Classificação de dados
Esta página descreve como usar a Classificação de Dados Databricks no Unity Catalog para classificar e tag automaticamente dados confidenciais no seu catálogo.
Um catálogo de dados pode ter uma grande quantidade de dados, muitas vezes contendo dados confidenciais conhecidos e desconhecidos. É essencial que as equipes de dados entendam que tipo de dados confidenciais existem em cada tabela para que possam governar e democratizar o acesso a esses dados.
Para solucionar esse problema, Databricks Data Classification utiliza um agente AI para classificar e tag automaticamente as tabelas do seu catálogo. Isso permite descobrir dados sensíveis e aplicar controles de governança sobre os resultados, usando ferramentas como o controle de acesso baseado em atributos no Unity Catalog. Para obter uma lista das tags suportadas, consulte tagsde classificação suportadas.
Com este recurso, é possível:
- Classificar dados : o mecanismo usa um sistema AI de agente para classificar e tag automaticamente quaisquer tabelas no Unity Catalog.
- Otimize custos por meio de varredura inteligente : o sistema determina de forma inteligente quando escanear seus dados, aproveitando o Unity Catalog e o Data Intelligence Engine. Isso significa que a digitalização é incremental e otimizada para garantir que todos os novos dados sejam classificados sem configuração manual.
- Revisar e proteger dados confidenciais : a exibição de resultados auxilia na visualização de resultados de classificação e na proteção de dados confidenciais por tags e na criação de políticas de controle de acesso para cada classe.
A Classificação de Dados Databricks usa armazenamentodefault para armazenar resultados de classificação. Você não será cobrado pelo armazenamento.
A Classificação de Dados do Databricks usa um modelo de linguagem grande (LLM) para auxiliar na classificação.
Requisitos
- Seu workspace deve ter computeserverless disponível (habilitada por default em espaços de trabalho com Unity Catalog).
- Para habilitar a classificação de dados, você deve ser o proprietário do catálogo ou ter privilégios
USE CATALOGeMANAGEnele. - Para habilitar tags automáticas para um catálogo, você deve ter
USE CATALOGno catálogo,APPLY TAGno catálogo eASSIGNna tag que está sendo aplicada. - Para view os resultados da classificação na interface do usuário, você deve ter
USE CATALOGeMANAGEou (SELECT+USE SCHEMA) no catálogo. Para ver os valores de amostra associados às detecções, você deve terSELECTna tabela do sistema de resultados.
Por default, apenas os administradores account têm permissões MANAGE e ASSIGN nas tags regidas pelo sistema de classificação de dados. Os administradores de contas podem conceder MANAGE e ASSIGN para tags governadas individuais a outros usuários, entidades de serviço ou grupos. Consulte a seção sobre gerenciamento de permissões em tagscontroladas.
Usar classificação de dados
Você pode habilitar a classificação de dados para vários catálogos simultaneamente na página de resultados ou configurar catálogos individuais com um controle mais granular em nível de esquema.
Habilitar vários catálogos
- Na página de resultados da Classificação de Dados, clique em Configurar .
- Selecione os catálogos que deseja ativar ou selecione todos os catálogos disponíveis no workspace.
- Clique em Habilitar .
Habilitar todos os catálogos disponíveis não habilita automaticamente os catálogos futuros. Para classificar um novo catálogo, retorne à caixa de diálogo Configurar e habilite-o.
Habilitar um único catálogo com seleção de esquema
Para selecionar esquemas específicos dentro de um catálogo:
-
Navegue até o catálogo e clique na tab Detalhes .
