Pacotes de autores no workspace
Os pacotes de automação declarativa podem ser criados e modificados diretamente no workspace.
Para obter informações sobre os requisitos de uso de pacotes no workspace, consulte os requisitos de pacotes de automação declarativa no workspace.
Para obter mais informações sobre pacotes, consulte O que são pacotes de automação declarativa?.
Criar um pacote
Para criar um pacote no site Databricks workspace:
-
Navegue até a pasta Git onde deseja criar o pacote.
-
Clique no botão Criar e, em seguida, clique em Pacote . Alternativamente, clique com o botão direito do mouse na pasta Git ou no ícone associado na árvore workspace e clique em Criar > Pacote :
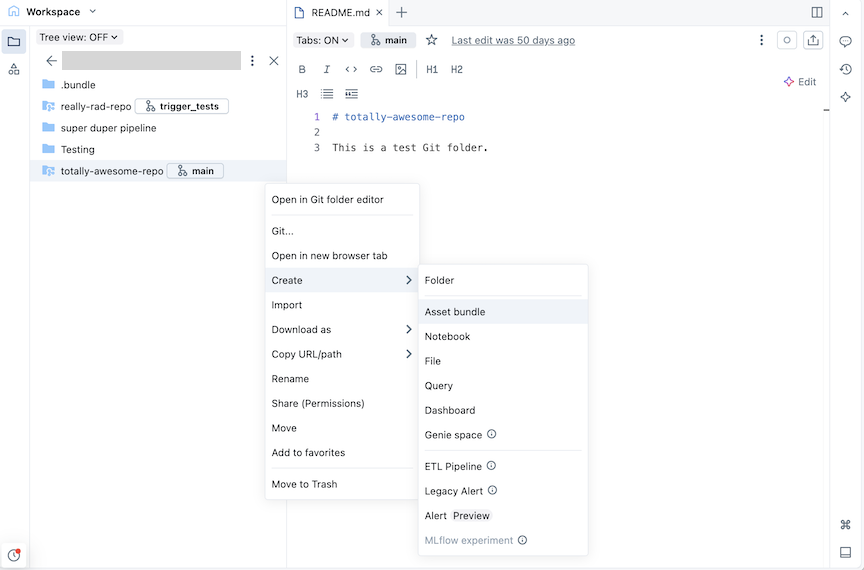
-
Na caixa de diálogo Criar um pacote , dê um nome ao pacote, como por exemplo, pacote-totalmente-incrível . O nome do pacote só pode conter letras, números, hífens e sublinhado.
-
Para padrão , escolha se deseja criar um pacote usando um padrão personalizado, um pacote vazio, um pacote que executa um Notebook Python de exemplo ou um pacote que executa SQL. Se o Editor de LakeFlow Pipelines estiver habilitado, uma opção para criar um projeto de pipeline ETL também será exibida. Qualquer modelo personalizado configurado no workspace, também estará disponível.
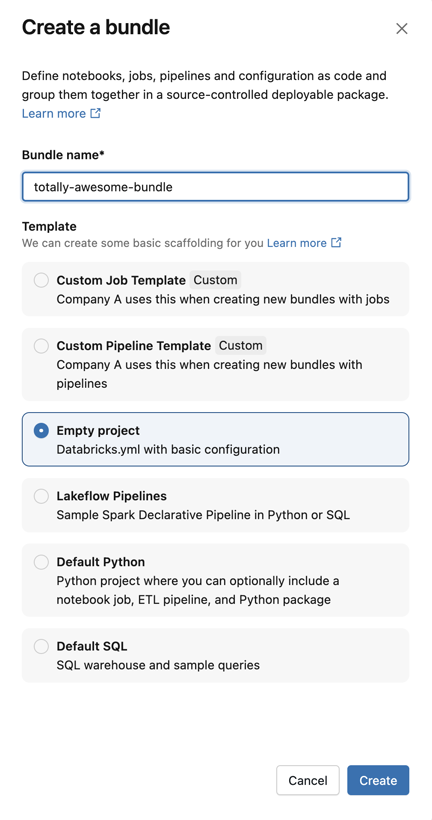
-
Alguns padrões exigem configuração adicional. Clique em Avançar para finalizar a configuração do projeto.
Template | Opções de configuração |
|---|---|
LakeFlow Pipelines |
|
padrão Python |
|
padrão SQL |
|
- Clique em Create and implantado .
