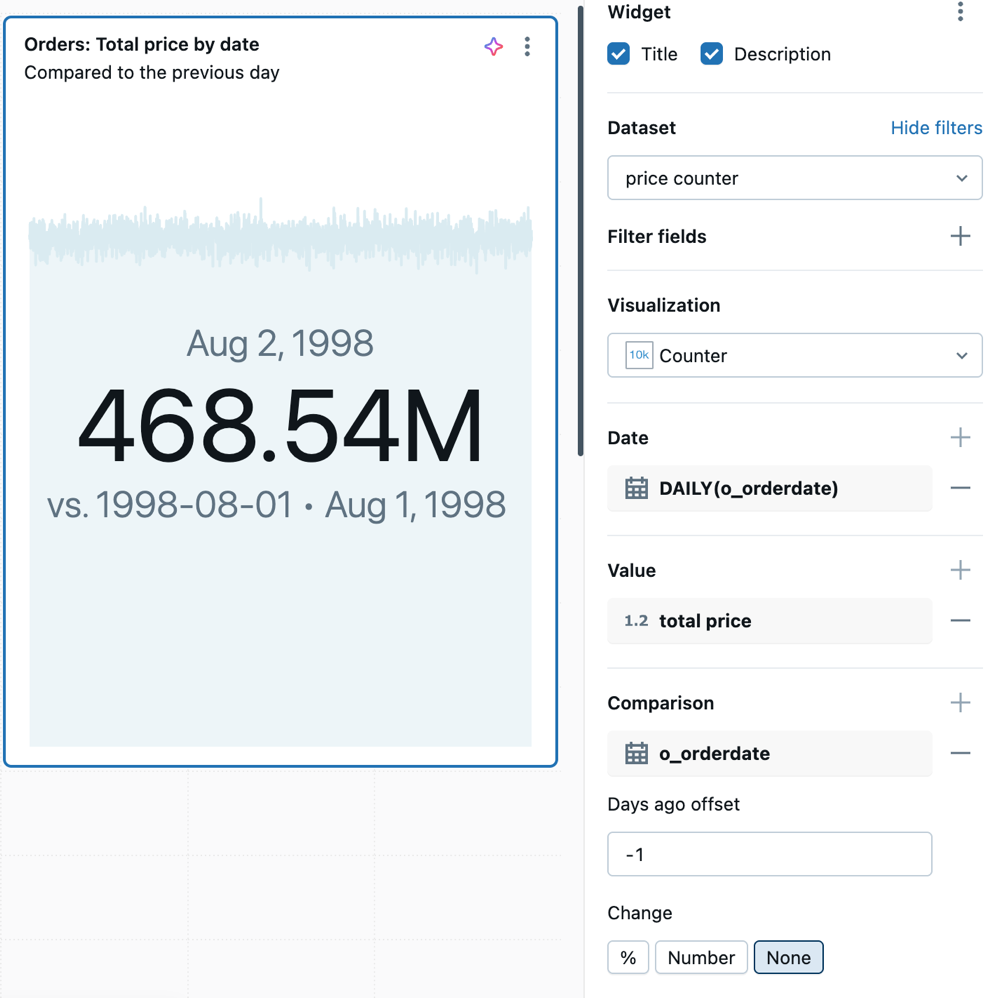
Visualização do contador
Os contadores exibem um único valor de forma destacada, com a opção de compará-lo com um valor de referência. Para usar contadores, especifique quais dados exibir na visualização do contador para as colunas Valor e Comparação . Opcionalmente, escolha uma coluna de data e uma agregação para exibir um gráfico de linhas no gráfico.
Você pode definir a formatação condicional e personalizar o estilo do texto nos detalhes de configuração do valor .
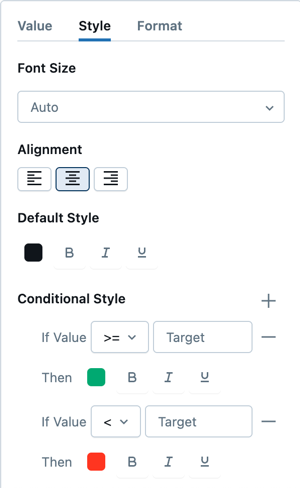
Formato
Para adicionar um prefixo ou sufixo personalizado em torno de um valor de contador, habilite o Formato padrão nos detalhes de configuração do valor . Use a sintaxe {{ }} para referenciar valores no padrão:
{{ @ }}— o valor bruto do contador{{ @formatted }}— o valor formatado do contador, com qualquer formatação numérica aplicada.{{ FieldName }}— qualquer outro campo dataset , como{{ Region }}ou{{ SUM(Profit) }}
Valores de configuração : Para este exemplo de visualização de contador, os seguintes valores foram definidos:
-
conjunto de dados:
samples.tpch.orders -
Visualização: Contador
-
Título:
Orders: Total price by date (compared to the previous day) -
Valor:
- Data:
DAILY(o_orderdate) - Valor:
total price
- Data:
-
Comparação:
- Campo:
o_orderdate - Deslocamento de dias atrás: -1
- Campo:
ConsultaSQL : Para esta visualização de contador, a seguinte consulta SQL foi usada para gerar o dataset:
SELECT
SUM(o_totalprice) AS `total price`,
o_orderdate
FROM
samples.tpch.orders
GROUP BY o_orderdate
ORDER BY o_orderdate DESC;
Visualização personalizada
Visualização
Esse recurso está em Prévia Pública.
