Faça um teste de carga no seu agente do Databricks Apps.
O teste de carga determina o número máximo de consultas por segundo (QPS) que o agente do Databricks Apps pode suportar antes que o desempenho seja afetado. Esta página mostra como fazer o seguinte:
- implementou uma versão simulada do seu agente para isolar a taxa de transferência da infraestrutura da latência LLM .
- Execução de um teste de carga de rampa até a saturação com o Locust.
- Analise os resultados com um painel interativo.
Você pode seguir o caminho assistido AIusando uma habilidade do Claude Code ou configurar cada passo manualmente.
Requisitos
- Um workspace Databricks com Databricks Apps ativados.
- Um aplicativo de agente implantado (ou pronto para implantação) no Databricks Apps usando o SDK de Agentes OpenAI , o LangGraph ou uma estrutura personalizada. Veja Criar um agente AI e implantá-lo em Databricks Apps.
- A CLI do Databricks foi instalada e autenticada. Consulte Instalar ou atualizar a CLI do Databricks.
- Python 3.10+ com gerenciador de pacotes
uv. - (Para o caminho assistido AI ) Código Claude instalado.
- (Para testes de carga com duração superior a ~1 hora) A entidade de serviço com credenciais M2M OAuth (
client_ideclient_secret). Consulte Autorizar o acesso da entidade de serviço ao Databricks com OAuth.- Para testes de carga curtos (menos de ~1 hora), suas credenciais OAuth de usuário existentes (U2M) de
databricks auth loginfuncionam bem. Para testes mais longos, use M2M OAuth com uma entidade de serviço Databricks — tokens U2M expiram durante uma execução longa e causam falhas no meio do teste. A criação de uma entidade de serviço Databricks requer acesso de administrador workspace .
- Para testes de carga curtos (menos de ~1 hora), suas credenciais OAuth de usuário existentes (U2M) de
Configuração assistidaAI(recomendada)
Se você usa o Claude Code, a habilidade /load-testing automatiza o fluxo de trabalho. Ele lê o código do seu agente, gera um mock, cria scripts de teste de carga e orienta você durante a implantação.
Diga ao Claude Code para fazer isso por você:
Clone https://github.com/databricks/app-templates and run the /load-testing skill against the {your-template} template.
Ou siga os passos abaixo.
o passo 1: Clonar um agente padrão
A habilidade /load-testing está incluída no repositório databricks/app-padrão , tanto como a habilidade agent-load-testing de nível superior quanto pré-sincronizada em cada padrão de agente individual. Se você já tem um projeto de app-templates, você já tem a habilidade.
Clone o repo e acesse o diretório padrão do agente que você deseja testar:
git clone https://github.com/databricks/app-templates.git
cd app-templates/{your-template}
o passo 2: execução da habilidade de teste de carga
Em Claude Code, execução:
/load-testing
A skill guia você interativamente pelos seguintes passos. Você pode pular a etapa de simulação para testar seu agente real ou pular a implantação se seus aplicativos já estiverem em execução.
- Coletando parâmetros : solicita informações sobre o status da sua implantação, tamanhos compute , configurações worker e credenciais OAuth .
- Criação de scripts de teste de carga : gera
locustfile.py,run_load_test.pyedashboard_template.pyadaptados ao seu projeto. - Simulação do seu LLM : cria um cliente simulado específico para o seu SDK (OpenAI Agents SDK, LangGraph ou personalizado) que substitui as chamadas reais LLM por atrasos de transmissão configuráveis.
- Aplicativos de teste implantados : guia você na implantação de várias configurações de aplicativos com diferentes tamanhos compute e número worker .
- Executando testes : executa o teste de carga com autenticação M2M OAuth e rampa até a saturação.
- Geração de resultados : produz um painel HTML interativo com métricas de QPS, latência e falhas.
Configuração manual
Siga estes passos para configurar e executar testes de carga sem assistência AI .
