Arquitetura fan-in e fan-out em LakeFlow Pipelines
Fan-in e fan-out são padrões comuns para a criação de pipelines de dados escaláveis e confiáveis. Esta página explica ambos e mostra como implementá-los em Lakeflow pipelines.
O que são fan-in e fan-out?
Fan-in é um padrão arquitetural onde dados de múltiplas fontes são ingeridos e processados em um único pipeline.
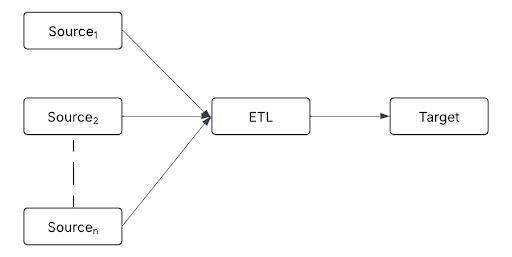
As fontes podem incluir:
- transmissão de evento tempo real (por exemplo, Kafka e Kinesis)
- armazenamento em nuvem (por exemplo, S3, ADLS e Google Cloud Storage)
- Bancos de dados relacionais (por exemplo, PostgreSQL, MySQL e Snowflake)
- Dispositivos IoT (por exemplo, sensores, logs e APIs)
Ao consolidar diversas transmissões de dados em uma única camada de processamento, o fan-in permite transformações consistentes, desduplicação e enriquecimento de dados antes que os dados sejam movidos para baixo.
O Fan-out segue uma abordagem de um para muitos, encaminhando uma única transmissão de dados processados para vários destinos.
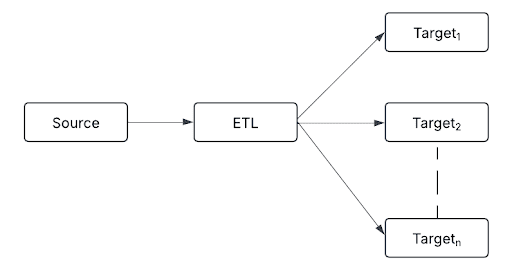
Os destinos podem incluir:
- Tabelas Delta para armazenamento estruturado
- tempo real sistemas de alerta para detecção de anomalia
- modelo de aprendizado de máquina para análise preditiva
- data warehouse para relatórios e análises
- Filas de mensagens para comunicação assíncrona e processamento desacoplado.
Esse padrão garante que cada sistema subsequente receba os dados no formato necessário, permitindo que as organizações integrem os dados de transmissão em diversos aplicativos de negócios.
Na prática, os pipelines frequentemente combinam ambos os padrões. Por exemplo:
- Uma empresa coleta dados de atividade do usuário de vários aplicativos, sites e dispositivos móveis (fan-in).
- Os dados processados são armazenados no Delta Lake para análise histórica, enquanto o Tempo Real Alert dispara alertas para atividades incomuns (expansão).
Implemente fan-in com fluxos de anexação
O pipeline Fan-in merge múltiplas transmissões de dados em um destino unificado. Tradicionalmente, isso requer consultas de união complexas e pontos de verificação manuais. Os fluxos de anexação simplificam isso, permitindo que várias transmissões de dados alimentem diretamente uma única tabela de transmissão sem uniões explícitas ou lógica complexa. Cada fonte é gerenciada de forma independente, permitindo a ingestão incremental de dados e atualizações.
Por exemplo, use fluxos de acréscimo para consolidar vários tópicos Kafka ou transmissões de dados regionais em uma tabela de destino unificada.
- Python
- SQL
from pyspark import pipelines as dp
dp.create_streaming_table("all_topics")
# Kafka stream from topic1
@dp.append_flow(target="all_topics")
def topic1():
return spark.readStream.format("kafka") \
.option("kafka.bootstrap.servers", "host1:port1,...") \
.option("subscribe", "topic1") \
.load()
# Kafka stream from topic2
@dp.append_flow(target="all_topics")
def topic2():
return spark.readStream.format("kafka") \
.option("kafka.bootstrap.servers", "host1:port1,...") \
.option("subscribe", "topic2") \
.load()
CREATE OR REFRESH STREAMING TABLE all_topics;
CREATE FLOW
topic1
AS INSERT INTO
all_topics BY NAME
SELECT * FROM
read_kafka(bootstrapServers => 'host1:port1,...', subscribe => 'topic1');
CREATE FLOW
topic2
AS INSERT INTO
all_topics BY NAME
SELECT * FROM
read_kafka(bootstrapServers => 'host1:port1,...', subscribe => 'topic2');
Implementar fan-out
Pipelines fan-out distribuem dados de uma fonte para múltiplas saídas. LakeFlow Pipelines oferecem suporte a três abordagens dependendo do seu caso de uso.
Use laços `for` para lógica generalizada.
Se a sua lógica ETL for idêntica em vários destinos, use loops `for` em Python para gerar dinamicamente várias tabelas por meio de loops parametrizados. Isso evita a codificação repetitiva e simplifica o escalonamento do pipeline por meio da configuração.
Cada fluxo ou tabela gerado processa o dataset de origem inteiro independentemente. Para fontes com taxa de transferência compartilhada ou limites de capacidade de leitura, como o Kafka, isso pode impactar significativamente o desempenho. É importante avaliar a abordagem cuidadosamente para tais fontes antes de seu uso.
regions = ["US", "EU", "APAC"]
for region in regions:
@dp.materialized_view(name=f"orders_{region.lower()}_filtered")
def filtered_orders(region_filter=region):
return spark.read.table("combined_orders").filter(f"region = '{region_filter}'")
Utilize fluxos independentes para lógica específica de destino.