Isso cria um pacote inicial na pasta Git , que inclui os arquivos para o padrão de projeto que você selecionou, um arquivo de configuração Git .gitignore e o arquivo Declarative Automation Bundles databricks.yml necessário. O arquivo databricks.yml contém a configuração principal do pacote. Para obter detalhes, consulte a configuração de pacotes de automação declarativa.
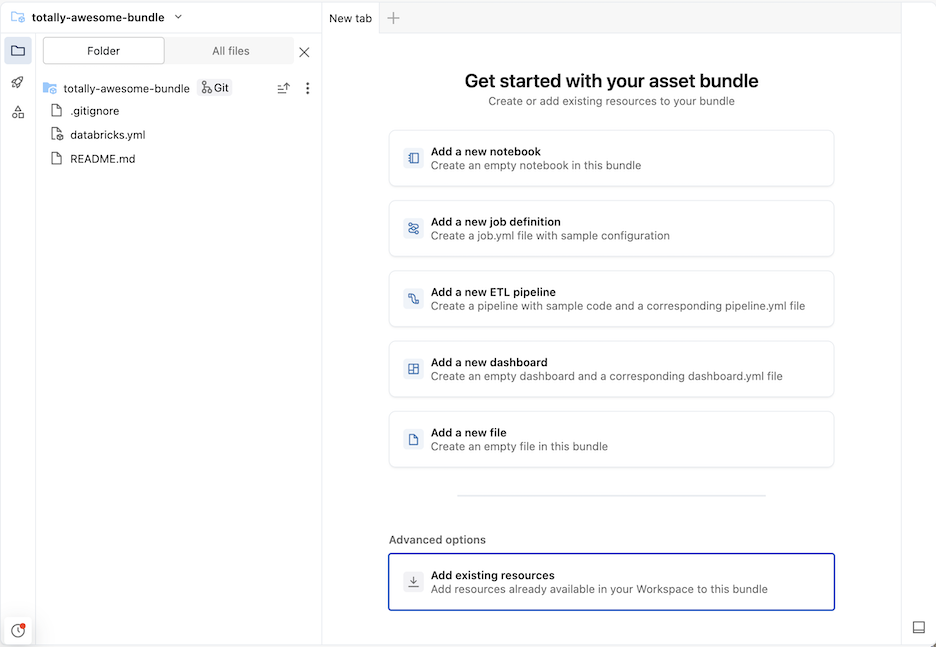
Todas as alterações feitas nos arquivos do pacote podem ser sincronizadas com o repositório remoto associado à pasta Git. Uma pasta Git pode conter muitos pacotes.
Adicionar novos arquivos a um pacote
Um pacote contém o arquivo databricks.yml que define as configurações de implantação e do Workspace, arquivos de origem, como Notebooks, arquivos Python e arquivos de teste, e definições e configurações para recursos do Databricks, como Lakeflow Jobs e LakeFlow Pipelines. Semelhante a qualquer pasta do Workspace, você pode adicionar novos arquivos ao seu pacote.
Para abrir um novo tab no pacote view que permite modificar os arquivos do pacote, navegue até a pasta do pacote em workspace e clique em Open in editor (Abrir no editor ) à direita do nome do pacote.
Adicionar arquivos de código-fonte
Para adicionar um novo Notebook ou outros arquivos a um pacote na interface do usuário do workspace, navegue até a pasta do pacote e, em seguida, clique em
- Clique em Create (Criar ) no canto superior direito e escolha um dos seguintes tipos de arquivo para adicionar ao seu pacote: Notebook, File (Arquivo), Query (Consulta), Dashboard (Painel).
- Como alternativa, clique no kebab à esquerda de Compartilhar e importe um arquivo.
Para que o arquivo faça parte da implementação do pacote, depois de adicionar um arquivo à pasta do pacote, o senhor deve adicioná-lo à configuração do pacote databricks.yml ou criar um arquivo de definição de trabalho ou pipeline que o inclua. Consulte Adicionar um recurso existente a um pacote.
Criar uma definição de recurso
Os pacotes contêm definições de recursos, como tarefas e pipelines, para inclusão em uma implantação. Quando o pacote é implantado, os recursos definidos no pacote são criados no workspace (ou atualizados, caso já tenham sido implantados). Essas definições são especificadas em YAML ou Python, e você pode criar e editar essas configurações diretamente na interface do usuário.
- Navegue até a pasta do pacote no workspace onde você deseja definir um novo recurso.
Se o senhor já tiver aberto o pacote no editor em workspace, poderá usar a lista de contextos de criação do navegador workspace para navegar até a pasta do pacote. Consulte Contextos de criação.