Passo 1: Simule as ligações LLM do seu agente (opcional)
Ignore esta etapa se quiser resultados de ponta a ponta que incluam a latência real LLM . Para medir a taxa de transferência da infraestrutura Databricks Apps de forma isolada, simule o LLM para que sua latência por solicitação (normalmente de 1 a 30 segundos) não se torne o gargalo.
Um mock retorna respostas predefinidas com um atraso de transmissão configurável, preservando todo o pipeline de solicitação/resposta (transmissão SSE, despacho de ferramentas, executor SDK ) e substituindo apenas o LLM. Isso revela o QPS máximo que a plataforma Databricks Apps pode fornecer e evita custos com tokens da API do Foundation Model durante os testes de carga.
O tempo simulado é controlado por duas variáveis de ambiente:
Variável | Padrão | Descrição |
|---|---|---|
|
| Atraso em milissegundos entre os blocos de texto da transmissão |
|
| Número de blocos de texto por resposta |
Com a configuração padrão, cada resposta simulada leva aproximadamente 800 ms (10 ms x 80 blocos), significativamente mais rápido do que uma resposta real LLM (3 a 15 segundos). Os números de taxas de transferência refletem então a plataforma, não o modelo.
Crie um cliente fictício que substitua o cliente real do curso de mestrado em Direito (LLM). O restante do código do seu agente permanece inalterado, e a abordagem depende do seu SDK. Para OpenAI, veja a implementação de referênciamock_openai_client.py em databricks/app-templates. O mesmo padrão se adapta a outros SDKs.
- OpenAI Agents SDK
- LangGraph
- Custom agents
Crie agent_server/mock_openai_client.py — uma classe MockAsyncOpenAI que implementa chat.completions.create() com transmissões. Ele retorna instantaneamente blocos de chamadas de ferramentas (simulando o LLM decidindo chamar uma ferramenta) e blocos de resposta de texto com atraso configurável de MOCK_CHUNK_DELAY_MS e MOCK_CHUNK_COUNT variáveis de ambiente.
Troque-o pelo seu agente:
from agent_server.mock_openai_client import MockAsyncOpenAI
from agents import set_default_openai_client, set_default_openai_api
set_default_openai_client(MockAsyncOpenAI())
set_default_openai_api("chat_completions")
O restante do código do seu agente (manipuladores, ferramentas, lógica de transmissão) permanece inalterado.
Substitua o modelo ChatDatabricks por um mock que retorne objetos AIMessage pré-construídos:
# Before:
# model = ChatDatabricks(endpoint="databricks-claude-sonnet-4")
# After:
from agent_server.mock_llm import MockChatModel
model = MockChatModel()
O mock deve retornar objetos AIMessage com chamadas de ferramentas na primeira invocação e conteúdo de texto nas invocações subsequentes, com atrasos de transmissão configuráveis.
Envolva quaisquer chamadas de API externas que seu agente faz (LLM, Pesquisa de IA, APIs de ferramentas) com implementações simuladas que retornem formas de resposta realistas com atrasos configuráveis.
o passo 2: Configurar scripts de teste de carga
Crie um diretório load-test-scripts/ em seu projeto. A estrutura de teste de carga consiste em três scripts independentes de framework e que funcionam com qualquer agente do Databricks Apps.