Visualizações personalizadas permitem criar gráficos com a biblioteca Vega-Lite quando for necessário um tipo de gráfico ou personalização além das opções integradas. Selecione **Visualização Personalizada** na seção de visualização **Avançada**. Para obter mais informações, consulte Visualizações personalizadas em dashboards de AI/BI.
gráfico de funil
O gráfico funnel ajuda a analisar a mudança em uma medida em diferentes estágios. Para usar o funnel, especifique uma coluna step e uma coluna value .
Por exemplo, o gráfico funnel a seguir mostra como os usuários progridem pelas etapas de um fluxo de inscrição. Cada etapa representa um passo no processo, sendo seu tamanho proporcional ao número de usuários que alcançaram esse passo.

Valores de configuração : Para este gráfico funnel , os seguintes valores foram definidos:
-
Conjunto de dados: Estágios do funil de engajamento do usuário
-
Visualização: funil
-
Eixo X:
stage -
Eixo Y:
count- Tipo de agregação:
SUM
- Tipo de agregação:
-
Coluna de cores:
- Coluna do conjunto de dados:
count
- Coluna do conjunto de dados:
Consulta SQL : A seguinte consulta SQL gerou o dataset para esta visualização de gráfico de funil.
SELECT *
FROM VALUES
('Visited Website', 10000),
('Signed Up', 4000),
('Activated Account', 2500),
('Added First Item', 1500),
('Completed Purchase', 800)
AS funnel(stage, count);
Gráfico de Gantt
Gráficos de Gantt exibem dados como barras horizontais em um eixo contínuo, codificando o início, o fim e a duração de cada item rapidamente. Utilize-os para visualizar programações de projeto, fluxos de trabalho de produção e outros eventos que abrangem um período de tempo.
Cada barra se estende de um valor inicial a um valor final no eixo X. Os campos de início e fim devem ser do mesmo tipo: data, data/hora ou numérico.
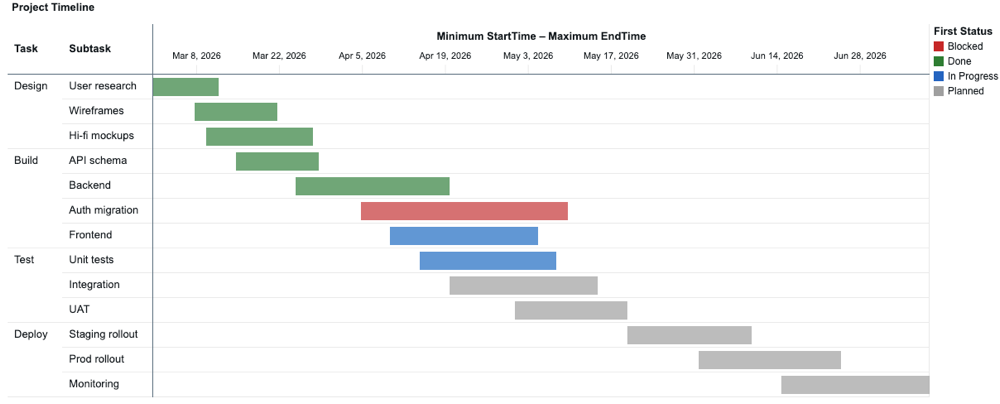
Valores de configuração : O exemplo de gráfico de Gantt a seguir usa estes valores.
-
Dataset: Tarefas do Projeto
-
Visualização: Gantt
-
Linhas:
TaskSubtask
-
Intervalo:
- começar:
MIN(StartTime) - Término:
MAX(EndTime)
- começar:
-
Cor:
- Campo:
FIRST(Status)
- Campo:
Consulta SQL : a seguinte consulta SQL gera o dataset nomeado Project Tasks para esta visualização de gráfico de Gantt.
SELECT * FROM VALUES
('Build', 'API schema', DATE'2026-03-15', DATE'2026-03-29', 'Done'),
('Build', 'Auth migration', DATE'2026-04-05', DATE'2026-05-10', 'Blocked'),
('Build', 'Backend', DATE'2026-03-25', DATE'2026-04-20', 'Done'),
('Build', 'Frontend', DATE'2026-04-10', DATE'2026-05-05', 'In Progress'),
('Deploy', 'Monitoring', DATE'2026-06-15', DATE'2026-07-10', 'Planned'),
('Deploy', 'Prod rollout', DATE'2026-06-01', DATE'2026-06-25', 'Planned'),
('Deploy', 'Staging rollout', DATE'2026-05-20', DATE'2026-06-10', 'Planned'),
('Design', 'Hi-fi mockups', DATE'2026-03-10', DATE'2026-03-28', 'Done'),
('Design', 'User research', DATE'2026-03-01', DATE'2026-03-12', 'Done'),
('Design', 'Wireframes', DATE'2026-03-08', DATE'2026-03-22', 'Done'),
('Test', 'Integration', DATE'2026-04-20', DATE'2026-05-15', 'Planned'),
('Test', 'UAT', DATE'2026-05-01', DATE'2026-05-20', 'Planned'),
('Test', 'Unit tests', DATE'2026-04-15', DATE'2026-05-08', 'In Progress')
AS tasks(Task, Subtask, StartTime, EndTime, Status);
Mapa de calor
Os gráficos de mapa de calor combinam recursos de gráficos de barras, gráficos empilhados e gráficos de bolhas, permitindo visualizar cores numéricas.
