O que são pacotes de automação declarativa?
Os Declarative Automation Bundles (anteriormente conhecidos como Databricks Ativo Bundles) são uma ferramenta para facilitar a adoção das melhores práticas de engenharia software , incluindo controle de versão, revisão de código, testes e integração e entrega contínuas (CI/CD), para seus projetos de dados e AI . Os Bundles oferecem uma maneira de incluir metadados junto com os arquivos de origem do seu projeto e possibilitam descrever recursos Databricks como Jobs e pipelines, como arquivos de origem. Em última análise, um pacote é uma definição completa de um projeto, incluindo como o projeto deve ser estruturado, testado e implementado. Isso facilita a colaboração em projetos durante o desenvolvimento ativo.
A coleção de arquivos de origem e metadados do seu projeto de pacote é implantada como um único pacote no seu ambiente de destino. Um pacote inclui as seguintes partes:
- Configurações obrigatórias de infraestrutura de nuvem e espaço de trabalho
- Arquivos de origem, como notebooks e arquivos Python, que incluem a lógica de negócios
- Definições e configurações para recursos Databricks , como Jobs LakeFlow , pipeline declarativo LakeFlow Spark , Dashboards, endpoint de modelo de serviço, Experimentos MLflow e modelos registrados MLflow
- Testes unitários e testes de integração
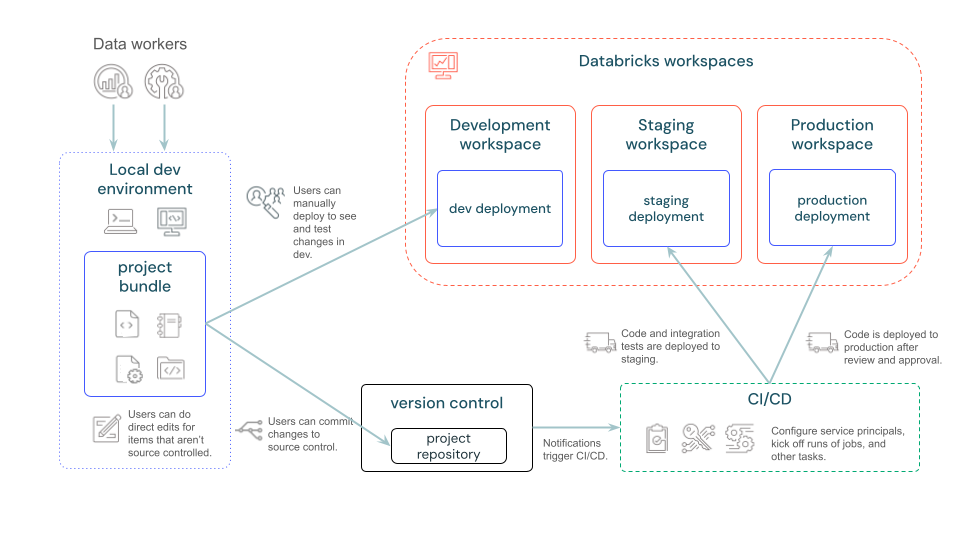
O diagrama a seguir fornece uma visão de alto nível de um pipeline de desenvolvimento e CI/CD com pacotes:
Vídeo explicativo
Este vídeo demonstra como trabalhar com pacotes de automação declarativa (5 minutos).
Quando devo usar pacotes?
Os pacotes de automação declarativa são uma abordagem Infrastructure-as-Code (IaC) para gerenciar seus projetos Databricks . Use-os quando precisar gerenciar projetos complexos onde múltiplos colaboradores e automação são essenciais, e a integração e implantação contínuas (CI/CD) são requisitos. Como os pacotes são definidos e gerenciados por meio do padrão YAML e de arquivos que você cria e mantém junto com o código-fonte, eles se adaptam bem a cenários em que IaC é uma abordagem apropriada.
Alguns cenários ideais para pacotes incluem:
- Desenvolva projetos de dados, análises e ML em um ambiente baseado em equipe. Os pacotes podem ajudá-lo a organizar e gerenciar vários arquivos de origem com eficiência. Isso garante uma colaboração tranquila e processos otimizados.
- Itere em problemas de ML mais rapidamente. Gerencie recursos de ML pipelines (como jobs de treinamento e inferência em lote) usando projetos de ML que seguem as práticas recomendadas de produção desde o início.
- Defina padrões organizacionais para novos projetos criando modelos de pacotes personalizados que incluem permissões default, entidades de serviço e configurações de CI/CD.
- Conformidade regulatória: em setores onde a conformidade regulatória é uma preocupação significativa, os pacotes podem ajudar a manter um histórico de versões do código e do trabalho de infraestrutura. Isso auxilia na governança e garante que os padrões de conformidade necessários sejam atendidos.
Como funcionam os pacotes?