<project-root>/
agent_server/ # Your existing agent code
load-test-scripts/ # Load testing scripts (create this)
run_load_test.py # CLI orchestrator
locustfile.py # Locust test with SSE streaming + TTFT tracking
dashboard_template.py # Interactive HTML dashboard generator
load-test-runs/ # Results (auto-created per run)
<run-name>/
dashboard.html # Interactive dashboard
test_config.json # Test parameters for reproducibility
<label>/ # Per-config Locust CSV output
A estrutura inclui os seguintes arquivos:
locustfile.py: Um teste de carga Locust que enviaPOST /invocationssolicitações comstream: true, analisa transmissões SSE, rastreia o tempo até os primeiros tokens (TTFT) como uma métrica personalizada, usa troca de tokens M2M OAuth comrefresh automática e implementa umStepRampShapeque aumenta gradualmente os usuários destep_sizeparamax_usersenquanto mantém cada nível porstep_durationsegundos.run_load_test.py: Um orquestrador de CLI que testa cada URL de aplicativo sequencialmente com métricas isoladas por configuração. Ele lida com refresh de tokens OAuth , execução de uma verificação de integridade e aquecimento antes de cada teste e salva os resultados emload-test-runs/<run-name>/<label>/.dashboard_template.py: Gera um painel HTML independente usando Chart.js com cartões de KPI, gráficos de barras (QPS, latência, TTFT por configuração), gráficos de linhas de progressão de rampa de QPS e uma tabela de resultados completa. Pode ser execução independente:uv run dashboard_template.py ../load-test-runs/<run-name>/.
Instalar dependências
Os scripts de teste de carga usam seus próprios pyproject.toml dentro de load-test-scripts/ para evitar poluir as dependências de produção do seu agente. Criar load-test-scripts/pyproject.toml:
[project]
name = "load-test-scripts"
version = "0.1.0"
requires-python = ">=3.10"
dependencies = [
"locust>=2.32,<2.40",
"urllib3<2.3",
"requests",
]
pino locust para <2.40. Versões mais recentes (>=2.43) têm um RecursionError conhecido que quebra testes de carga longos.
Instale a partir do diretório load-test-scripts/ :
cd load-test-scripts/
uv sync
o passo 3: implantei aplicativos de teste com configurações variadas
Implante vários Databricks Apps com diferentes tamanhos compute e número worker para encontrar a configuração ideal para sua carga de trabalho.
Matriz de testes recomendada
As configurações abaixo focam no ponto ideal identificado em testes anteriores. Se você quiser uma cobertura mais ampla, adicione uma configuração de cada lado (por exemplo, medium-w1 ou large-w12), mas as seis abaixo geralmente são suficientes.
Tamanho de compute | Workers | Nome sugerido para o aplicativo |
|---|---|---|
Médio | 2 |
|
Médio | 3 |
|
Médio | 4 |
|
Grande | 6 |
|
Grande | 8 |
|
Grande | 10 |
|
Configurar tamanho compute
Use a CLI Databricks para definir o tamanho compute ao criar ou atualizar um aplicativo:
# Create a new app with Medium compute
databricks apps create <app-name> --compute-size MEDIUM
# Update an existing app to Large compute
databricks apps update <app-name> --compute-size LARGE
Configure a quantidade worker com pacotes de automação declarativa.
start-server (via AgentServer.run()) aceita um sinalizador --workers diretamente. Passe a contagem worker na matriz command usando uma variável DAB:
variables:
app_name:
default: 'my-agent-medium-w2'
workers:
default: '2'
resources:
apps:
load_test_app:
name: ${var.app_name}
source_code_path: .
config:
command: ['uv', 'run', 'start-server', '--workers', '${var.workers}']
env:
- name: MOCK_CHUNK_DELAY_MS
value: '10'
- name: MOCK_CHUNK_COUNT
value: '80'
targets:
medium-w2:
default: true
variables:
app_name: 'my-agent-medium-w2'
workers: '2'
large-w8:
variables:
app_name: 'my-agent-large-w8'
workers: '8'
implantar e verificar
Implante cada alvo com a CLI Databricks :
databricks bundle deploy --target medium-w2
databricks bundle run load_test_app --target medium-w2
Verifique se os aplicativos estão ativos antes de executar os testes de carga:
databricks apps get <app-name> --output json | jq '{app_status, compute_status, url}'
Aguarde até que todos os aplicativos atinjam o status ACTIVE antes de prosseguir. Aplicativos que ainda estão em fase inicial produzem resultados enganosos.
o passo 4: testes de carga de execução
Configurar autenticação
Selecione seu método de autenticação com base na duração prevista da execução:
- Testes curtos (menos de ~1 hora) : use suas credenciais de usuário existentes de
databricks auth login. Nenhuma configuração adicional é necessária. - Testes longos (mais de aproximadamente 1 hora, como execução noturna) : use M2M OAuth com uma entidade de serviço Databricks . Os tokens U2M expiram e interrompem seu teste no meio da execução. A criação de uma entidade de serviço Databricks requer acesso de administrador workspace .