Por exemplo, o mapa de calor a seguir visualiza a quantidade de pedidos com base em sua prioridade e método de envio. O eixo x representa as diferentes prioridades de pedidos, enquanto o eixo y representa os vários métodos de envio. A intensidade da cor indica a soma da contagem de pedidos, com uma legenda mostrando a escala de contagem de pedidos.
Os mapas de calor podem exibir até 64 mil linhas ou 10 MB.

Valores de configuração : Para esta visualização de mapa de calor, os seguintes valores foram definidos:
-
conjunto de dados: samples.tpch.orders
-
Visualização: Mapa de calor
-
Eixo X:
priority -
Eixo Y:
ship_mode -
Coluna de cores:
- Coluna do conjunto de dados:
order_count - Tipo de agregação:
SUM
- Coluna do conjunto de dados:
-
Nome do eixo X (substituir valor default ):
Order Priority -
Nome do eixo Y (substituir valor default ):
Shipping method -
Rampa de cores:
Green Blue
Consulta SQL: Para esta visualização de gráfico de mapa de calor, a seguinte consulta SQL foi usada para gerar o dataset.
SELECT
o.o_orderpriority AS priority,
l.l_shipmode AS ship_mode,
COUNT(*) AS order_count,
o.o_orderdate
FROM
samples.tpch.orders AS o
JOIN
samples.tpch.lineitem AS l
ON
o.o_orderkey = l.l_orderkey
GROUP BY
o.o_orderpriority,
l.l_shipmode,
o.o_orderdate
ORDER BY
priority,
ship_mode;
Gráfico de histograma
Um histograma representa graficamente a frequência com que um determinado valor ocorre em um dataset. Um histograma ajuda a entender se um dataset possui valores agrupados em torno de um pequeno número de intervalos ou se estão mais dispersos. Um histograma é exibido como um gráfico de barras no qual você controla o número de barras distintas (também chamadas de intervalos).
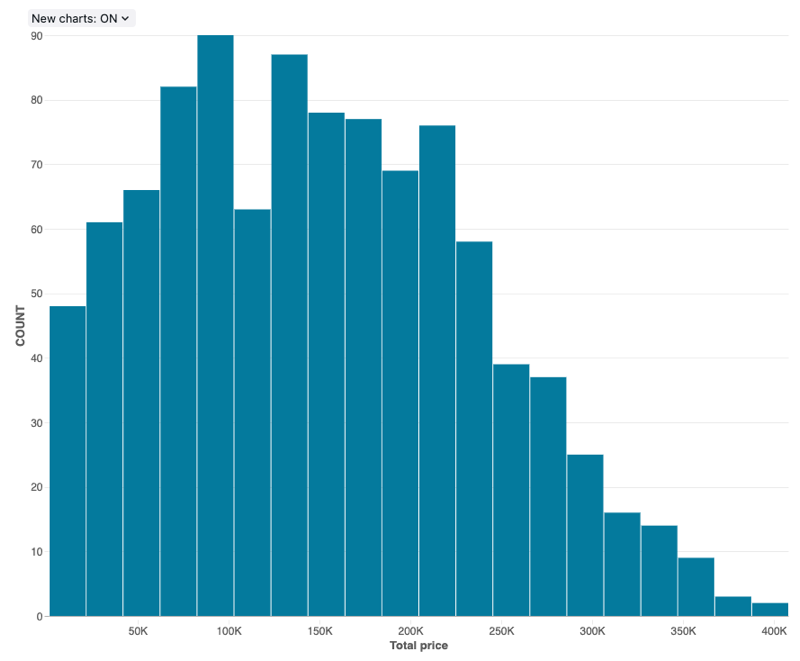
Valores de configuração : Para esta visualização de histograma, os seguintes valores foram definidos:
- conjunto de dados: samples.tpch.orders
- Visualização: Histograma
- Coluna X (coluna dataset ):
o_totalprice - Número de recipientes: 20
- Nome do eixo X (substituir valor default ):
Total price
Opções de configuração : Para opções de configuração do gráfico de histograma, consulte Opções de configuração do gráfico de histograma.
Consulta SQL : Para esta visualização de gráfico de histograma, a seguinte consulta SQL foi usada para gerar o dataset.
SELECT * FROM samples.tpch.orders;
Visualização de linhas
As visualizações de linha apresentam a variação de uma ou mais métricas ao longo do tempo.
