Práticas recomendadas de desenvolvimento no Databricks
Esta página fornece práticas recomendadas para a engenharia de dados e o ciclo de vida de desenvolvimento, incluindo controle de versão, gerenciamento de ambiente, ferramentas de desenvolvimento e implantações gerenciadas.
Controle do código-fonte
Controle de versão de todos os arquivos
A automação declarativa baseia-se na ideia de que, se algo não está em controle de versão, não existe. Portanto, o Databricks recomenda o controle de versão de quase todos os arquivos, incluindo:
- Todos os notebooks e arquivos de origem (
.py,.sql) - Arquivos de configuração do pacote (
databricks.ymle substituições de YAML específicos do ambiente)
No entanto, não realize o commit:
- Artefatos de build, como arquivos
.jarou.whl. Em vez disso, fazer upload de binários compilados para volumes do Unity Catalog durante o CI. Consulte upload de JAR. - Tokens ou credenciais. Use o gerenciamento de segredos no nível do workspace com suporte de um gerenciador de segredos da cloud (como AWS Secrets Manager ou Azure Key Vault) e sincronize valores em Secret Scopes do Databricks. Consulte Gerenciamento de segredos.
- Exemplos de dados locais e arquivos com PII. Use
.gitignorepara excluí-los.
Repositório único
A Databricks recomenda o uso de um único repositório para todo o código (código-fonte e arquivos de configuração), pois facilita a colaboração e o compartilhamento de código e de práticas recomendadas, tanto para humanos quanto para AI. Caso haja vários pacotes para ciclos de vida de deploy separados, eles devem ser mantidos em um único repositório.
A única exceção à recomendação de um único repositório é em indústrias reguladas onde múltiplos repositórios são necessários para fins de confidencialidade.
Estratégia de ramificação baseada em tronco
Para minimizar conflitos de merge e garantir que a branch principal esteja sempre em um estado implantável, recomenda-se usar uma estratégia de ramificação baseada em tronco.
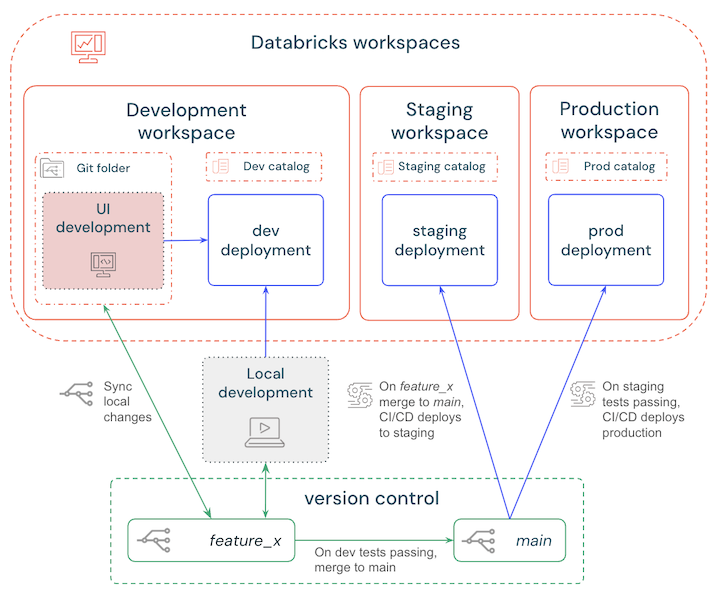
Um fluxo de trabalho simples seria:
- Desenvolva localmente ou no workspace e implante em um workspace de desenvolvimento do Databricks para testar as alterações.
- Crie um branch de recurso de curta duração para controle de versão de atualizações e sincronize regularmente suas alterações locais ou do workspace.
- Quando os testes forem concluídos, faça o merge da branch de recurso na branch principal.
- O CI/CD implanta automaticamente a ramificação principal em um workspace de preparação e os testes automatizados são acionados.
- Quando os testes e as verificações de staging são aprovados, o CI/CD implanta o branch principal em um workspace de produção.
