Preenchimento retroativo de dados históricos com oleoduto
Na engenharia de dados, backfilling refere-se ao processo de processamento retroativo de dados históricos por meio de um pipeline de dados que foi projetado para processar dados atuais ou de transmissão.
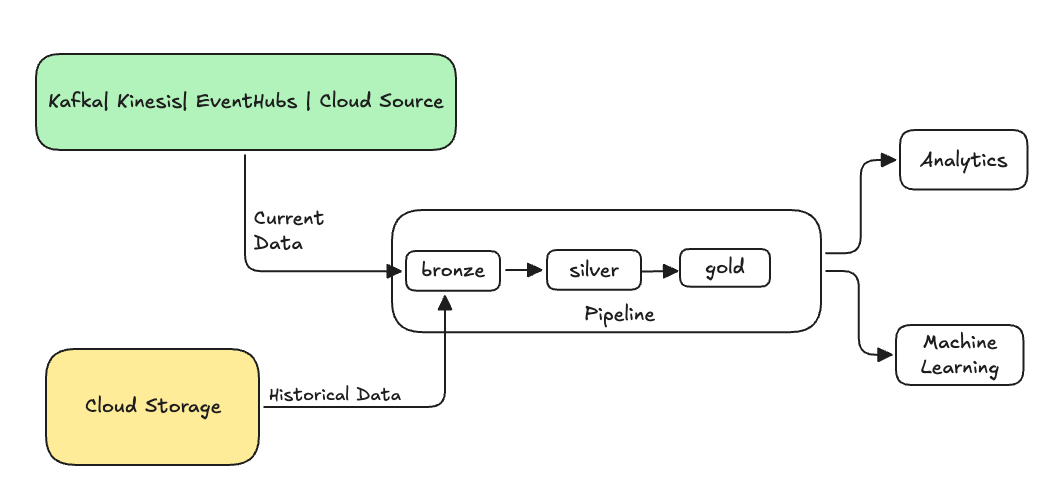
Normalmente, esse é um fluxo separado que envia dados para suas tabelas existentes. A ilustração a seguir mostra um fluxo de preenchimento enviando dados históricos para as tabelas de bronze no seu pipeline.
Alguns cenários que podem exigir um preenchimento:
- Processe dados históricos de um sistema legado para ensinar um modelo machine learning (ML) ou construir um painel de análise de tendências históricas.
- Reprocesse um subconjunto de dados devido a um problema de qualidade de dados com fonte de dados upstream.
- Seus requisitos de negócios mudaram e você precisa preencher dados para um período de tempo diferente que não foi coberto pelo pipeline inicial.
- Sua lógica de negócios mudou e você precisa reprocessar dados históricos e atuais.
O preenchimento de lacunas no pipeline LakeFlow Spark Declarative é suportado com um fluxo de anexação especializado que usa a opção ONCE . Consulte append_flow ou CREATE FLOW (pipeline) para obter mais informações sobre a opção ONCE .
Considerações ao preencher dados históricos em uma tabela de transmissão
- Normalmente, anexe os dados à tabela de transmissão de bronze. As camadas de prata e ouro a jusante coletarão os novos dados da camada de bronze.
- Garanta que seu pipeline possa lidar com dados duplicados com eficiência caso os mesmos dados sejam anexados várias vezes.
- Garanta que o esquema histórico de dados seja compatível com o esquema de dados atual.
- Considere o tamanho do volume de dados e o tempo de processamento necessário SLA) e configure adequadamente os tamanhos cluster e dos lotes.
Exemplo: Adicionar um aterro a um pipeline existente
Neste exemplo, digamos que você tenha um pipeline que ingere dados brutos de registro de eventos de uma fonte de armazenamento cloud , a partir de 1º de janeiro de 2025. Mais tarde, você percebe que deseja preencher os três anos anteriores de histórico de dados para casos de uso de relatórios e análises posteriores. Todos os dados estão em um local, particionados por ano, mês e dia, no formato JSON.
pipelineinicial
Este é o código pipeline inicial que ingere incrementalmente os dados brutos de registro de eventos do armazenamento cloud .
- Python
- SQL
from pyspark import pipelines as dp
source_root_path = spark.conf.get("registration_events_source_root_path")
begin_year = spark.conf.get("begin_year")
incremental_load_path = f"{source_root_path}/*/*/*"
# create a streaming table and the default flow to ingest streaming events
@dp.table(name="registration_events_raw", comment="Raw registration events")
def ingest():
return (
spark
.readStream
.format("cloudFiles")
.option("cloudFiles.format", "json")
.option("cloudFiles.inferColumnTypes", "true")
.option("cloudFiles.maxFilesPerTrigger", 100)
.option("cloudFiles.schemaEvolutionMode", "addNewColumns")
.option("modifiedAfter", "2025-01-01T00:00:00.000+00:00")
.load(incremental_load_path)
.where(f"year(timestamp) >= {begin_year}") # safeguard to not process data before begin_year
)
-- create a streaming table and the default flow to ingest streaming events
CREATE OR REFRESH STREAMING LIVE TABLE registration_events_raw AS
SELECT * FROM read_files(
"/Volumes/gc/demo/apps_raw/event_registration/*/*/*",
format => "json",
inferColumnTypes => true,
maxFilesPerTrigger => 100,
schemaEvolutionMode => "addNewColumns",
modifiedAfter => "2024-12-31T23:59:59.999+00:00"
)
WHERE year(timestamp) >= '2025'; -- safeguard to not process data before begin_year
Aqui usamos a opção modifiedAfter Auto Loader para garantir que não estamos processando todos os dados do caminho de armazenamento cloud . O processamento incremental é interrompido nesse limite.