Os metadados do pacote são definidos usando arquivos YAML que especificam os artefatos, os recursos e a configuração de um projeto do Databricks. A CLI do Databricks pode ser usada para validar, implantar e executar pacotes usando esses arquivos YAML de pacote. Você pode executar projetos em pacotes a partir de IDEs, terminais ou diretamente no Databricks.
Os pacotes podem ser criados manualmente ou com base em um padrão. O Databricks CLI fornece o padrão default para casos de uso simples, mas para trabalhos mais específicos ou complexos, o senhor pode criar um padrão de pacote personalizado para implementar as práticas recomendadas da sua equipe e manter a consistência das configurações comuns.
Para obter mais detalhes sobre a configuração YAML usada para expressar os Pacotes de Automação Declarativa, consulte Configuração dos Pacotes de Automação Declarativa.
O que preciso instalar para usar os pacotes?
Os pacotes de automação declarativa são um recurso da CLI do Databricks. Você cria pacotes localmente e, em seguida, usa a CLI Databricks para implantar seus pacotes em espaços de trabalho remotos Databricks e executar o fluxo de trabalho do pacote nesses espaços de trabalho a partir da linha de comando.
Se você quiser apenas usar pacotes no workspace, não precisa instalar o Databricks CLI . Consulte Colaborar em pacotes no workspace.
Para criar, implantar e executar pacotes em seu espaço de trabalho Databricks:
-
Seu espaço de trabalho remoto Databricks deve ter os arquivos workspace ativados. Se o senhor estiver usando Databricks Runtime versão 11.3 LTS ou acima, esse recurso é ativado por default.
-
O senhor deve instalar o Databricks CLI, versão v0.218.0 ou acima. Para instalar ou atualizar a CLI da Databricks, consulte Instalar ou atualizar a CLI da Databricks.
Databricks recomenda que o senhor atualize regularmente para a versão mais recente do site CLI para aproveitar as vantagens dos novos recursos do pacote. Para encontrar a versão do Databricks CLI que está instalada, execute o seguinte comando:
shdatabricks --version -
Você configurou a CLI Databricks para acessar seu espaço de trabalho Databricks . Databricks recomenda configurar o acesso usando a autenticação OAuth de usuário para máquina (U2M), que é descrita em Configurar o acesso ao seu workspace. Outros métodos de autenticação são descritos em Autenticação para Pacotes de Automação Declarativa.
Como faço para começar a usar os pacotes?
A maneira mais rápida de começar o desenvolvimento de pacotes locais é usar um projeto de pacote padrão. Crie seu primeiro projeto de pacote usando o comando bundle init do Databricks CLI. Este comando apresenta uma escolha de pacote default fornecido Databrickse faz uma série de perguntas para inicializar variáveis do projeto.
databricks bundle init
Criar seu pacote é a primeira etapa no ciclo de vida de um pacote. Em seguida, desenvolva o pacote definindo as configurações do pacote e o recurso nos arquivos de configuração databricks.yml e recurso. Por fim, valide e implante seu pacote e, em seguida, execute seu fluxo de trabalho.
Os exemplos de configuração do pacote podem ser encontrados em Exemplos de configuração do pacote e no repositório de exemplos do pacote no GitHub.
Próximas etapas
- Crie um pacote que implante um Notebook em um workspace Databricks e, em seguida, execute esse Notebook implantado em um Job ou pipeline Databricks . Consulte Desenvolver um trabalho com pacotes de automação declarativa e Desenvolver um pipeline com pacotes de automação declarativa.
- Crie um pacote que implante e execute uma pilha MLOps . Consulte Pacotes de Automação Declarativa para Pilhas MLOps.
- Inicie uma implantação de pacote como parte de um fluxo de trabalho de CI/CD (integração contínua/implantação contínua) no GitHub. Veja a execução a CI/CD fluxo de trabalho com um pacote que executa a pipeline atualização.
- Crie um pacote que construa, implante e execute um arquivo Python wheel . Consulte Criar um arquivo Python wheel usando Declarative Automation Bundles.
- Gere a configuração em seu pacote para uma tarefa ou outro recurso em seu workspace e, em seguida, vincule-a ao recurso em workspace para que a configuração permaneça sincronizada. Veja databricks bundle generate e databricks bundle deployment bind.
- Crie e implante um pacote no site workspace. Consulte Colaboração em pacotes no site workspace.
- Crie um padrão personalizado que você e outras pessoas possam usar para criar um pacote. Um padrão personalizado pode incluir permissões default , entidade de serviço e configuração personalizada CI/CD . Consulte o projeto Padrão de Pacotes de Automação Declarativa.
- Migre do dbx para os Pacotes de Automação Declarativa. Consulte Migrar de dbx para bundles.
- Descubra o mais recente recurso importante lançado para Declarative Automation Bundles. Consulte o recurso Declarative Automation Bundles, notas sobre a versão.