Estes passos estão descritos no diagrama a seguir:
Configuração do workspace
Isolar ambientes do workspace
Isolar ambientes de workspace para minimizar o impacto de uma falha na implementação. Por exemplo:
- Pequenas equipes (até 5 engenheiros de dados) : Comece com dois workspaces (desenvolvimento e produção) em uma única conta cloud.
- Equipes em crescimento (mais de 5 engenheiros de dados) : Migrar para três workspaces (desenvolvimento, preparação e produção). O preparo deve ser funcionalmente representativo da produção — a mesma configuração de pacote, o mesmo esquema e as mesmas integrações críticas — mesmo que seja em menor escala.
- Indústrias regulamentadas (banco, saúde, defesa): Isolar fisicamente workspaces e accounts de cloud para evitar vazamento de dados. Gerenciar o isolamento por meio dos limites do IAM e do Unity Catalog em uma única account é possível, mas oferece uma postura de segurança menos robusta.
Para workspaces de produção, utilize compute serverless com políticas de rede sempre que possível. Caso contrário, configure cloud accounts para usar sub-redes privadas ou VNets com controles de saída rigorosamente controlados e controles de segurança de rede.
Para mais informações, consulte políticas de rede baseadas em contexto.
Isolamento do armazenamento de dados
- Use um único metastore do Unity Catalog e crie catálogos separados para desenvolvimento, staging (se aplicável) e produção, espelhando a disposição do seu workspace.
- Utilize esquemas pessoais para desenvolvedores individuais em catálogos de desenvolvimento e staging (não produção).
- Vincular o catálogo de produção no modo
ISOLATEDsomente ao workspace de produção. Definir o modo de isolamento de um catálogo paraISOLATEDgarante que os dados de produção sejam inacessíveis a partir de ambientes de desenvolvimento ou de preparação, mesmo que uma identidade esteja configurada incorretamente. - Reserve metastores, accounts ou regiões separadas apenas para organizações com requisitos regulatórios, de soberania de dados ou de múltiplas regiões que o isolamento em nível de catálogo não consegue satisfazer.
Tratar metadados de tabela e coluna como código
Considere os comentários de tabela e coluna como parte do código. Mantenha-os em .sql arquivos juntamente com suas definições de Pacotes de Automação Declarativa e implante-os por meio de um Job de metadados para que definições precisas e voltadas para os negócios estejam sempre disponíveis. Escreva comentários que descrevam o que uma linha representa, as unidades e os valores válidos em linguagem simples, em vez de repetir o nome da coluna.
Configurar esquemas pessoais
Durante o desenvolvimento, configure os pacotes para usar um esquema pessoal por usuário, p. ex. dev_${user_name}. Isso impede que os desenvolvedores substituam as tabelas uns dos outros em um workspace compartilhado.
Usar compute serverless
Use compute serverless para simplificar o gerenciamento de clusters e otimizar o custo. Consulte Conectar-se ao compute serverless.
Recomendações de CI/CD
Pacotes de Automação Declarativa para CI/CD
Os Bundles de Automação Declarativa (anteriormente conhecidos como Pacotes de Ativos do Databricks) oferecem uma abordagem poderosa e unificada para gerenciar código, fluxos de trabalho e infraestrutura dentro do ecossistema Databricks e são recomendados para seus pipelines de CI/CD.
Para obter detalhes adicionais sobre o uso de pacotes para fluxos de trabalho de CI/CD, consulte fluxos de trabalho de CI/CD no Databricks.
Para obter mais informações sobre Pacotes de Automação Declarativa, consulte O que são Pacotes de Automação Declarativa?
Use Terraform somente para recursos externos
Use o Terraform para definir os seguintes recursos:
- Recursos em cloud e externos
- Ações administrativas que usuários não privilegiados não devem realizar, como provisionamento de workspace ou configuração de rede da cloud.
Use Pacotes de Automação Declarativa para todos os outros recursos do Databricks.
Gerenciamento de pacotes
Criar pacotes pequenos
A Databricks recomenda o desenvolvimento de pacotes pequenos e focados em vez de um único pacote grande.
- Tudo o que uma única equipe possui deve ser agrupado em um só pacote.
- Testar e implantar por meio do mesmo pipeline CI/CD que compartilha o mesmo ciclo de vida e cadência de lançamento.
