Use a Extração de Informações (legado)
Beta
Este recurso está em Beta. Os administradores de workspace podem controlar o acesso a este recurso na página **Pré-visualizações**. Consulte Gerenciar prévias do Databricks.
Esta página aborda a versão antiga da Extração de Informações. A Databricks recomenda usar a versão mais recente. Consulte Extração de Informações.
Esta página descreve como criar um agente de AI generativa para extração de informações usando a Extração de Informações.
O que é Extração de Informação?
A Extração de Informações suporta a extração de informações e simplifica o processo de transformar um grande volume de documentos de texto não rotulados em uma tabela estruturada com informações extraídas para cada documento.
Exemplos de extração de informações incluem:
- Extraindo preços e informações de aluguel de contratos.
- Organizando dados a partir de notas de clientes.
- Obtenção de detalhes importantes de artigos de notícias.
Extração de Informações utiliza recursos de avaliação automatizada, incluindo MLflow e Agent Evaluation, para permitir uma avaliação rápida da compensação custo-qualidade para sua tarefa de extração específica. Esta avaliação permite tomar decisões informadas sobre o equilíbrio entre precisão e investimento de recursos.
Extração de Informação usa armazenamento default para armazenar transformações de dados temporários, pontos de verificação de modelo e metadados internos que alimentam cada agente. Ao excluir o agente, todos os dados associados ao agente são removidos do armazenamento default.
Requisitos
-
Um workspace que inclui o seguinte:
- Serverless compute disponível (ativado por default em workspace com Unity Catalog).
- Unity Catalog ativado. Consulte Ativar um workspace para o Unity Catalog.
- Acesso a modelos de base no Unity Catalog por meio do esquema
system.ai. - Acesso a uma política de uso serverless com um orçamento diferente de zero.
-
Um workspace em uma das regiões suportadas.
-
Capacidade de usar a função SQL
ai_query. -
Arquivos para extração de dados. Os arquivos devem estar em um volume ou tabela do Unity Catalog.
- Caso queira usar PDFs, converta-os primeiro para uma tabela do Unity Catalog. Consulte Usar PDFs na Extração de Informações.
- Para construir seu agente, você precisa de pelo menos 1 documento não rotulado em seu volume do Unity Catalog ou 1 linha em sua tabela.
Criar um agente de extração de informação
Vá para ![]() Agentes no painel de navegação esquerdo do seu workspace. No bloco Extração de Informações , clique em Build .
Agentes no painel de navegação esquerdo do seu workspace. No bloco Extração de Informações , clique em Build .
O passo 1: Configure seu agente
Configure seu agente:
-
No campo Nome , insira um nome para seu agente.
-
Selecione o tipo de dados que deseja fornecer. Você pode escolher entre **Dataset sem rótulo** ou **Dataset com rótulo**.
-
Selecione o dataset a ser fornecido.
- Unlabeled dataset
- Labeled dataset
Se você selecionar o **dataset sem rótulo**:
-
No campo Local do dataset , selecione a pasta ou tabela que você deseja usar do seu volume do Unity Catalog. Se uma pasta for selecionada, ela deve conter documentos em um formato de documento compatível.
O seguinte é um volume de exemplo:
/Volumes/main/info-extraction/bbc_articles/ -
Se você estiver fornecendo uma tabela, selecione a coluna que contém seus dados de texto no dropdown. A coluna da tabela deve conter dados em um formato de dados compatível.
Caso queira usar PDFs, converta-os primeiro para uma tabela do Unity Catalog. Consulte Usar PDFs na Extração de Informações.
-
A Extração de Informações infere e gera automaticamente uma saída JSON de exemplo contendo dados extraídos do seu dataset no campo Saída JSON de exemplo . Você pode aceitar a saída de exemplo, editá-la ou substituí-la por um exemplo de sua saída JSON desejada. O agente retorna informações extraídas usando este formato.
Se você selecionar Dataset rotulado :
- No campo dataset de verdades fundamentais , selecione a tabela do Unity Catalog que contém seus dados de verdade fundamental.