Para OAuth M2M, exporte as credenciais da entidade de serviço do Databricks antes de executar os testes:
export DATABRICKS_HOST=https://your-workspace.cloud.databricks.com
export DATABRICKS_CLIENT_ID=<your-client-id>
export DATABRICKS_CLIENT_SECRET=<your-client-secret>
Referência de parâmetros
Parâmetro | Obrigatório | Padrão | Descrição |
|---|---|---|---|
| Sim | — | URL(s) do(s) aplicativo(s) para teste (repetível) |
| Para testes longos |
| ID do cliente da entidade de serviço (M2M OAuth) |
| Para testes longos |
| entidade de serviço segredo do cliente (M2M OAuth) |
| Não | Derivado automaticamente do URL | Etiqueta legível por humanos por aplicativo (repetível) |
| Não | Detecção automática ou | Calcular o tamanho da tag por aplicativo: |
| Não |
| Número máximo de usuários simulados simultâneos |
| Não |
| Usuários adicionados por rampa o caminho |
| Não |
| Segundos por rampa ou passo |
| Não |
| Taxa de geração de usuários (usuários/seg) |
| Não |
| Nome desta execução — resultados salvos em |
| Não | Desativada | Gere um painel HTML interativo após a conclusão dos testes. |
Exemplo de comando
Teste rápido com um único aplicativo (execução curta — usa sua sessão databricks auth login ):
cd load-test-scripts/
uv run run_load_test.py \
--app-url https://my-app.aws.databricksapps.com \
--dashboard --run-name quick-test
Matriz completa nas 6 configurações recomendadas (execução longa — passe as credenciais M2M). Passe as flags --compute-size na mesma ordem que --app-url:
uv run run_load_test.py \
--app-url https://my-app-medium-w2.aws.databricksapps.com \
--app-url https://my-app-medium-w3.aws.databricksapps.com \
--app-url https://my-app-medium-w4.aws.databricksapps.com \
--app-url https://my-app-large-w6.aws.databricksapps.com \
--app-url https://my-app-large-w8.aws.databricksapps.com \
--app-url https://my-app-large-w10.aws.databricksapps.com \
--compute-size medium --compute-size medium --compute-size medium \
--compute-size large --compute-size large --compute-size large \
--client-id $DATABRICKS_CLIENT_ID \
--client-secret $DATABRICKS_CLIENT_SECRET \
--dashboard --run-name overnight-sweep
Execução múltipla para consistência estatística:
for RUN in r1 r2 r3 r4 r5; do
uv run run_load_test.py \
--app-url https://my-app.aws.databricksapps.com \
--client-id $DATABRICKS_CLIENT_ID \
--client-secret $DATABRICKS_CLIENT_SECRET \
--max-users 1000 --step-size 20 --step-duration 10 \
--run-name my_test_${RUN} --dashboard || break
done
O que acontece durante uma execução
- Healthcheck : verifica se o aplicativo transmite corretamente (recebe
[DONE]). - Aquecimento : envia solicitações sequenciais para aquecer o aplicativo.
- Ramp-to-saturation : os passos up usuários concorrentes a cada
step_durationsegundos. - Detecção de saturação : quando as QPS (consultas por segundo) se estabilizam apesar da adição de mais usuários, você atingiu o limite de taxa de transferência.