Outras fontes de dados, como Kafka, Kinesis e Azure Event Hubs, têm opções de leitor equivalentes para atingir o mesmo comportamento.
Dados de preenchimento dos últimos 3 anos
Agora você deseja adicionar um ou mais fluxos para preencher dados anteriores. Neste exemplo, tomemos os seguintes passos:
- Use o fluxo
append once. Isso executa um preenchimento único sem continuar a execução após esse primeiro preenchimento. O código permanece no seu pipeline e, se o pipeline for totalmente atualizado, o backfill será reexecutado. - Crie três fluxos de preenchimento, um para cada ano (nesse caso, os dados são divididos por ano no caminho). No Python, parametrizamos a criação dos fluxos, mas no SQL repetimos o código três vezes, uma para cada fluxo.
Se você estiver trabalhando em seu próprio projeto e não estiver usando compute serverless , talvez seja necessário atualizar o número máximo de trabalhadores para o pipeline. Aumentar o número máximo de trabalhadores garante que você tenha o recurso para processar o histórico de dados enquanto continua a processar os dados de transmissão atuais dentro do SLA esperado.
Se você usar compute serverless com dimensionamento automático aprimorado (o default), seu cluster aumentará automaticamente de tamanho quando sua carga aumentar.
- Python
- SQL
from pyspark import pipelines as dp
source_root_path = spark.conf.get("registration_events_source_root_path")
begin_year = spark.conf.get("begin_year")
backfill_years = spark.conf.get("backfill_years") # e.g. "2024,2023,2022"
incremental_load_path = f"{source_root_path}/*/*/*"
# meta programming to create append once flow for a given year (called later)
def setup_backfill_flow(year):
backfill_path = f"{source_root_path}/year={year}/*/*"
@dp.append_flow(
target="registration_events_raw",
once=True,
name=f"flow_registration_events_raw_backfill_{year}",
comment=f"Backfill {year} Raw registration events")
def backfill():
return (
spark
.read
.format("json")
.option("inferSchema", "true")
.load(backfill_path)
)
# create the streaming table
dp.create_streaming_table(name="registration_events_raw", comment="Raw registration events")
# append the original incremental, streaming flow
@dp.append_flow(
target="registration_events_raw",
name="flow_registration_events_raw_incremental",
comment="Raw registration events")
def ingest():
return (
spark
.readStream
.format("cloudFiles")
.option("cloudFiles.format", "json")
.option("cloudFiles.inferColumnTypes", "true")
.option("cloudFiles.maxFilesPerTrigger", 100)
.option("cloudFiles.schemaEvolutionMode", "addNewColumns")
.option("modifiedAfter", "2024-12-31T23:59:59.999+00:00")
.load(incremental_load_path)
.where(f"year(timestamp) >= {begin_year}")
)
# parallelize one time multi years backfill for faster processing
# split backfill_years into array
for year in backfill_years.split(","):
setup_backfill_flow(year) # call the previously defined append_flow for each year
-- create the streaming table
CREATE OR REFRESH STREAMING TABLE registration_events_raw;
-- append the original incremental, streaming flow
CREATE FLOW
registration_events_raw_incremental
AS INSERT INTO
registration_events_raw BY NAME
SELECT * FROM STREAM read_files(
"/Volumes/gc/demo/apps_raw/event_registration/*/*/*",
format => "json",
inferColumnTypes => true,
maxFilesPerTrigger => 100,
schemaEvolutionMode => "addNewColumns",
modifiedAfter => "2024-12-31T23:59:59.999+00:00"
)
WHERE year(timestamp) >= '2025';
-- one time backfill 2024
CREATE FLOW
registration_events_raw_backfill_2024
AS INSERT INTO ONCE
registration_events_raw BY NAME
SELECT * FROM read_files(
"/Volumes/gc/demo/apps_raw/event_registration/year=2024/*/*",
format => "json",
inferColumnTypes => true
);
-- one time backfill 2023
CREATE FLOW
registration_events_raw_backfill_2023
AS INSERT INTO ONCE
registration_events_raw BY NAME
SELECT * FROM read_files(
"/Volumes/gc/demo/apps_raw/event_registration/year=2023/*/*",
format => "json",
inferColumnTypes => true
);
-- one time backfill 2022
CREATE FLOW
registration_events_raw_backfill_2022
AS INSERT INTO ONCE
registration_events_raw BY NAME
SELECT * FROM read_files(
"/Volumes/gc/demo/apps_raw/event_registration/year=2022/*/*",
format => "json",
inferColumnTypes => true
);
Esta implementação destaca vários padrões importantes.
Separação de preocupações
- O processamento incremental é independente das operações de preenchimento.
- Cada fluxo tem suas próprias configurações e configurações de otimização.
- Há uma distinção clara entre operações incrementais e de preenchimento.
Execução controlada
- Usar a opção
ONCEgarante que cada preenchimento seja executado exatamente uma vez. - O fluxo de preenchimento permanece no gráfico pipeline , mas se torna paradoxo após sua conclusão. Ele está pronto para uso na refresh completa, automaticamente.
- Há uma trilha de auditoria clara das operações de aterramento na definição do pipeline.
Otimização de processamento
- Você pode dividir o preenchimento grande em vários preenchimentos menores para um processamento mais rápido ou para controlar o processamento.
- Usando o dimensionamento automático aprimorado, escale dinamicamente o tamanho cluster com base na carga atual cluster .
evolução do esquema
- Usar
schemaEvolutionMode="addNewColumns"manipula alterações de esquema com elegância. - Você tem inferência de esquema consistente em dados históricos e atuais.
- Há um tratamento seguro de novas colunas em dados mais recentes.