- No campo Coluna de entrada , selecione a coluna que contém o texto que o agente deve processar. Os dados nesta coluna devem estar no formato
str. - No campo Coluna de resposta de verdade fundamental , selecione a coluna que contém as respostas ideais esperadas. Os dados nesta coluna devem ser uma strings JSON. Cada linha nesta coluna deve seguir o mesmo formato JSON. Linhas que contêm key adicionais ou ausentes não são aceitáveis.
- No campo **Saída JSON de exemplo**, a Extração de Informações gera automaticamente uma saída JSON de exemplo usando a primeira linha de dados da coluna de resposta de verdade fundamental. Verifique se esta saída JSON corresponde ao formato esperado.
-
Verifique se o campo **Sample JSON output** corresponde ao formato de resposta desejado. Edite conforme necessário.
Por exemplo, o seguinte exemplo de saída JSON pode ser usado para extrair informações de um conjunto de artigos de notícias:
JSON{
"title": "Economy Slides to Recession",
"category": "Politics",
"paragraphs": [
{
"summary": "GDP fell by 0.1% in the last three months of 2004.",
"word_count": 38
},
{
"summary": "Consumer spending had been depressed by one-off factors such as the unseasonably mild winter.",
"word_count": 42
}
],
"tags": ["Recession", "Economy", "Consumer Spending"],
"estimate_time_to_read_min": 1,
"published_date": "2005-01-15",
"needs_review": false
} -
Em Escolha do modelo , selecione o melhor modelo para seu agente de extração de informações:
- **Otimizar para Escala** (default): Escolha esta opção se você estiver processando grandes volumes de dados ou preferir um agente de custo-benefício. Este modelo é projetado para alta Taxa de transferência e tempo de resposta mais rápido e é adequado para a maioria das tarefas de extração de informação.
- **Otimizar para Complexidade**: Escolha esta opção se precisar de raciocínio complexo e priorizar a precisão em relação à velocidade e ao custo. Este modelo oferece maiores capacidades de raciocínio para documentos mais longos (como demonstrações financeiras) e pode lidar com extrações mais complexas (como a extração de mais de 40 campos de esquema).
-
Clique em **Criar agente**.
Formatos de documento compatíveis
A tabela a seguir mostra os tipos de arquivo de documento compatíveis para seus documentos de origem se você fornecer um volume do Unity Catalog.
Arquivos de código | Arquivos de documento | Arquivos de log |
|---|---|---|
|
|
|
Formatos de dados suportados
Extração de informações oferece suporte aos seguintes tipos de dados e esquemas para seus documentos de origem se você fornecer uma tabela do Unity Catalog. Extração de informações também pode extrair estes tipos de dados de cada documento.
strintfloatbooleanenum(usado para tarefas de classificação onde o agente deve selecionar apenas de categorias predefinidas)- Objeto
- Arrays
enum (adequado para tarefas de classificação onde queremos que o agente gere saída apenas de um conjunto de categorias predefinidas) object (no lugar de "campos aninhados personalizados") array
O passo 2: Aprimore seu agente
Na **tab** de **Build**, revise os exemplos de saída para ajudar a refinar sua definição de esquema e adicionar instruções para melhores resultados.
-
À esquerda, analise as respostas de exemplo e forneça feedback para ajustar o agente. Estas amostras são baseadas na configuração atual do agente.
- Clique em uma linha para revisar a entrada e a resposta completas.
- Na parte inferior, ao lado de A resposta está correta?, forneça feedback selecionando
 Sim ou
Sim ou  Corrigir. Para feedback de Corrigir, forneça detalhes adicionais sobre como o agente deve mudar sua resposta e então clique
Corrigir. Para feedback de Corrigir, forneça detalhes adicionais sobre como o agente deve mudar sua resposta e então clique  em Salvar.
em Salvar. - Depois de terminar de revisar todas as respostas, clique em Sim, atualizar agente . Ou, você pode clicar em Salvar feedback e atualizar após revisar pelo menos três respostas.
-
À direita, em Campos de saída , refine as descrições dos campos do seu esquema de extração. Essas descrições são nas quais o agente se baseia para entender o que você deseja extrair. Use os exemplos de respostas à esquerda para ajudar a refinar a definição do esquema.
- Para cada campo, revise e edite a definição do esquema conforme necessário. Use as respostas de amostra à esquerda para ajudar a refinar essas descrições.