Quando as transformações ETL variam significativamente de acordo com o destino, implemente fluxos de dados independentes. Essa abordagem oferece controle preciso e desempenho otimizado, adaptado a cada caso de uso.
from pyspark import pipelines as dp
# Grouped output
@dp.materialized_view(name="orders_sink")
def region_orders():
df = spark.read.table("combined_orders").groupBy("region").count()
# Add additional logic here
return df
# BI materialized view
@dp.materialized_view(name="orders_bi_materialized")
def orders_bi():
return spark.read.table("combined_orders").select("order_id", "amount", "region")
# ML feature table
@dp.materialized_view(name="orders_ml_features")
def orders_ml():
return (
spark.read.table("combined_orders")
.withColumn("high_value_order", col("amount") > 1000)
.select("order_id", "high_value_order", "region")
)
Use ForEachBatch para roteamento personalizado.
Pré-visualização pública
foreach_batch_sink está disponível em prévia pública no canal de PRÉVIA do LakeFlow Pipelines. Consulte channel em Configurações de pipeline.
O foreach_batch_sink aplica lógica personalizada a cada microlote, permitindo transformação complexa, mesclagem ou roteamento para vários destinos, incluindo aqueles sem suporte de transmissão integrada, como coletores JDBC.
Cada lote executa múltiplas operações de gravação de forma independente. Falhas em uma operação não revertem automaticamente as gravações bem-sucedidas anteriores. Isso pode levar a dados parciais ou inconsistentes entre os destinos, especialmente ao processar fontes compartilhadas como o Kafka. Projete seu pipeline com tratamento cuidadoso de erros e testes completos. Consulte Usar ForEachBatch para gravar em destinos de dados arbitrários no pipeline.
from pyspark import pipelines as dp
@dp.foreach_batch_sink(name="user_events_feb")
def user_events_handler(batch_df, batch_id):
# Write to Delta table
batch_df.write.format("delta").mode("append").saveAsTable("my_catalog.my_schema.my_delta_table")
# Write to JSON files
batch_df.write.format("json").mode("append").save("/Volumes/path/to/json_target")
@dp.append_flow(target="user_events_feb", name="user_events_flow")
def read_user_events():
return (
spark.readStream.format("cloudFiles")
.option("cloudFiles.format", "json")
.load("/data/incoming/events")
)
Padrões comuns de ForEachBatch
O foreach_batch_sink suporta múltiplos padrões. Alguns padrões comuns incluem:
-
Fluxo único para coletor de múltiplos destinos : Um único
append_flowlê de uma fonte de transmissão e encaminha dados para umforeach_batch_sink. O coletor lida com a escrita em múltiplos destinos (por exemplo, Delta, JSON e sistemas externos). Isso é ideal para casos de uso simples com múltiplas saídas e lógica de transformações compartilhada. -
Múltiplos fluxos para um coletor unificado: Múltiplas
append_flowfontes (por exemplo, diferentes diretórios, formatos, tópicos do Kafka ou APIs externas) merge em umforeach_batch_sinkúnico. Isso centraliza a lógica de transformação comum, o gerenciamento de saída e o tratamento de erros. Porque apenas um checkpoint precisa ser mantido, essa abordagem reduz significativamente a complexidade de coordenação. É particularmente útil ao lidar com filas de mensagens, como Kafka ou APIs externas. -
Um fluxo para um destino (muitos pares independentes) : Cada
append_flowtem umforeach_batch_sinkdedicado, estabelecendo relações claras e isoladas entre fontes individuais e seus destinos. Isso é ideal para pipelines com muitas transmissões independentes que exigem lógica de processamento exclusiva, solução de problemas simplificada e tratamento de erros isolado.
Na prática, essas abordagens muitas vezes se complementam. Por exemplo, use loops para gerar vários fluxos de anexação dinamicamente para cenários de fan-in em grande escala e, em seguida, distribua os resultados usando loops ou foreach_batch_sink para fan-out.
Melhores práticas
- Fluxos de acréscimo exigem que os esquemas de origem se alinhem com a tabela de transmissão de destino para evitar erros de processamento. Utilize as expectativas de esquema dos Lakeflow pipelines para detectar e lidar proativamente com exceções, garantindo a consistência do esquema em todo o pipeline.
- Mantenha a lógica do laço `for` bem definida e direta.
- Dê nomes claros a cada fluxo e tabela para manter a legibilidade.
- Monitore a utilização de recursos para escalar de forma eficiente e evitar gargalos de desempenho.
- Ao escrever em filas de mensagens, use um
foreach_batch_sinkcom um únicoappend_flowque consolida todas as transmissões de entrada. Isso simplifica o gerenciamento de estado e de pontos de verificação subsequentes.
Limitações
- A IU de linhagem de LakeFlow Pipelines pode não exibir métricas e metadados de nível de fluxo para novas fontes de fluxo de acréscimo.
- Expandir em vez de reduzir a lista de valores usada em um loop for. Se um dataset previamente definido for omitido em execuções de pipeline subsequentes, ele é automaticamente descartado do esquema de destino, o que causa perda de dados não intencional.