evolução do esquema em Databricks
A evolução do esquema refere-se à capacidade de um sistema se adaptar às mudanças na estrutura dos dados ao longo do tempo. Essas mudanças são comuns ao trabalhar com dados semiestruturados, transmissão de eventos ou fontes de terceiros, onde novos campos são adicionados, os tipos de dados mudam ou as estruturas aninhadas evoluem.
As alterações comuns incluem:
- Novas colunas : Campos adicionais não definidos anteriormente, às vezes com um valor de preenchimento personalizado.
- Renomear coluna : Alterar o nome de uma coluna, por exemplo, de
nameparafull_name. - Colunas removidas : Colunas retiradas do esquema da tabela.
- Ampliação de tipo : Alterar o tipo de uma coluna para um tipo mais amplo. Por exemplo, um campo
INTtornando-seDOUBLE. - Outras alterações de tipo : Alterar o tipo de uma coluna. Por exemplo, um campo
INTtornando-seSTRING.
Apoiar a evolução do esquema é fundamental para construir um pipeline resiliente e de longa duração que possa acomodar dados em constante mudança sem atualizações manuais frequentes.
Componentes
A evolução do esquema do Databricks envolve quatro categorias principais de componentes, cada uma lidando com as alterações de esquema de forma independente:
- Conectores : Componentes que recebem dados de fontes externas. Isso inclui conectores Auto Loader, Kafka, Kinesis e LakeFlow .
- Analisadores de formato : Funções que decodificam formatos brutos, incluindo
from_json,from_avro,from_xmlefrom_protobuf. - Engines : Engines de processamento que executam consultas, inclusive transmissão estructurada.
- Conjunto de dados : tabelas de transmissão, visão materializada, tabelas Delta e visão que persiste e fornece dados.
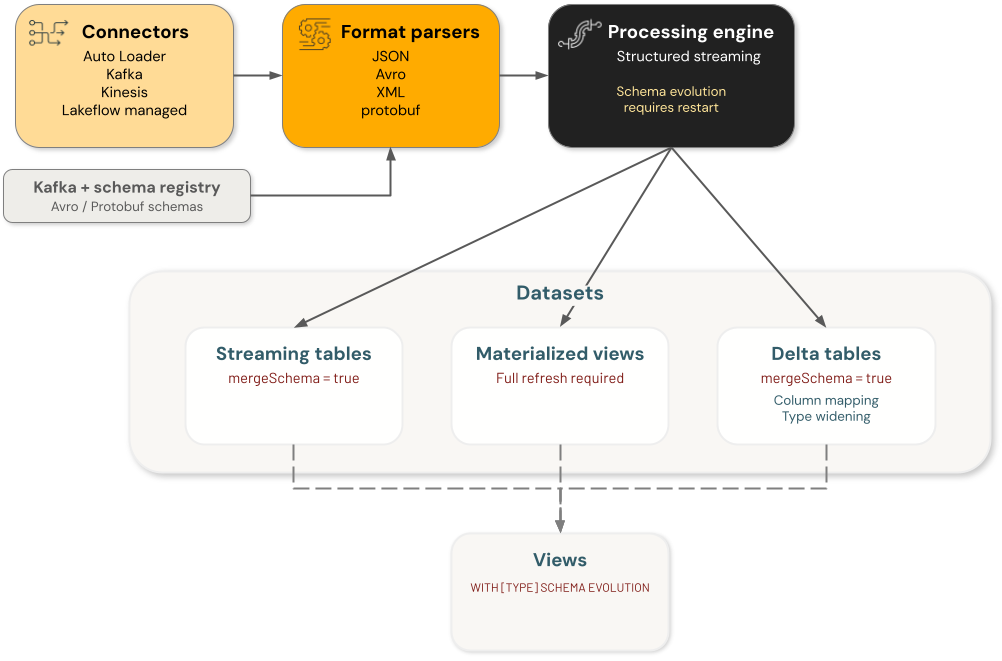
Cada componente na evolução do esquema da arquitetura de engenharia de dados é independente. Você é responsável por configurar a evolução do esquema em componentes individuais para alcançar o comportamento desejado no seu fluxo de processamento de dados.