- Para editar o nome e o tipo do campo, clique em
 Editar campo .
Editar campo . - Para adicionar um novo campo, clique em
 Adicionar novo campo . Insira o nome, tipo e descrição e clique em Confirmar .
Adicionar novo campo . Insira o nome, tipo e descrição e clique em Confirmar . - Para remover um campo, clique
 em ** Remover campo**.
em ** Remover campo**. - Clique em Salvar e atualizar para atualizar a configuração do seu agente.
-
(Opcional) À direita, em **Instruções**, insira quaisquer instruções globais para o seu agente. Estas instruções se aplicam a todos os elementos extraídos. Clique em **Salvar e atualizar** para aplicar as instruções.
-
Novas respostas de amostra são geradas no lado esquerdo. Analise estas respostas atualizadas e continue a refinar a configuração do seu agente até que as respostas sejam satisfatórias.
O passo 3: Use seu agente
Você pode usar seu agente em fluxos de trabalho no Databricks.
Para começar a usar seu agente, clique em Usar . Você pode optar por usar seu agente de várias maneiras:
- Extração de dados para todos os documentos : Clique em Começar extração para abrir o editor SQL e use
ai_querypara enviar solicitações ao seu novo agente de extração de informação. - Criar pipeline ETL : Clique em Criar pipeline para implantar um pipeline que seja executado em intervalos programados para invocar seu agente com novos dados. Consulte Spark Declarative Pipelines para obter mais informações sobre pipelines.
- Teste seu agente : Clique em Abrir no Playground para experimentar seu Agente em um ambiente de teste para ver como ele funciona. Consulte Converse com LLMs e prototipe aplicativos de AI generativa usando o AI Playground para saber mais sobre o AI Playground.