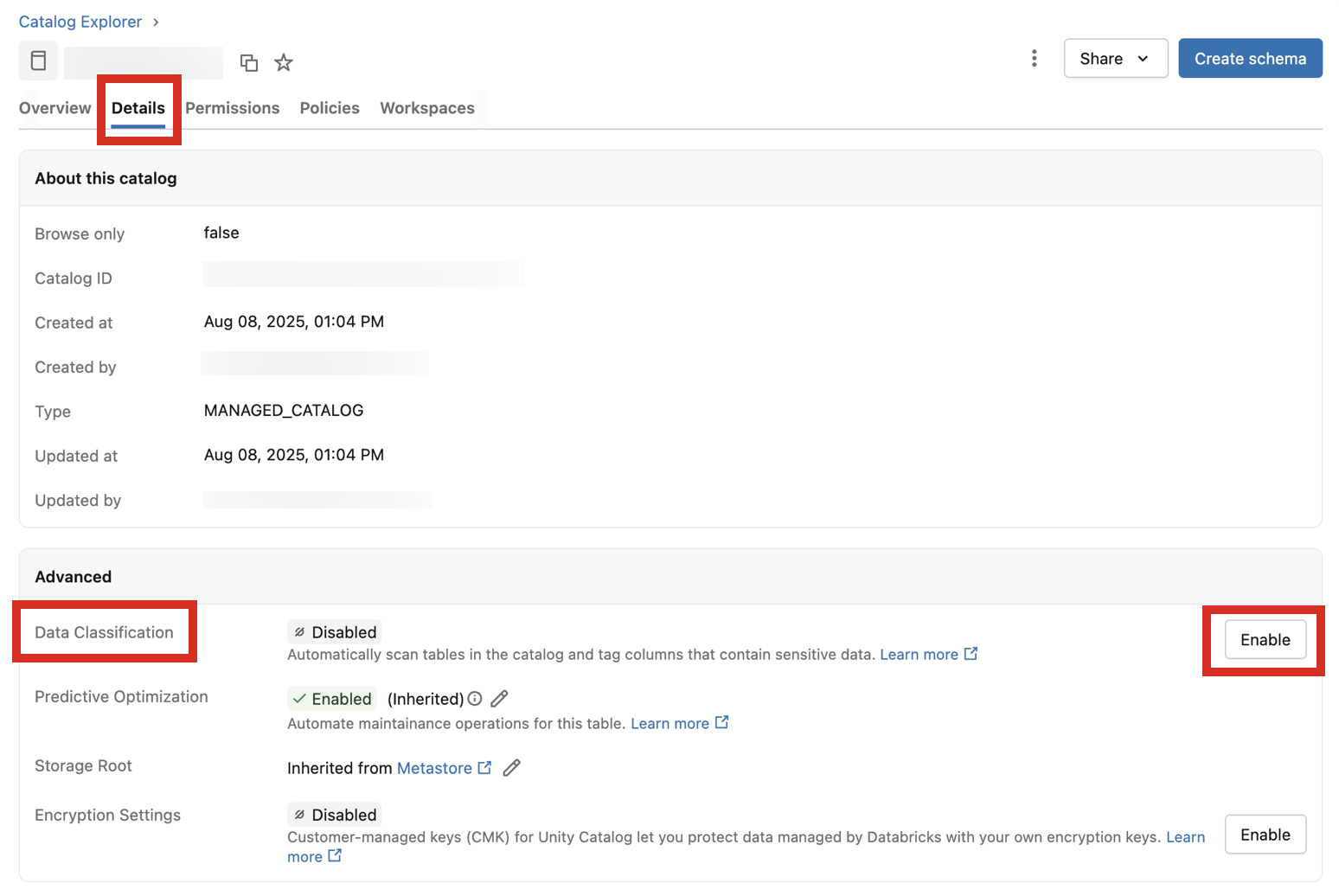
-
Ao lado de Classificação de Dados , clique no botão Ativar .
-
A caixa de diálogo Classificação de Dados é exibida. Por default, todos os esquemas estão incluídos. Para incluir apenas alguns esquemas, selecione-os no menu dropdown Esquemas a incluir" . Você também pode selecionar uma política de uso.