Por exemplo, ao usar o Auto Loader para ingerir dados em uma tabela Delta, há dois esquemas persistidos: um é gerenciado pelo Auto Loader em seu local de esquema e o outro é o esquema da tabela Delta de destino. Em um estado estável, esses dois são os mesmos. Quando o Auto Loader evolui seu esquema, com base nos dados recebidos, a tabela Delta também deve evoluir seu esquema, ou a consulta falha. Nesse caso, você pode (a) atualizar o esquema da tabela Delta de destino habilitando a evolução do esquema ou usando um comando DDL direto, ou (b) fazer uma reescrita completa da tabela Delta de destino.
Suporte à evolução do esquema por conector
As seções a seguir detalham como cada componente do Databricks lida com diferentes tipos de alterações de esquema.
Auto Loader
O Auto Loader suporta alterações de coluna e ampliação de tipo. Configure a evolução automática do esquema com cloudFiles.schemaEvolutionMode e rescuedDataColumn. Você pode definir manualmente schemaHints ou um imutável schema. Ao evoluir o esquema automaticamente, a transmissão inicialmente falha. Ao reiniciar, o esquema evoluído é utilizado. Veja Como funciona a evolução do esquema do Auto Loader?
- Novas colunas : Suportadas, dependendo do
schemaEvolutionModeselecionado. Ocorreu uma falha e foi necessário reiniciar manualmente para adicionar novas colunas ao esquema. - Renomeação de colunas : Suportada, dependendo do
schemaEvolutionModeselecionado. A coluna renomeada é tratada como uma nova coluna adicionada e a coluna antiga é preenchida comNULLpara novas linhas. A falha requer uma reinicialização manual para atualizar o esquema. - Colunas excluídas : Suportado. Tratadas como exclusões lógicas, onde as novas linhas para a coluna excluída são definidas como
NULL. - Ampliação de tipo : Suportado no Databricks Runtime 16.4 e superior com
schemaEvolutionModedefinido comoaddNewColumnsWithTypeWidening. As alterações nos tipos de dados suportados são ampliadas automaticamente. Alterações de tipo não suportadas são capturadas emrescuedDataColumn. Veja Ampliação automática de tipos com Auto Loader. - Outras alterações de tipo : Não suportadas. As alterações de tipo são capturadas em
rescuedDataColumnserescueDataColumntiver sido definido eschemaEvolutionModedefinido comorescue. Caso contrário, será necessária uma alteração manual do esquema.
Conector Delta
O conector Delta pode suportar a evolução do esquema. Ao ler dados de uma tabela Delta com mapeamento de colunas e schemaTrackingLocation ativados, é possível obter suporte à evolução do esquema para renomeação de colunas e remoção de colunas. Você deve configurar o Spark corretamente para cada uma dessas alterações para que o esquema evolua sem interromper a transmissão. Caso contrário, a transmissão evolui seu esquema rastreado sempre que uma mudança é detectada e, em seguida, para. Em seguida, você deve reiniciar manualmente a consulta de transmissão para retomar o processamento.
- Novas colunas : Suportadas. Com
mergeSchemaativado, novas colunas são adicionadas automaticamente. Caso contrário, a consulta falha e você precisa reiniciar a transmissão para adicionar as novas colunas ao esquema, mas a tabela Delta não requer uma reescrita. - Renomeação de coluna : Suportado. É possível evoluir o esquema em uma consulta de transmissão com a configuração do Spark
spark.databricks.delta.streaming.allowSourceColumnRename. - Colunas removidas: compatível. É possível evoluir o esquema em uma consulta de transmissão com a configuração do Spark
spark.databricks.delta.streaming.allowSourceColumnDrop. - Ampliação de tipo : Compatível no Databricks Runtime 16.4 LTS e acima. Com
mergeSchemahabilitado e ampliação de tipo habilitada na tabela de destino, as alterações de tipo são tratadas automaticamente. Você pode habilitar a ampliação de tipo com a propriedade de tabeladelta.enableTypeWidening. Consulte Ampliação de tipo. - Outras alterações de tipo : Não suportadas.
Conectores SaaS e CDC
Os conectores SaaS e CDC adaptam o esquema automaticamente quando as colunas são alteradas. Isso é resolvido por meio de uma reinicialização automática quando uma alteração é detectada. As alterações de texto exigem uma refresh completa.
- Novas colunas : Suportadas. A consulta é reiniciada automaticamente para resolver a incompatibilidade de esquema.