(Opcional) O passo 4: Avalie seu agente
Para garantir que você construiu um agente de alta qualidade, faça uma execução de avaliação e revise o relatório de qualidade resultante.
-
Mude para a tab Qualidade .
-
Clique em
Execução da avaliação . -
No painel **Nova avaliação** que desliza para fora, configure a avaliação:
- Selecione o nome da execução de avaliação. Você pode optar por usar um nome gerado ou fornecer um nome personalizado.
- Selecione o dataset de avaliação. É possível escolher usar o mesmo dataset de origem utilizado para criar seu agente ou fornecer um dataset de avaliação personalizado utilizando dados com ou sem rótulo.
-
Clique em Começar avaliação .
-
Após a conclusão da execução da sua avaliação, revise o relatório de qualidade:
-
Uma view de **Summary** é exibida por default. Analise a qualidade geral, o custo, a taxa de transferência e o relatório resumido das métricas de avaliação. Clique em
 ao lado do campo do esquema para ver como esse campo é avaliado.
ao lado do campo do esquema para ver como esse campo é avaliado.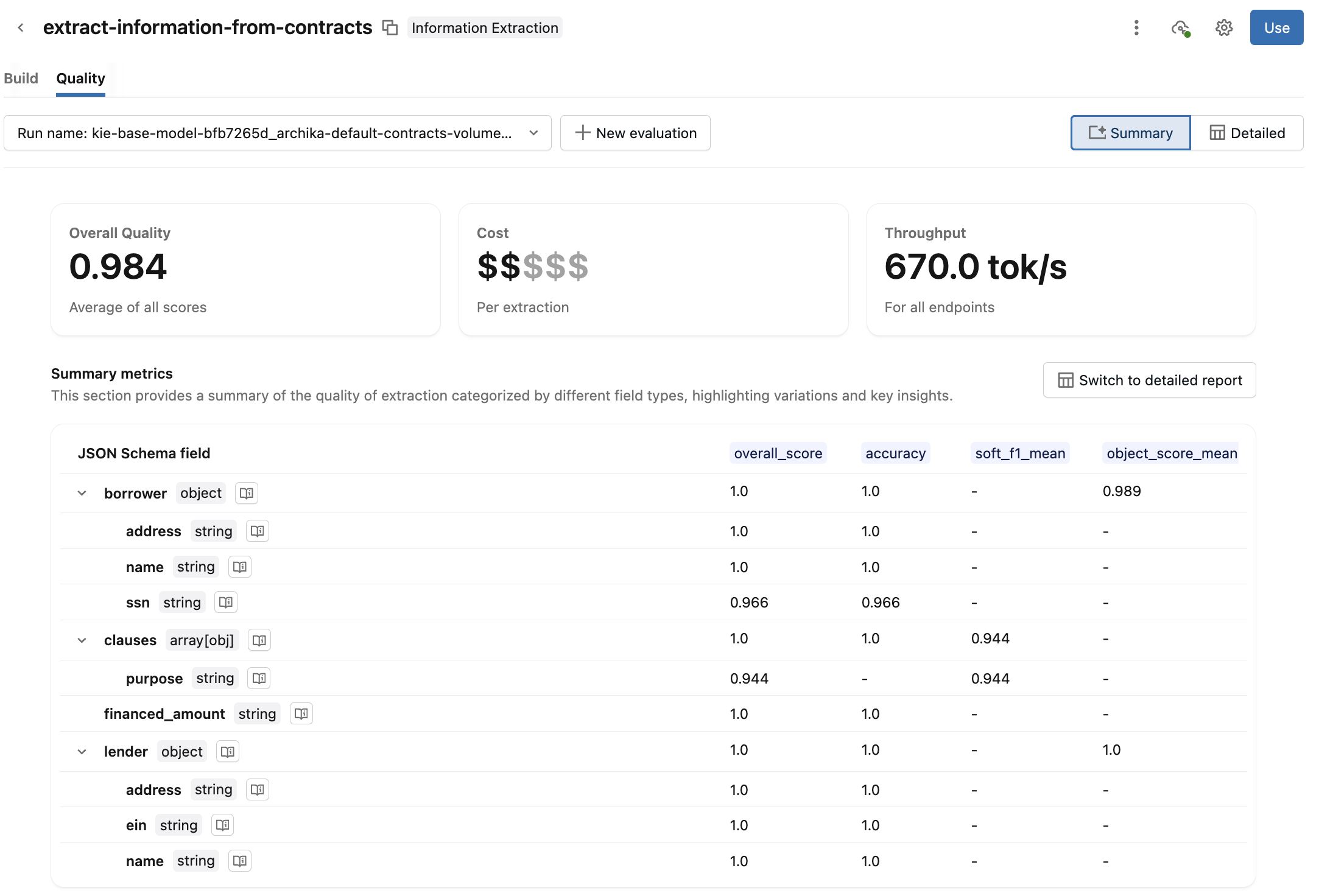
-
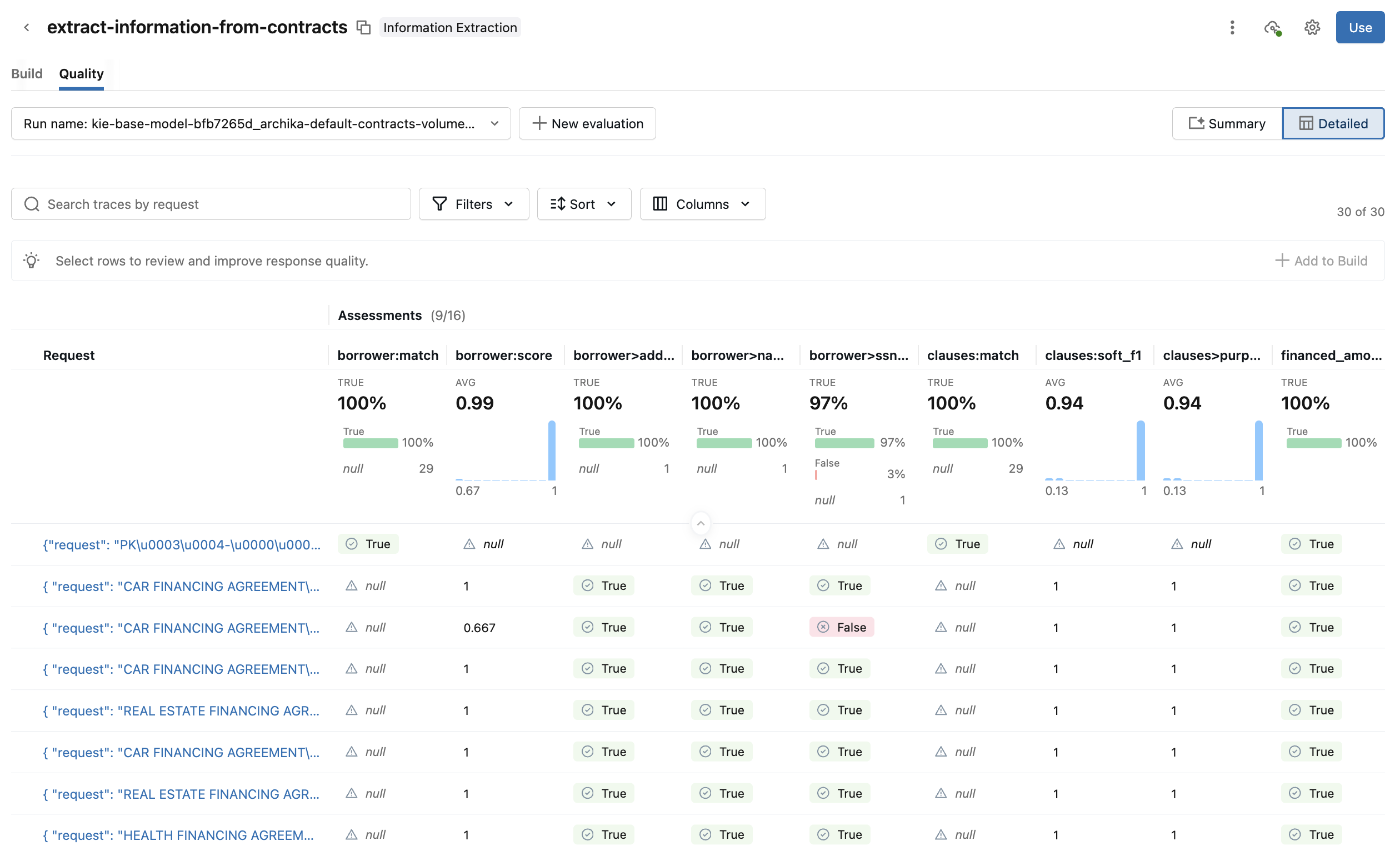
Mude para a view **Detalhada** para detalhes adicionais. Esta view mostra cada solicitação e a pontuação da avaliação para cada métricas. Clique em uma solicitação para ver detalhes adicionais, tais como a entrada, a saída, as avaliações, os rastreamentos e os prompts vinculados. É possível também editar as avaliações da solicitação e fornecer feedback adicional.
-
Consultar o endpoint do agente