Duração estimada
Cada aplicativo em teste é executado por meio de sua própria rampa, portanto, o tempo total de execução aumenta com o número de configurações em sua matriz. Utilize a fórmula abaixo para planejar o período de execução do seu teste.
Duração por aplicativo: (max_users / step_size) * step_duration segundos.
Com valor padrão (--max-users 300 --step-size 20 --step-duration 30):
- 15 passos x 30 segundos = aproximadamente 7,5 minutos por aplicação
- Para a matriz de configuração recomendada de 6 elementos: aproximadamente 45 minutos por execução.
o passo 5: visualizar e interpretar resultados
-
Abra o painel de controle:
Bashopen load-test-runs/<run-name>/dashboard.html -
(Opcional) Regenere o painel a partir de dados existentes, por exemplo, após atualizar o padrão:
Bashcd load-test-scripts/
uv run dashboard_template.py ../load-test-runs/<run-name>/
Seções do painel de controle
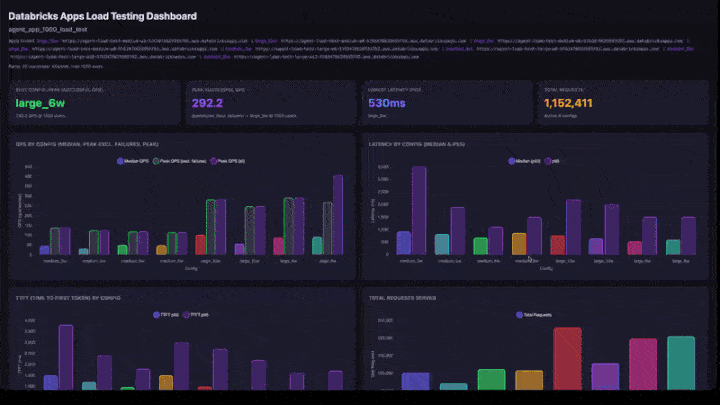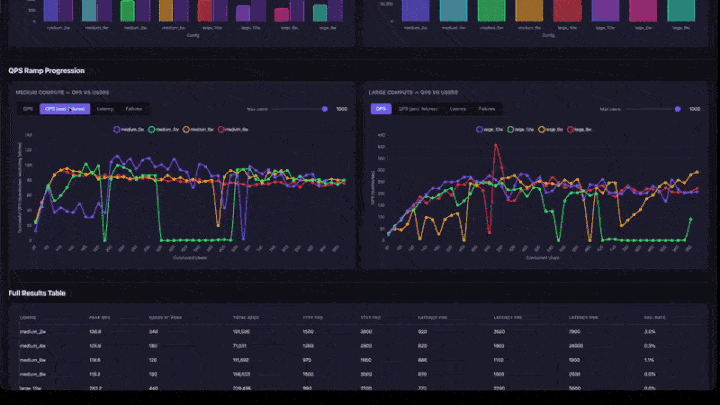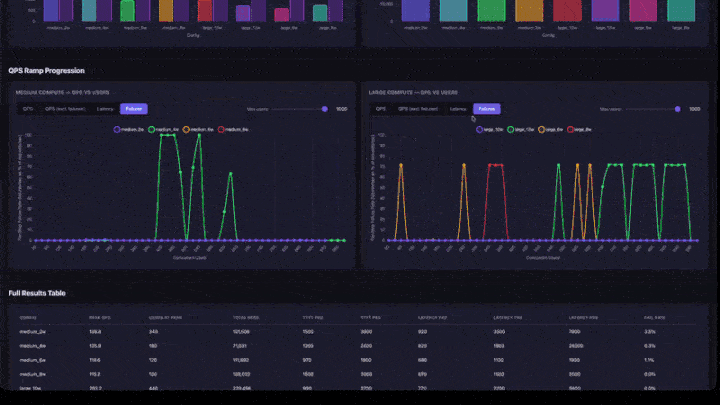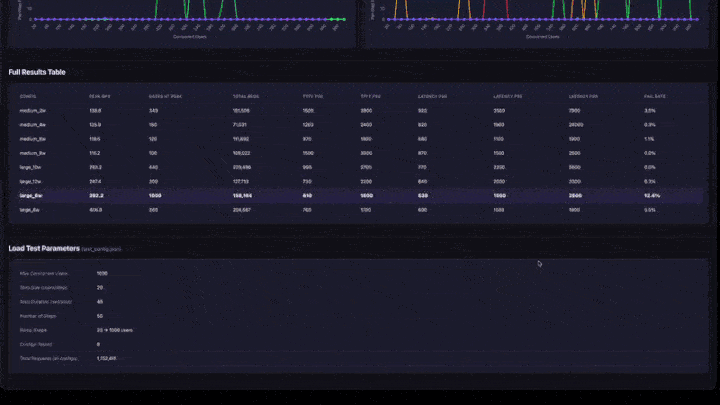
O painel interativo inclui:
- Indicadores-chave de desempenho (KPIs ): melhor configuração (por pico de QPS bem-sucedidos), pico geral de QPS, menor latência e total de solicitações atendidas.