- Renomeação de colunas : Suportada. A consulta é reiniciada automaticamente para resolver a incompatibilidade de esquema. A coluna renomeada é tratada como uma nova coluna adicionada.
- Colunas excluídas : Suportado. As colunas removidas são tratadas como exclusões lógicas, onde as novas linhas para a coluna excluída são definidas como
NULL. - Ampliação de tipos : Não suportada. A atualização do esquema requer uma refresh completa.
- Outras alterações de tipo : Não suportadas. A atualização do esquema requer uma refresh completa.
Conectores Kinesis, Kafka, Pub/Sub e Pulsar
Nenhuma evolução nativa do esquema é suportada. Cada uma das funções do conector retorna um bloco binário. A evolução do esquema é gerenciada pelo analisador de formato.
- Novas colunas : Gerenciadas pelo analisador de formato.
- Renomeação de colunas : gerenciada pelo analisador de formato.
- Colunas descartadas : Gerenciadas pelo analisador de formato.
- Ampliação de tipo : Gerenciada pelo analisador de formato.
- Outras alterações de tipo : tratadas pelo analisador de formato.
evolução do esquema suporte por analisador de formato
analisador sintáticofrom_json
O analisador from_json não suporta evolução do esquema. Você deve atualizar o esquema manualmente. Ao usar from_json nos LakeFlow Pipelines, a evolução do esquema automática pode ser habilitada com schemaLocationKey e schemaEvolutionMode.
- Novas colunas : Quando a evolução automática do esquema está ativada, ela se comporta como Auto Loader.
- Renomeação de colunas : Quando a evolução automática do esquema está ativada, ela se comporta como Auto Loader.
- Colunas descartadas : Quando a evolução automática do esquema está ativada, ela se comporta como Auto Loader.
- Ampliação de tipo : Quando a evolução automática do esquema está ativada, ela se comporta como Auto Loader.
- Outras alterações de tipo : Quando a evolução automática do esquema está ativada, ela se comporta como Auto Loader.
analisadores sintáticosfrom_avro e from_protobuf
Os analisadores from_avro e from_protobuf comportam-se da mesma maneira. O esquema pode ser obtido do Confluent Schema Registry, ou o usuário pode fornecer um esquema e deverá atualizá-lo manualmente. Não existe o conceito de evolução do esquema dentro da função from_avro ou from_protobuf ; isso deve ser tratado pelo mecanismo de execução e pelo Registro de Esquemas.
- Novas colunas : Compatíveis com o Confluent Schema Registry. Caso contrário, o usuário deverá atualizar o esquema manualmente.
- Renomeação de colunas : Compatível com o Confluent Schema Registry. Caso contrário, o usuário deverá atualizar o esquema manualmente.
- Colunas descartadas : Compatível com o Confluent Schema Registry. Caso contrário, o usuário deverá atualizar o esquema manualmente.
- Ampliação de tipos : Compatível com o Confluent Schema Registry. Caso contrário, o usuário deverá atualizar o esquema manualmente.
- Outras alterações de tipo : Compatível com o Confluent Schema Registry. Caso contrário, o usuário deverá atualizar o esquema manualmente.
analisadores sintáticosfrom_csv e from_xml
Os analisadores from_csv e from_xml não suportam a evolução do esquema.
- Novas colunas : Não suportado
- Renomear colunas : Não suportado
- Colunas excluídas : Não suportado
- Ampliação de tipo : Não suportado
- Outras alterações de tipo : Não suportado
Suporte à evolução do esquema pelo mecanismo
estrutura de fábrica
O esquema de uma consulta de transmissão é definido durante a fase de planejamento, e todos os microlotes reutilizam esse plano sem necessidade de replanejamento. Se o esquema de origem for alterado durante a execução, a consulta falhará e o usuário deverá reiniciar a consulta de transmissão para que Spark possa replanejar com base no novo esquema.
O dataset para o qual a transmissão escreve também deve suportar a evolução do esquema.
- Novas colunas : Suportadas. A consulta falhou e você precisa reiniciar a transmissão para resolver a incompatibilidade de esquema.
- Renomeação de colunas : Suportada. A consulta falhou e você precisa reiniciar a transmissão para resolver a incompatibilidade de esquema.
- Colunas excluídas : Suportado. A consulta falhou e você precisa reiniciar a transmissão para resolver a incompatibilidade de esquema.
- Ampliação de tipos : Suportada. A consulta falhou e você precisa reiniciar a transmissão para resolver a incompatibilidade de esquema.