Na página do agente, clique em ![]() Ver status do agente no canto superior direito para obter o endpoint do agente implantado e ver os detalhes do endpoint.
Ver status do agente no canto superior direito para obter o endpoint do agente implantado e ver os detalhes do endpoint.
Há várias maneiras de consultar o endpoint do agente criado. Use os exemplos de código fornecidos no AI Playground como ponto de partida:
- Na página do agente, clique em **Usar**.
- Clique em Abrir no playground .
- No Playground, clique em Obter código .
- Escolha como você deseja usar o endpoint:
- Selecione Aplicar em dados para criar uma consulta SQL que aplica o agente a uma coluna de tabela específica.
- Selecione Curl API para obter um exemplo de código para consultar o endpoint usando curl.
- Selecione API Python para um exemplo de código para interagir com o endpoint usando Python.
Gerenciar permissões
Por default, somente autores de agentes e administradores de workspace têm permissões para o agente. Para permitir que outros usuários editem ou consultem o agente, é necessário conceder permissão explicitamente.
Para gerenciar permissões no seu agente:
-
Abra o agente na página **Agentes**.
-
Na parte superior, clique no menu kebab
 .
. -
Clique em Gerenciar permissões .
-
Na janela **Configurações de permissão**, selecione o usuário, grupo ou entidade de serviço.
-
Selecione a permissão a conceder:
- Pode Gerenciar : Permite gerenciar o agente, incluindo a configuração de permissões, a edição da configuração do agente e a melhoria da sua qualidade.
- Pode Consultar : Permite consultar o endpoint do agente no AI Playground e por meio da API. Usuários com apenas esta permissão não podem view ou editar o agente na página Agentes.