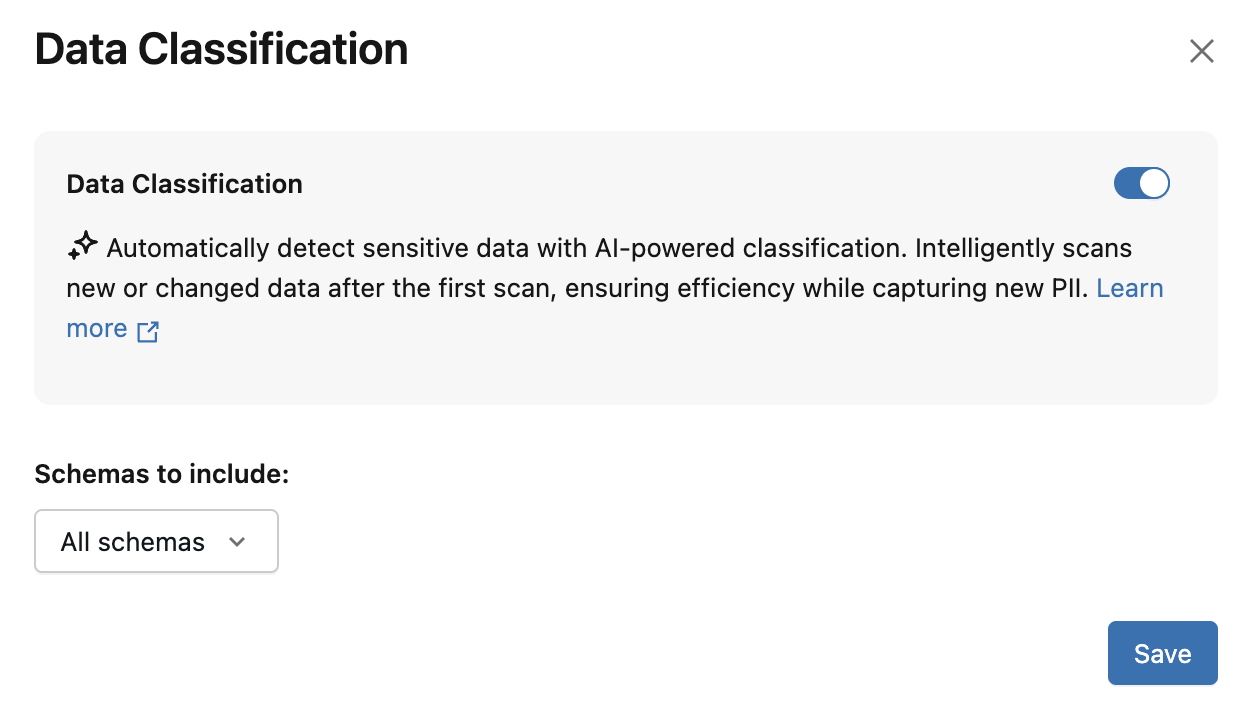
-
Clique em Salvar .
Isso cria uma tarefa em segundo plano que verifica incrementalmente todas as tabelas no catálogo ou nos esquemas selecionados.
O mecanismo de classificação depende de varredura inteligente para determinar quando varrer uma tabela. Novas tabelas e colunas em um catálogo geralmente são digitalizadas dentro de 24 horas após sua criação.
visualizar resultados da classificação
Para view os resultados da classificação, clique em " Ver resultados" ao lado da configuração "Classificação de dados" .
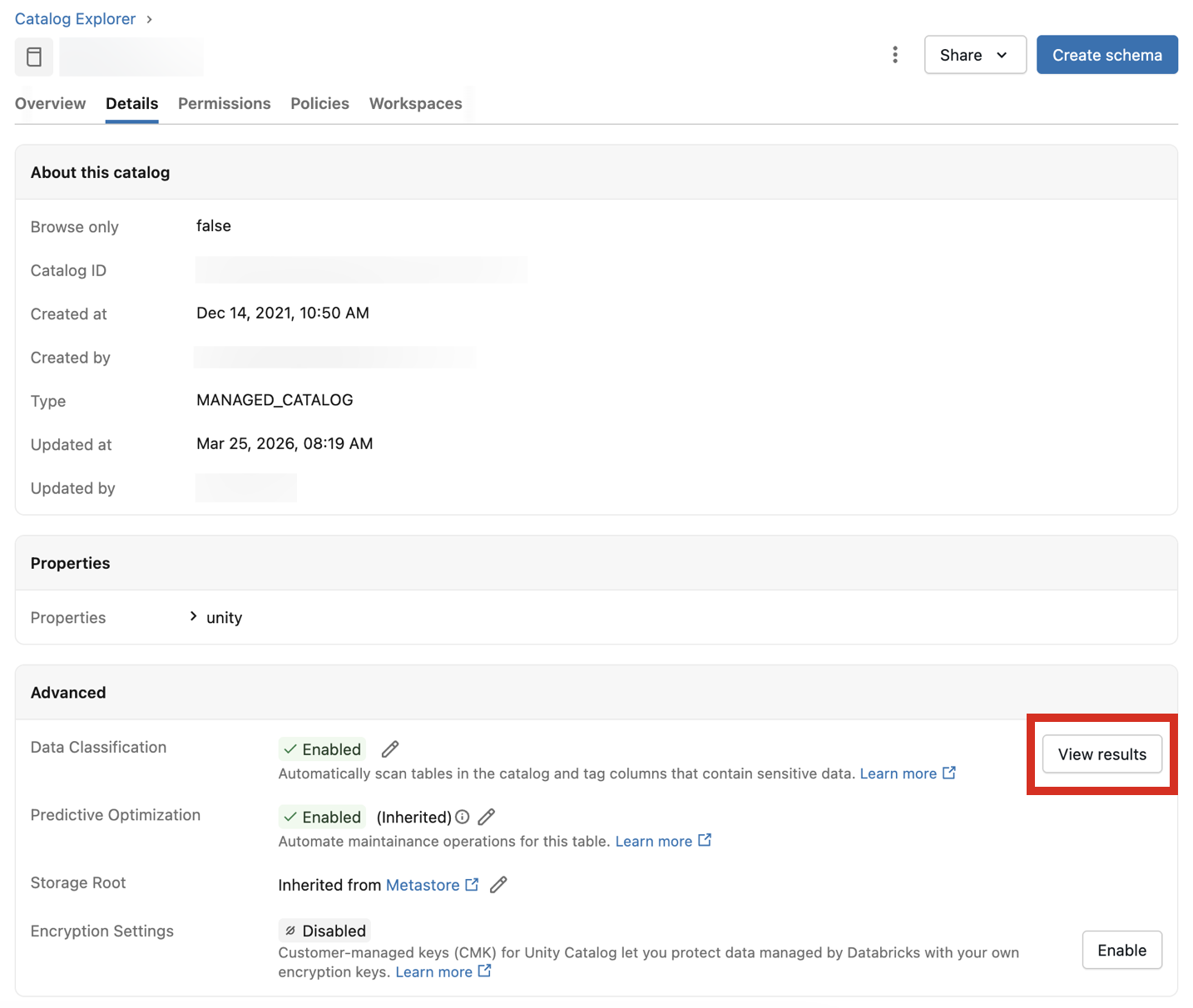
Isso abre a interface de usuário de Classificação de Dados para o catálogo. Para view os resultados da classificação, é necessário um SQL warehouse serverless .
Você também pode view os resultados agregados de todos os catálogos classificados no metastore usando o seletor de catálogo no canto superior esquerdo. Selecione " Todos os catálogos" no menu suspenso.
Para cada tipo de classificação, a tabela mostra:
- Colunas detectadas : O número de colunas onde a classificação foi detectada.
- Etiquetas automáticas : O status das etiquetas para essa classificação — Ativo ou Inativo . Na view do metastore, o status " Parcialmente Ativo" indica que a funcionalidade de tags está habilitada em alguns catálogos, mas não em todos.
- Acesso do usuário (últimos 7 dias) : Número de usuários distintos que acessaram dados não mascarados versus dados mascarados dessa classificação nos últimos 7 dias. Utilize esta ferramenta para avaliar a exposição de dados sensíveis em toda a sua organização.