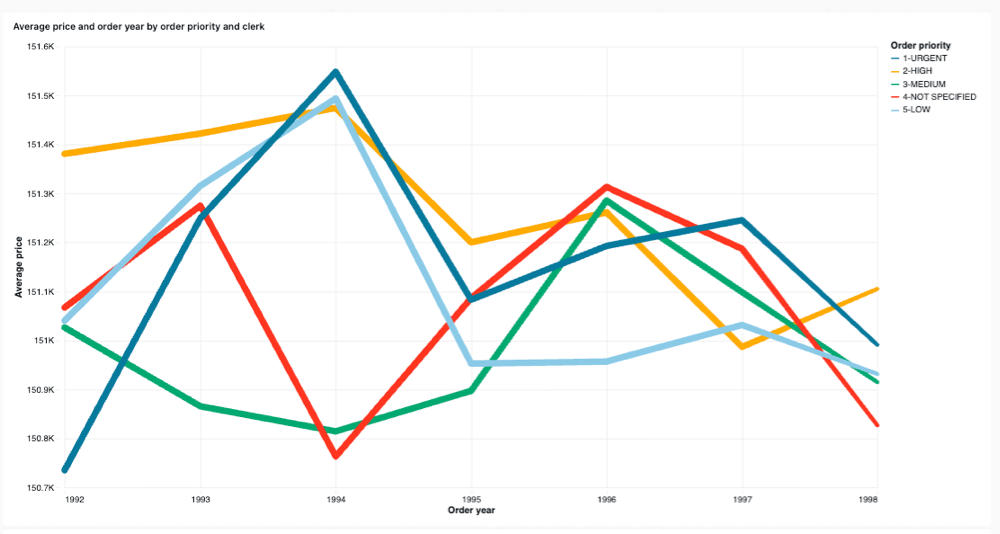
Valores de configuração : Para este exemplo de visualização de linha, os seguintes valores foram definidos:
-
conjunto de dados: samples.tpch.orders
-
Visualização: Linha
-
Título:
Average price and order year by order priority and clerk -
Eixo X:
- Campo:
o_orderdate - Tipo de escala:
Continuous - Transformar:
Yearly - Nome de exibição:
Order year
- Campo:
-
Eixo Y
- Campo:
o_totalprice - Tipo de escala:
Continuous - Transformar:
Average - Nome de exibição:
Average price
- Campo:
-
Cor:
- Campo:
o_orderpriority - Título da legenda:
Order priority
- Campo:
Consulta SQL: Para esta visualização de gráfico de linhas, a seguinte consulta SQL foi usada para gerar o dataset Orders data denominado.
SELECT * FROM samples.tpch.orders;
visualização de pizza
As visualizações em forma de pizza mostram a proporcionalidade entre as métricas. Eles não são destinados à transmissão de dados de séries temporais.
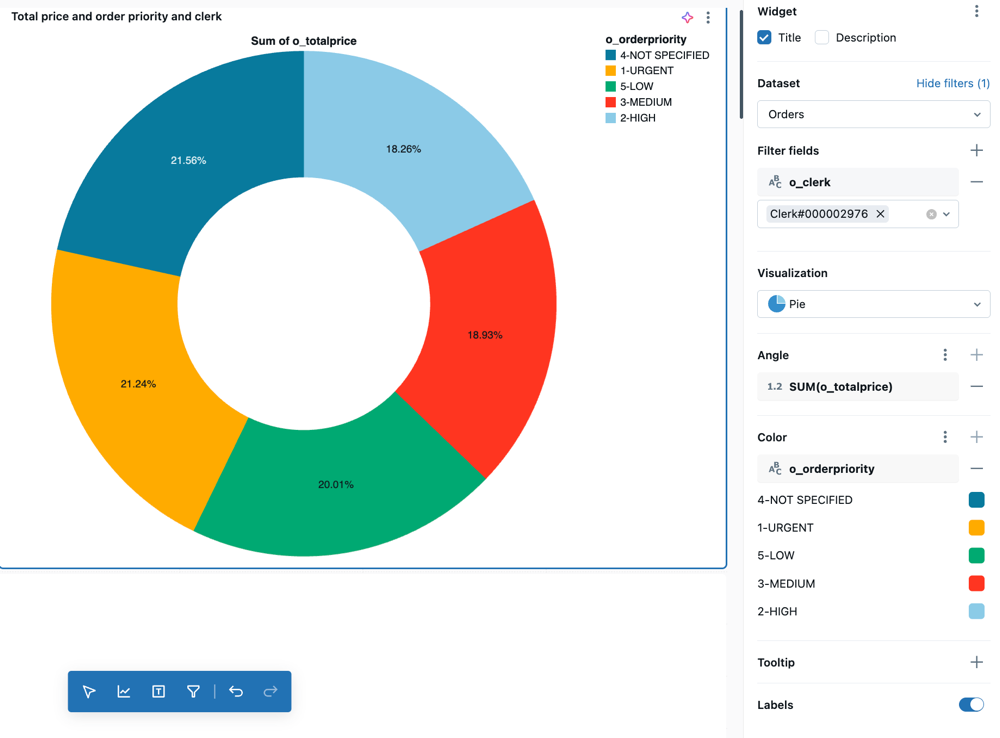
Valores de configuração : Para este exemplo de visualização de gráfico pie , os seguintes valores foram definidos:
-
conjunto de dados: samples.tpch.orders
-
Visualização: visualização em forma de pizza
-
Título:
Total price by order priority and clerk -
Ângulo:
- Campo:
o_totalprice - Transformar:
Sum - Nome de exibição:
Total price
- Campo:
-
Cor:
- Campo:
o_orderpriority - Título da legenda:
Order priority
- Campo:
-
Filtrar
- Campo:
TPCH orders.o_clerk
- Campo:
Consulta SQL: Para esta visualização de pie, a seguinte consulta SQL foi usada para gerar o dataset TPCH orders nomeado.