- Outras alterações de tipo : Suportadas. A consulta falhou e você precisa reiniciar a transmissão para resolver a incompatibilidade de esquema.
evolução do esquema por dataset
mesas
tabelas de transmissão suportam comportamento merge evolução do esquema por default. A atualização do esquema não requer uma reinicialização manual, mas alterações arbitrárias no esquema exigem uma refresh completa.
- Novas colunas : Suportadas. A consulta é reiniciada automaticamente para resolver a incompatibilidade de esquema.
- Renomeação de colunas : Suportada. A consulta é reiniciada para resolver a incompatibilidade de esquema. A coluna renomeada é tratada como uma nova coluna adicionada.
- Colunas excluídas : Suportado. As colunas excluídas são tratadas como exclusões lógicas, em que as novas linhas da coluna excluída são definidas como NULL.
- Ampliação de tipo : Suportado. A ampliação de tipo deve ser habilitada no nível do pipeline ou diretamente na tabela. Consulte ampliação de tipo em Lakeflow pipelines.
- Outras alterações de tipo : Não suportadas. A atualização do esquema requer uma refresh completa.
Visão materializada
Qualquer atualização no esquema ou na consulta de definição aciona um recálculo completo da view materializada.
- Novas colunas : Recálculo completo acionado.
- Renomeação de coluna : Recálculo completo acionado.
- Colunas excluídas : Recálculo completo acionado.
- Ampliação de tipo : Recálculo completo acionado.
- Outras alterações de tipo : Recálculo completo acionado.
Tabelas Delta
As tabelas Delta suportam diversas configurações para atualizar o esquema da tabela, incluindo renomear, remover e ampliar o tipo de colunas sem sobrescrever os dados da tabela. As configurações suportadas incluem merge evolução do esquema, column mapping, type widening e overwriteSchema.
- Novas colunas : Suportadas. Evolui automaticamente quando merge evolução do esquema está habilitada, sem exigir a reescrita da tabela Delta . Se merge evolução do esquema não estiver habilitada, as atualizações falharão.
- Renomeação de colunas : Suportada. É possível renomear através do comando manual
ALTER TABLE DDLcom o mapeamento de colunas ativado. Não requer a reescrita da tabela Delta. - Colunas excluídas : Suportado. É possível remover colunas manualmente através do comando
ALTER TABLE DDLcom o mapeamento de colunas ativado. Não requer a reescrita da tabela Delta. - Ampliação de tipos : Suportada. Aplica automaticamente a mudança de tipo quando o alargamento de tipo e merge da evolução do esquema estão ativados. Você pode ampliar colunas através do comando manual
ALTER TABLE DDLquando a ampliação de tipo estiver habilitada. Sem nenhuma das duas configurações, as operações falham. Veja Ampliar tipos com evolução automática do esquema. - Outras alterações de tipo : Suportadas, mas exigem uma reescrita completa da tabela Delta. Você deve habilitar
overwriteSchema, o que permite uma reescrita completa da tabela Delta. Caso contrário, as operações falham.
visualizar
Se a view tiver um column_list que não corresponda ao novo esquema, ou tiver uma consulta que não possa ser analisada, a view torna-se inválida. Caso contrário, você pode habilitar a evolução do esquema para alterações de tipo com SCHEMA TYPE EVOLUTION e para alterações de tipo, bem como colunas novas, renomeadas e removidas com SCHEMA EVOLUTION (que é um superconjunto da evolução de tipo).
- Novas colunas : Suportadas. Com o modo
SCHEMA EVOLUTION, a view evolui automaticamente sem qualquer intervenção manual se não houver umcolumn_listexplícito. Caso contrário, a view pode se tornar inválida e o usuário não poderá consultá-la. - Renomeação de colunas : Suportada. Com o modo
SCHEMA EVOLUTION, a view evolui automaticamente sem qualquer intervenção manual se não houver umcolumn_listexplícito. Caso contrário, a view pode se tornar inválida. - Colunas excluídas : Suportado. Com o modo
SCHEMA EVOLUTION, a view evolui automaticamente sem qualquer intervenção manual se não houver umcolumn_listexplícito. Caso contrário, a view pode se tornar inválida. - Ampliação de tipos : Suportada. Com o modo
SCHEMA TYPE EVOLUTION, a view evolui automaticamente para quaisquer alterações de tipo. Com o modoSCHEMA EVOLUTION, a view evolui automaticamente sem qualquer intervenção manual se não houver umcolumn_listexplícito. Caso contrário, a view pode se tornar inválida. - Outras alterações de tipo : Suportadas. Com o modo
SCHEMA TYPE EVOLUTION, a view evolui automaticamente para quaisquer alterações de tipo. Com o modoSCHEMA EVOLUTION, a view evolui automaticamente sem qualquer intervenção manual se não houver umcolumn_listexplícito. Caso contrário, a view pode se tornar inválida.