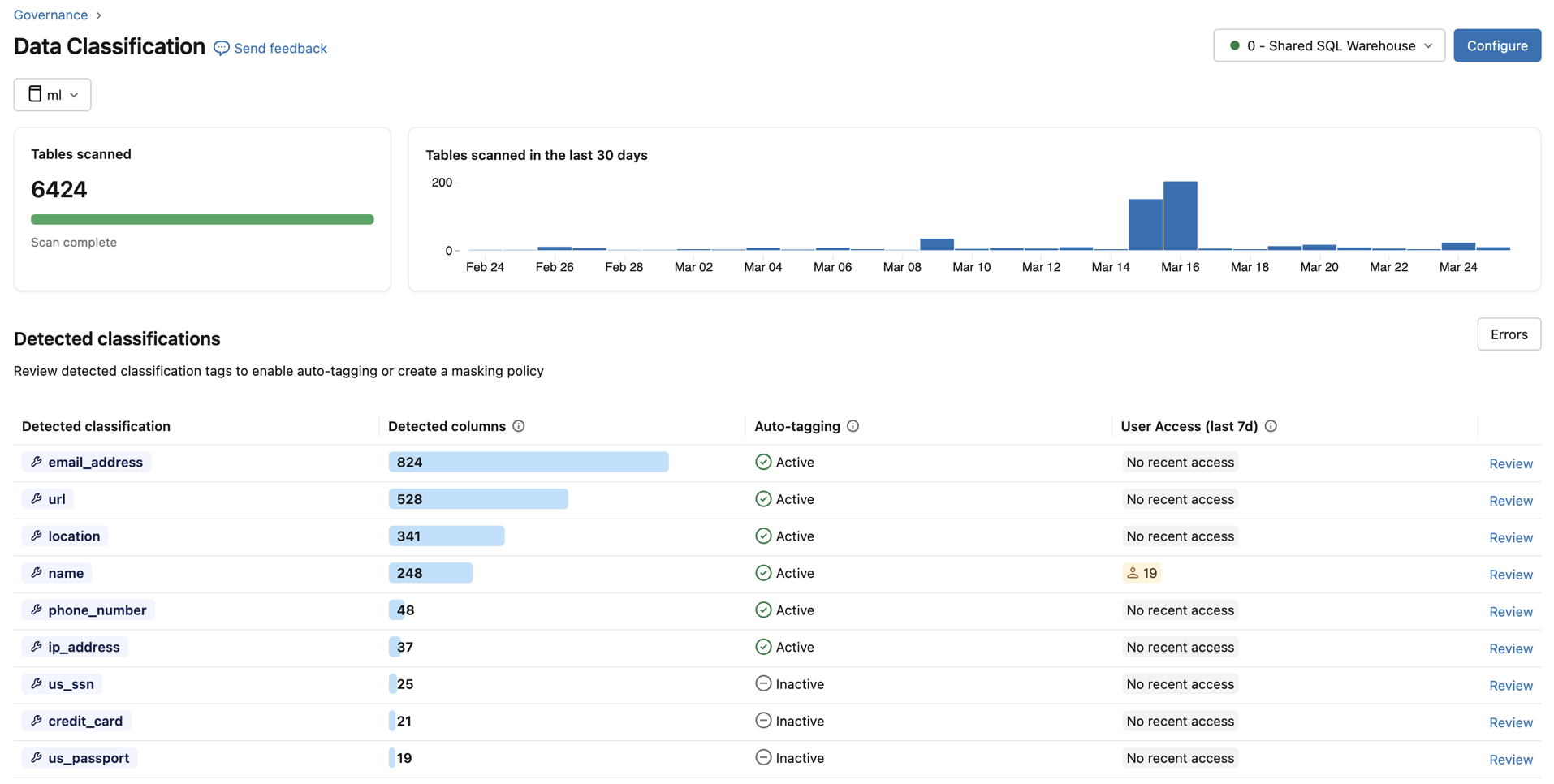
Detecções de revisão
Para analisar os resultados de um tipo de classificação específico, clique em "Analisar" na coluna mais à direita. Aparece um painel com duas abas:
- Colunas detectadas : Exibe as colunas onde a tag de classificação foi detectada com alta confiança, ordenadas da detecção mais recente para a mais antiga. Inclui também um gráfico de detecções ao longo do tempo e uma lista de colunas detectadas com valores de exemplo. Clique em qualquer barra do gráfico para ver as detecções específicas daquela data. Os valores de exemplo só aparecem se você tiver as permissões necessárias para view os resultados da classificação.
- Acesso do usuário : Lista todos os usuários que acessaram colunas com esta tag de classificação, mostrando seus email e nomes de usuário, além de indicar se o acesso é mascarado ou não mascarado. Também mostra quaisquer políticas de controle de acesso baseado em atributos (ABAC) atribuídas a esta tag de classificação. Ao visualizar os resultados de um único catálogo, você pode criar uma nova política ABAC diretamente do painel.