SELECT * FROM samples.tpch.orders;
Visualização de pivô
Uma visualização de tabela dinâmica agrega registros de um resultado de consulta em uma exibição tabular. É semelhante às instruções PIVOT ou GROUP BY em SQL. Você configura a visualização da tabela dinâmica com campos de arrastar e soltar.
Para obter informações detalhadas sobre as opções de configuração da tabela dinâmica, incluindo cabeçalhos fixos, formatação condicional e adição de links, consulte Configuração da tabela dinâmica.
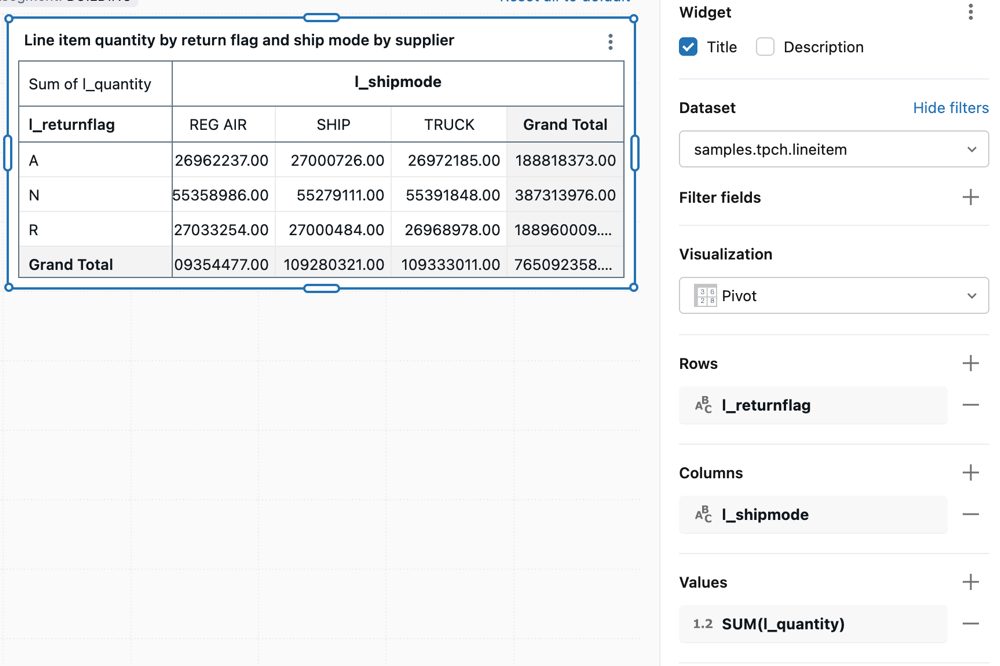
Valores de configuração : Para este exemplo de visualização de tabela dinâmica, os seguintes valores foram definidos:
-
conjunto de dados: samples.tpch.lineitem
-
Visualização: Pivô
-
Título:
Line item quantity by return flag and ship mode by supplier -
Linhas:
- Campo:
l_returnflag - Exibir total: Verificado
- Campo:
-
Colunas:
- Campo:
l_shipmode - Exibir total: Verificado
- Campo:
-
Valores
- Campo:
l_quantity - Transformar: Soma
- Campo:
Consulta SQL : Para esta visualização dinâmica, a seguinte consulta SQL foi utilizada para gerar o dataset nomeado TPCH lineitem.
SELECT * FROM samples.tpch.lineitem;
Mapa de pontos
Mapas de pontos exibem dados quantitativos como símbolos colocados em locais específicos no mapa. Marcadores são posicionados usando coordenadas de latitude e longitude, que devem ser incluídas como parte do conjunto de resultados para este tipo de gráfico.