- Cada pacote deve cobrir todos os ambientes para um determinado projeto (desenvolvimento, preparação e produção) em vez de usar pacotes separados por ambiente.
Criar pacotes separados para:
- Diferentes produtos ou domínios, por exemplo, "analítica de faturamento" e "detecção de fraude"
- Diferentes limites de propriedade ou permissão
- Cargas de trabalho com ciclos de vida claramente diferentes
- Casos em que se necessita de promoção ou rollback independente.
Use sync.paths para sincronizar pastas compartilhadas
Ao gerenciar vários pacotes em um repositório, use sync.paths para sincronizar pastas compartilhadas de fora da raiz do pacote. Isso permite que projetos diferentes compartilhem uma pasta de biblioteca comum, como ../common, mantendo identidades de implantação separadas.
Modelar dependências entre pacotes em CI/CD
Quando o Pacote B depender de ativos publicados pelo Pacote A, modele essa dependência na sua camada de CI/CD ou orquestração, em vez de agrupar ambos em um único pacote.
- Defina o fluxo de trabalho de implantação e publicação do Pacote A como um pré-requisito explícito para o Pacote B. Conecte seu pipeline para que o Pacote B comece somente após a implantação do Pacote A ser bem-sucedida e todas as verificações de validação necessárias serem aprovadas.
- Passe os identificadores ou as localizações de ativos publicados como entradas do pipeline e falhe rapidamente se os ativos upstream estiverem ausentes. Isso garante que o Pacote B nunca seja implantado em um estado parcialmente publicado.
Para obter mais informações sobre o compartilhamento de pacotes, consulte Compartilhando Pacotes e Arquivos de Pacotes.
Modelos de pacotes personalizados
Use modelos personalizados de Pacotes de Automação Declarativa como o ponto de partida default para novos projetos, para que cada projeto herde as mesmas salvaguardas — permissões, tag, políticas de cluster, configuração de CI/CD e linhas de base de instância — sem que cada equipe tenha que resolver do zero.
Padrões devem codificar convenções compartilhadas e de longa duração, como governança, padrões de desempenho, disposição do ambiente e limites de cota. Evite lógica de negócios específica do aplicativo, segredos ou configuração avulsa em padrões.
Parametrizar apenas as entradas que se espera que variem por equipe, projeto ou ambiente:
- Projeto ou nome do aplicativo
- Configurações do workspace de destino
- Nomes de catálogo ou esquema
- Identificadores de entidade de serviço
- Cronogramas e configurações de notificação
Manter os guardrails da plataforma e os defaults compartilhados fixos no modelo, em vez de parametrizá-los.
Para obter informações sobre modelos de pacotes personalizados e como criá-los, consulte Declarative Automation Bundles project templates.
Planejar reversões e correções urgentes
Mantenha os bundles pequenos o suficiente para que seja possível fazer um rollback direcionado em um único bundle, em vez de coordenar um rollback entre muitas cargas de trabalho não relacionadas.
Durante um incidente:
- Reverter ou restaurar o pacote afetado para a última versão conhecida como boa.
- Deve-se usar um hotfix somente para correções urgentes, de escopo restrito, que não podem esperar pelo fluxo de promoção normal.
- Fazer merge de qualquer hotfix com a branch principal imediatamente após a validação para que o tronco permaneça a única fonte de verdade.
Desenvolvimento geral
Usar entidades de serviço ou OIDC
Use entidades de serviço para toda a automação não relacionada ao desenvolvimento, a fim de desacoplar fluxos de trabalho automatizados de contas de usuário individuais e garantir que os Jobs continuem sendo executados quando usuários internos saírem. See entidade de serviço.
- Usar entidades de serviço separadas para implantação e tempo de execução. Uma entidade de serviço de implantação dedicada para implantações de pacote deve ter acesso mínimo aos dados. Cada Job de produção ou pipeline deve ter sua própria entidade de serviço, cujo escopo seja restrito apenas aos dados e recursos que essa carga de trabalho exige. Essa separação garante que as implantações permaneçam seguras quando as permissões de acesso a dados são rotacionadas ou ajustadas, e evita o acoplamento de alterações na infraestrutura ao acesso a dados de produção.