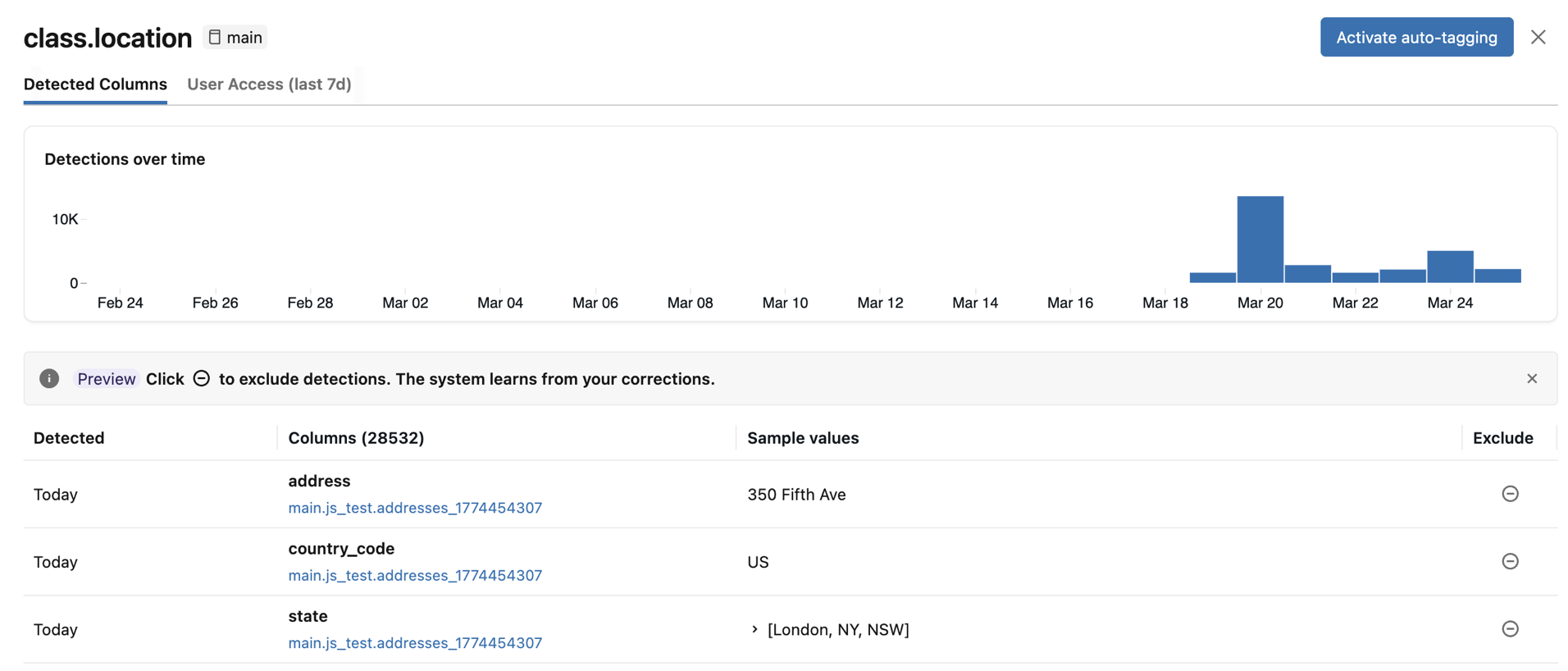
Caso alguma das colunas detectadas esteja incorreta, você pode clicar no ícone Excluir à direita da entrada. Consulte Excluir detecções.
Ativar tags automáticas
Se as colunas identificadas corresponderem às suas expectativas, você poderá ativar as tags automáticas para a tag de classificação. Quando a marcação automática está ativada, todas as detecções existentes e futuras dessa classificação são marcadas.
Você pode configurar tags automáticas em dois níveis:
- Nível do Metastore : Ativar ou desativar em todos os catálogos simultaneamente. Você precisa ser um administrador do metastore e ter
ASSIGNna tag que está sendo aplicada. - Nível do catálogo : Ativar ou desativar apenas para o catálogo atual. As configurações de nível de catálogo têm precedência sobre as configurações de nível de metastore. Você deve ter
USE CATALOGeAPPLY TAGno catálogo eASSIGNna tag que está sendo aplicada.
No nível do catálogo, as etiquetas automáticas possuem três estados:
- Padrão (herdado) : O catálogo herda a configuração de tags do nível do metastore.
- A opção "Ativo : as tags" está explicitamente habilitada para este catálogo, independentemente da configuração no nível do metastore.
- A opção "Inativo : as tags" está explicitamente desativada para este catálogo, independentemente da configuração no nível do metastore.
Ao desativar as tags, nenhuma tags futura será aplicada, mas tags existentes não serão removidas.