-
Clique em Adicionar .
-
Clique em Salvar .
Para endpoints de agente criados antes de 16 de setembro de 2025 , é possível conceder permissões de Pode Consultar ao endpoint na página de Serving endpoints .
Use PDFs na Extração de informações
PDFs ainda não são compatíveis nativamente na Extração de Informações e no LLM Personalizado. No entanto, você pode usar o fluxo de trabalho da UI para converter uma pasta de arquivos PDF em markdown e, em seguida, usar a tabela resultante do Unity Catalog como entrada ao criar seu agente. Este fluxo de trabalho usa ai_parse_document para a conversão. Siga os passos:
-
Clique em **Agentes** no painel de navegação esquerdo.
-
Nos casos de uso de Extração de Informações ou LLM Personalizado, clique em **Usar PDFs**.
-
No painel lateral que se abre, insira os seguintes campos para criar um novo fluxo de trabalho para converter seus PDFs:
- Selecionar pasta com PDFs ou imagens : Selecione a pasta do Unity Catalog contendo os PDFs que você deseja usar.
- Selecionar tabela de destino : Selecione o esquema de destino para a tabela markdown convertida e, opcionalmente, ajuste o nome da tabela no campo abaixo.
- Selecione o SQL warehouse ativo : Selecione o SQL warehouse para executar o fluxo de trabalho.
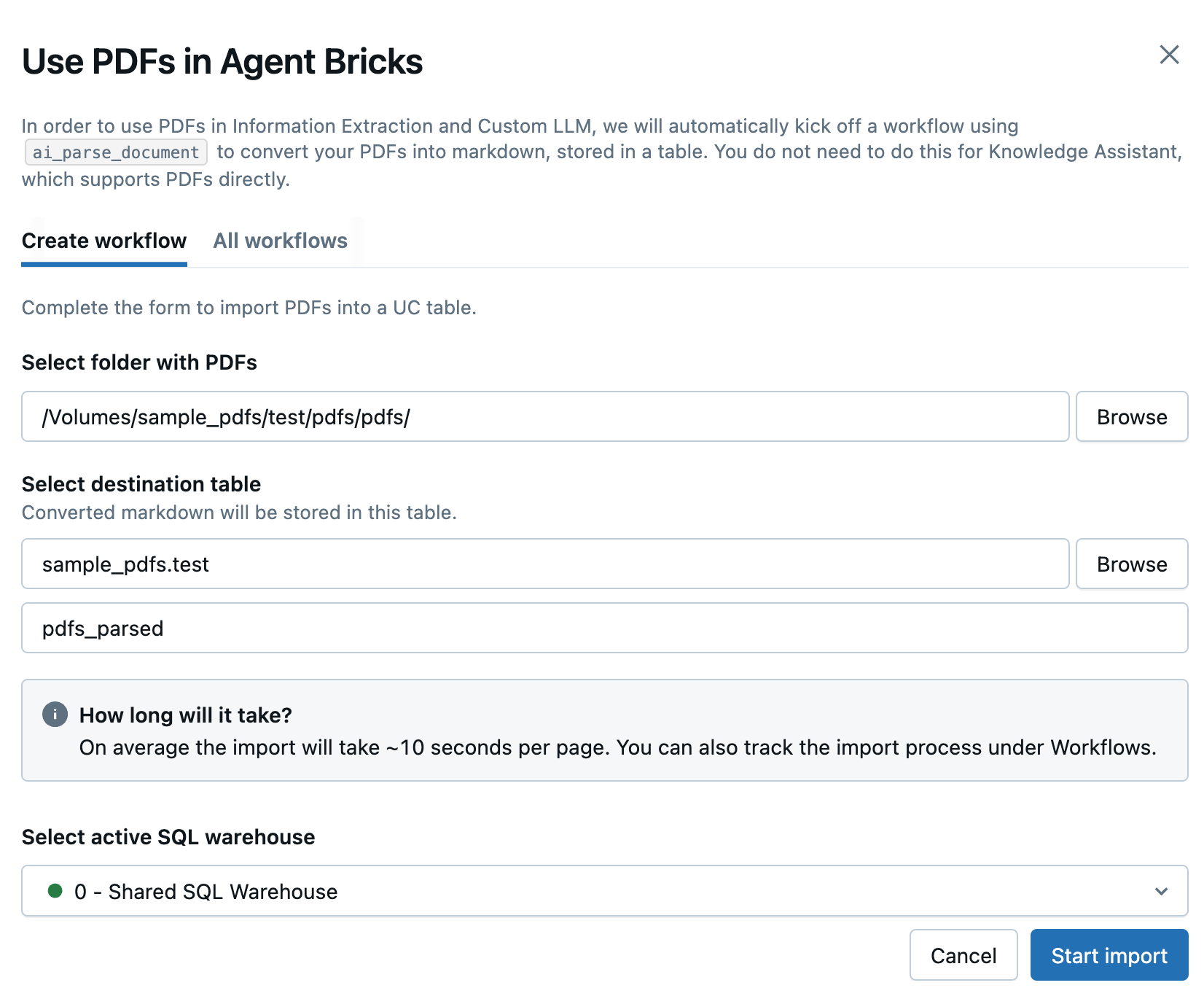
-
Clique em Começar importação .