Exemplo
O exemplo a seguir mostra como ingerir um tópico Kafka com payloads codificados em Avro registrados no Confluent Schema Registry e gravá-los em uma tabela Delta gerenciada com a evolução do esquema habilitada.
Pontos-chave ilustrados:
- Integre com o conector Kafka.
- Decodificar registros Avro usando `from_avro` com um Registro de Esquemas Kafka.
- Gerencie a evolução do esquema definindo
avroSchemaEvolutionMode. - Escreva em uma tabela Delta com
mergeSchemahabilitado para permitir alterações aditivas.
O código pressupõe que você tenha um tópico do Kafka usando o Confluent Schema Registry, que gera dados codificados em Avro.
# ----- CONFIG: fill these in -----
# Catalog and schema:
CATALOG = "<catalog_name>"
SCHEMA = "<schema_name>"
# Schema Registry:
# (This is where the producer evolves the schema)
SCHEMA_REG = "<schema registry endpoint>"
SR_USER = "<api key>"
SR_PASS = "<api secret>"
# Confluent Cloud: SASL_SSL broker:
BOOTSTRAP = "<server:ip>"
# Kafka topic:
TOPIC = "<topic>"
# ----- end: config -----
BRONZE_TABLE = f"{CATALOG}.{SCHEMA}.bronze_users"
CHECKPOINT = f"/Volumes/{CATALOG}/{SCHEMA}/checkpoints/bronze_users"
# Kafka auth (example for Confluent Cloud SASL/PLAIN over SSL)
KAFKA_OPTS = {
"kafka.security.protocol": "SASL_SSL",
"kafka.sasl.mechanism": "PLAIN",
"kafka.sasl.jaas.config": f"kafkashaded.org.apache.kafka.common.security.plain.PlainLoginModule required username='{SR_USER}' password='{SR_PASS}';"
}
# ----- Evolution knobs -----
# spark.conf.set("spark.databricks.delta.schema.autoMerge.enabled", value = True)
from pyspark.sql.functions import col
from pyspark.sql.avro.functions import from_avro
# Build reader
reader = (spark.readStream
.format("kafka")
.option("kafka.bootstrap.servers", BOOTSTRAP)
.option("subscribe", TOPIC)
.option("startingOffsets", "earliest")
)
# Attach Kafka auth options
for k, v in KAFKA_OPTS.items():
reader = reader.option(k, v)
# --- No native schema evolution supported. Returns a binary blob. ---
raw_df = reader.load()
# Decode Avro with Schema Registry
# --- The format parser handles updating the schema using the schema registry ---
decoded = from_avro(
data=col("value"),
jsonFormatSchema=None, # using SR
subject=f"{TOPIC}-value",
schemaRegistryAddress=SCHEMA_REG,
options={
"confluent.schema.registry.basic.auth.credentials.source": "USER_INFO",
"confluent.schema.registry.basic.auth.user.info": f"{SR_USER}:{SR_PASS}",
# Behavior on schema changes:
"avroSchemaEvolutionMode": "restart", # fail-fast so you can restart and adopt new fields
"mode": "FAILFAST"
}
).alias("payload")
bronze_df = raw_df.select(decoded, "timestamp").select("payload.*", "timestamp")
# Write to a managed Delta table as a STREAM
# --- Need to enable schema evolution separately for streaming to a Delta separately with mergeSchema --
(bronze_df.writeStream
.format("delta")
.option("checkpointLocation", CHECKPOINT)
.option("ignoreChanges", "true")
.outputMode("append")
.option("mergeSchema", "true") # only supports adding new columns. Renaming, dropping, and type changes need to be handled separately.
.trigger(availableNow=True) # Use availableNow trigger for Databricks SQL/Unity Catalog
.toTable(BRONZE_TABLE)
)