Quando você habilita tags automáticas, tags não são preenchidas imediatamente. Eles serão preenchidos na próxima verificação, que deverá entrar em vigor em 24 horas. Classificações subsequentes serão marcadas imediatamente.
Excluir detecções
Beta
As exclusões de detecção e sua utilização para melhorar a precisão da classificação futura estão em versão Beta.
No painel de revisão, você pode excluir detecções de colunas individuais. Excluindo uma detecção:
- Remove qualquer tag de classificação existente dessa coluna.
- Impede que futuras verificações reapliquem a tag a essa coluna.
- Fornece feedback que melhora a precisão dos resultados de classificação futuros.
Para excluir uma detecção, clique no ícone Excluir da coluna correspondente no painel de revisão. Para incluir novamente a detecção, clique no ícone mais uma vez.
A tabela do sistema de resultados
A classificação de dados cria uma tabela de sistema chamada system.data_classification.results para armazenar resultados que, por default são acessíveis somente ao administrador account . O administrador account pode compartilhar esta tabela. A tabela só fica acessível quando você usa compute serverless . Para obter detalhes sobre esta tabela, consulte Referência da tabela do sistema de classificação de dados.
A tabela de resultados system.data_classification.results contém todos os resultados de classificação em todo o metastore e inclui valores de amostra de tabelas em cada catálogo. Você deve compartilhar esta tabela somente com usuários que tenham o privilégio de ver os resultados da classificação em todo o metastore, incluindo valores de amostra.
Usuários com acesso SELECT a esta tabela também podem ver valores de amostra associados às detecções na página de resultados da Classificação de Dados.
Configurar controles de governança com base nos resultados da classificação de dados
Mascarar uso de dados confidenciais em uma política ABAC
A Databricks recomenda o uso do controle de acesso baseado em atributos no Unity Catalog para criar controles de governança com base nos resultados da classificação de dados.
Para criar uma política a partir da página de resultados da Classificação de Dados, clique em Revisar para uma tag de classificação, abra a tab Acesso do Usuário e clique em Nova política . O formulário de política é preenchido previamente para ocultar as colunas com a tag de classificação que está sendo analisada. Para mascarar os dados, especifique qualquer função de mascaramento registrada no Unity Catalog e clique em Salvar .
Você também pode criar uma política que abranja diversas tags de classificação, alterando a coluna Quando para atende à condição e fornecendo diversas tags.
Por exemplo, para criar uma política chamada "Confidencial" que mascara qualquer nome, email ou número de telefone, defina a condição meets como has_tag("class.name") OR has_tag("class.email_address") OR has_tag("class.phone_number").
Descoberta e exclusão do GDPR
Este exemplo de Notebook mostra como você pode usar a classificação de dados para auxiliar na descoberta e exclusão de dados para compliance GDPR .
Descoberta e exclusão GDPR usando o Notebook de classificação de dados
Como lidar com tags incorretas
Se uma classificação estiver incorreta, exclua a detecção do painel de revisão. Excluir uma detecção remove a tag, impede que ela seja reaplicada e melhora a precisão de varreduras futuras. Consulte Excluir detecções.
Erros de digitalização
Se ocorrer algum erro durante a verificação, um botão Erros aparecerá no canto superior direito da tabela de resultados.
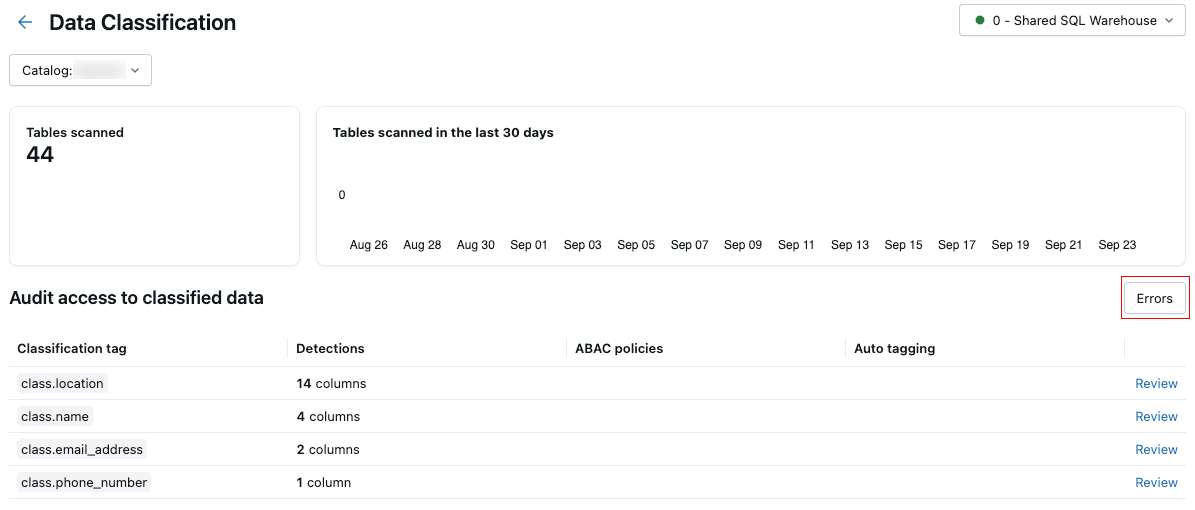
Clique no botão para exibir as tabelas que falharam na verificação e as mensagens de erro associadas.