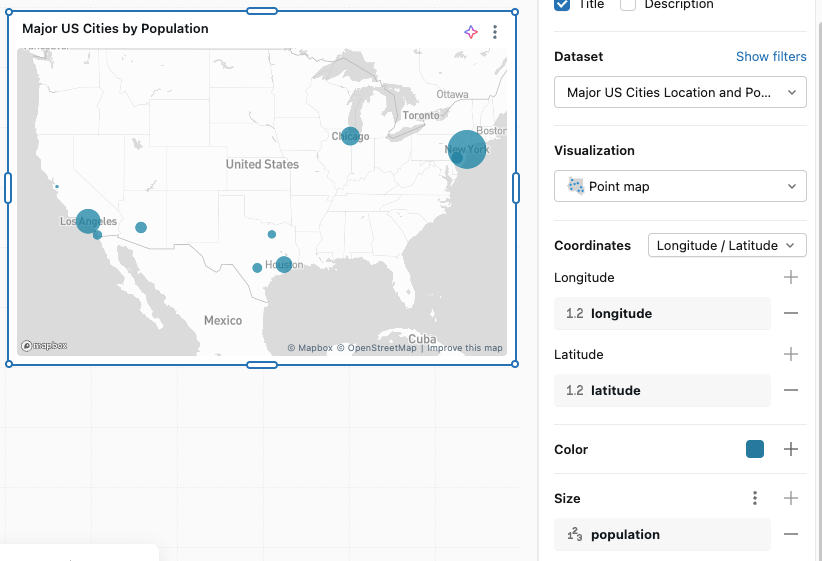
Para um exemplo de configuração e opções de mapa de pontos, consulte Opções de mapa de pontos.
Diagrama de Sankey
Um diagrama de Sankey visualiza o fluxo de um conjunto de valores para outro.
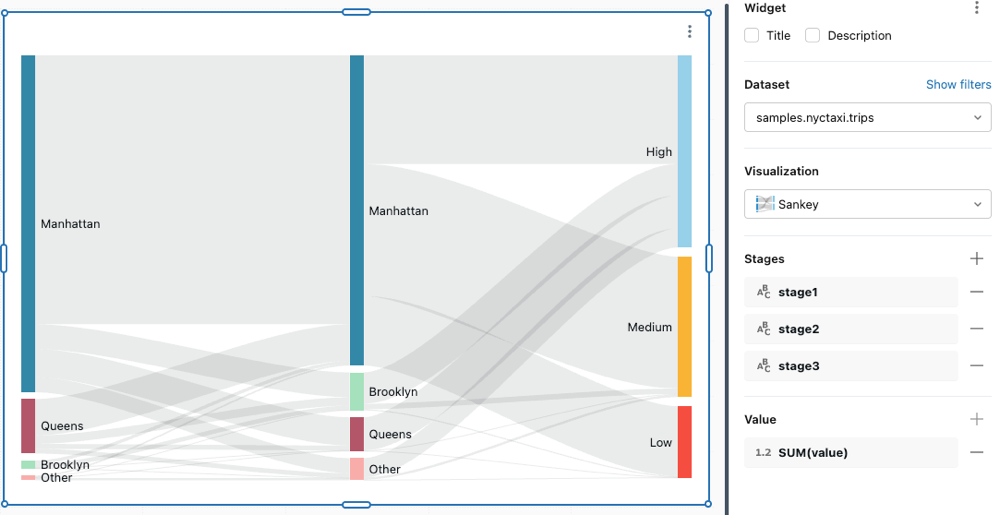
Valores de configuração : Para este diagrama de Sankey, os seguintes valores foram definidos:
-
conjunto de dados: samples.nyctaxi.trips
-
Visualização: Sankey
-
Etapas
stage1stage2stage3
-
Valor
- SOMA(valor)
Consulta SQL : para esta visualização Sankey, a seguinte consulta SQL foi usada para gerar o dataset.
SELECT
CASE
WHEN pickup_zip BETWEEN 10000 AND 10299 THEN 'Manhattan'
WHEN pickup_zip BETWEEN 11200 AND 11299 THEN 'Brooklyn'
WHEN pickup_zip BETWEEN 11300 AND 11499 THEN 'Queens'
ELSE 'Other'
END AS stage1,
CASE
WHEN dropoff_zip BETWEEN 10000 AND 10299 THEN 'Manhattan'
WHEN dropoff_zip BETWEEN 11200 AND 11299 THEN 'Brooklyn'
WHEN dropoff_zip BETWEEN 11300 AND 11499 THEN 'Queens'
ELSE 'Other'
END AS stage2,
CASE
WHEN fare_amount < 8 THEN 'Low'
WHEN fare_amount <= 15 THEN 'Medium'
ELSE 'High'
END AS stage3,
SUM(fare_amount) AS value
FROM samples.nyctaxi.trips
GROUP BY 1, 2, 3
ORDER BY value DESC
LIMIT 50;
Visualização de dispersão
Os gráficos de dispersão são comumente usados para mostrar a relação entre duas variáveis numéricas. Você pode codificar a terceira dimensão com cores para mostrar como as variáveis numéricas diferem entre os grupos.