- QPS por Configuração : gráfico de barras agrupadas mostrando a mediana do QPS, o pico do QPS excluindo falhas e o pico do QPS lado a lado para cada configuração.
- Latência por configuração : barras agrupadas mostrando a latência p50 e p95.
- TTFT por Configuração : tempo até os primeiros tokens (p50 e p95).
- Total de solicitações atendidas : número de solicitações por configuração.
- Progressão da Rampa de QPS : gráficos de linhas com abas para QPS, QPS (excluindo falhas), Latência e Falhas. Inclui um controle deslizante para o número máximo de usuários, permitindo ajustar o zoom para intervalos de concorrência mais baixos. Os gráficos estão agrupados por tamanho compute (médio e grande lado a lado).
- Tabela de Resultados Completos : todas as configurações com QPS máximo, usuários no pico, percentis de latência e taxa de falhas.
- Parâmetros de teste : resumo da configuração para reprodução.
Como interpretar os resultados
- Pico de QPS : o QPS máximo alcançado em qualquer rampa de passagem. Este é o teto da Taxa de transferência para essa configuração.
- Usuários no pico : o número de usuários simultâneos quando o pico de QPS foi atingido. Adicionar mais usuários além desse ponto não aumenta a taxa de transferência.
- Taxa de falha : deve ser de 0% ou muito baixa. Uma alta taxa de falhas significa que o aplicativo está sobrecarregado nesse nível de concorrência.
- Gráfico de rampa QPS : procure o ponto onde a linha se estabiliza. Esse é o ponto de saturação: adicionar mais usuários não aumentará a Taxa de transferência.
Solução de problemas
Problema | soluções |
|---|---|
Os tokens de autenticação expiraram durante o teste. | Para testes com duração superior a aproximadamente 1 hora, alterne de OAuth U2M para M2M passando |
A verificação de integridade falhou. | Verifique se o aplicativo está ATIVO: |
0 QPS ou nenhum resultado | Verifique |
Baixa quantidade de consultas por segundo (QPS) apesar do grande número de usuários. | O aplicativo está saturado. Tente usar mais trabalhadores ou compute maior. |
Alta taxa de falha | O aplicativo está sobrecarregado. Reduza |
O painel não mostra dados da rampa. | Verifique |
Recursos adicionais
- Teste com chamadas LLM reais : ignore a etapa de simulação e implante seu agente real para medir a latência de ponta a ponta, incluindo o tempo de resposta LLM .
- Ajuste o número worker : use os resultados da matriz de testes para encontrar o número ideal worker para o tamanho do seu compute .
- Tutorial: Avalie e aprimore um aplicativo GenAI para medir precisão, relevância e segurança em conjunto com a Taxa de transferência.
- Prepare seu agente do Databricks Apps para produção, seguindo toda a sequência de ativação, incluindo o AI Gateway.