-
À direita do nome do pacote, clique em Open in editor (Abrir no editor ) para navegar até o editor de pacotes view.
-
Clique no ícone de implantação do pacote para alternar para o painel Implantações.
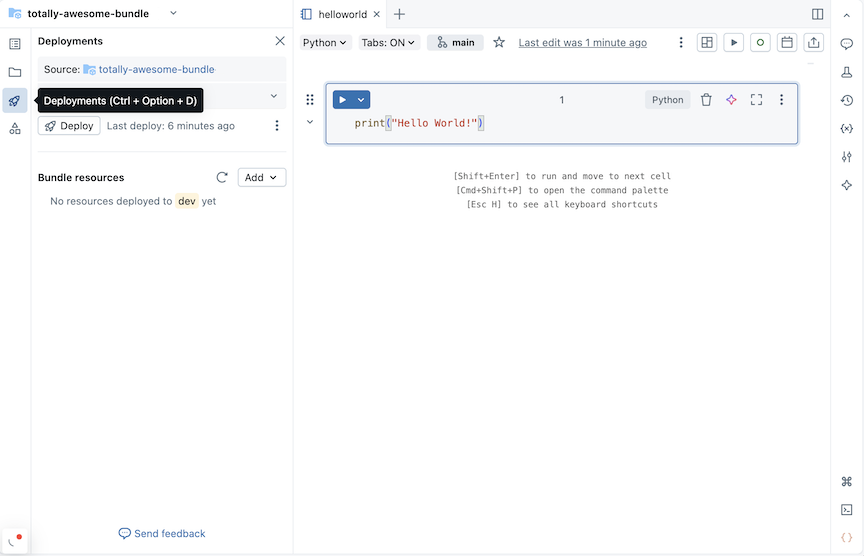
-
Na seção "Recurso do pacote" , clique em "Adicionar" e, em seguida, escolha uma definição de recurso para criar.
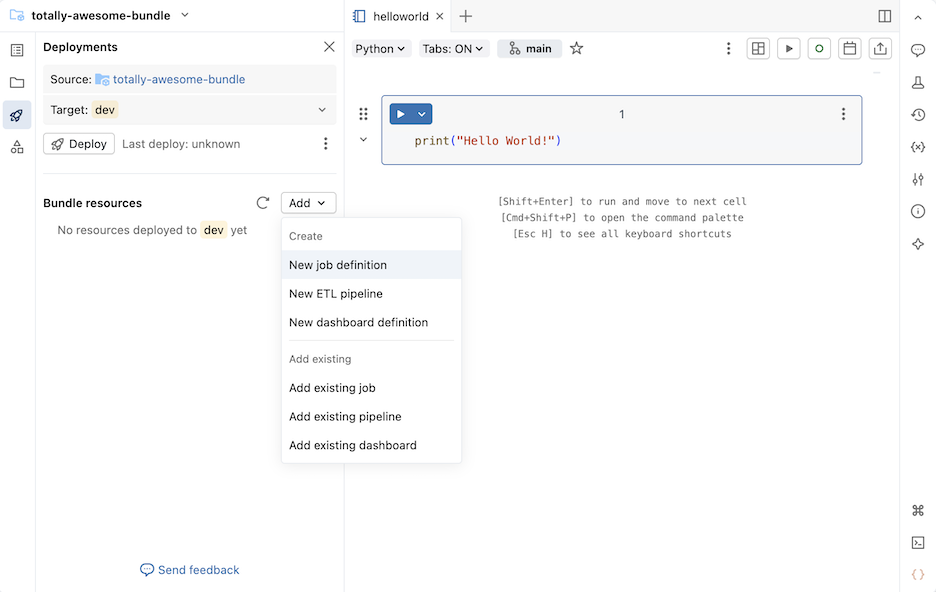
Nova definição de emprego
Para criar um arquivo de configuração de pacote que define um trabalho:
-
Na seção Recursos do pacote do painel Implantações , clique em Adicionar e, em seguida, em Nova definição de trabalho .
-
Digite um nome para o trabalho no campo Job name da caixa de diálogo Create Job definition (Criar definição de trabalho ). Clique em Criar .
-
Adicione o código YAML ao arquivo de definição de tarefa que foi criado. O exemplo de YAML a seguir define um Job que executa um Notebook:
YAMLresources:
jobs:
run_notebook:
name: run-notebook
queue:
enabled: true
tasks:
- task_key: my-notebook-task
notebook_task:
notebook_path: ../helloworld.ipynb
Para obter detalhes sobre como definir um Job em YAML, consulte Job. Para obter a sintaxe YAML para outros tipos de tarefas de Job compatíveis, consulte Adicionar tarefa ao Job em Pacotes de Automação Declarativa.