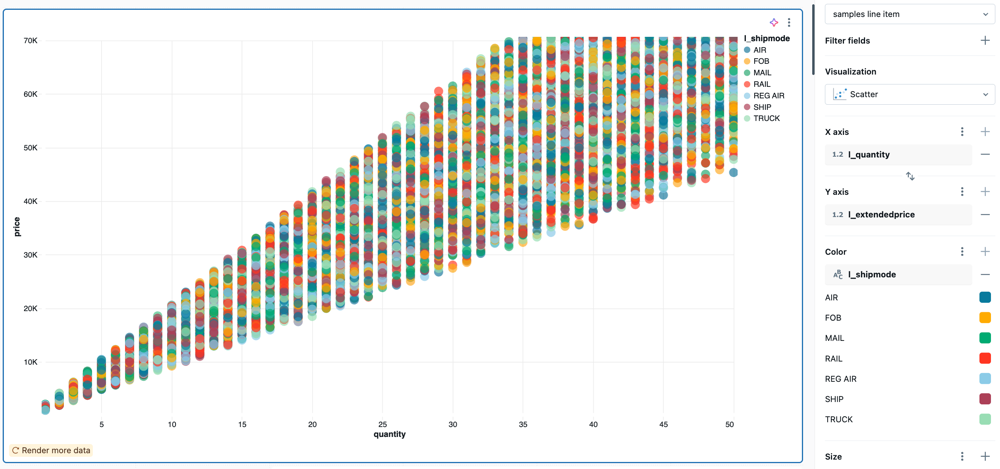
Valores de configuração : Para este exemplo de visualização de dispersão, os seguintes valores foram definidos:
-
conjunto de dados: samples.tpch.lineitem
-
Visualização: Dispersão
-
Título:
Total price and quantity by ship mode and supplier -
Eixo X:
- Campo:
l_quantity - Nome de exibição:
Quantity - Tipo de escala:
Continuous - Transformar:
None
- Campo:
-
Eixo Y
- Campo:
l_extendedprice - Tipo de escala:
Continuous - Transformar:
None - Nome de exibição:
Price
- Campo:
-
Cor:
- Campo:
l_shipmode - Título da legenda:
Ship mode
- Campo:
-
Filtrar
- Campo:
TPCH lineitem.l_supplierkey
- Campo:
Consulta SQL: Para esta visualização de dispersão, a seguinte consulta SQL foi usada para gerar o dataset TPCH lineitem chamado.
SELECT * FROM samples.tpch.lineitem
Visualização em tabela
A visualização em tabela exibe os dados em uma tabela padrão, mas permite reordenar, ocultar e formatar os dados manualmente.
As tabelas podem exibir até 64 mil linhas ou 10 MB.
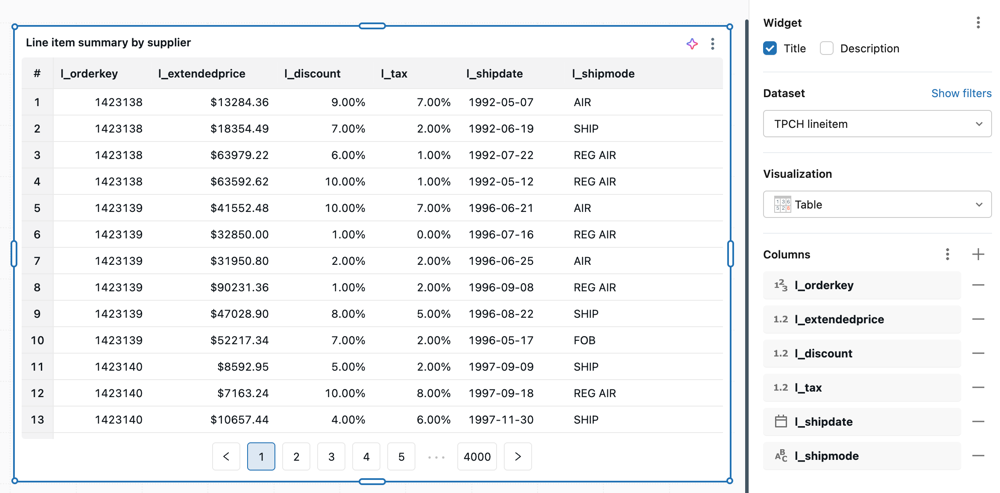
Valores de configuração : Para este exemplo de visualização de tabela, os seguintes valores foram definidos:
-
conjunto de dados: samples.tpch.lineitem
-
Visualização: Tabela
-
Título:
Line item summary by supplier -
Colunas:
-
Exibir número da linha: Ativado
-
Campo:
l_orderkey -
Campo:
l_extendedprice- Formato: Personalizado
- Tipo:
$(Moeda)
-
Campo:
l_discount- Formato: Personalizado
- Tipo:
%(Porcentagem)
-
Campo:
l_tax- Formato: Personalizado
- Tipo:
%(Porcentagem)
-
Campo:
l_shipdate -
Campo:
l_shipmode
-
-
Filtrar
- Campo:
TPCH lineitem.l_supplierkey
- Campo:
Opções de configuração : Para opções de configuração de visualização de tabela, consulte Visualizações de tabela e tabela dinâmica.
Consulta SQL: Para esta visualização de tabela, a seguinte consulta SQL foi usada para gerar o dataset TPCH lineitem nomeado.
SELECT * FROM samples.tpch.lineitem
Gráfico de cachoeira
Os gráficos de cascata exibem o efeito cumulativo de valores positivos e negativos sequenciais, mostrando como um valor inicial é afetado por uma série de valores intermediários positivos e negativos. São comumente utilizadas para visualizar dados financeiros, como demonstrações de resultados, ou para mostrar como diferentes fatores contribuem para uma mudança total.