-
Você será redirecionado para a tab **Todos os fluxos de trabalho**, que lista todos os seus fluxos de trabalho em PDF. Use esta tab para monitorar o status de seus Job.
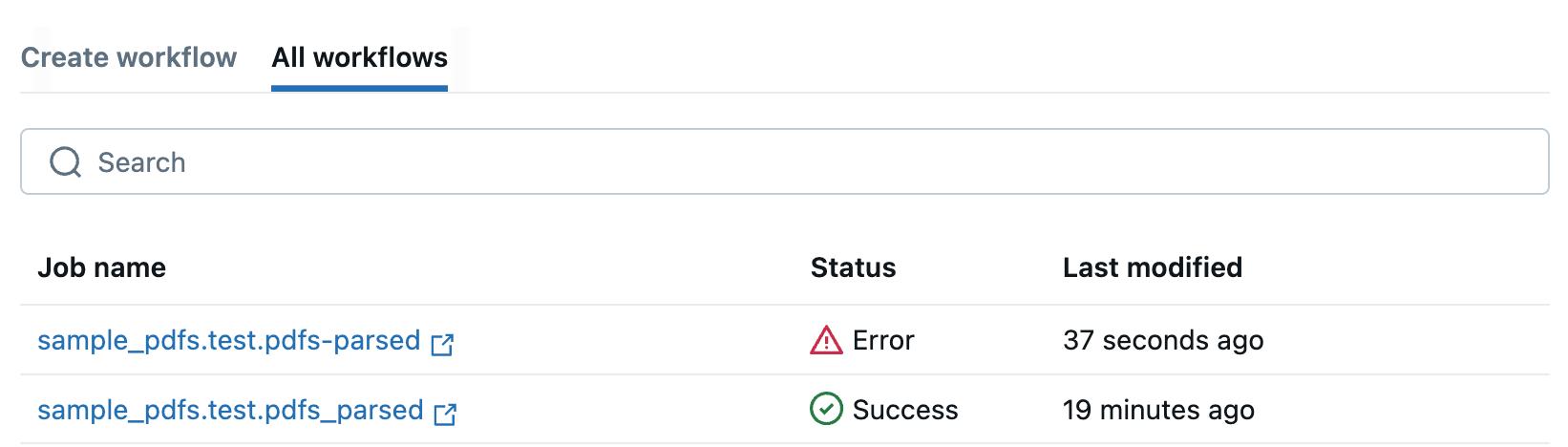
Se seu fluxo de trabalho falhar, clique no nome do Job para abri-lo e view as mensagens de erro para auxiliar na depuração.
-
Quando seu fluxo de trabalho for concluído com sucesso, clique no nome do Job para abrir a tabela no Catalog Explorer para explorar e entender as colunas.
-
Use a tabela do Unity Catalog como dados de entrada ao configurar seu agente.
Limitações
- Agentes de extração de informações têm um comprimento máximo de contexto de 128 mil tokens.
- Workspaces que têm Segurança e Compliance Aprimorados habilitados não são suportados.
- Tipos de esquema de união não são suportados.