Nova definição pipeline
Se você habilitou o EditorLakeFlow Pipelines em seu workspace, consulte Novo pipeline ETL.
Para adicionar uma definição de pipeline ao seu pacote:
-
Na seção Recursos do pacote do painel Implantações , clique em Adicionar e, em seguida, em Nova definição pipeline .
-
Digite um nome para o pipeline no campo de nome do pipeline da caixa de diálogo Adicionar pipeline ao pacote existente .
-
Clique em Adicionar e instalado .
Para um pipeline com o nome test_pipeline que executa um Notebook, o seguinte YAML é criado em um arquivo test_pipeline.pipeline.yml:
resources:
pipelines:
test_pipeline:
name: test_pipeline
libraries:
- notebook:
path: ../test_pipeline.ipynb
serverless: true
catalog: main
target: test_pipeline_${bundle.environment}
Você pode modificar a configuração para executar um Notebook existente. Para obter detalhes sobre como definir um pipeline em YAML, consulte pipeline.
Novo pipeline ETL
Para adicionar uma nova definição de pipeline ETL:
-
Na seção Recursos do pacote do painel Implantações , clique em Adicionar e, em seguida, em Novo pipeline ETL .
-
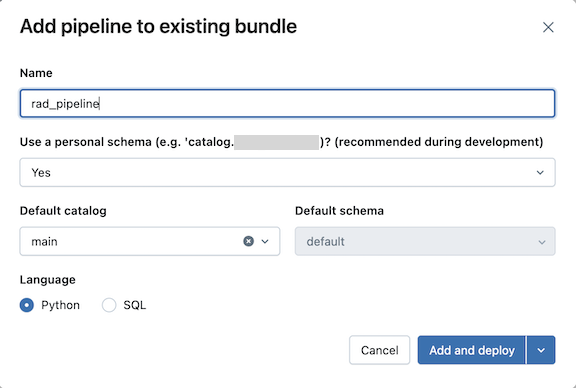
Digite um nome para o pipeline no campo Nome da caixa de diálogo Adicionar pipeline ao pacote existente . O nome deve ser único dentro do workspace.
-
No campo Usar esquema pessoal , selecione Sim para cenários de desenvolvimento e Não para cenários de produção.
-
Selecione um catálogo padrão e um esquema padrão para o site pipeline.
-
Escolha um idioma para o código-fonte do pipeline.
-
Clique em Adicionar e instalado .
-
Revise os detalhes na caixa de diálogo de confirmação de instalado para desenvolvimento e clique em instalado .
Um site ETL pipeline é criado com exemplos de tabelas de exploração e transformações.
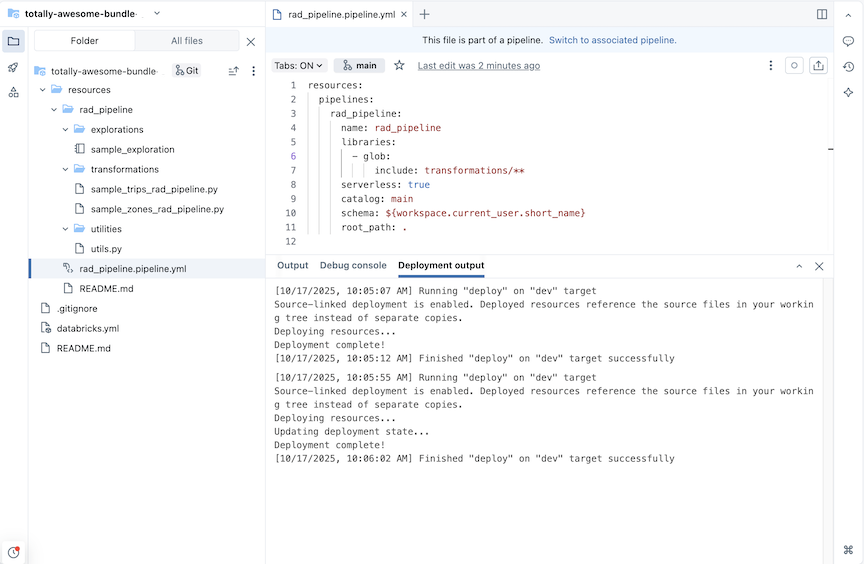
Para um pipeline com o nome rad_pipeline, o seguinte YAML é criado em um arquivo rad_pipeline.pipeline.yml. Este pipeline está configurado para execução em compute serverless . Para obter informações sobre a configuração do pipeline, consulte pipeline.
resources:
pipelines:
rad_pipeline:
name: rad_pipeline
libraries:
- glob:
include: transformations/**
serverless: true
catalog: main
schema: ${workspace.current_user.short_name}
root_path: .