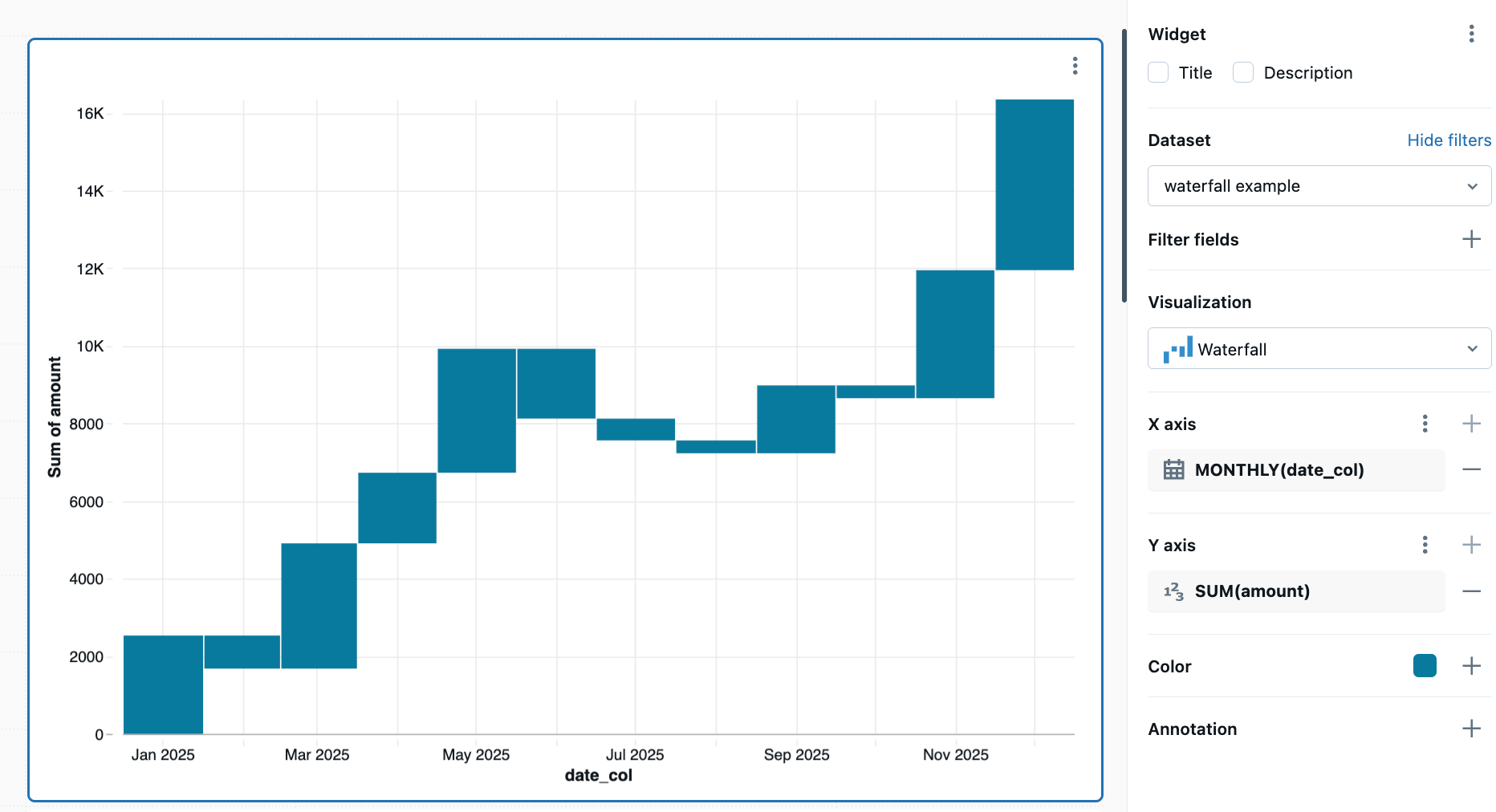
Valores de configuração : Para este exemplo de gráfico em cascata, os seguintes valores foram definidos:
- Conjunto de dados: Gerado por consulta
- Visualização: Cascata
- Eixo X: MENSAL(data_col)
- Eixo Y: SOMA(quantidade)
Consulta SQL : Para esta visualização de tabela, a seguinte consulta SQL foi usada para gerar o dataset.
with base as (
SELECT
*
FROM
VALUES
(2535, '2025-01-01'),
(-853, '2025-02-01'),
(3229, '2025-03-01'),
(1820, '2025-04-01'),
(3195, '2025-05-01'),
(-1800, '2025-06-01'),
(-562, '2025-07-01'),
(-332, '2025-08-01'),
(1750, '2025-09-01'),
(-330, '2025-10-01'),
(3300, '2025-11-01'),
(4400, '2025-12-01') AS t (amount, date_str)
)
SELECT
amount,
cast(date_str as date) as date_col
from
base