- Indústrias regulamentadas : use a Federação de Identidades de Carga de Trabalho (OIDC) para CI/CD. Isso elimina segredos de longa duração no GitHub Actions ou no Azure DevOps. Consulte Habilitar federação de identidade de carga de trabalho em CI/CD.
Usar ferramentas de desenvolvedor do Databricks
Desenvolva na interface do usuário do workspace do Databricks usando Pastas do Git, ou em um IDE local. Caso utilize o Visual Studio Code ou um fork compatível, instale a extensão oficial do Databricks para:
- Habilidades do agente específicas do Databricks
- Acesso ao Unity Catalog e ao sistema de arquivos
- Recursos de desenvolvimento remoto para executar cargas de trabalho no Databricks compute
Para obter mais informações, consulte extensão do Databricks para Visual Studio Code.
Minimize a lógica de negócios em notebooks
Não se deve tratar notebooks como o principal contêiner para a lógica de negócios. Devem ser utilizados apenas para exploração e visualização.
- Python : Coloque a lógica principal em módulos
.pyimportáveis emsrc/ousrc/py/, e chame essas funções de notebooks. - SQL: Mantenha consultas em arquivos
.sqlemsrc/ousrc/sql/, e referencie esses arquivos de Job e pipeline em vez de incorporar SQL diretamente em Notebook.
Utilize notebooks apenas como camadas finas de orquestração e visualização que invocam o código subjacente. Essa abordagem facilita os testes e a reutilização.
Ao migrar um projeto que utiliza muitos Notebooks, realize-o de forma incremental. Extraia um módulo reutilizável ou arquivo SQL por vez e utilize os Pacotes de Automação Declarativa para incluir os ativos migrados no mesmo fluxo de trabalho de implantação e teste do restante do projeto.
Transmitir contexto dinamicamente
Evitar variáveis estáticas para dependências de tarefas. Use referências de valor dinâmico como {{tasks.<task_key>.values.<value_key>}} para passar contexto de tempo de execução entre tarefas em um job de várias etapas.
Testes e observabilidade
Implementando camadas de teste
Utilize três camadas de teste que correspondam à forma como seus pacotes avançam para a produção:
- Testes de unidade : Mantenha a lógica de negócios em módulos
src/importáveis e cubra-a compytestou um framework equivalente. Estes devem ser executados a cada solicitação pull para que falhas bloqueiem as mesclagens. - Validação do pacote : Execute
bundle validatelocalmente. No CI, prefirabundle deploypara um workspace de não produção para identificar problemas de YAML e mapeamento de recursos antes das implantações em produção. - Testes de integração na preparação: após a implantação na preparação, executar Jobs de ponta a ponta com verificações de completude e asserções críticas de qualidade de dados, como contagem de linhas ou expectativas de esquema.
Considerar "todos os testes passam no branch principal e em staging" como o portão para a promoção de artefatos para produção.
Para LakeFlow pipelines, use os recursos de desenvolvimento e validação integrados em vez de execuções ad-hoc de Notebook. Teste a lógica do pipeline com datasets pequenos e representativos que incluam registros com erros, e use o modo de desenvolvimento para validar as alterações antes de atualizar as tabelas de produção.
Considere o registro como parte da implantação
Para cargas de trabalho implantadas por Pacotes de Automação Declarativa, trate as métricas e o registro como parte do contrato de implantação, em vez de algo que cada projeto define de forma independente.
- Emitir logs estruturados de forma consistente em todos os jobs, pipelines e tarefas. É necessário incluir o nome do pacote, o ambiente de destino, o nome da carga de trabalho, o identificador de execução e qualquer identificador de negócios necessário para rastrear falhas.
- Acompanhe um conjunto padrão de métricas operacionais para cada carga de trabalho de produção: status de execução, duração, contagem de tentativas e taxa de transferência ou indicadores de atualização, quando relevante.
- Codifique essas convenções em bibliotecas compartilhadas, definições de carga de trabalho reutilizáveis ou padrões de pacote para que as equipes não precisem recriar padrões de observabilidade para cada projeto.