Nova definição de painel de controle
Para criar um arquivo de configuração de pacote que defina um painel de controle:
-
Na seção Recursos do pacote do painel Implantações , clique em Adicionar e, em seguida, em Nova definição de painel .
-
Digite um nome para o painel no campo Nome do painel da caixa de diálogo Adicionar painel a um pacote existente .
-
Selecione um armazém para o painel de controle. Clique em Adicionar e implantar .
Um novo painel vazio e um arquivo de configuração *.dashboard.yml são criados no pacote. O painel de controle é armazenado no repositório especificado no arquivo de configuração.
Para obter detalhes sobre painéis, consulte Painéis. Para obter informações sobre a sintaxe YAML para configuração do painel de controle, consulte painel de controle.
Adicionar um recurso existente a um pacote
Você pode adicionar recursos existentes ao seu pacote usando a interface do usuário workspace ou adicionando a configuração de recursos ao seu pacote.
Use a interface de usuário workspace do pacote.
Para adicionar um Job, pipeline ou dashboard existente a um pacote:
- Navegue até a pasta do pacote no workspace onde você deseja adicionar um recurso.
Se o senhor já tiver aberto o pacote no editor em workspace, poderá usar a lista de contextos de criação do navegador workspace para navegar até a pasta do pacote. Consulte Contextos de criação.
-
À direita do nome do pacote, clique em Open in editor (Abrir no editor ) para navegar até o editor de pacotes view.
-
Clique no ícone de implantação do pacote para alternar para o painel Implantações.
-
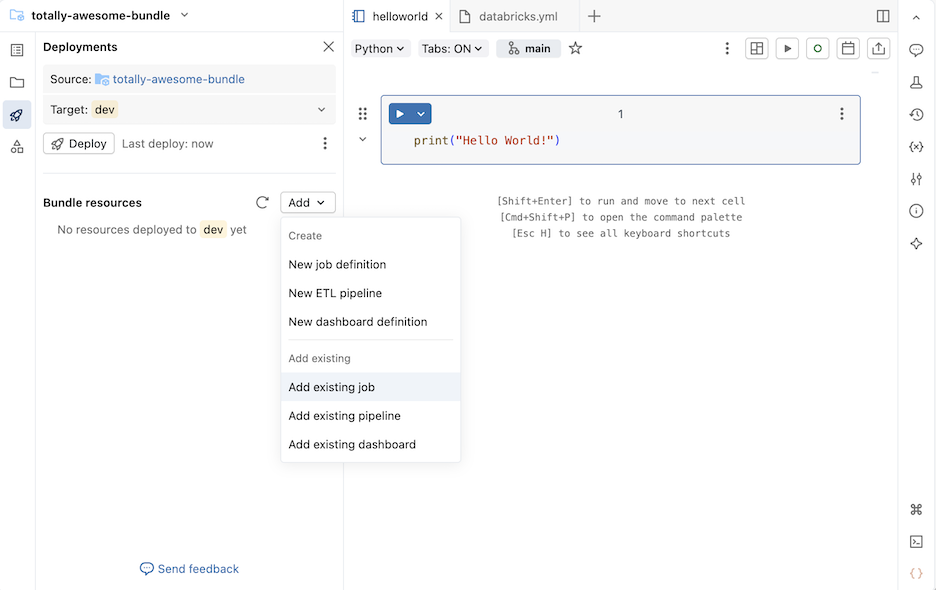
Na seção Agrupar recursos , clique em Adicionar e, em seguida, clique em Adicionar tarefa existente , Adicionar pipelineexistente ou Adicionar painel existente .
-
Na caixa de diálogo Adicionar recurso existente... , selecione o recurso existente na lista suspensa.
-
Ao adicionar um recurso existente a um pacote, o Databricks cria uma definição para esse recurso em um arquivo de configuração do pacote. Como você pode modificar essa definição no pacote, o recurso definido no pacote pode divergir do recurso usado para criá-lo.