Por default, falhas que ocorreram em tabelas individuais são ignoradas e repetidas no dia seguinte.
visualizar despesas com classificação de dados
Para entender como a Classificação de Dados é cobrada, consulte a página de preços. Você pode view despesas relacionadas à Classificação de Dados executando uma consulta ou visualizando o painel de uso.
A digitalização inicial é mais custosa do que as digitalizações subsequentes no mesmo catálogo, pois essas digitalizações são incrementais e normalmente geram custos mais baixos.
visualizar o uso na tabela do sistema system.billing.usage
Você pode consultar as despesas de classificação de dados de system.billing.usage. Os campos created_by e catalog_id podem ser usados opcionalmente para detalhar os custos:
created_byIncluir para visualizar os custos por usuário que iniciou o uso.catalog_idInclua para visualizar os custos por catálogo. O ID do catálogo é mostrado na tabelasystem.data_classification.results.
Exemplo de consulta para os últimos 30 dias:
SELECT
usage_date,
identity_metadata.created_by,
usage_metadata.catalog_id,
SUM(usage_quantity) AS dbus
FROM
system.billing.usage
WHERE
usage_date >= DATE_SUB(CURRENT_DATE(), 30)
AND billing_origin_product = 'DATA_CLASSIFICATION'
GROUP BY
usage_date,
created_by,
catalog_id
ORDER BY
usage_date DESC,
created_by;
Para calcular o custo total em dólares, join com system.billing.list_prices. A consulta de exemplo a seguir usa um parâmetro nomeado :add_on_rate como um multiplicador no preço de lista. Defina como 1 para usar o preço de tabela diretamente ou para um valor menor que 1 para refletir um desconto negociado (por exemplo, 0.9 para um desconto de 10%).
Exemplo de consulta para o custo total em dólares nos últimos 30 dias:
SELECT
u.usage_date,
SUM(u.usage_quantity * lp.pricing.effective_list.default) * :add_on_rate
AS `Data Classification Dollar Cost`
FROM system.billing.usage AS u
JOIN system.billing.list_prices AS lp
ON lp.sku_name = u.sku_name
WHERE
u.billing_origin_product = 'DATA_CLASSIFICATION'
AND u.usage_end_time >= lp.price_start_time
AND (lp.price_end_time IS NULL OR u.usage_end_time < lp.price_end_time)
AND u.usage_date >= DATE_ADD(CURRENT_DATE(), -30)
GROUP BY
u.usage_date
ORDER BY
u.usage_date DESC;
visualizar o uso no painel de uso
Caso já possua um painel de uso configurado em workspace, é possível utilizá-lo para filtrar o uso selecionando o rótulo “Classificação de dados” em Projeto de origem de faturamento. Se você não tiver um painel de uso configurado, poderá importar um e aplicar a mesma filtragem. Para obter detalhes, consulte Painéis de uso.
tagsde classificação suportadas
Para obter uma lista completa de tags compatíveis, organizadas por tags globais, tags regionais e estruturas de compliance (PII, PCI DSS, GDPR, HIPAA, GLBA, DPDPA e PIPEDA), consulte Tags de classificação compatíveis.
Limitações
- view e métricas view não são suportadas. Se a view for baseada em tabelas existentes, Databricks recomenda classificar as tabelas subjacentes para verificar se elas contêm dados confidenciais.