Escolha uma opção para lidar com as atualizações na configuração do recurso do pacote:
- Atualização na implantação de produção : O recurso existente torna-se vinculado ao recurso no pacote e quaisquer alterações que você fizer no recurso no pacote são aplicadas ao recurso existente quando você implanta no destino
prod. - Atualização sobre o desenvolvimento implantado : O recurso existente torna-se vinculado ao recurso no pacote e quaisquer alterações que você fizer no recurso no pacote serão aplicadas ao recurso existente quando você implantar no destino
dev. - (Avançado) Não atualizar : O recurso existente não está vinculado ao pacote. As alterações feitas no recurso dentro do pacote nunca são aplicadas ao recurso existente. Em vez disso, é criada uma cópia. Para obter mais informações sobre o recurso de pacote configurável de ligação ao seu recurso workspace correspondente, consulte databricks bundle implantação bind.
- Atualização na implantação de produção : O recurso existente torna-se vinculado ao recurso no pacote e quaisquer alterações que você fizer no recurso no pacote são aplicadas ao recurso existente quando você implanta no destino
-
Clique em Adicionar... para adicionar o recurso existente ao pacote.
Adicionar configuração de pacote
Um recurso existente também pode ser adicionado ao seu pacote definindo a configuração do pacote para incluí-lo na sua implantação. O exemplo a seguir adiciona um pipeline existente a um pacote.
Supondo que o senhor tenha um pipeline chamado taxifilter que executa o taxifilter.ipynb Notebook em seu workspace compartilhado:
-
Na barra lateral do site Databricks workspace, clique em Jobs & pipeline .
-
Opcionalmente, selecione os filtros pipeline e Owned by me .
-
Selecione o pipeline
taxifilterexistente. -
Na página do pipeline, clique no botão à esquerda do botão Modo de implantação de desenvolvimento . Em seguida, clique em view settings YAML .
-
Clique no ícone de cópia para copiar a configuração do pacote para o pipeline.
-
Navegue até seu pacote no espaço de trabalho .
-
Clique no ícone de implantação do pacote para alternar para o painel Implantações.
-
Na seção Bundle recurso , clique em Adicionar e depois em Nova definição pipeline .
Se, em vez disso, você vir um item de menu Novo pipeline ETL , então o EditorLakeFlow Pipelines está habilitado. Para adicionar um pipeline ETL a um pacote, consulte Criar um pipeline controlado por origem.
-
Digite
taxifilterno campo de nome do pipeline da caixa de diálogo Adicionar pipeline ao pacote existente . Clique em Criar . -
Cole a configuração do pipeline existente no arquivo. Este exemplo pipeline é definido para executar o
taxifilterNotebook:YAMLresources:
pipelines:
taxifilter:
name: taxifilter
catalog: main
libraries:
- notebook:
path: /Workspace/Shared/taxifilter.ipynb
target: taxifilter_${bundle.environment}
Agora, o senhor pode implantar o pacote e, em seguida, executar o recurso pipeline por meio da UI.
Editar pacote de recursos
Beta
Este recurso está em versão Beta.
Você pode editar trabalhos e pipelines que fazem parte do seu pacote diretamente na interface do usuário workspace . As alterações são aplicadas automaticamente ao arquivo YAML de configuração para os recursos presentes no pacote.
Para editar um Job ou pipeline em um pacote:
- No painel Implantações do editor de pacotes, clique em Trabalho ou pipeline em Recurso de pacote para abrir o Trabalho ou pipeline.
- Faça alterações no trabalho ou pipeline, como adicionar uma tarefa de notebook ou alterar o esquema pipeline .
- Uma notificação workspace aparece confirmando que as edições feitas no Job ou pipeline foram aplicadas à configuração do pacote. Você pode clicar no link do arquivo YAML na notificação para view as alterações de configuração no editor de pacotes.
- Implante o pacote para que as alterações de configuração sejam aplicadas à implantação.
A edição de recursos está sempre desativada no modo de produção.
Limitações
As seguintes limitações se aplicam à edição de recursos no workspace:
- Ao editar um campo cujo valor provém de uma variável agrupada ou de uma substituição, a alteração atualiza apenas esse campo. Essa alteração não atualiza a definição da variável, portanto, outros campos que fazem referência à mesma variável não são afetados.
- A atualização das permissões de tarefas ainda não é suportada.
- Programar um pipeline ou dashboard cria um Job que inicia o recurso em um programar, mas o Job e pipeline ou dashboard associado não estão vinculados e o programar não é exibido na interface do usuário do pipeline ou dashboard. Para modificar o programa, edite o gatilho no trabalho que foi criado.